



O Insight preparou uma lista com 10 repositórios para ajudar você no desenvolvimento de suas tarefas em Ciência de Dados. O Github é uma plataforma gratuita que hospeda código fonte por meio do controle de versão (o Git) e disponibiliza diversos repositórios abertos feitos por interessados na área.
A área de estudos em Ciência de Dados é muito ampla e no GitHub existem diversos repositórios com projetos muito úteis a quem se interessa por Ciência de Dados. E para tornar sua pesquisa mais fácil, nós separamos alguns para você. Confira:
1 –Graph4NLP
![]()

Esta é uma biblioteca fácil de usar para P&D na interseção de Aprendizado Profundo em Gráficos e Processamento de Linguagem Natural. Ele fornece implementações completas de modelos de última geração para cientistas de dados e também interfaces flexíveis para construir modelos personalizados para pesquisadores e desenvolvedores com suporte de pipeline completo.
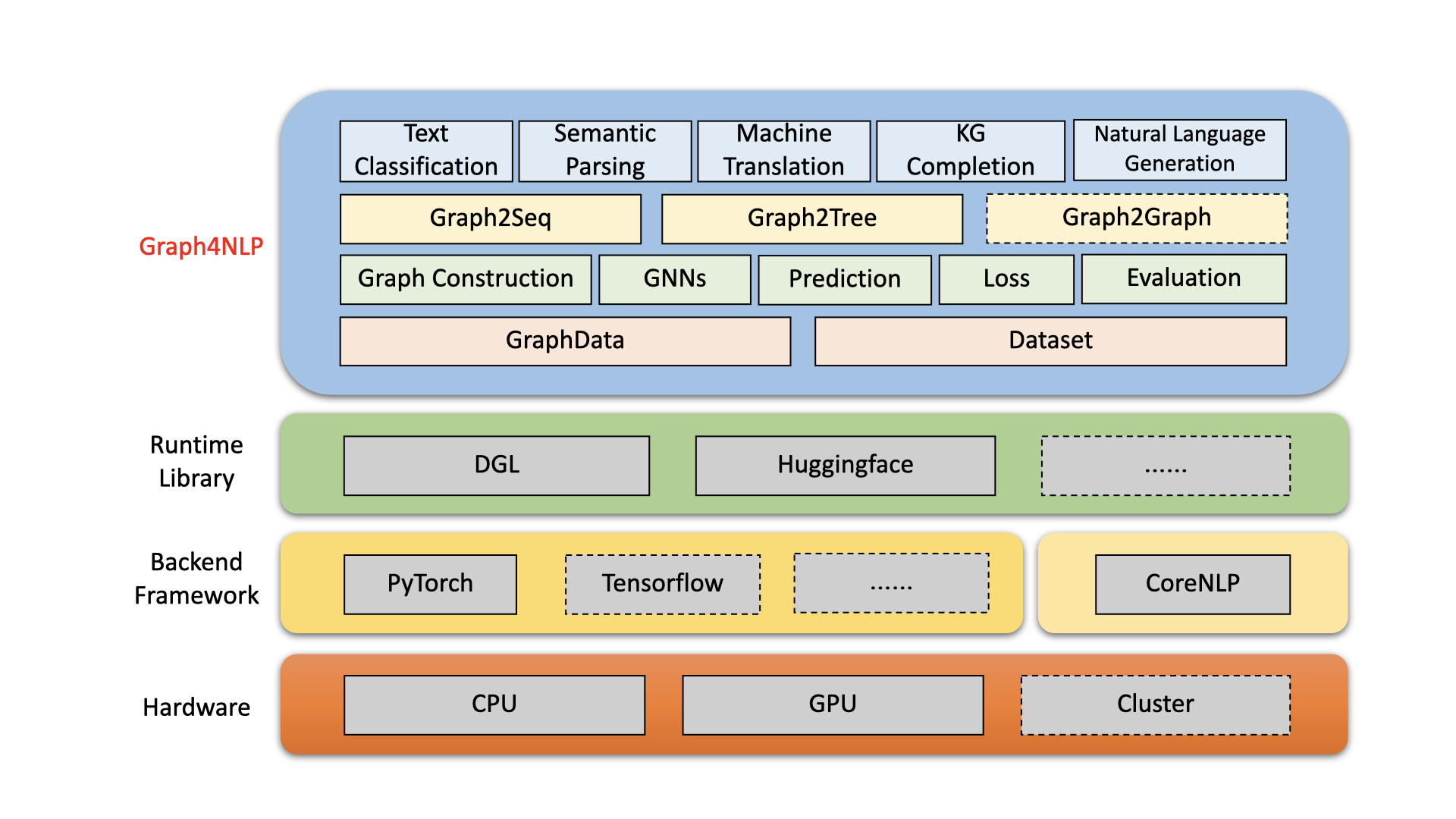
Construído sobre bibliotecas com tempo de execução altamente otimizadas, incluindo DGL, esta biblioteca tem alta eficiência de execução e alta extensibilidade. Sua arquitetura é mostrada na figura a seguir, onde caixas com linhas tracejadas representam os recursos em desenvolvimento que consistem em quatro camadas diferentes:
1) Camada de dados;
2) Camada de módulo;
3) Camada de modelo;
4) Camada de aplicativo.

2 – Rasa


Este é um framework de Machine Learning de código aberto para automatizar conversas baseadas em texto e voz. Com o Rasa, você pode criar assistentes contextuais para diversas plataformas:
- Facebook Messenger;
- Folga;
- Hangouts do Google;
- Equipes Webex;
- Microsoft Bot Framework;
- Rocket.Chat;
- Mattermost;
- Telegrama;
- Twilio.
E também em assistentes de voz como: Alexa Skills e ações do Google Home.

Rasa ajuda a criar assistentes contextuais capazes de ter conversas em camadas com muitas idas e vindas. Para que um humano tenha uma troca significativa com um assistente virtual, este precisa ser capaz de usar o contexto para desenvolver coisas que foram discutidas anteriormente. O Rasa permite que você crie assistentes que podem fazer isso de uma forma escalonável.
3 – Merlion


Merlion é uma biblioteca Python para inteligência em séries temporais. Ela fornece uma estrutura de Machine Learning de ponta a ponta que inclui carregamento e transformação de dados, construção de modelos de treinamento, saídas de modelo de pós-processamento e avaliação de desempenho do modelo. Além disso, oferece suporte a várias tarefas de aprendizagem em séries temporais, incluindo previsão, detecção de anomalias e detecção de ponto de mudança para séries temporais univariadas e multivariadas.
Esta biblioteca tem como objetivo fornecer aos engenheiros e pesquisadores uma solução completa para desenvolver rapidamente modelos para suas necessidades específicas em séries temporais e compará-los em vários datasets.
As principais características do Merlion são: carregamento e benchmarking de dados padronizados e facilidades extensíveis para uma ampla gama de datasets de previsão e detecção de anomalias.
4 – NitroFE


NitroFE é um mecanismo de engenharia de features do Python que fornece uma variedade de módulos projetados para salvar internamente valores com dependência do passado para fornecer cálculos contínuos.
Os atributos de indicadores, janelas e médias móveis dependem dos valores anteriores para cálculo. Por exemplo, uma janela móvel de tamanho 4 depende dos 4 valores anteriores. Embora a criação de tais atributos durante o treinamento seja bastante simples, levá-los para a produção se torna um desafio, pois exigiria que alguém salvasse externamente os valores anteriores e implementasse a lógica. A criação de indicadores torna-se ainda mais complexa, pois dependem de vários outros componentes de janela de tamanhos diferentes.
O NitroFE lida internamente com o salvamento de valores com dependência do passado e torna a criação de recursos descomplicada. Basta usar first_fit = True para seu ajuste inicial.
O NitroFe oferece uma rica variedade de atributos que são inspirados e traduzidos a partir de indicadores de mercado como oscilador de preço absoluto, oscilador de preço percentual, divergência de convergência da média móvel, entre outros.
Em estatística, uma média móvel é um cálculo para analisar pontos de dados criando uma série de médias de diferentes subconjuntos do dataset. O NitroFE oferece uma variedade de tipos de médias móveis para você utilizar.
5 – Aim


O Aim registra suas execuções de treinamento, possui uma bela interface para compará-los e uma API para consultá-los programaticamente. Essa é uma ferramenta de rastreamento de experimentos de IA auto-hospedada e de código aberto. Útil para inspecionar profundamente centenas de execuções de treinamento sensíveis a hiperparâmetros de uma só vez.
O SDK do Aim registra quantas métricas e parâmetros forem necessários para as execuções de treinamento e avaliação. Os usuários do Aim monitoram milhares de execuções de treinamento e, às vezes, mais de 100 métricas por execução com muitas etapas.
Integrado com as ferramentas:


6 – JupyterLab Desktop
O JupyterLab é a interface da próxima geração de usuários do Project Jupyter, oferecendo todos os blocos de construção familiares do Jupyter Notebook clássico (notebook, terminal, editor de texto, navegador de arquivos, saídas ricas, etc.) em uma interface de usuário flexível e poderosa. O JupyterLab eventualmente substituirá o Jupyter Notebook clássico.
Você pode organizar vários documentos e atividades lado a lado na área de trabalho usando guias e divisores. Documentos e atividades se integram, permitindo novos fluxos de trabalho para computação interativa, por exemplo:
- Os consoles de código fornecem rascunhos temporários para a execução de código de forma interativa, com suporte total para uma saída valiosa. Um console de código pode ser vinculado a um kernel do notebook como um log de computação do notebook, por exemplo.
- Documentos baseados em kernel permitem que o código em qualquer arquivo de texto (Markdown, Python, R, LaTeX, etc.) seja executado interativamente em qualquer kernel Jupyter.
- As saídas das células do notebook podem ser espelhadas em sua própria guia, lado a lado com o notebook, permitindo painéis simples com controles interativos apoiados por um kernel.
- Múltiplas visualizações de documentos com diferentes editores ou visualizadores permitem a edição ao vivo de documentos refletidos em outros visualizadores. Por exemplo, é fácil ter uma visualização ao vivo de Markdown, valores separados por delimitador ou documentos Vega / Vega-Lite.
A interface também oferece um modelo unificado para visualizar e manipular formatos de dados. O JupyterLab compreende muitos formatos de arquivo (imagens, CSV, JSON, Markdown, PDF, Vega, Vega-Lite, etc.) e também pode exibir uma saída rica do kernel nesses formatos. Consulte Arquivos e formatos de saída para obter mais informações.

7 – RIVER


River é uma biblioteca Python para Machine Learning (ML) on-line. É o resultado da fusão entre o creme e o scikit-multiflow. O objetivo do River é ser a biblioteca ideal para fazer ML em dados de streaming.
O Machine Learning geralmente é feito em uma configuração de batch, em que um modelo é ajustado a um dataset de uma só vez. Isso resulta em um modelo estático que precisa ser retreinado para aprender com os novos dados. Em muitos casos, isso não é eficiente e geralmente resulta em um problema técnico considerável. Na verdade, se você estiver usando um modelo em batch, precisará pensar em manter um conjunto de treinamento, monitorar o desempenho em tempo real, retreinar o modelo, etc.
Com o River, a abordagem é aprender continuamente com um fluxo de dados. Isso significa que o modelo processa uma observação por vez e pode, portanto, ser atualizado em tempo real. Permitindo assim, aprender com grandes datasets que não cabem na memória principal.
8 – LIGHTNING FLASH
![]()

Flash é uma coleção de tarefas para prototipagem rápida, definição de linha de base e ajuste fino de modelos de Deep Learning escaláveis, baseados no PyTorch Lightning.
Quer você seja novo no Deep Learning ou um pesquisador experiente, o Flash oferece uma experiência perfeita, desde experimentos básicos até pesquisas de ponta. Ele permite que você construa modelos sem ser sobrecarregado por todos os detalhes e, em seguida, substitua e experimente o Lightning para obter total flexibilidade.
Com o Flash, você pode criar sua própria imagem ou classificador de texto em algumas linhas de código, sem necessidade de matemática. Atualmente ele suporta: classificação Imagem, incorporação Imagem, classificação tabular, classificação de texto, sumarização, tradução entre outras.
As tarefas do Flash contêm todas as informações relevantes para resolver sua tarefa como: o número de rótulos de classe que você deseja prever, o número de colunas em seu dataset, bem como detalhes sobre a arquitetura do modelo usada, como função de perda, otimizadores, etc.
9 – PARLAI


ParlAI (pronuncia-se “par-lay”) é uma estrutura Python para compartilhar, treinar e testar modelos de diálogo, desde bate-papos de domínio aberto a diálogos orientados a tarefas e respostas visuais de perguntas.
Seu objetivo é fornecer aos pesquisadores: mais de 100 datasets populares disponíveis em um só lugar, com a mesma API, entre eles PersonaChat, DailyDialog, Assistente de Wikipedia, Empathetic Dialogues, SQuAD, MS MARCO, QuAC, HotpotQA, QACNN & QADailyMail, CBT, BookTest, bAbI Dialogue tasks, Ubuntu Dialoge, OpenSubtitles, Image Chat, VQA, VisDial e CLEVR.
ParlAI possui:
- um amplo conjunto de modelos de referência de linhas de base de recuperação a transformadores.
- uma gama de modelos pré-treinados prontos para usar;
- integração perfeita do Amazon Mechanical Turk para coleta de dados e avaliação humana;
- integração com o Facebook Messenger para conectar agentes com humanos em uma interface de bate-papo;
- uma grande variedade de ajudantes para criar seus próprios agentes e treinar em várias tarefas com multitarefa;
- multimodalidade, algumas tarefas usam texto e imagens.
10 – ZINGG
Os dados do mundo real contêm vários registros pertencentes ao mesmo cliente. Esses registros podem estar em um único sistema ou em vários e possuírem variações nos campos, o que torna difícil combiná-los, especialmente com volumes de dados crescentes. Isso prejudica a análise do cliente – estabelecer valor vitalício, programas de fidelidade ou canais de marketing é impossível quando os dados básicos não estão vinculados.
Nenhum algoritmo de IA para segmentação pode produzir resultados corretos quando há várias cópias do mesmo cliente escondidas nos dados. Nenhum data warehouse pode cumprir sua promessa se as tabelas de dimensão tiverem duplicatas.
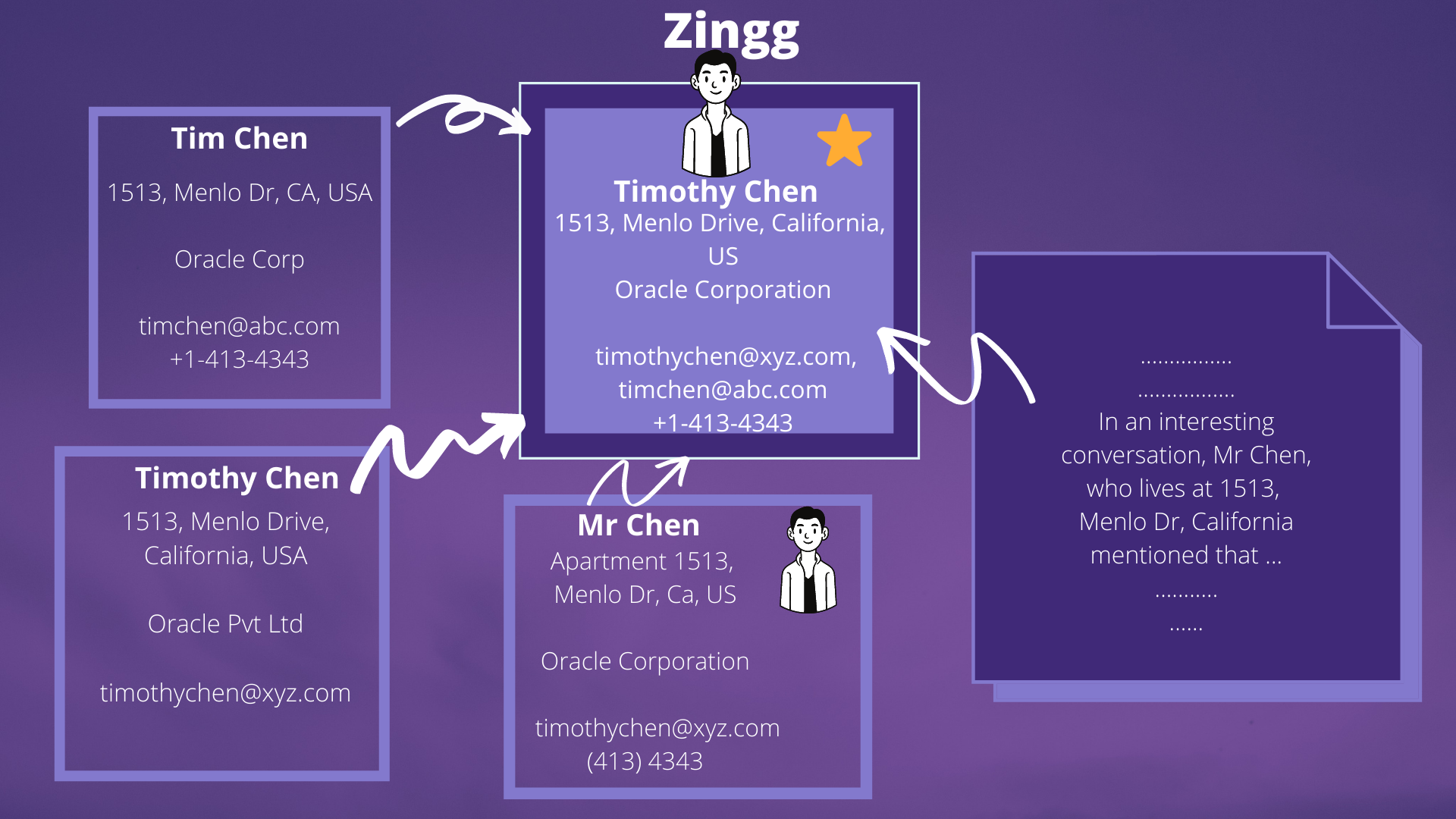
Com uma pilha de dados e DataOps modernos, estabelecemos padrões para E e L em ELT para a construção de data warehouses, datalakes e deltalakes. No entanto, o T – preparar os dados para análises ainda precisa de muito esforço. Ferramentas modernas como DBT estão lidando com isso de forma ativa e bem-sucedida. O que também é necessário é uma maneira rápida e escalável de construir a única fonte de verdade das principais entidades de negócios pós-extração e pré ou pós-carregamento.
Com o Zingg, o engenheiro analítico e o cientista de dados podem integrar rapidamente silos de dados e construir visualizações unificadas em escala!
Obrigado por conferir nossa lista, esperamos que isso tenha contribuído para o conhecimento e crescimento com um cientista de dados!
