O Insight, que possui um trabalho incessante de pesquisa e desenvolvimento na área de ciência de dados e inteligência artificial, recentemente teve uma de suas aplicações premiadas em concurso. O Módulo de Participação Cidadã do aplicativo Sinesp Cidadão, do Ministério da Justiça e Segurança Pública, foi premiado no IV Concurso de Boas Práticas da Rede Nacional de Ouvidorias, promovido pela Controladoria-Geral da União (CGU). A premiação corresponde à categoria Tecnologia, Segurança da Informação e Proteção de Dados Pessoais.
Nosso laboratório
Coordenado por José Macêdo, Cientista-chefe na área de Dados da Transformação Digital do Governo do Ceará e professor associado do Departamento de Computação da Universidade Federal do Ceará (UFC), o Insight Lab atualmente trabalha no desenvolvimento de 12 soluções tecnológicas para o Ministério da Justiça e Secretaria Nacional de Segurança Pública através do Projeto Sinesp Big Data.
O Produto
A ferramenta premiada do aplicativo Sinesp Cidadão foi idealizada pela Ouvidoria-Geral do Ministério da Justiça e Segurança Pública e desenvolvida pela parceria entre a UFC, através do laboratório Insight Lab, e a Secretaria Nacional de Segurança Pública – SENASP. O Módulo de Participação Cidadã é um instrumento para receber e tratar manifestações que possam contribuir nas atividades de prevenção às ocorrências locais na área de segurança pública, especialmente nas cinco cidades do Projeto Piloto do Programa “Em Frente Brasil”.
Trata-se de um módulo dentro do aplicativo Sinesp Cidadão, que cadastra manifestações de ouvidoria diretamente no banco de dados da Plataforma Fala.br, através de API (Application Programming Interface).
A ferramenta possui 11 categorias de reclamação:
Vandalismo;
Equipamento Público Danificado;
Perturbação do Sossego;
Construção Irregular;
Descumprimento das Leis de Trânsito;
Veículo Abandonado;
Descarte Irregular de Lixo e Entulho;
Iluminação Pública;
Comércio Irregular;
Saúde Pública;
Escola sem Estrutura.
Quem pode utilizar
O serviço pode ser utilizado por qualquer cidadão que possua login único no gov.br. O download do aplicativo pode ser realizado na Play Store e na Apple Store.
A visualização do Módulo de Participação Cidadã está disponível aos usuários que residem nas cidades cobertas pelo programa “Em Frente Brasil”. Através deste canal é possível encaminhar reclamações diretamente à Ouvidoria-Geral do Ministério da Justiça e Segurança Pública, que as encaminha aos órgãos competentes.
Histórico da ferramenta
Durante o ano de 2019 o Ministério da Justiça e Segurança Pública iniciou o Projeto Piloto do Programa “Em Frente Brasil”. Dentro do eixo de prevenção social, foi prevista a realização de um Diagnóstico Local de Segurança – DLS nas cinco cidades do projeto piloto.
Para apoiar a iniciativa, foi idealizada a inclusão do aplicativo Participação Cidadã como um módulo dentro do Sinesp Cidadão, o qual estava em fase de desenvolvimento de uma nova versão pelo Insight.
O módulo, como citado antes, cadastra 11 tipos de incidentes de segurança pública e os direciona para a Ouvidoria-Geral do Ministério da Justiça e Segurança Pública, via Plataforma Fala.br. As demandas são remetidas aos entes federados responsáveis, por meio do Fórum Nacional de Ouvidores do Sistema Único de Segurança Pública – Fnosp.
A definição dos incidentes de segurança pública seguiu as diretrizes da teoria da Ecologia Criminal da Escola de Chicago, sendo tratados pelo canal da ouvidoria.
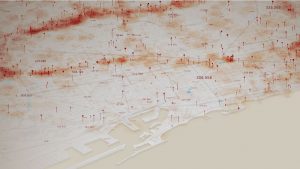
É possível plotar a localização do fato em um mapa de calor, visando a identificação dos problemas mais recorrentes em cada região, para adoção de ações preventivas. Também é possível consultar o histórico do tratamento dado às manifestações realizadas.
Importante destacar que o Módulo de Participação Cidadã abre possibilidade para colaboração efetiva dos próprios agentes de segurança pública, que já utilizam outras funcionalidades do aplicativo.
Aproximação com o cidadão
O Módulo de Participação Cidadã visa aproximar o cidadão das políticas e ações de segurança pública, de forma a resguardar a ordem pública e zelar por sua própria segurança e a das demais pessoas em apoio ao Estado, que detém protagonismo do tema, mas não é o único ator.
Muito se fala sobre a grande procura das empresas por cientistas de dados e os excelentes salários reservados a esses profissionais. Mas quem pode receber esse título, quais habilidades tornam os cientistas de dados tão requisitados e ainda raros no mercado de trabalho?
Para conhecer quais competências você deve desenvolver para se tornar um cientista de dados, e entender que este não é um processo de apenas 6 meses, trazemos aqui a lista produzida por Daniel D. Gutierrez sobre as 10 habilidades essenciais de ciência de dados em 2021.
Gutierrez é cientista de dados, autor de quatro livros de data science, jornalista de tecnologia e professor, tendo ministrado aulas de ciência de dados, aprendizado de máquina (machine learning) e R em nível universitário.
1. Experiência com GPUs
Agora é a hora de entender a grande popularidade das GPUs. A maneira mais fácil de começar a usar GPUs para aprendizado de máquina é começar com um serviço de GPU em nuvem. Aqui está uma pequena lista de opções que podem ser adequadas às suas necessidades:
Colab – Google Colaboratory, ou “Colab” para abreviar, é um produto do Google Research. O Colab permite que qualquer pessoa escreva e execute código Python arbitrário por meio do navegador, e é especialmente adequado para aprendizado de máquina. Especificamente, o Colab é um serviço de nuvem gratuito hospedado pelo Google que usa o Jupyter Notebook, ou seja, que não requer instalação para uso, ao mesmo tempo que fornece acesso a recursos de computação, incluindo GPUs.
Kaggle – Kaggle (propriedade do Google) fornece acesso gratuito às GPUs NVIDIA TESLA P100. Essas GPUs são úteis para treinar modelos de aprendizado profundo (deep learning), no entanto, não aceleram a maioria dos outros fluxos de trabalho, como bibliotecas Python, Pandas e Scikit-learn. Você pode usar um limite de cota por semana de GPU. A cota é restabelecida semanalmente e é de 30 horas ou às vezes mais, dependendo da demanda e dos recursos.
NVIDIA NGC – O catálogo NGC ™ é um hub para software otimizado por GPU para deep learning, machine learning e computação de alto desempenho que acelera a implantação para fluxos de trabalho de desenvolvimento para que cientistas, desenvolvedores e pesquisadores possam se concentrar na construção de soluções, coleta de insights e entrega de valor comercial.
Cloud GPUs no Google Cloud Platform – GPUs de alto desempenho no Google Cloud para aprendizado de máquina, computação científica e visualização 3D.
2. Visualização de dados criativa e storytelling de dados
A visualização de dados, juntamente com o storytelling de dados, continua sendo uma habilidade importante a ser cultivada por todos os cientistas de dados. Essa etapa integra o processo de ciência de dados e é uma habilidade que diferencia os cientistas de dados de seus colegas engenheiros de dados. Os cientistas de dados assumem a importante função de interagir com os responsáveis pelo projeto ao entregar os resultados de um trabalho de data science.
Além dos tradicionais relatórios e resultados numéricos, uma visualização de dados atraente e bem pensada é a melhor maneira de mostrar os resultados provenientes de um algoritmo de aprendizado de máquina. Além disso, é também um ingrediente básico do estágio final do storytelling de dados do projeto, onde o cientista de dados se esforça para chegar a uma descrição concisa e não técnica dos resultados, onde as principais descobertas são facilmente compreendidas.
Para quem sente dificuldade nesta parte, como no trabalho com elementos mais criativos e visuais, sempre procure por novas técnicas de visualização de dados usando pacotes R recém-descobertos e bibliotecas Python para tornar o resultado mais atraente.
3. Python
Para Gutierrez, é difícil ignorar o Python, pois a maioria dos bons artigos de blog e materiais de aprendizagem usam esta linguagem. Por exemplo, a maioria dos documentos de aprendizagem profunda que aparecem no arXiv referem-se a repositórios GitHub com código Python usando estruturas como Keras, TensorFlow e Pytorch, e quase tudo que acontece no Kaggle envolve Python.
Ainda de acordo com o autor, o R costumava ter a vantagem com os 16.891 pacotes disponíveis para complementar a linguagem base, mas o Python afirma ter uma ordem de magnitude maior do que essa. Um conhecimento robusto de Python é uma habilidade de ciência de dados importante para se aprender.
4. SQL
SQL é uma ótima linguagem de consulta de dados, mas não é uma linguagem de programação de propósito geral. É fundamental que todo cientista de dados seja proficiente em SQL. Muitas vezes, seus conjuntos de dados para um projeto de ciência de dados vêm diretamente de um banco de dados relacional corporativo. Portanto, o SQL é seu canal para adquirir dados. Além disso, você pode usar SQL diretamente em R e Python como uma ótima maneira de consultar dados em um quadro de dados.
5. GBM além de Deep Learning
A IA e o aprendizado profundo continuam no topo do “hype cycle” do setor, e certamente 2021 não será diferente. O aprendizado profundo é a ferramenta perfeita para muitos domínios de problemas, como classificação de imagens, veículos autônomos, PNL e muitos outros. Mas quando se trata de dados tabulares, ou seja, dados típicos de negócios, deep learning pode não ser a escolha ideal. Em vez disso, o GBM (Gradient Boosted Machines) é o algoritmo de aprendizado de máquina que geralmente atinge a melhor precisão em dados estruturados / tabulares, superando outros algoritmos, como as tão faladas redes neurais profundas (deep learning). Alguns dos principais GBMs incluem XGBoost, LightGBM, H2O e catboost.
6. Transformação de dados
Muitas vezes, é mencionado em voz baixa quando os cientistas de dados se encontram: o processo de data munging (também conhecido como data wrangling, transformação de dados) leva a maior parte do tempo e do orçamento de custos de um determinado projeto de ciência de dados.
Transformar dados não é o trabalho mais atraente, mas acertar pode significar sucesso ou fracasso com o aprendizado de máquina. Para uma tarefa tão importante, um cientista de dados deve certificar-se de agregar à sua caixa de ferramentas de ciência de dados código que atenda a muitas necessidades comuns. Se você usa R, isso significa usar dplyr e, se você usa Python, então Pandas é sua ferramenta de escolha.
7. Matemática e estatística
Manter um conhecimento sólido dos fundamentos dos algoritmos de aprendizado de máquina requer uma base em matemática e estatística. Essas áreas são normalmente deixadas por último no esforço de aprendizado de muitos cientistas de dados, isso porque matemática / estatística podem não estar em sua lista pessoal de atualização. Mas um entendimento elementar dos fundamentos matemáticos do aprendizado de máquina é imprescindível para evitar apenas adivinhar os valores dos hiperparâmetros ao ajustar algoritmos.
As seguintes áreas da matemática são importantes: cálculo diferencial, equações diferenciais parciais, cálculo integral (curvas AUC-ROC), álgebra linear, estatística e teoria da probabilidade. Todas essas áreas são importantes para entender como funcionam os algoritmos de aprendizado de máquina.
Um objetivo de todos os cientistas de dados é ser capaz de consumir “a bíblia do aprendizado de máquina”, “Elements of Statistical Learning”, de Hastie, Tibshirani e Friedman. Esse é um daqueles livros que você nunca termina de ler.
Para atualizar sua matemática, verifique o conteúdo do OpenCourseWare do professor Gilbert Strang do MIT.
8. Realização de experimentos com os dados
Busque novos conjuntos de dados e experimente, experimente e experimente! Os cientistas de dados nunca conseguem praticar o suficiente trabalhando com fontes de dados desconhecidas. Felizmente, o mundo está cheio de dados. É apenas uma questão de combinar suas paixões (ambientais, econômicas, esportivas, estatísticas de crime, o que for) com os dados disponíveis para que você possa realizar as etapas do “processo de ciência de dados” para aprimorar suas habilidades. A experiência que você ganha com seus próprios experimentos com dados o ajudará profissionalmente no futuro.
9. Conhecimento especializado
Um consultor independente de ciência de dados pode trabalhar em todos os tipos de projetos interessantes em um amplo espectro de domínios de problemas: manufatura, sem fins lucrativos, educação, esportes, moda, imóveis, para apenas mencionar alguns.
Então, quando se tem um novo cliente de um novo setor, é fundamental aumentar rapidamente seu conhecimento na área desde o início. Falar com pessoas da organização do cliente que são especialistas no assunto, analisar as fontes de dados disponíveis, ler tudo que possa encontrar sobre o assunto, incluindo white papers, postagens em blogs, periódicos, livros, artigos de pesquisa; tudo isso em uma tentativa de começar a todo vapor.
10. Aprendizado de máquina ético
O professor Gutierrez apresenta aos seus alunos uma lista de casos em que cientistas de dados foram solicitados a usar suas habilidades para fins nefastos.
“Falo a eles sobre os cientistas de dados que desenvolvem tecnologia para criar imagens e vídeos ‘deep fake’ indetectáveis. Conto a eles a vez em que testemunhei um gerente de ciência de dados de uma grande empresa pública de jogos que disse a uma multidão em um encontro que ele e sua equipe trabalharam com psicólogos para descobrir maneiras de viciar crianças em seus jogos. E eu falo sobre Rebekah Jones, a cientista de dados do estado da Flórida que se recusou a adulterar os dados do COVID-19 para fazer a situação da saúde pública do estado parecer melhor.”
Se você deseja se tornar um profissional de ciência de dados ético, pense no futuro. Saiba desde já que em sua carreira, provavelmente, surgirão situações nas quais você precisará se posicionar contra o uso de suas habilidades para prejudicar outras pessoas. Olhando para 2021, o clima político pode estar propício para tais dilemas.
O Insight indica hoje uma leitura para quem está procurando conhecer sobre limpeza de códigos. Código Limpo: Habilidades Práticas do Agile Software é uma obra bem avaliada, indicada por especialistas e o melhor, com versão em português. Como destacado nas críticas dos usuários, a obra possui leitura agradável e provoca a mudança do seu entendimento em relação aos códigos. Se você é iniciante, sinta-se encorajado a este mergulho.
Um código ruim pode funcionar? Sim, mas se ele não for limpo, pode acabar comprometendo todo um projeto. Um código mal escrito demanda um tempo considerável dos desenvolvedores para resolver problemas de programação, ao invés de se dedicarem a inovações. Porém, isso pode ser resolvido se você tiver interesse em aprender sobre códigos limpos com quem domina o assunto.
O Livro
O célebre especialista em software, Robert C. Martin, apresenta um paradigma revolucionário com o livro Código Limpo: Habilidades Práticas do Agile Software. Martin se reuniu com seus colegas do Mentor Object (equipe de consultores experientes) para divulgar suas melhores e mais ágeis práticas de limpar códigos “dinamicamente” em um obra que apresentará gradualmente os valores necessários a um profissional de software, assim como, pode transformá-lo em um programador melhor. Mas lembre-se, é preciso muita prática.
O que você vai encontrar
Nesta obra você lerá muitos códigos. Isso lhe ajudará a entender o que está correto e errado neles. Além disso, te dará um incentivo para reavaliar seus valores profissionais e seu comprometimento com o seu trabalho.
Divisão do conteúdo
Código Limpo está dividido em três partes com 17 capítulos ao todo. Na 1ª parte há diversos capítulos que descrevem os princípios, padrões e práticas para criar um código limpo.
A 2ª parte consiste em diversos casos de estudo de complexidade cada vez maior. Cada um é um exercício para limpar um código – transformar o código base que possui alguns problemas em um melhor e mais eficiente.
A 3ª parte é a compensação: um único capítulo com uma lista de heurísticas
reunidas durante a criação dos estudos de caso. O resultado será um conhecimento base que descreve a forma como pensamos quando criamos, lemos e limpamos um código.
O que você aprenderá com este livro
Após ler este livro os leitores saberão:
✔ Como distinguir um código bom de um ruim
✔ Como escrever códigos bons e como transformar um ruim em um bom
✔ Como criar bons nomes, boas funções, bons objetos e boas classes
✔ Como formatar o código para ter uma legibilidade máxima
✔ Como implementar completamente o tratamento de erro sem obscurecer a lógica
✔ Como aplicar testes de unidade e praticar o desenvolvimento dirigido a testes
Esta leitura é essencial para qualquer desenvolvedor, engenheiro de software, gerente de projeto, líder de equipes ou analistas de sistemas com interesse em construir códigos melhores.
Sobre o autor
Robert C. “Tio Bob” Martin é profissional de softwares desde 1970 e consultor internacional de software desde 1990. Ele é o fundador e o presidente da Mentor Object, Inc., uma equipe de consultores experientes que orientam seus clientes no mundo todo em C++, Java, C#, Ruby, OO, Padrões de Projeto, UML, Metodologias Agile e Xtreme Programming.
Concluindo
Este livro não promete lhe transformar no melhor programador ou lhe dar a “sensibilidade ao código”. Tudo o que ele pode fazer é lhe mostrar a linha de pensamento de bons programadores e os truques, técnicas e ferramentas que eles usam.
Assim como um livro sobre arte está cheio de obras, Código Limpo está repleto de códigos. Você irá se deparar com códigos bons e ruins; código ruim sendo transformado em bom; listas de heurísticas, orientações e técnicas e também exemplo após exemplo. Depois disso, é por sua conta praticar.
? A boa leitura é garantida, então tenha um excelente aprendizado e pratique sempre!
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade