Sabe aqueles livros que você precisa ler antes de terminar a graduação? Então, para os estudantes de Estatística, um dos primeiros livros dessa lista é “Uma senhora toma chá – Como a Estatística revolucionou a ciência no século XX”, de David Salsburg.
E o título já traz história. Em uma tarde de verão em Cambridge, Inglaterra, um grupo de professores universitários e suas esposas tomavam o chá da tarde. Uma das mulheres presentes afirmava que a ordem na qual os ingredientes, leite e chá, eram colocados alterava o sabor do chá. E por isso, um dos homens presentes disse: “vamos testar a proposição”.
Esse homem era Ronald Aylmer Fisher, que, em 1935, publicou The Design of Experiments, no qual descreveu o experimento da senhora provando chá. Como resume Salsburg, “nesse livro, Fisher analisa a senhora e sua crença como um problema hipotético e considera os vários experimentos que podem ser planejados para determinar se era possível a ela notar a diferença”.
As vidas que revolucionaram a Estatística
E assim segue Salsburg nos contando a história da revolução estatística na ciência do século XX. Como afirma o autor, no final desse século, “quase toda a ciência tinha passado a usar modelos estatísticos”.
Em “Uma senhora toma chá”, David Salsburg nos convida a conhecer a história do desenvolvimento da Estatística mesclada às histórias de algumas das pessoas que protagonizaram essa ciência. Mas além da beleza da Estatística e genialidade desses estudiosos, o livro nos conta também sobre os conflitos entre esses pioneiros e sobre algumas de suas contradições.
E como escrito por Carlos Antonio Costa na revista Ciência Hoje, “os leitores que conhecem e trabalham com estatística vão adorar conhecer as histórias dos homens e mulheres que inventaram os métodos que usam em seu cotidiano de trabalho. Por exemplo, as de William Gosset (1876-1937), que inventou o teste t de Student enquanto trabalhava na cervejaria Guiness; Chester Bliss (1899-1979), inventor do modelo probit; de Jerzy Neyman (1894- 1981), que desenvolveu a matemática que explica os testes de hipótese; de W. Edwards Deming (1900-1993), que revolucionou a indústria japonesa; ou de Andrey Kolmogorov (1903-1987), o gênio matemático que desenvolveu a teoria da probabilidade”.
Sobre o autor
David Salsburg é PhD em Estatística Matemática e lecionou na University of Pennsylvania, Harvard School of Public Health, Yale University, Connecticut College e University of Connecticut. Mas antes de sua experiência docente, David trabalhou na Pfizer Central Research por 27 anos. E isso foi um marco, pois Salsburg foi o primeiro estatístico contratado pela Pfizer, assim como um dos primeiros a trabalhar para qualquer empresa farmacêutica.
Se você está sempre on-line nas redes sociais, em especial no Twitter, e não desperdiça a oportunidade de ter acesso a excelentes dicas e conteúdos, então você vai gostar do que preparamos aqui. Como você, diversos pesquisadores e cientistas também compartilham suas experiências na rede social do passarinho azul. São aprendizados, projetos, artigos e pesquisas compartilhados abertamente por cientistas de destaque no mundo e que vale a pena acompanhar o que eles têm a dizer. Confira esses perfis valiosos que selecionamos.
Professor de ciência da computação na Universidade de Oxford, Nando é especialista em Machine Learning (ML) com ênfase em redes neurais, otimização e inferência bayesiana e Deep Learning. Como cientista principal do Google DeepMind, ele ajuda a organização em sua missão de usar tecnologias para amplo benefício público e descobertas científicas, garantindo a segurança e a ética. Seu trabalho em ML lhe rendeu vários prêmios, incluindo prêmios de melhor artigo na Conferência Internacional sobre Aprendizado de Máquina e na Conferência Internacional sobre Representações de Aprendizagem, ambas em 2016.
Professora de Ciência da Computação em Stanford University e co-diretora do Human-Centered AI Institute de Stanford, Li é uma pioneira em IA, Machine Learning e neurociência cognitiva. Ela é uma escritora e pesquisadora produtiva, tendo publicado cerca de 180 artigos revisados por pares. Em 2007, como professora assistente na Universidade de Princeton, ela liderou uma equipe de pesquisadores para criar o projeto ImageNet, um enorme banco de dados visual para ser usado com um software que reconhece objetos visuais. Esse trabalho influenciou a revolução do “Deep Learning” na década seguinte. Enquanto atuava como diretora do Stanford Artificial Intelligence Lab (SAIL) de 2013 a 2018, Li cofundou a organização sem fins lucrativos AI4ALL, que se esforça para aumentar a diversidade e inclusão no campo da IA.
Bernard é autor, futurista, palestrante frequente e consultor estratégico em Percepções de Dados para empresas e governos. Ele aconselha e treina muitas das organizações mais conhecidas do mundo e foi eleito pelo LinkedIn como um dos cinco maiores influenciadores de negócios do mundo e o influenciador número 1 no Reino Unido. Ele contribui para o Fórum Econômico Mundial e é autor de muitos artigos e livros, incluindo Big Data: Using SMART Big Data, Analytics and Metrics to Make Better Decisions and Improve Performance.
Hilary fundou o Fast Forward Labs e atuou como cientista-chefe na Bitly por quatro anos. Atualmente no conselho do Instituto Anita Borg para Mulheres e Tecnologia, ela cofundou o HackNY e é membro do NYCResistor, um coletivo de hackers no Brooklyn.
Lillian é estrategista de dados, consultora e instrutora que trabalha com equipes executivas para oferecer supervisão e recomendações para operações de Engenharia e Ciência de Dados ideais. Ela se concentra na solução de problemas de negócios com várias tecnologias e métodos de dados que os empreendedores podem colocar em prática. Estrategista de dados na Data-Mania, fornece serviços de treinamento e consultoria de dados, desde 2012.
Também fundador dodeeplearning.ai, Andrew foi cientista-chefe da Baidu Research, é professor adjunto da Universidade de Stanford e fundador e presidente do conselho da Coursera, razão pela qual ele é considerado um pioneiro na educação online. Ele fundou o projeto Google Brain, que desenvolveu redes neurais artificiais em grande escala, incluindo uma que aprendeu a reconhecer gatos em vídeos. Ele é especialista em Deep Learning e publicou amplamente sobre Machine Learning e outros campos.
Kira iniciou o SalesPredict em 2012 para aconselhar os vendedores sobre como identificar e lidar com leads promissores. “Minha verdadeira paixão”, disse ela em um artigo da MIT Technology Review de 2013 , “é armar a humanidade com capacidades científicas para antecipar automaticamente e, em última instância, afetar os resultados futuros com base nas lições do passado”. Ela é considerada uma pioneira em análise preditiva, ganhou muitos prêmios e foi reconhecida em 2015 como uma estrela em ascensão da tecnologia empresarial na lista “Forbes 30 Under 30” .
Cientista-chefe de dados / CEO fundador – Sociaall Inc., Dez é um líder estratégico em negócios e transformação digital, com 25 anos de experiência nas indústrias de TI e telecomunicações, desenvolvendo estratégias e implementando iniciativas de negócios. Possui ampla experiência em tecnologias como Computação em Nuvem, Big Data e Analytics, Computação Cognitiva, Machine Learning e Internet das Coisas.
Mine é professora sênior de Estatística e Ciência de Dados na Escola de Matemática da Universidade de Edimburgo, professora associada no Departamento de Ciência estatística da Duke University e também educadora profissional e cientista de dados na RStudio. Ah, sim, e ela também é Fellow do OpenIntro.
Seu trabalho se concentra na inovação em pedagogia estatística, com ênfase na aprendizagem centrada no aluno, computação, pesquisa reprodutível e educação de código aberto. Ela também é muito ativa na educação de acesso aberto, tendo sido co-autora de três livros didáticos de estatística de código aberto como parte do projeto OpenIntro.
✔️ E essa foi mais uma seleção de primeira que o Insight fez para você seguir. Se quiser mais dicas sobre Ciência de Dados, nos acompanhe aqui e nas nossas redes sociais. Siga a ciência de dados com o Insight!
Acessar o Ted Talks é ter certeza de encontrar alguns dos melhores conteúdos disponíveis na internet sobre design, sociedade, inovação e, é claro, data science. Por isso, escolhemos os 10 melhores Ted Talks sobre campos que compõem a ciência de dados. O conjunto de palestras que lhe apresentaremos a seguir, comandados por profissionais que estão à frente do desenvolvimento e aplicação da ciência de dados, nos ajudam a aprofundar nosso conhecimento e entendimento do potencial, beleza, magnitude e responsabilidade que todos os responsáveis por essa ciência têm.
1. Como os computadores estão aprendendo a ser criativos
Estamos à beira de uma nova fronteira na arte e criatividade – e isso não é humano. Blaise Agüera y Arcas, cientista-chefe do Google, trabalha com redes neurais profundas para percepção de máquina e aprendizado distribuído. Nesta demonstração cativante, ele mostra como redes neurais treinadas para reconhecer imagens podem ser executadas ao contrário, para gerá-las. Os resultados: colagens alucinatórias espetaculares (e poemas!) que desafiam qualquer categorização. “Percepção e criatividade estão intimamente conectadas”, diz Agüera y Arcas. “Qualquer criatura, qualquer ser que é capaz de fazer atos perceptivos também é capaz de criar.”
2. Como a IA pode provocar uma segunda revolução industrial
“O caminho real percorrido por uma gota de chuva enquanto desce o vale é imprevisível, mas a direção geral é inevitável”, diz o visionário digital Kevin Kelly. E com a tecnologia acontece praticamente o mesmo, impulsionada por padrões que são surpreendentes, mas inevitáveis. Nos próximos 20 anos, diz ele, nossa tendência para tornar as coisas cada vez mais inteligentes terá um impacto profundo em quase tudo o que fazemos. Kelly explora três tendências em IA que precisamos entender para abraçá-la e orientar seu desenvolvimento. “O produto de IA mais popular daqui a 20 anos, que todo mundo usará, ainda não foi inventado”, diz Kelly. “Isso significa que você não está atrasado.”
3. Como vamos ganhar dinheiro em um futuro sem emprego
Máquinas que podem pensar, aprender e se adaptar estão chegando, e isso pode significar que nós, humanos, teremos um nível de desemprego significativo. O que devemos fazer sobre isso? Em uma conversa direta sobre uma ideia polêmica, o futurista Martin Ford defende a separação entre renda e trabalho tradicional e a instituição de uma renda básica universal.
4. A próxima revolução de software: programação de células biológicas
As células do seu corpo são como um software de computador: elas são “programadas” para realizar funções específicas em momentos específicos. Se pudermos entender melhor esse processo, poderemos, nós mesmos, desbloquear a capacidade de reprogramar células, diz a bióloga computacional Sara-Jane Dunn. Em uma palestra sobre a ciência de ponta, ela explica como sua equipe está estudando células-tronco embrionárias para obter uma nova compreensão dos programas biológicos que impulsionam a vida e desenvolver “software vivo” que pode transformar a medicina, a agricultura e a energia.
5. As incríveis invenções da IA intuitiva
O que você ganha quando dá a uma ferramenta de design um sistema nervoso digital? Computadores que melhoram nossa capacidade de pensar e imaginar, e sistemas robóticos que apresentam (e constroem) novos designs para pontes, carros, drones e muito mais, sozinhos. Faça um tour pela Augmented Age com o futurista Maurice Conti e visualize uma época em que robôs e humanos trabalharão lado a lado para realizar coisas que nenhum deles poderia fazer sozinho.
6. Podemos construir IA sem perder o controle sobre ela?
Assustado com a IA superinteligente? Você deveria estar, diz o neurocientista e filósofo Sam Harris, e não apenas de uma forma teórica. Vamos construir máquinas sobre-humanas, diz Harris, mas ainda não enfrentamos os problemas associados à criação de algo que pode nos tratar da mesma forma que tratamos as formigas.
7. Estamos construindo uma distopia apenas para fazer as pessoas clicarem nos anúncios
Estamos construindo uma distopia alimentada por inteligência artificial, um clique de cada vez, diz a tecno-socióloga Zeynep Tufekci. Em uma palestra reveladora, ela detalha como os mesmos algoritmos que empresas como Facebook, Google e Amazon usam para fazer você clicar em anúncios também são usados para organizar seu acesso a informações políticas e sociais. E as máquinas nem são a verdadeira ameaça. O que precisamos entender é como os poderosos podem usar IA para nos controlar, e o que podemos fazer em resposta.
8. 3 princípios para criar IA mais segura
Como podemos aproveitar o poder das máquinas super inteligentes e, ao mesmo tempo, prevenir a catástrofe de robôs controladores? À medida que nos aproximamos da criação de máquinas oniscientes, o pioneiro da IA, Stuart Russell, está trabalhando em algo um pouco diferente: robôs com incerteza. Ouça sua visão para IA compatível com humanos que pode resolver problemas usando bom senso, altruísmo e outros valores humanos.
9. A beleza da visualização de dados
David McCandless transforma conjuntos de dados complexos (como gastos militares mundiais, assuntos cobertos pela mídia, atualizações de status do Facebook) em diagramas bonitos e simples que revelam padrões e conexões invisíveis. Um bom design, ele sugere, é a melhor maneira de navegar por grandes conjuntos de informações, e pode mudar a maneira como vemos o mundo.
10. Como estou lutando contra o preconceito nos algoritmos
A aluna do MIT Joy Buolamwini estava trabalhando com um software de análise facial quando percebeu um problema: o software não detectou seu rosto, porque as pessoas que codificaram o algoritmo não o ensinaram a identificar uma ampla gama de tons de pele e estruturas faciais . Agora ela está em uma missão de combater o preconceito no aprendizado de máquina, um fenômeno que ela chama de “olhar codificado”. É uma palestra reveladora sobre a necessidade de responsabilidade na codificação à medida que os algoritmos assumem cada vez mais aspectos de nossas vidas.
Gostou da nossa seleção? Então conheça a nossa lista dos “10 melhores Ted Talks de tecnologia”. E você também pode deixar nos comentários outras sugestões de palestras sobre data science que merecem ser compartilhadas.
Keras é uma biblioteca aberta de Deep Learning implementada utilizando TensorFlow para diversas linguagens/plataformas, como Python e R, como foco na sua facilidade para utilização. Ela permite modelar e treinar modelos de redes neurais com poucas linhas de código, como você verá no tutorial a seguir.
Nesse tutorial, vamos utilizar o Keras para criar um modelo capaz de classificar se membros de uma população indígena possuem ou não diabetes.
Preparações
Para seguir esse projeto, você precisará ter instalados:
Python 3;
Bibliotecas SciPy e Numpy;
Bibliotecas TensorFlow e Keras;
Jupyter Notebook;
Alternativamente, você pode realizar este tutorial na plataforma Google Colab, que já possui todas as dependências instaladas e prontas para que você execute o tutorial no seu navegador.
Após isso, basta criar um novo notebook com o título “projeto_deep_learning” (ou qualquer outro nome), e iniciar o tutorial.
1. Carregando os dados
Em uma célula, importe as seguintes bibliotecas Python:
from numpy import loadtxt
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
Na célula seguinte, carregue os dados da base Pima Indians Diabetes. Essa base possui inicialmente 9 colunas, sendo as 8 primeiras as entradas e a última o resultado esperado. Todas as entradas dessa base são numéricas, assim como as saídas, o que facilita a computação dos dados por modelos de Deep Learning.
# carregue a base de dados
dataset = loadtxt('https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv', delimiter=',')
Em seguida, utilizando a funcionalidade de slice do Python, separe o conjunto de dados entre “Entradas” (X) e “Saídas” (y).
# separe os dados entre entradas (X) e saídas (y)
X = dataset[:,0:8]
y = dataset[:,8]
2. Criar o modelo utilizando Keras
Agora que nossos dados foram carregados e ajustados entre entradas e saídas, podemos definir nosso modelo utilizando a biblioteca Keras.
Modelos Keras são definidos como uma sequência de camadas. Nesse tutorial, vamos criar um modelo sequencial e adicionar uma camada de cada.
Primeiramente, precisamos garantir que a camada de entrada tem a quantidade correta de inputs de entrada. Isso pode ser especificado no Keras utilizando o argumento input_dim e o ajustando para 8, nosso número de entradas.
Para esse tutorial, vamos utilizar camadas completamente conectadas, que são definidas no Keras pela classe Dense. Esse projeto utilizará 3 camadas, as quais as duas primeiras utilizarão a função de ativação ReLU e a função Sigmoid na última. Podemos especificar o número de neurônios no primeiro argumento, e a função de ativação com o parâmetro activation.
# definir o modelo com keras
# inicializar o modelo sequencial
model = Sequential()
# inicializar a primeira camada, com 12 neurônios, 8 entradas utilizando a função ReLU
model.add(Dense(12, input_dim=8, activation='relu'))
# inicializar a segunda camada com 8 neurônios e a função ReLU
model.add(Dense(8, activation='relu'))
# inicializar a última camada (camada de saída) com um neurônio e a função Sigmoid
model.add(Dense(1, activation='sigmoid'))
3. Compilando o modelo
Com nosso modelo definido, precisamos compilá-lo. A compilação ocorre utilizando bibliotecas como Theano ou TensorFlow, onde a melhor forma de representar a rede para treinar e fazer predições utilizando o hardware disponível é selecionada.
Ao compilar, precisamos especificar algumas propriedades, como a função de perda, otimizador e a métrica que será utilizada para avaliar o modelo. Foge ao escopo do tutorial apresentar esses conceitos, mas vamos utilizar a função de perda de Entropia Cruzada Binária, o otimizador Adam (que utiliza o gradiente descendente) e acurácia como métrica.
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
4. Treinando o modelo
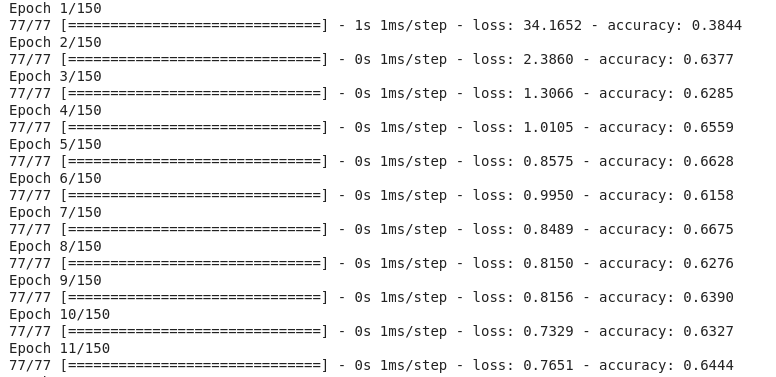
Como nosso modelo definido e compilado, precisamos treiná-lo, ou seja, executar o modelo utilizando nossos dados. Para treinar o modelo, basta chamar a função fit() para o modelo.
O treinamento ocorre através de épocas, e cada época é dividida em lotes, onde uma época é uma passagem por todas as linhas do conjunto de testes, e um lote é composto de uma ou mais amostras (quantidade definida pelo usuário) consideradas pelo modelo antes que seja feita a atualização dos seus pesos. Aqui, vamos executar 150 épocas com lotes de tamanho 10 (um número considerado pequeno).
# treinar o modelo keras
model.fit(X, y, epochs=150, batch_size=10)
5. Avaliando o modelo
Agora que estamos com nosso modelo treinado, precisamos avaliá-lo. Essa avaliação vai dizer o quão bem o modelo foi construído utilizando o conjunto de dados de treinamento. Esse pequeno projeto foi construído para ser simples, mas você pode separar os dados entre dados de treinamento e de teste para avaliar o desempenho do modelo com novos dados.
Para avaliar como o modelo se comportou para os dados de treinamento, basta passar os mesmos dados de entrada e saída para a função evaluate() . Essa função retorna uma lista com a perda e a acurácia do modelo para o conjunto de dados.
# avaliando o modelo keras
_, accuracy = model.evaluate(X, y)
print('Acurácia: %.2f' % (accuracy*100))
Conclusão
Com esse tutorial, podemos acompanhar em 5 passos o ciclo de vida de um modelo de Deep Learning, da sua concepção até a sua avaliação. Você pode expandir o que foi feito neste tutorial para, por exemplo, ajustar o modelo (é possível obter uma acurácia maior do que a obtida?), salvar o modelo (para utilização em outros projetos), plotar a curva de aprendizado, entre outras ideias.
Para mais tutoriais, continue atento ao nosso Blog.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade