O mercado para profissionais com bagagem eminteligência artificial não para de crescer. Em fevereiro, a ONU informou que os números de pedidos de patentes para inovações baseadas em inteligência artificial aumentaram exponencialmente nos últimos anos.
O estudo de inteligência artificial começou, ainda na década de 50 na Universidade de Carnegie Mellon, nos EUA. De lá pra cá muita coisa mudou. Na época, o objetivo dos pesquisadores pioneiros, Hebert Simon, Allen Newell e Jonh McCarthy era criar um “ser” que simulasse uma vida humana.
Hoje, a inteligência artificial sustenta a automação de muitos negócios, com software que aprende a tomar as melhores decisões analisando os dados gerados de decisões anteriores.
Na prática, a inteligência artificial já habita um amplo espectro de nossas rotinas. Seja com a recomendação de músicas no Spotify seja com o melhor caminho para você chegar ao trabalho através do Waze.
Mas para aqueles que desejam trabalhar na área, por onde começar? Afinal, o conhecimento em inteligência artificial é muito amplo e exigido em cargos que vão desde um Cientista de Dados até um Engenheiro Aeroespacial. Aqueles com habilidades para analisar, organizar e traduzir bits de informação digital em experiências humanas significativas, certamente vão encontrar na carreira de inteligência artificial uma oportunidade recompensadora.
Por esse motivo, a redação do IT Trends preparou um guia completo, com tudo que você precisa saber para trabalhar com Inteligência Artificial. Confira.
Carreiras em inteligência artificial
De acordo com o Computer Science Degree Hub, carreiras em inteligência artificial podem ser encontradas em diversos ambientes, como empresas públicas e privadas, organizações educacionais, artes, instalações de saúde, agências governamentais e militares, entre outros.
Em alguns desses ambientes, as vagas podem exigir alto nível de responsabilidade e segurança, principalmente quando se trata de dados, dependendo da sensibilidade das informações, empresas podem até exigir certificações em segurança.
Confira a lista de cargos com atuação em inteligência artificial:
Analistas e Desenvolvedores de softwares e sistemas;
Cientistas e Engenheiros da computação;
Cientistas e Engenheiros de Machine Learning;
Cientistas e Engenheiros de aplicações e plataformas;
Cientistas e Engenheiros de Integração de Hardware;
Arquiteto de Dados;
Especialistas em algoritmos;
Cientistas de pesquisa e consultores de engenharia;
Engenheiros mecânicos e técnicos de manutenção;
Engenheiros elétricos e de manufatura;
Técnicos cirúrgicos trabalhando com ferramentas robóticas;
Profissionais de saúde médicos que trabalham com membros artificiais, próteses, aparelhos auditivos e dispositivos de restauração da visão;
Eletricistas militares e de aviação que trabalham com simuladores de voo, drones e armamentos;
Designers gráficos, músicos digitais, produtores de entretenimento, fabricantes de têxteis e arquitetos;
Professores pós-secundários em escolas técnicas e comerciais, centros vocacionais e universidades;
Conhecimentos e habilidades exigidos
Uma carreira em inteligência artificial é caracterizada pelo contato muito próximo com a automação, robótica, programação, algoritmos e uso de softwares específicos, sendo assim necessário que o interessado tenha disposição para adotar esses conceitos no seu dia a dia. No entanto, para adotar esses conceitos na rotina é necessário conhecimentos básicos e fundamentais, como matemática, tecnologia, lógica e engenharia.
Trabalhar com inteligência artificial exige também características comportamentais, como pensamento analítico e capacidade de resolver problemas com soluções eficientes e sustentáveis.
Os profissionais de inteligência artificial devem ser capazes de traduzir informações altamente técnicas, de modo que outras pessoas e colegas possam entender. Isso requer habilidades de comunicação interpessoal além de eficiência em trabalhos em equipe.
É importante lembrar que cada cargo, empresa ou área de atuação dentro da inteligência artificial pode ter exigências de conhecimentos específicos para a vaga. Os interessados em uma carreia em inteligência artificial devem investigar quais são os conhecimentos necessários para cada vaga, individualmente.
Educação
Mesmo que a área de tecnologia seja aberta para profissionais sem diplomas de ensino tradicional, inteligência artificial é um conceito muito discutido na academia, sendo um diferencial, um curso superior, mesmo para cargos de entrada.
Para trabalhar com inteligência artificial é necessário conhecimentos básicos em informática, matemática e lógica de computadores, que é a fundação da maioria dos programas de inteligência artificial.
É interessante também, procurar se especializar com cursos específicos da área. Diversas instituições de ensino oferecem cursos de pós-graduação em inteligência artificial. A FIAP por exemplo, oferece o programa de MBA: Artificial Intelligence & Machine Learning onde os alunos estudam majoritariamente:
História da inteligência artificial
Tipos de aprendizagem e algoritmos: aprendizagem e algoritmos por reforço, aprendizagem e algoritmos não supervisionados e aprendizagem e algoritmos supervisionados.
Heurísticas e meta-heurísticas de busca.
Deep learning e reinforcement Learning.
Redes neurais, convolucionais, recorrentes e recursivas
Manipulação de dados com Python e R
Modelagem de dados e big data
Indexação de documentos, text mining, cluster e chatbot.
Visão computacional, manipulação e segmentação de imagens, realidade aumentada
A USP explica que o curso cobre tópicos como predição, linguagens de programação R e Python, redes neurais, deep learning, consequências do uso de machine learning na economia e sociedade, entre outros.
Sendo assim, os interessados em conseguir uma oportunidade em uma carreira de inteligência artificial devem se atentar a esses detalhes como o que estudar e quais tipos de empresas precisam de profissionais especializados em inteligência artificial para conseguir uma vaga.
A análise de big data foi aplicada a diferentes esferas da vida humana. Um dos melhores recursos da análise de dados é sua adaptabilidade e amplo espectro de aplicativos. Percorremos toda a série de artigos sobre aplicação de ciência de dados em várias esferas que estão comprovando essa afirmação. Vamos considerar os casos de uso da ciência de dados para a atividade do governo.
Sob condições de rápido desenvolvimento de tecnologias e sociedades, os governos precisam resolver tarefas complexas e gerenciar vários procedimentos simultaneamente. Os governos enfrentam a necessidade de plataformas inteligentes capazes de coletar, limpar, filtrar e analisar grandes quantidades de dados. Governos locais, agências federais e departamentos usam ferramentas orientadas a dados para otimizar seu trabalho e melhorar os assuntos de segurança, setor público, direito, defesa, etc.
Vamos examinar mais de perto e esclarecer como os governos usam a ciência de dados e quais benefícios ela pode trazer.
Detecção de fraude
Todos os anos, transações fraudulentas causam perdas financeiras significativas para os governos. A fraude se tornou uma coisa comum. Esse fato pode parecer marcante para você, mas vamos dar uma olhada. Todas as operações que são mais ou menos relacionadas ao dinheiro apresentam interesse para possíveis fraudadores.
A principal característica da fraude no nível governamental é que as consequências, em certa medida, afetarão cada cidadão.
Para mitigar os riscos de fraude e ameaças subsequentes, os governos aplicam soluções de dados inteligentes e análise de dados.
Evasão fiscal
A sonegação de impostos pressupõe as ações tomadas pelos indivíduos ou empresas para deturpar os negócios reais com as autoridades fiscais. Desonestidade nos relatórios fiscais, como declarar menos renda, ajuda a reduzir a responsabilidade tributária. Em outras palavras, pessoas ou empresas mostram menos dinheiro com o objetivo de pagar menos dinheiro ao Estado. Imagine a quantidade de dados que devem ser processados e analisados para encontrar um evasor. Isso está realmente além da competência humana.
Felizmente, plataformas e soluções analíticas modernas são capazes de detectar sonegação de impostos. Os algoritmos analíticos usados para esse fim baseiam-se não apenas nos dados financeiros, mas também nas informações de mídia social. Os algoritmos analisam cuidadosamente os dados e combinam os padrões dos gastadores com os rendimentos declarados. Assim, aqueles que gastam muito mais do que gastam são facilmente detectados.
Empresas não registradas
O grupo de firmas canceladas de registro abrange as empresas que não estão mais registradas no registro, desistiram de negociar e não estão sujeitas a obrigações legais e tributação. No entanto, essas empresas podem ser facilmente trazidas de volta à vida em caso de necessidade.
Esse fato fornece um vasto campo para atividades fraudulentas. Muitas vezes, as empresas não estão mais no registro, mas continuam sua operação e, finalmente, obtêm renda.
Algoritmos analíticos e soluções baseadas em IA estão ajudando os governos a esse respeito. Os algoritmos rastreiam a atividade mesmo para as empresas que parecem inativas e alarmadas em caso de ações suspeitas tomadas. Os algoritmos detectam a aparência do nome da empresa ou outras informações entre os dados financeiros. A divulgação das firmas canceladas de registro ajuda o estado a minimizar e até impedir a evasão ilegal do pagamento de impostos.
Defesa
Questões de defesa são cruciais para todos os estados do mundo. Todos os anos, governos de todo o mundo gastam bilhões de dólares em defesa.
Uma parte significativa desse dinheiro é gasta na introdução de big data, algoritmos de aprendizado de máquina e soluções baseadas em IA para melhorar o desempenho de vários departamentos e instituições militares. Fortalecidas pelas soluções de dados inteligentes, essas instituições podem melhorar o processo de tomada de decisão e reduzir o tempo gasto na solução de um assunto específico.
No campo da defesa, a importância do big data é enorme. Com a introdução da análise em tempo real, os estados tiveram a oportunidade de assistir, rastrear e monitorar as fronteiras, criar vários fluxos de vídeo a partir de vários objetos estrategicamente importantes e observar os espaços aéreo e marinho. As soluções inteligentes são mais atentas, precisas e confiáveis em seus resultados de monitoramento. A análise preditiva parece ser um fator de mudança de jogo na logística de defesa e na prevenção de possíveis ameaças. Os algoritmos criam cenários possíveis calculando possíveis ameaças ou danos.
Atividade terrorista
Nas últimas décadas, fomos testemunhas de vários incidentes terroristas em todo o mundo. Essas questões precisam ser tomadas medidas severas, pois a segurança e o bem-estar das pessoas estão ameaçados.
O terrorismo se tornou um tipo de negócio para alguns grupos de pessoas. As organizações terroristas até recrutam jovens através de plataformas de mídia social.
A análise de big data, algoritmos de aprendizado de máquina e mineração de texto são amplamente aplicados para detectar essa atividade. Grandes quantidades de dados sobre o potencial comportamento terrorista são coletadas e cuidadosamente processadas. Esses dados incluem conversas incomuns, textos, interação e contatos, compras ou movimentos em locais potencialmente perigosos etc. As agências de segurança estão trabalhando na detecção em tempo real de padrões de dados e vinculando esses padrões aos sistemas. Essas soluções de dados inteligentes examinam todos os dados disponíveis e relatórios de formulário sobre indivíduos ou grupos possivelmente perigosos, levando em consideração os dados referentes a casos anteriores de extremismo, crime ou terrorismo.
Sensibilização para o crime nas ruas
O uso de invenções e bancos de dados modernos pelas autoridades estaduais mudou toda a imagem do mundo do crime. Impressões digitais, amostras de DNA e análises balísticas abriram novas oportunidades para quem investiga crimes e se esforça para impedir que eles aconteçam.
Os departamentos de polícia de todo o mundo utilizam big data para prever o mapeamento de crimes. Esses sistemas usam dados anteriores sobre tipo de crime, localização, data e hora para criar os pontos críticos. Os mapas com os pontos ativos provam ser muito mais eficientes do que pura adivinhação.
Além disso, os sistemas de cidades inteligentes permitem o monitoramento de vários locais sob condições de transmissão em tempo real. Câmeras e detectores de movimentos altamente sensíveis detectam ações suspeitas e enviam alarmes à polícia.
Ataques cibernéticos
No mundo das tecnologias digitais, a cibersegurança se tornou uma questão do nível governamental. Coletamos e analisamos a grande quantidade de dados para revelar suas informações valiosas. Mas os resultados de nosso cuidadoso processamento e análise podem se tornar interessantes para alguém que deseja usá-lo para um objetivo específico. Além disso, essas pessoas planejam levar os dados ilegalmente por roubo ou ataque de hackers.
Imagine a quantidade e a importância dos dados possuídos pelas instituições governamentais. Caso esses dados se tornem disponíveis ao público ou, pelo menos, a indivíduos particulares, ou se os dados desaparecerem, as consequências podem ser perturbadoras. Portanto, análises de big data e ferramentas específicas de aprendizado de máquina são usadas para monitorar e examinar cuidadosamente todas as operações que envolvem dados valiosos para revelar tendências e padrões nessas ações. Os sistemas monitoram os usuários e dispositivos na rede e sinalizam indivíduos ou ações suspeitas. Ele permite que o estado tome medidas mais operacionais, confiáveis e seguras para evitar ataques cibernéticos.
Vigilância mais inteligente
Câmeras de vigilância são usadas cada vez mais extensivamente. Essas câmeras já provaram sua eficiência em objetos menores. Agora eles estão caminhando para as ruas e cantos mais escuros e menores das cidades e vilas.
As câmeras de vigilância não estão apenas gravando os vídeos. Hoje, suas capacidades se ampliam. Por exemplo, agora eles podem reconhecer violência ou atividade criminosa e distinguir brigas ou abusos físicos de outras ações e movimentos depois que o sistema de reconhecimento inteligente envia a mensagem à polícia.
Além disso, algoritmos semelhantes são usados para reconhecer quedas traumáticas ou outras lesões e podem informar sobre a emergência. Isso prova ser muito útil para idosos e pessoas que sofrem de doenças crônicas graves.
Segurança nacional
Como a interação de pessoas e dados se torna mais intensa a cada dia, a idéia de usar big data para o benefício da sociedade parece cada vez mais atraente. Os dados se tornam uma fonte mais confiável, apresentando grande valor para o estado. Assim, e se tornar uma questão de segurança nacional.
Sem dúvida, a análise de big data suporta a segurança nacional e traz oportunidades para diferentes áreas. Entre eles estão a detecção de anomalias, mineração de associação para divulgação dos padrões e interconexão entre os conjuntos de dados, classificação e agrupamento de dados. Além disso, pode ser usado para análise de links e divulgação de mensagens ocultas dos textos ou documentos. Assim, torna visível para as pessoas as informações, relações e padrões que as pessoas podem ignorar. Em combinação com julgamentos humanos, a análise de big data ajuda na tomada de decisões.
Aplicação da lei
A análise de big data pode fazer a diferença na aplicação da lei. As agências policiais podem obter resultados significativos no trabalho, tendo em mãos os enormes bancos de dados cheios de dados referentes a chapas de matrícula, identidades criminais, estatísticas criminais e acesso a plataformas de mídia social.
Com a ajuda de modernas ferramentas de análise, as agências policiais podem transformar os dados disponíveis em inteligência acionável. Assim, o fenômeno do policiamento preditivo aparece. Isso significa que a análise de big data permite impedir a ocorrência de crimes. Atualmente, o policiamento preditivo está em ascensão, apesar de todas as disputas e argumentos contra ele.
Saúde e Serviços Humanos
As agências estatais que trabalham com ou controlam serviços de saúde e humanos usam a análise de big data com a mesma eficiência que outras autoridades governamentais. Não analisar os dados disponíveis nessa área seria uma perda significativa.
A prestação de serviços de alta qualidade aos cidadãos é a tarefa prioritária do governo. Portanto, as atividades das agências de saúde e serviços humanos (HHS) são regulamentadas pelo estado. As agências de HHS trabalham duro para fornecer transparência em suas operações e satisfazer todas as necessidades de seus clientes. A aplicação da análise em tempo real capacita os funcionários a coletar, processar, analisar e visualizar dados e obter uma visão real dos serviços que prestam e do nível de satisfação de seus clientes. É muito mais fácil tirar conclusões e identificar os assuntos para melhorias adicionais, com base nos resultados de análises precisas.
Resposta de emergência
A capacidade de incorporar dados de várias fontes oferece uma vantagem significativa para governos e autoridades locais em condições de emergência. A análise em tempo real ajuda a tomar decisões imediatas em situações estressantes. O controle sobre vários canais de comunicação e o uso de ferramentas inteligentes que reconhecem possíveis ameaças e enviam alarmes permitem às autoridades locais avisar os cidadãos e aconselhá-los sobre ações adicionais.
Conclusão
Levando em consideração todas as instâncias mencionadas em nossos principais casos de uso de ciência de dados no governo, é bastante evidente que as vantagens são numerosas. Eles estão começando com a redução do tempo para resolver um único problema e terminando com a capacidade de evitar casos desastrosos. Tudo isso cai sob a competência da ciência de dados e seu uso inteligente. O leque de possibilidades é vasto.
O big data melhora o setor governamental. Os cidadãos comuns sentem resultados práticos dessas mudanças em suas vidas diárias e serviços prestados pelo Estado. Esperamos que ainda mais mudanças positivas ainda estejam por vir e tragam mudanças positivas para os estados em todo o mundo.
Nos últimos anos, os pesquisadores criaram um número crescente de técnicas de reconhecimento facial baseadas em aprendizado de máquina (ML), que podem ter inúmeras aplicações interessantes, por exemplo, aprimorando o monitoramento de vigilância, controle de segurança e arte potencialmente forense. Além do reconhecimento facial, os avanços no ML também permitiram o desenvolvimento de ferramentas para prever ou estimar qualidades específicas (por exemplo, sexo ou idade) de uma pessoa, analisando imagens de seus rostos.
Em um estudo recente, pesquisadores da Universidade de Kwazulu-Natal, na África do Sul, desenvolveram um modelo de machine learning para estimar a idade das pessoas analisando imagens de seus rostos tirados em ambientes aleatórios da vida real. Essa nova arquitetura foi introduzida em um artigo publicado no Springer e apresentado há alguns dias na Conferência Internacional sobre Inteligência Coletiva Computacional (ICCCI) 2019.
As abordagens mais tradicionais para classificação etária somente têm bom desempenho ao analisar imagens de rosto tiradas em ambientes controlados, por exemplo, no laboratório ou em estúdios de fotografia. Por outro lado, muito poucos deles são capazes de estimar a idade das pessoas em imagens tiradas em ambientes cotidianos reais.
“Os métodos de aprendizado profundo provaram ser eficazes na solução desse problema, especialmente com a disponibilidade de uma grande quantidade de dados para treinamento e máquinas de ponta”, escreveram os pesquisadores em seu artigo. “Em vista disso, propomos uma solução de aprendizado profundo para estimar a idade a partir de rostos da vida real”.
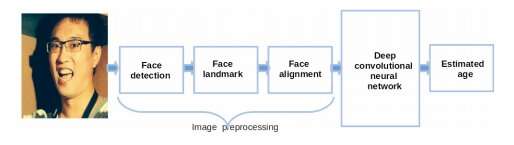
A equipe de pesquisadores da Universidade de Kwazulu-Natal desenvolveu uma arquitetura baseada em rede neural convolucional profunda (CNN) com seis camadas. Seu modelo foi treinado para estimar a idade dos indivíduos a partir de imagens de rostos tirados em ambientes não controlados. A arquitetura consegue isso aprendendo quais representações faciais são mais cruciais para a estimativa de idade e concentrando-se nesses recursos específicos.
A fase de pré-processamento da imagem. Crédito: Agbo-Ajala e Viriri.
Para melhorar o desempenho de seu modelo baseado na CNN, os pesquisadores o treinaram em um grande conjunto de dados chamado IMDB-WIKI, que contém mais de meio milhão de imagens de rostos tirados do IMDB e da Wikipedia, rotulados com a idade de cada sujeito. este treino inicial permitiu-lhes conformar sua arquitetura para enfrentar o conteúdo da imagem.
Posteriormente, os pesquisadores ajustaram o modelo usando imagens de outros dois bancos de dados, MORPH-II e OUI-Adience, treinando-o para captar peculiaridades e diferenças. O MORPH-II contém aproximadamente 70.000 imagens rotuladas de rostos, enquanto o OUI-Adience contém 26.580 imagens de rostos tiradas em ambientes ideais da vida real.
Quando eles avaliaram seu modelo em imagens tiradas em ambientes não controlados, os pesquisadores descobriram que esse extenso treinamento levou a um desempenho notável. Seu modelo alcançou resultados de última geração, superando vários outros métodos baseados na CNN para estimativa de idade.
“Nossas experiências demonstram a eficácia do nosso método para estimativa de idade na natureza quando avaliadas no benchmark OUI-Adience, que é conhecido por conter imagens de rostos adquiridos em condições ideais e sem restrições “, escreveram os pesquisadores.” O método de classificação etária proposto alcança novos resultados de última geração, com uma melhoria na precisão de 8,6% (exato) e 3,4% (pontual) em relação ao melhor resultado relatado no conjunto de dados OUI-Adience “.
No futuro, a nova arquitetura baseada na CNN desenvolvida por esses pesquisadores poderá permitir implementações de estimativa de idade mais eficazes em uma variedade de configurações da vida real. A equipe também planeja adicionar camadas ao modelo e treiná-lo em outros conjuntos de dados de imagens de rosto tiradas em ambientes não controlados assim que estiverem disponíveis, a fim de melhorar ainda mais seu desempenho.
Mais Informações:
Olatunbosun Agbo-Ajala et al. Age Estimation of Real-Time Faces Using Convolutional Neural Network, Computational Collective Intelligence (2019). DOI: 10.1007/978-3-030-28377-3_26
Existe uma infinidade de opções para classificação. Em geral, não existe uma única opção “melhor” para todas as situações. Dito isto, três métodos populares de classificação – Decision Trees, k-NN e Naive Bayes – podem ser aprimorados para praticamente todas as situações.
visão global
Naive Bayes e K-NN, são dois exemplos de aprendizado supervisionado (onde os dados já vêm rotulados). Árvores de decisão são fáceis de usar para pequenas quantidades de classes. Se você está tentando decidir entre os três, sua melhor opção é levar todos os três para um test drive em seus dados e ver qual produz os melhores resultados.
Se você é novo na classificação, uma árvore de decisão é provavelmente o seu melhor ponto de partida. Isso lhe dará um visual claro e é ideal para entender o que a classificação está realmente fazendo. K-NN vem em um segundo próximo; Embora a matemática por trás disso seja um pouco assustadora, você ainda pode criar um visual do processo do vizinho mais próximo para entender o processo. Finalmente, você vai querer cavar na Naive Bayes. A matemática é complexa, mas o resultado é um processo altamente preciso e rápido – especialmente quando você está lidando com Big Data.
Onde Bayes se destaca
1. Naive Bayes é um classificador linear enquanto K-NN não é; Tende a ser mais rápido quando aplicado a big data. Em comparação, k-nn geralmente é mais lento para grandes quantidades de dados, devido aos cálculos necessários para cada nova etapa do processo. Se a velocidade for importante, escolha Naive Bayes sobre K-NN.
2. Em geral, Naive Bayes é altamente acurado quando aplicado a big data. Não desconsidere o K-NN quando se trata de precisão; como o valor de k no K-NN aumenta, a taxa de erro diminui até atingir a do Bayes ideal (para k → ∞).
3. Naive Bayes oferece a você dois hiperparâmetros para ajustar para suavização: alfa e beta. Um hiperparâmetro é um parâmetro anterior que é ajustado no conjunto de treinamento para otimizá-lo. Em comparação, o K-NN tem apenas uma opção de ajuste: o “k”Ou número de vizinhos.
4. Este método não é afetado pelo maldição da dimensionalidade e euconjuntos de recursos arge, enquanto o K-NN tem problemas com ambos.
1. Se tiver independência condicional Se você tiver uma classificação de afeto altamente negativo, escolha K-NN em vez de Naive Bayes. Naive Bayes pode sofrer com a problema de probabilidade zero; quando a probabilidade condicional de um atributo específico for igual a zero, o Naive Bayes falhará completamente em produzir uma previsão válida. Isso poderia ser corrigido usando um estimador Laplaciano, mas o K-NN poderia acabar sendo a escolha mais fácil.
2. Naive Bayes só funcionará se o limite de decisão é linear, elíptico ou parabólico. Caso contrário, escolha K-NN.
3. Naive Bayes requer que você conheça o subjacente distribuições de probabilidade para categorias. O algoritmo compara todos os outros classificadores contra esse ideal. Portanto, a menos que você conheça probabilidades e pdfs, o uso do Bayes ideal não é realista. Em comparação, o K-NN não exige que você saiba nada sobre as distribuições de probabilidade subjacentes.
4. O K-NN não requer nenhum Treinamento– você apenas carrega o conjunto de dados e ele é executado. Por outro lado, Naive Bayes requer treinamento.
5. O K-NN (e Naive Bayes) superam as árvores de decisão quando se trata de ocorrências raras. Por exemplo, se você está classificando tipos de câncer na população em geral, muitos tipos de câncer são bastante raros. Uma árvore de decisão quase certamente removerá essas classes importantes do seu modelo. Se você tiver ocorrências raras, evite usar árvores de decisão.
1. Dos três métodos, as árvores de decisão são as mais fácil de explicar e entender. A maioria das pessoas entende árvores hierárquicas, e a disponibilidade de um diagrama claro pode ajudá-lo a comunicar seus resultados. Por outro lado, a matemática subjacente ao Teorema de Bayes pode ser muito difícil de entender para o leigo. K-NN se encontra em algum lugar no meio; Teoricamente, você pode reduzir o processo K-NN a um gráfico intuitivo, mesmo que o mecanismo subjacente esteja provavelmente além do nível de entendimento de um leigo.
2. As árvores de decisão têm recursos fáceis de usar para identificar as dimensões mais significativas, lidar com valores ausentes e lidar com valores discrepantes.
3. Embora excessivo Como é um grande problema com as árvores de decisão, a questão poderia (pelo menos em teoria) ser evitada usando árvores reforçadas ou florestas aleatórias. Em muitas situações, o reforço ou florestas aleatórias podem resultar em árvores com desempenho superior a Bayes ou K-NN. A desvantagem desses complementos é que eles adicionam uma camada de complexidade à tarefa e diminuem a grande vantagem do método, que é sua simplicidade.
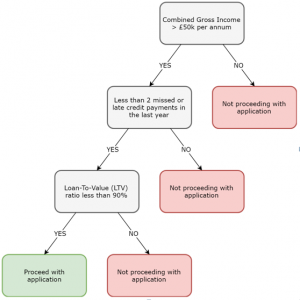
Mais galhos em uma árvore levam a uma chance maior de adaptação excessiva. Portanto, as árvores de decisão funcionam melhor para um pequeno número de aulas. Por exemplo, a imagem acima resulta apenas em duas classes: continue ou não prossiga.
4. Ao contrário de Bayes e K-NN, as árvores de decisão podem trabalhar diretamente de um tabela de dados, sem qualquer trabalho prévio de design.
5. Se você não conhece seus classificadores, uma árvore de decisão será escolha esses classificadores para você de uma tabela de dados. Naive Bayes requer que você conheça seus classificadores com antecedência.
Considerada a 3ª linguagem “mais amada” pelos desenvolvedores segundo pesquisa do Stack Overflow, o Python está entre as 5 linguagens mais populares por exigir poucas linhas de código e não ter uma leitura complicada, se comparada com programas semelhantes. Até por isso, pode ser considerada uma boa opção para ser “porta de entrada” para quem deseja se aventurar por esse mundo.
Para quem possui esse interesse e domina o inglês, temos novidades: o canal da Microsoft para Desenvolvedores lançou um módulo básico de estudo da linguagem. De acordo com os profissionais responsáveis por desenvolver as aulas, a ideia é fornecer conceitos concretos o suficiente para que, ao final das aulas, o “aluno” consiga por conta própria desenvolver as habilidades adquiridas.
Os vídeos são curtos (com duração máxima de 14 minutos) e apresentam conceitos como Machine Learning para aplicativos, apps desenvolvidos para web e automação de processos em computadores. Nas últimas aulas, a equipe disponibiliza conteúdos como livros e tutoriais que podem ser usados como referência
Cursos de Python em português e com diferentes formatos
Apesar de prático, o curso tem como limitadores o idioma e ser intensamente focado em vídeos. Para quem deseja entender mais sobre a plataforma e gostaria de outras opções preparamos recentemente uma matéria com 5 cursos on-line gratuitos sobre Python.
Neste post, explicarei a detecção de objetos e vários algoritmos como Faster R-CNN, YOLO, SSD. Começaremos do nível dos iniciantes e avançaremos até o estado da arte na detecção de objetos, entendendo a intuição, a abordagem e as principais características de cada método.
O que é classificação de imagem?
A classificação da imagem obtém uma imagem e prevê o objeto em uma imagem.
O problema de identificar a localização de um objeto (dada a classe) em uma imagem é chamado de localização. No entanto, se a classe de objeto não for conhecida, precisamos não apenas determinar a localização, mas também prever a classe de cada objeto.
Prever a localização do objeto junto com a classe é chamado de detecção de objeto. Em vez de prever a classe de objeto a partir de uma imagem, agora precisamos prever a classe e também um retângulo (chamado caixa delimitadora) contendo esse objeto. São necessárias 4 variáveis para identificar exclusivamente um retângulo. Portanto, para cada instância do objeto na imagem, preveremos as seguintes variáveis:
Servidores do Laboratório de Identificação de Desconhecidos (LID) da Coordenadoria de Identificação Humana e Perícias Biométricas (CIHBP), da Perícia Forense do Estado do Ceará (Pefoce), realizaram a identificação de um homem suspeito de ser fugitivo da cadeia pública de Pacajus, nessa segunda-feira (16). A identificação foi realizada por meio do aplicativo do Portal de Comando Avançado (PCA), que foi desenvolvido pela Secretaria da Segurança Pública e Defesa Social (SSPDS) em parceria com a Universidade Federal do Ceará (UFC).
De acordo com o servidor da Pefoce, Humberto Quezado, do LID, a Pefoce foi acionada para realizar a identificação de um paciente, que deu entrada no hospital Universitário Walter Cantídio, localizado no bairro Rodolfo Teófilo. O homem foi deixado por uma pessoa, que também não se identificou. O acompanhante apenas deu um suposto nome, que seria do paciente, e foi embora.
Porém, ao realizarem uma busca no PCA, as impressões digitais do paciente foram verificadas junto ao banco de dados civil. Com isso, foi possível chegar ao nome do homem, sendo este identificado por Narcílio Cavalcante (23). Ainda de acordo com Humberto Quezado, a pesquisa apontou que o homem possui ficha criminal e passagem na Polícia Civil por roubo. Além disso, Narcílio é fugitivo da cadeia pública de Pacajus, onde estava preso aguardando julgamento. A fuga teria ocorrido no ano de 2016.
Aplicativo
O aplicativo Portal de Comando Avançado foi desenvolvido pela Secretaria da Segurança Pública e Defesa Social (SSPDS), em parceria com a Universidade Federal do Ceará (UFC), com o objetivo de fornecer informações gerenciais para a área operacional e administrativa da SSPDS. Desta forma, a ferramenta integra os serviços disponibilizados para os servidores da Policia Militar, Policia Civil, Corpo de Bombeiros e Perícia Forense.
Data Science ganhou muita popularidade nos últimos anos. O foco principal deste campo é converter dados significativos em valores para o negócio que ajudam as empresas a crescer.
Os dados são armazenados e pesquisados para entrar em uma solução lógica.
Anteriormente, apenas as principais empresas de TI estavam envolvidas nesse campo, mas, atualmente, organizações de vários setores e áreas, como comércio eletrônico, assistência médica, finanças e outras, estão usando Data Science para aumentar sua competitividade.
Existem várias ferramentas disponíveis para análise de dados, como Hadoop, programação R, SAS, SQL, entre outras.
No entanto, a técnologia mais popular e fácil de usar para análise de dados é a linguagem Python. Essa tecnologia é conhecida como um canivete suíço do mundo da programação porque suporta programação estruturada, codificação orientada a objetos, além ser de uma linguagem de programação funcional e ter outras funções.
De acordo com a pesquisa do StackOverflow, de 2018, Python é a linguagem de programação mais popular do mundo e também é a mais adequada para ferramentas e aplicativos de Data Science.
Por isso, preparei o artigo a seguir com os principais motivos pelos quais Python é a linguagem mais adotada pelos principais cientistas e centros da área de Data Science mundial.
Confira!
A importância da Data Science
Elaboramos um breve resumo sobre o que é Data Science na introdução deste artigo, mas precisamos nos aprofundar um pouco mais nos conceitos relacionados à análise de dados antes de prosseguir falando sobre as vantagens do Python sobre outras linguagens.
Durante toda a história da civilização, os dados que tínhamos eram, na maior parte, estruturados e pequenos em tamanho, podendo ser analisados com ferramentas simples. Ao contrário dos dados nos sistemas tradicionais, que eram na sua maioria estruturados, hoje a maioria dos dados é não estruturada ou semiestruturada.
Estimativas indicam que até 2020, mais de 80% dos dados serão desestruturados.
Esses dados são gerados de diferentes fontes, como registros financeiros, arquivos de texto, formulários, sensores e instrumentos.
Ferramentas simples não são capazes de processar esse enorme volume e variedade de dados. É por isso que precisamos de soluções mais complexas e algoritmos analíticos avançados para processar, analisar e extrair insights significativos.
No entanto, esta não é a única razão pela qual Data Science se tornou tão popular e relevante.
E se você pudesse entender exatamente o que os seus clientes precisam a partir dos dados existentes, como histórico de navegação, histórico de compras, idade e renda, sem dúvida, você já teria todos esses dados antes.
Mas agora é possível treinar modelos com mais eficácia e recomendar o produto aos seus clientes com mais precisão a partir da grande quantidade e variedade de informações disponíveis. Incrível, certo?
Vamos imaginar um cenário futurista para entender o papel da Ciência de Dados na tomada de decisões.
E se o seu carro tivesse inteligência para levá-lo para casa? Os carros autônomos coletam dados ao vivo de sensores, radares, câmeras e lasers, para criar um mapa dos arredores.
Com base nesses dados, ele toma decisões sobre quando acelerar, quando diminuir, quando ultrapassar e onde fazer uma curva, usando algoritmos avançados de Machine Learning.
Data Science também pode ser usada em modelos de análises preditivas. Vamos pegar a previsão do tempo como um exemplo.
Dados de navios, aeronaves, radares, satélites podem ser coletados e analisados para construir modelos. Esses modelos não apenas preveem o clima, mas também ajudam a prever a ocorrência de quaisquer calamidades naturais. Isso ajudará você a tomar as medidas apropriadas de antemão e a salvar vidas.
Agora que você entendeu a necessidade da Ciência de Dados, vamos entender o que é, de fato, Data Science.
Data Science é uma mistura de várias ferramentas, algoritmos e princípios de aprendizado de máquina com o objetivo de descobrir padrões ocultos a partir dos dados brutos. Como isso é diferente do que os estatísticos vêm fazendo há anos? A resposta está na diferença entre explicar e prever.
Um analista de dados geralmente explica o que está acontecendo ao processar o histórico dos dados. Por sua vez, um Data Scientist não só faz a análise exploratória para descobrir padrões relevantes a partir dela, mas também usa vários algoritmos avançados de Machine Learning para identificar a ocorrência de um evento particular no futuro.
Um cientista de dados examinará os dados de muitos ângulos — em muitos casos, abordagens que não eram possíveis anteriormente.
Portanto, a Data Science é usada principalmente para tomar decisões e prever cenários que usam a análise causativa preditiva, a análise prescritiva (ciência preditiva somada à decisão) e o aprendizado de máquina (Machine Learning).
Análise causativa preditiva
Se você quiser um modelo que possa prever as possibilidades de um determinado evento no futuro, será necessário aplicar a análise causativa preditiva.
Se uma empresa tem seu modelo de negócios estruturado em torno da concessão de empréstimos, então a probabilidade de os clientes fazerem pagamentos desse crédito em dia é motivo de preocupação constante para essa empresa.
Com a análise causativa preditiva, é possível criar um modelo que possa executar análises no histórico de pagamento dos clientes para prever se os pagamentos futuros serão pontuais ou não.
Análise prescritiva
Se você quiser um modelo que tenha a inteligência de tomar suas próprias decisões e a capacidade de modificar essas decisões com parâmetros dinâmicos, certamente precisará de uma análise prescritiva.
Esse campo relativamente novo está relacionado com a previsão e sugestão de uma gama de ações prescritas e resultados associados.
O melhor exemplo disso é o carro autônomo do Google. Os dados recolhidos pelos veículos podem ser usados para treinar outros carros autônomos. Além disso, você pode executar algoritmos nesses dados para adicionar inteligência a eles.
Isso permitirá que seu carro tome decisões como quando virar, qual caminho tomar, quando desacelerar ou estacionar.
Machine Learning
Se você tiver dados de uma empresa financeira e precisar criar um modelo para determinar as tendências para negociações futuras, os algoritmos de aprendizado de máquina serão a melhor opção.
Isso se enquadra no conceito de Machine Learning Supervisionado, porque você já tem os dados com base nos quais pode treinar suas máquinas.
Por exemplo, um modelo de detecção de fraude pode ser treinado, usando-se um registro do histórico de fraudes em um determinado período.
Se você não tiver os parâmetros com base nos quais pode fazer previsões, precisará descobrir os padrões ocultos no conjunto de dados para poder fazer previsões significativas.
Este é o modelo de Machine Learning Não Supervisionado, pois você não tem rótulos predefinidos para agrupamento.
Agora que você conhece as principais características e funções da Data Science, vamos abordar como a Python tem revolucionada o modo como as organizações e a academia têm aplicado a ciência de dados nos mais variados campos.
Python: perfeita para Data Science
A Python tem um atributo único entre outras linguagens de programação: é fácil de usar quando se trata de computação quantitativa e analítica. É a linguagem líder do setor há algum tempo e está sendo amplamente utilizada em vários campos, como petróleo e gás, processamento de sinal, finanças e outros.
Além disso, a Python foi usada para fortalecer a infraestrutura interna do Google e para criar aplicativos como o YouTube.
Python é amplamente utilizado por ser uma linguagem flexível e de código aberto.
Suas enormes bibliotecas são usadas para manipulação de dados e são muito fáceis de aprender, mesmo para um analista de dados iniciante.
Além de ser uma plataforma independente, também se integra facilmente a qualquer infraestrutura existente que possa ser usada para resolver os problemas mais complexos.
A maioria dos bancos e instituições financeiras usa Python para processar dados; instituições acadêmicas e centros de pesquisa usam a linguagem para visualização e processamento de informações; empresas de previsão do tempo, de construção de modelos financeiros e corretoras de seguros também a usam.
Mas, você deve estar se perguntando: afinal, por que a Python é a preferida em relação a outras ferramentas de ciência de dados?
Poderosa e fácil de usar
Python é considerada uma linguagem para iniciantes e qualquer aluno ou pesquisador com conhecimento básico pode começar a trabalhar com ela. O tempo gasto em códigos de depuração e em várias restrições de engenharia de software também é minimizado.
Em comparação com outras linguagens de programação, como C, Java e C #, o tempo para implementação de código é menor, o que ajuda desenvolvedores e engenheiros de software a dedicar mais tempo para trabalhar em seus algoritmos.
Opções de bibliotecas
Python fornece um banco de dados massivo de bibliotecas para inteligência artificial e aprendizado de máquina. Algumas das bibliotecas mais populares incluem Scikit Learn, TensorFlow, Seaborn, Pytorch, Matplotlib, Pandas e muito mais.
Muitos tutoriais e recursos de ciência de dados e aprendizado de máquina estão disponíveis on-line e podem ser acessados facilmente.
Escalabilidade
Em comparação a outras linguagens de programação, como R, Python se mostrou como uma linguagem altamente escalável e mais rápida. Ela fornece flexibilidade para resolver problemas que não podem ser resolvidos usando outras linguagens de programação.
Muitas empresas a utilizam para desenvolver aplicativos e ferramentas rápidas para os mais variados cenários.
Visualização e gráficos
Existem várias opções de visualização disponíveis utilizando Python. Sua biblioteca Matplotlib fornece uma base sólida em torno da qual outras bibliotecas como Plotly, Seaborn e outras são construídas.
Esses pacotes ajudam a criar tabelas, gráficos prontos para a web, layouts gráficos, entre outros tipos de visualização.
Como Python é usada em cada estágio da Data Science?
A primeira fase
Em primeiro lugar, precisamos saber e entender que tipo de formulário é um dado relevante. Se considerarmos os dados como uma enorme planilha de Excel, com milhares de linhas e colunas, você sabe o que fazer com ela?
Você precisa obter informações úteis executando algumas funções e procurando um tipo específico de dados em cada linha e coluna. Completar esse tipo de tarefa pode consumir muito tempo e trabalho duro, mas você pode usar as bibliotecas Python como Pandas e Numpy para executar rapidamente o trabalho usando o processamento paralelo.
A segunda fase
O próximo obstáculo é extrair os dados necessários. Como os dados nem sempre estão disponíveis imediatamente, precisamos coletar dados da Web. Aqui as bibliotecas Python Scrapy e do BeautifulSoup podem ajudar a extrair dados da internet de forma simples e rápida.
A terceira fase
Nesse estágio, precisamos obter a visualização ou representação gráfica dos dados, mas pode ser difícil extrair as informações de que você precisa com tantos números na tela.
A melhor maneira de fazer isso é representar os dados como gráficos. Para executar essa função, são utilizadas as bibliotecas Seaborn e Matplotlib.
A quarta fase
O próximo passo é o aprendizado de máquina, que é uma técnica computacional altamente complexa. Envolve ferramentas matemáticas como funções de probabilidade, cálculo e matrizes avançadas.
Tudo isso pode se tornar superfácil e eficiente usando a biblioteca de aprendizado de máquina Scikit-Learn.
Todas as etapas discutidas foram de dados na forma de texto, mas, e se estiverem na forma de imagens?
Python está bem equipada para lidar com esse tipo de operação também. Existe uma biblioteca open source chamada opencv que é dedicada apenas ao processamento de imagens e vídeos.
Explicando a popularidade do Python em grupos e comunidades de Data Science
A alta compatibilidade e sua sintaxe fácil de usar a tornam a linguagem mais popular nas comunidades e grupos de Data Science, e aqueles que não têm experiência em engenharia e ciências podem aprender a codificar em um curto espaço de tempo.
Python é mais adequada para prototipagem e aprendizado de máquina, e existem muitas opções de cursos on-line adequados para iniciantes. A versatilidade e facilidade de compreensão fazem do Python a ferramenta mais procurada pelas grandes organizações em um profissional de Data Science.
Os cientistas e engenheiros de Machine Learning também preferem Python para criar aplicativos e ferramentas, como análise de sentimento e o processamento de linguagem natural.
Gostou do nosso artigo? Então descubra outros interessantes no nosso blog!
E não perca a oportunidade de assinar a nossa lista de e-mail para continuar atualizado sobre as principais novidades do mundo da Data Science.
Me fale também o que achou do artigo nos comentários abaixo, será um prazer interagir com você!
O profissional que atua em Ciência de Dados tem sido cada vez mais demandado pela indústria de tecnologia, à medida que mais empresas realizam a chamada transformação digital.
Mas, afinal, o que um cientista de dados precisa saber? Além de conhecimentos em programação, ele precisa saber criar modelos estatístico e ter o conhecimento e domínio apropriado de negócios. Precisa ainda compreender as diferentes plataformas de Big Data e como elas funcionam.
Criatividade também é uma habilidade necessário ao cientista de dados, pois ele deverá construir gráficos bonitos e informativos, com boa visualização e que possam ser compreendidos pelos clientes. A formação em ciência de dados é multidisciplinar e nunca acaba. A boa notícia é que você pode se especializar sem sair de casa.
Confira abaixo algumas opções de qualificação gratuita na área indicadas pela gerente responsável pela Escola de Data Science e AI da Udacity, Ana Romeo.
O profissional aprenderá com um instrutor da Harvard University quais são os princípios de visualização de dados para comunicar resultados de forma precisa, motivar análises e detectar falhas.
Quem oferece: edX
Preço: gratuito ou $49,00 para adquirir o certificado
Ao longo de quatro semanas, o curso apresentará quais as principais ideias e ferramentas nas quais se baseiam essa área de atuação. Os exercícios práticos envolvem linguagens e frameworks como markdown, git, GitHub, R e RStudio
O curso ensinará como manipular dados, trabalhar com big data e realizar uma comunicação clara a partir da visualização de informações, possibilitando que o aluno experimente e aplique as técnicas básicas da ciência de dados.
Esse conjunto de ferramentas de Business Analytics fornece insights para empresas e tomadores de decisão. O curso ensina a produzir relatórios profissionais e a publicá-los para consumo online (web e mobile), além de explicar como criar dashboards personalizados.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade