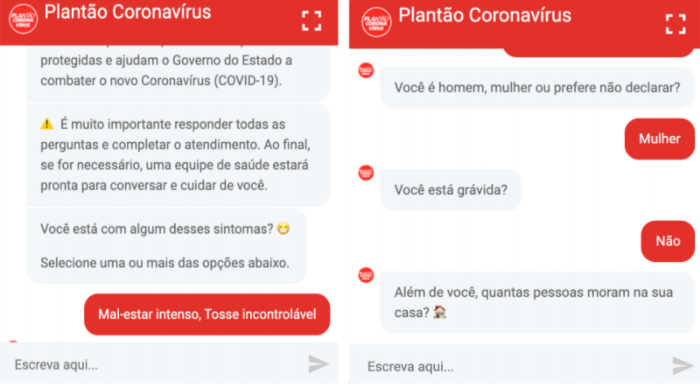
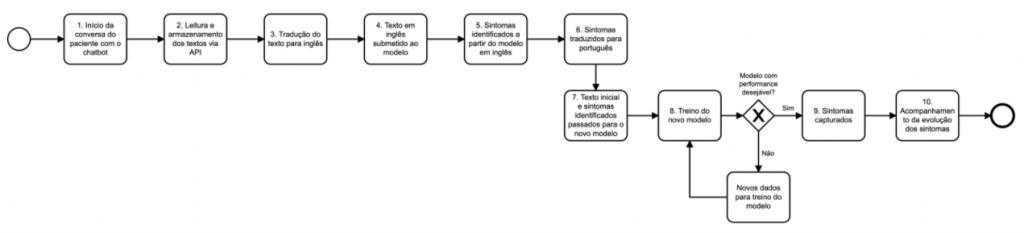
Atualmente, grandes organizações estão investindo em análise preditiva e testando opções que sejam capazes de gerar eficiência de negócios e novas maneiras de lidar com seu público.
Partindo da ideia de que os dados são a nova riqueza mundial, saber refiná-los e transformá-los em informação será a chave para alavancar seu potencial.
Se você quer entender o que Machine Learning faz, o melhor é aprender na prática através de uma série de projetos já disponíveis. Veja aqui, 9 projetos de ML que o Insight selecionou no Kaggle para você aprender e se inspirar.
01 Previsão de Preço de Imóvel
Diariamente, pessoas no mundo todo compram e vendem imóveis. Mas como saber qual o melhor preço para esta categoria de produto? Como saber se o valor oferecido é justo? Neste projeto, é proposto um modelo de Machine Learning para prever o preço de uma casa baseado em dados como tamanho, ano de construção, entre outros. Durante o desenvolvimento e avaliação desse modelo, você verá o código usado para cada etapa seguido de sua saída. Este estudo utilizou a linguagem de programação Python.
02 Reconhecimento de gênero por voz
O reconhecimento de gênero permite a uma empresa fazer sugestões de produtos ou serviços de maneira mais personalizada aos seus usuários. Neste projeto o banco de dados foi criado para identificar uma voz como masculina ou feminina, com base nas propriedades acústicas da voz e da fala.
O conjunto de dados consiste em 3.168 amostras de voz gravadas, coletadas de homens e mulheres. As amostras de voz são pré-processadas por análise acústica em R usando os pacotes seewave e tuneR, com uma faixa de frequência analisada de 0hz-280hz (faixa vocal humana).
03 Detecção de email spam
Com o crescimento da internet, o meio digital incentivou diversas práticas ruins como o email spam. Aparentemente, ele é uma parte inseparável da experiência na web, algo que aceitamos como normal, mas que é preciso combater e para isso surgiu a detecção de emails spam.
Neste projeto você irá encontrar um arquivo CSV contendo informações relacionadas de 5172 arquivos de email escolhidos aleatoriamente e seus respectivos rótulos para classificação de spam ou não spam. As informações sobre todos os 5172 emails estão armazenadas em um dataframe compacto, em vez de arquivos de texto separados.
04 Análise de Dados da Uber
Neste projeto de análise de dados do aplicativo Uber, o conjunto de dados são de viagens de passageiros que partem de um ponto A para um ponto B. O valor da viagem é calculado no momento da solicitação de forma automática pelo aplicativo, considerando distância, tempo estimado de viagem e disponibilidade atual do carro.
Terminada a viagem, é cobrado no cartão de crédito do passageiro e transferido uma porcentagem desse valor para a conta do motorista. Finalmente, antes de iniciar uma corrida, a viagem pode ser cancelada pelo motorista ou pelo passageiro.
A análise descritiva dos dados irá responder perguntas relacionadas a quantidade de passageiros e motoristas, quanto será o custo de uma viagem, quem são os melhores passageiros e os piores motoristas, entre outros questionamentos.
05 Detecção de Fraude com Cartão de Crédito
Em contrapartida ao surgimento do e-commerce e a facilidade de meios de pagamento e transações bancárias totalmente online, houve um aumento significativo nas fraudes com cartão de crédito. As operadoras de cartão passaram a dar mais importância a sistemas que possam detectar transações fraudulentas, para preservar seus clientes.
Este projeto contém transações realizadas com cartões de crédito em setembro de 2013 por portadores de cartões europeus, com intuito de analisar as transações fraudulentas.
06 Sistemas de Recomendação de Filme
Os sistemas de recomendação fazem com que o processo de recomendação natural do ser humano ganhe uma maior versatilidade, de modo que venha a atender digitalmente as demandas e necessidades das pessoas que procuram por algo.
O projeto analisa dados de filmes e sistemas de recomendação. Nele você verá algumas implementações de algoritmos de recomendação (baseado em conteúdo, popularidade e filtragem colaborativa) e também a construção de um conjunto desses modelos para chegar ao sistema de recomendação final.
07 Análise de Sentimento no Twitter
A análise de sentimentos é uma mineração contextual de um texto que identifica e extrai informações subjetivas no material de origem. Ela ajuda as empresas a entenderem o sentimento social de sua marca, produto ou serviço.
Segundo os criadores deste conjunto de dados, sua abordagem foi única porque os dados de treinamento foram criados automaticamente, ao invés de anotações humanos. Nesta abordagem, foi presumido que qualquer tuíte com emotions positivos, era positivo, e tuítes com emotions negativos, foram negativos.
08 Predição de Câncer de Mama
Em um processo de extração de informações dos dados, existe a técnica de Mineração de Dados, que visa explorar grandes quantidades de dados com o intuito de encontrar padrões relevantes e consistentes no relacionamento entre os atributos (basicamente, colunas de tabelas) dessas bases de dados.
Uma das primeiras técnicas desenvolvidas nesse sentido foi o KDD (Knowledge Discovery in Database), desenvolvido durante o final da década de 1980. A extração de conhecimento a partir de uma base de dados é dividida em: coleta de dados, tratamento dos dados e resultado final (transformação dos dados em informações e posteriormente em conhecimento).
Neste projeto, pode-se entender as fases do KDD (Knowledge Discovery in Database) para uma base de dados na qual existe uma série de atributos de análise de imagens de células na região do câncer feitos com ultrassonografia para prever se um câncer de mama é benigno ou maligno.
Após a extração dos dados da plataforma Kaggle, foi realizado um pré-processamento para garantir que os dados lidos e interpretados sejam relevantes para o processo de extração de conhecimento.
Em seguida, foi implementada a transformação dos dados, através do algoritmo KNN (K-Nearest Neighbors). Por fim, foram feitas as previsões a partir de novos dados, isto é, após o aprendizado realizado pelo algoritmo KNN sobre a base de dados, novas entradas de dados buscaram classificar se uma nova entrada de fotos de células seria um câncer benigno ou maligno, baseado no aprendizado anterior.
09 Análise estatística e fluxo de trabalho
Este projeto é para todos os aspirantes a cientistas de dados aprenderem e revisarem seus conhecimentos através de uma análise estatística detalhada do conjunto de dados do Titanic com a implementação do modelo ML.
Os objetivos principais deste trabalho são:
- fazer uma análise estatística de como alguns grupos de pessoas sobreviveram mais do que outros;
- fazer uma análise exploratória de dados (EDA) do titanic com visualizações e contação de histórias;
- prever com o uso de ML as chances de sobrevivência dos passageiros.
10 Previsão de preços de ações
Se você gosta de trabalhar com dados financeiros, este projeto pode ser interessante para você. O objetivo deste projeto é prever os preços futuros das ações aprendendo com o desempenho de uma empresa.
Neste projeto serão explorados dados do mercado de ações, em particular ações de tecnologia. Ele apresenta como usar o Pandas para obter informações sobre ações, visualizar seus diferentes aspectos e, por fim, algumas maneiras de analisar o risco de uma ação com base em seu histórico de desempenho anterior. Além disso tudo, será abordado a previsão dos preços futuros de ações por meio do método Long Short Term Memory (LSTM).
No kaggle, você também encontra outros excelentes projetos como estes, disponíveis para aprendizagem e competições com outros cientistas de dados, engenheiros de Machine Learning e curiosos da área. Aprender com profissionais e ter acesso à base de dados para treinar suas habilidades, além de participar de competições, trará a você cada vez mais segurança em sua formação.
Gostou da nossa seleção? Se você tem o seu próprio projeto ou quer indicar outro, compartilha aqui conosco!