Venha trabalhar como Líder Técnico da Secretaria da Proteção Social, Justiça, Cidadania, Mulheres e Direitos Humanos no Projeto Observatório (Oi Sol). Projeto desenvolvido em parceria com o Laboratório Insight da Universidade Federal do Ceará e o Laboratório ÍRIS de Dados e Inovação do estado do Ceará.
O Projeto Observatório (Oi Sol) visa construir uma plataforma para recebimento de denúncias de violência contra mulheres, crianças e adolescentes e encaminhar às instituições competentes do estado do Ceará para que tomem medidas para a proteção das vítimas. A plataforma permitirá a visualização de analíticos a partir dos dados das denúncias e encaminhamentos realizados pelas Instituições.
Você será responsável por
estudar tecnologias que se adequem às necessidades do produto;
contribuir para a tomada de decisões tecnológicas;
atuar na arquitetura e desenvolvimento da plataforma do Observatório (Oi Sol);
liderar squads de desenvolvimento.
Procuramos por pessoas
com paixão por criar, aprender e testar novas tecnologias;
altamente criativas e curiosas sobre os assuntos, produtos e serviços;
que tenham habilidades interpessoais e de comunicação;
que saibam trabalhar bem em equipe e com uma gama de pessoas criativas;
que saibam gerenciar demandas de trabalho de forma eficaz e organizada.
Competências e Habilidades em
UML;
Padrões de Projeto;
Microsserviços;
Javascript;
React JS;
TypeScript;
HTML;
CSS;
Java;
Spring Boot;
Git, Gitlab;
PostgreSQL;
Docker.
É desejável conhecer
Spark;
Airflow;
Kafka.
Modalidade de Contratação
Celetista (40h semanais): R$ 7.332,89 + Vale Alimentação + Plano de Saúde.
Etapas da seleção
Envio de currículo:
até 27/07
Resultados da análise de currículo:
28/07
Entrevistas a partir de:
28/07
Submissão de candidatura
Envie seu currículo para sergio.brilhante@sps.ce.gov.br, ticianalc@insightlab.ufc.br e humberto.bezerra@sps.ce.gov.br com o assunto [VAGA LÍDER TÉCNICO].
Acompanhe nossas postagens também nas redes sociais. Alguma dúvida? Comente aqui embaixo, estamos à disposição para ajudá-lo(a)!
Se você é Desenvolvedor Júnior na área de Front End então fique atento a esta oportunidade! O Insight, por meio do Projeto de Transformação Digital do Governo do Ceará, está com bolsas disponíveis para alunos de graduação. Venha colaborar com a gente, conheça os requisitos da função.
Responsável por:
Atuar no desenvolvimento de soluções e aplicações web.
Habilidades:
Javascript;
Typescript;
HTML;
CSS;
React Js;
Redux;
Git;
Gitlab.
Desejável:
Next Js;
Node Js;
MongoDB;
PostgreSQL;
Spring Boot;
Docker.
Diferencial:
Ant Design;
Noções de UX/UI.
Modalidade de Contratação
Alunos de graduação: bolsa FUNCAP com uma carga horária de 20h semanais (R$ 800,00).
Etapas da seleção:
Inscrições
Até 28/07
Entrevistas técnicas
29/07
Resultado da entrevista técnica
30/07 (previsão)
Acesse o formulário para preencher seus dados e realizar sua inscrição.
? Desafio de Programação
O presente desafio consiste na criação de um Dashboard para Indicadores de Processo, na qual o usuário pode utilizar filtros para busca de informações.
Especificações do sistema
Cada candidato deverá implementar o front-end da aplicação informada utilizando o framework React.js. A interface a ser construída deverá possibilitar todas as interações possíveis por meio de dados previamente cadastrados, simulando a aplicação. São elas:
busca por processo através de uso de filtros;
ordenação de processos;
plotar gráficos de acordo com os dados.
A estrutura da aplicação a ser desenvolvida já foi desenhada por nossa equipe. Não se limite ao design e usabilidade apresentado, caso seja do seu interesse interpretá-los à sua maneira, isso será bem apreciado durante a avaliação.
Serão avaliadas questões relacionadas à qualidade da interface, como:
responsividade;
robustez;
harmonização dos elementos;
usabilidade;
criatividade;
boas práticas ao gerenciar URLs, histórico, estados da aplicação entre outros artefatos do contexto de navegadores.
Além do código implementado, como:
organização;
legibilidade;
modularização/componentização;
boas práticas e padrões;
uso das APIs recentes do React.js;
gerenciamento de versões com Git.
Diferencial e Dicas
A linguagem poderá ser Javascript ou Typescript. O uso de outros frameworks e bibliotecas Javascript ou CSS, assim como de pré-processadores CSS para outros fins também é opcional.
Não perca tempo criando componentes do zero, a biblioteca de componentes Ant Design fornece um conjunto de componentes que você pode utilizar para construir a aplicação. Exemplos: formulários, botões, listas, tabelas, etc.
O uso dos componentes doCE GOV UI poderá ajudar na estruturação do sistema e facilitará no uso de componentes.
Entregas via formulário:
URL do repositório Git, como GitHub e GitLab, contendo o código-fonte da aplicação.
URL da aplicação Web em execução em serviço online com Heroku, GitPod, Vercel etc. (Opcional, mas recomendável).
Link para um vídeo de demonstração da sua solução (hospedado em plataformas como YouTube, Vimeo, etc). Duração máxima do vídeo: 10 minutos.
Acompanhe as postagens do Insight para saber mais atualizações!
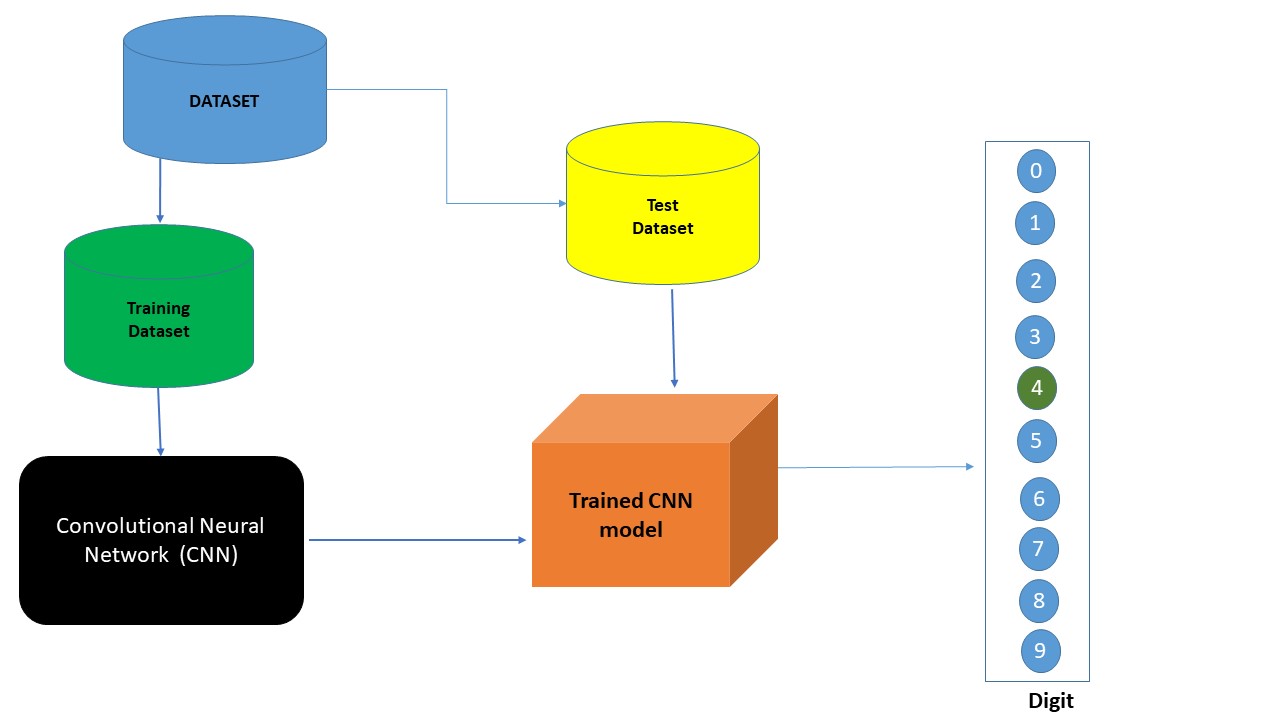
As redes neurais convolucionais (CNN) se utilizam de uma arquitetura especial que é particularmente bem adequada para classificar imagens. O uso dessa arquitetura torna as redes convolucionais rápidas de treinar, o que é vantajoso para trabalhar com redes profundas. Hoje, a CNN ,ou alguma variante próxima, é usada na maioria dos modelos para reconhecimento de imagem.
Neste artigo, vamos entender como criar e treinar uma (CNN) simples para classificar dígitos manuscritos de um conjunto de dados popular.
Figura 1: dataset MNIST ( imagem:en.wikipedia.org/wiki/MNIST_database)
Pré-requisito
Embora cada etapa seja detalhada neste tutorial, certamente quem já possui algum conhecimento teórico sobre o funcionamento da CNN será beneficiado. Além disso, é bom ter algum conhecimento prévio do TensorFlow2 , mas não é necessário.
Rede Neural Convolucional
Ao longo dos anos, o CNN se popularizou como técnica para a classificação de imagens para visões computacionais e tem sido usada nos domínios da saúde. Isso indica que o CNN é um modelo de deep learning confiável para uma previsão automatizada de ponta a ponta. Ele essencialmente extrai recursos ‘úteis’ de uma entrada fornecida automaticamente, facilitando nosso trabalho.
Figura 2: Processo end to end de CNN
Um modelo que utiliza CNN consiste, em suas versões mais simples, em três camadas principais: Camada Convolucional, Camada de Pooling e Camada Totalmente Conectada.
Camada Convolucional: Esta camada extrai recursos de alto nível dos dados de entrada e os repassa para a próxima camada na forma de mapas de recursos.
Camada de Pooling: É usada para reduzir as dimensões dos dados aplicando camadas de agrupamento (Pooling). Essa camada recebe cada saída do mapa de recursos da camada convolucional e prepara um mapa de características condensadas.
Camada Totalmente Conectada: Finalmente, a tarefa de classificação é feita pela camada totalmente conectada. As pontuações de probabilidade são calculadas para cada rótulo de classe por uma função de ativação popularmente chamada de função softmax.
Dataset
O dataset que está sendo usado aqui é o de classificação de dígitos MNIST. O Keras é uma API de deep learning escrita em Python e ele traz consigo o MNIST. Este conjunto de dados consiste em 60.000 imagens de treinamento e 10.000 imagens de teste, o que o torna ideal para quem precisa experimentar o reconhecimento de padrões, pois ele é executado em apenas um minuto.
Quando a API do Keras é chamada, quatro valores são retornados. São eles:
x_train,
y_train,
x_test,
y_test .
Não se preocupe, você será orientado(a) sobre isso.
Carregando o dataset
A linguagem usada aqui é Python. Vamos usar o Google Colab para escrever e executar o código. Você também pode escolher um Jupyter notebook. o Google Colab foi escolhido aqui por fornecer acesso fácil a notebooks a qualquer hora e em qualquer lugar. Também é possível conectar um notebook Colab a um repositório GitHub. Você pode aprender mais sobre o Google Colab aqui.
Além disso, o código usado neste tutorial está disponível neste repositório Github. Portanto, se você se sentir confuso em alguma fase, verifique esse repositório. Para manter este tutorial relevante para todos, explicaremos o código mais crítico.
Crie e nomeie um notebook.
Depois de carregar as bibliotecas necessárias, carregue o dataset MNIST conforme mostrado abaixo:
Como discutimos anteriormente, este conjunto de dados retorna quatro valores e na mesma ordem mencionada acima: x_train, y_train, x_test e y_test , que são representações para datasets divididos em treinamento e teste.
Muito bem! Você acabou de carregar seu dataset e está pronto para passar para a próxima etapa, que é processar os dados.
Processando o dataset
Os dados devem ser processados e limpos para melhorar sua qualidade. Para que a CNN aprenda é preciso que o dataset não contenha nenhum valor nulo, que tenha todos os dados numéricos e que seja normalizado. Então, aqui vamos realizar algumas etapas para garantir que tudo esteja perfeitamente adequado para um modelo CNN aprender. Daqui em diante, até criarmos o modelo, trabalharemos apenas no dataset de treinamento.
Se você escrever X_train[0], obterá a 0ª imagem com valores entre 0-255, representando a intensidade da cor (preto ao branco). A imagem é uma matriz bidimensional. É claro, não saberemos o que o dígito manuscrito X_train[0] representa, para saber isso escreva y_train[0] e você obterá 5 como saída. Isso significa que a 0ª imagem deste dataset de treinamento representa o número 5.
Vamos normalizar este dataset de treinamento e de teste, colocando os valores entre 0 e 1 conforme mostrado abaixo:
X_train=X_train/255
X_test=X_test/255
Em seguida, precisamos redimensionar a matriz para se adequar a API do Keras. Ela espera que cada entrada tenha 3 dimensões: uma pra linha, uma para a coluna e uma para a cor. Normalmente, essa 3ª dimensão é usada quando trabalhamos com imagens coloridas e temos múltiplos canais de cor (ex: RGB). Porém, como trabalhamos com imagens monocromáticas, essa terceira dimensão terá apenas um elemento.
X_train=X_train.reshape(-1,28,28,1) #conjunto de treinamento
X_test=X_test.reshape(-1,28,28,1) #conjunto de teste
Agora que está tudo em ordem, é hora de criarmos uma rede neural convolucional.
Criação e treinamento de uma CNN
Vamos criar um modelo CNN usando a biblioteca TensorFlow. O modelo é criado da seguinte maneira:
Reserve algum tempo para permitir que todo o código seja absorvido. É importante que você entenda cada parte dele. No modelo CNN criado acima, há uma camada CNN de entrada, seguida por duas camadas CNN ocultas, uma camada densa oculta e, finalmente, uma camada densa de saída. Em termos mais simples, as funções de ativação são responsáveis por tomar decisões de passar o que foi identificado adiante ou não. Em uma rede neural profunda como a CNN, existem muitos neurônios e, com base nas funções de ativação, os neurônios disparam e a rede avança. Se você não entende muito sobre as funções de ativação use ‘relu’, pois ele é mais popular devido sua versatilidade.
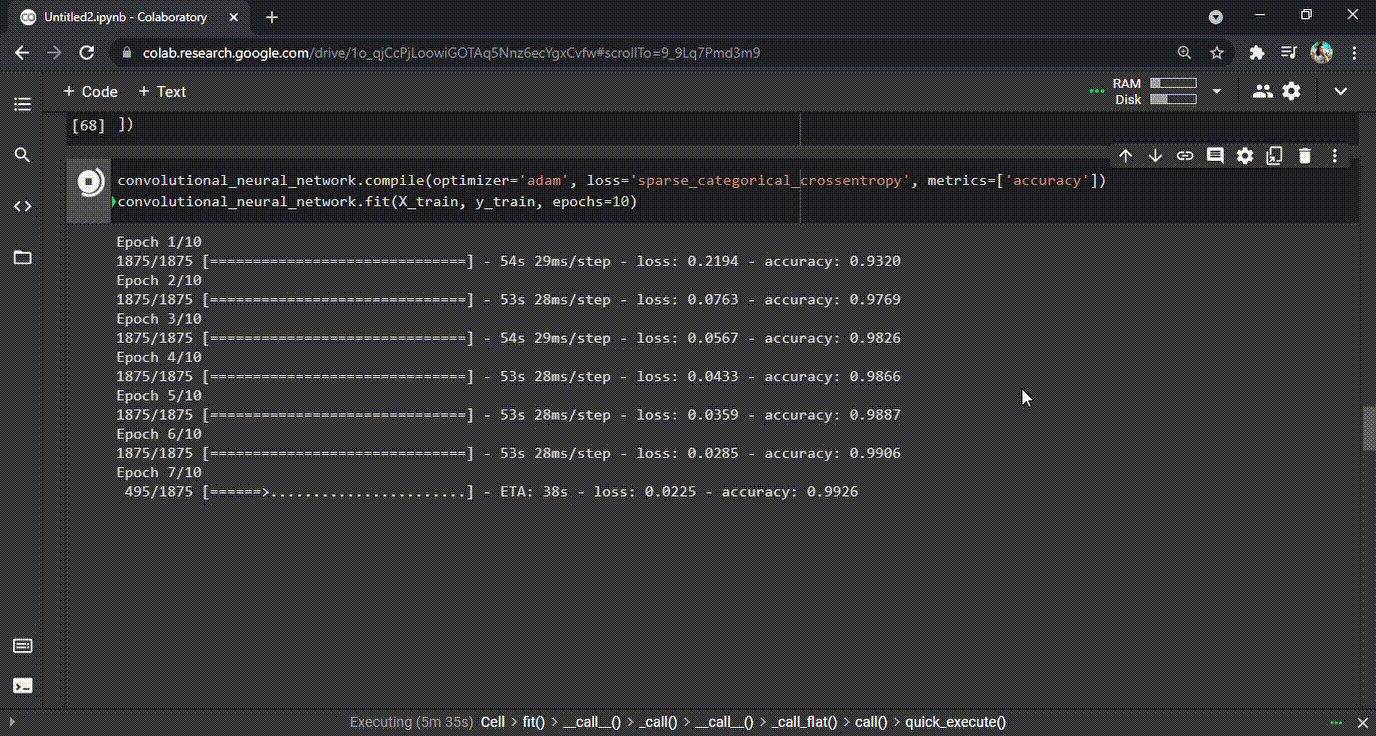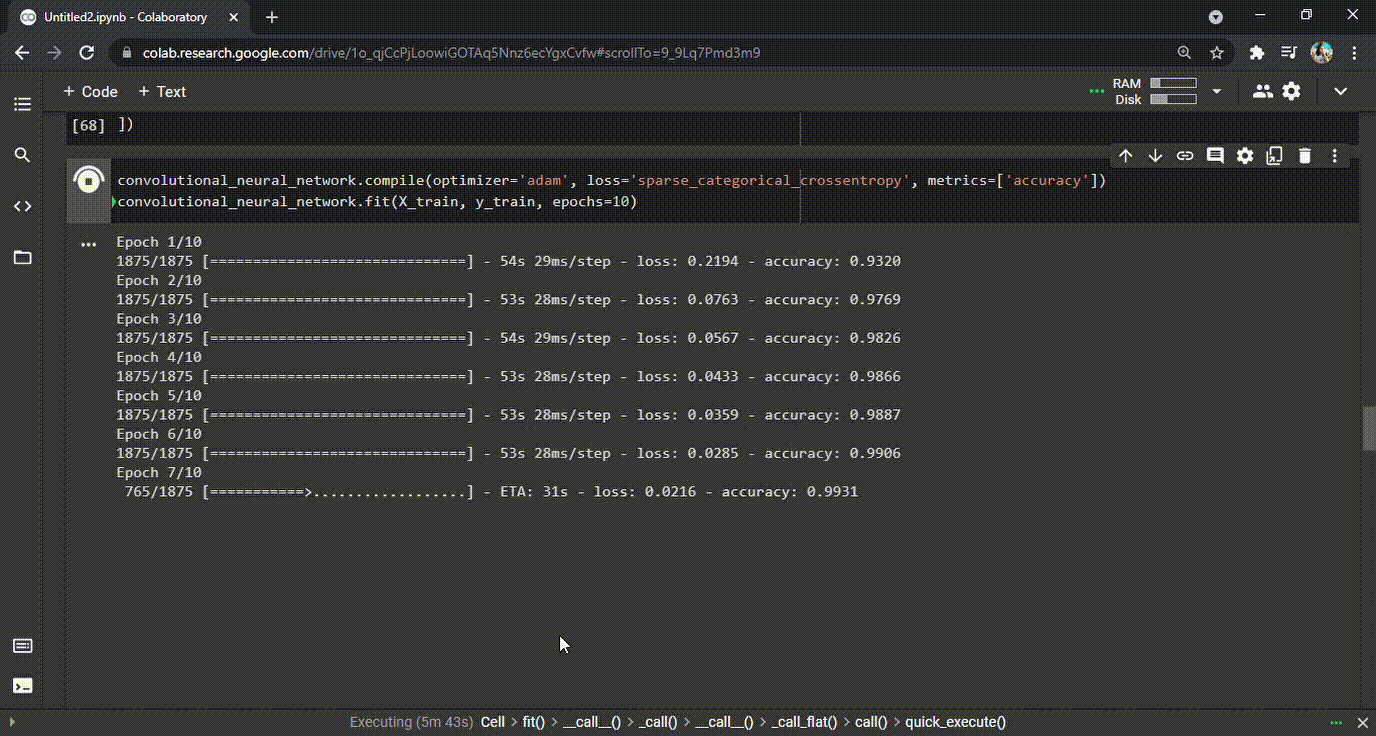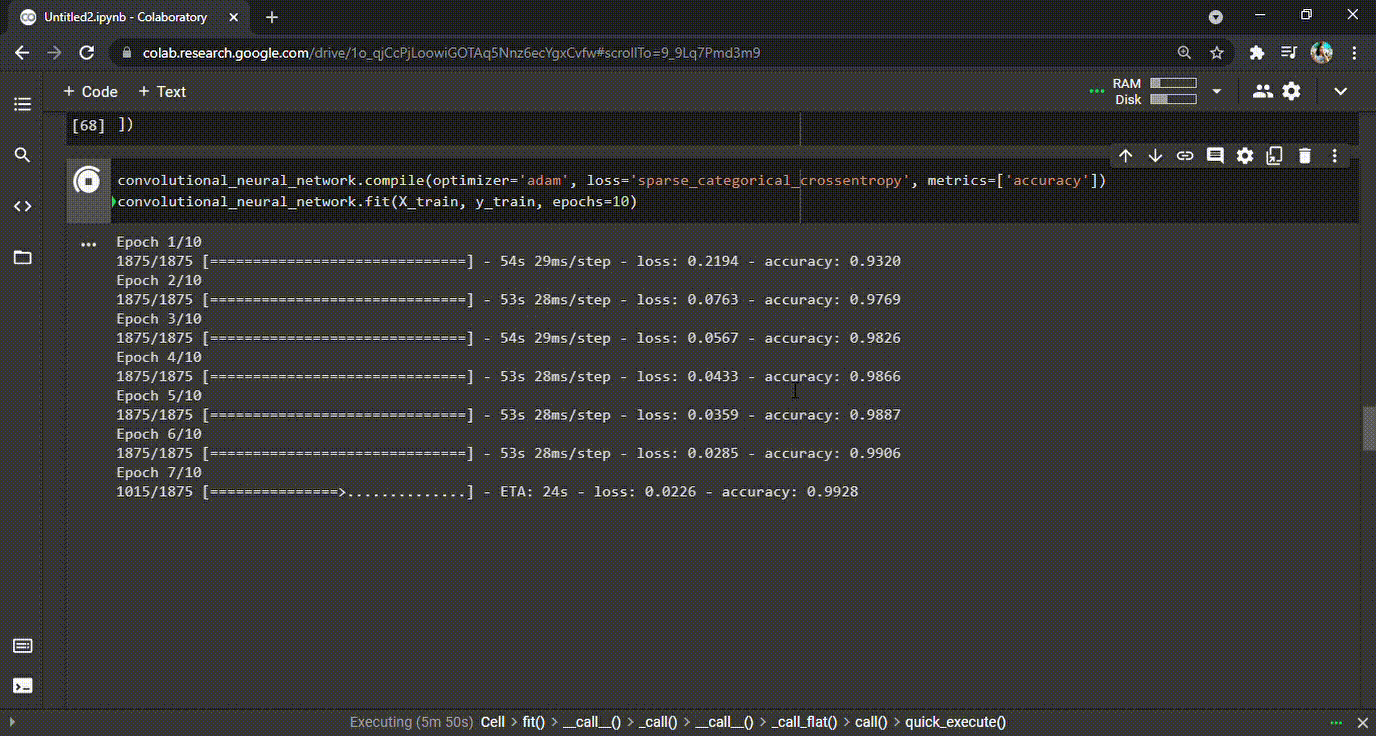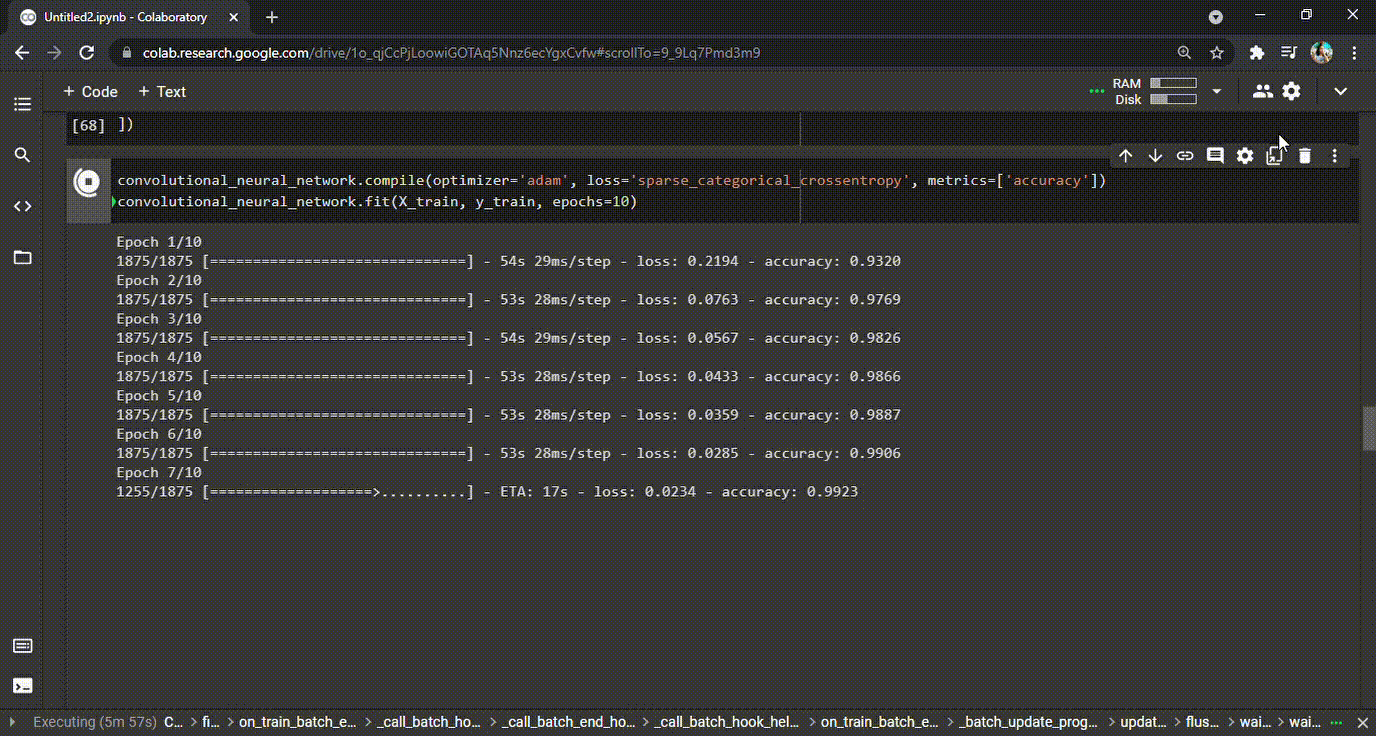
Uma vez que o modelo foi criado, é hora de compilá-lo e treiná- lo . Durante o processo de treino, o modelo percorrerá o dataset e aprenderá os padrões. Ele treinará quantas vezes for definido (as chamadas épocas). Em nosso exemplo, definimos 10 épocas. Durante o processo, o modelo da CNN vai aprender e também cometer erros. Para cada erro (previsões erradas) que o modelo comete, há uma penalidade (ou um custo) e isso é representado no valor da perda (loss) para cada época (veja o GIF abaixo). Resumindo, o modelo deve gerar o mínimo de perda e a maior precisão possível no final da última época.
Modelo de treinamento | classificação de dígitos manuscritos CNN
GIF 1: Treinamento CNN e as precisões aprimoradas durante cada época
Fazendo previsões
Para avaliar o modelo CNN assim criado, você pode executar:
O código acima usará o modelo convolutional_neural_network para fazer previsões para o conjunto de teste e armazená-lo no dataframe y_predicted_by_model. Para cada um dos 10 dígitos possíveis, uma pontuação de probabilidade será calculada. A classe com a pontuação de probabilidade mais alta é a previsão feita pelo modelo. Por exemplo, se você quiser ver qual é o dígito na primeira linha do conjunto de teste:
Como é realmente difícil identificar o rótulo da classe de saída com a pontuação de probabilidade mais alta, vamos escrever outro código:
np.argmax(y_predicted[0])
E com isso, você obterá um dos dez dígitos como saída (0 a 9). Para saber a representação direta do dígito, aplique o resultado do argmax nas classes do modelo.
Em suma
Após aprender como um dataset é dividido em treinamento e teste, utilizando o MNIST para fazer previsões de dígitos manuscritos de 0 a 9, criamos um modelo CNN treinado no dataset de treinamento. Por fim, com o modelo treinado, as previsões são realizadas.
Incentivamos você a experimentar por conta própria a ajustar os hiperparâmetros do modelo na expectativa de saber se eles são capazes de alcançar precisões mais altas ou não. Se você quer aprender sempre mais, acompanhe esta aula de Redes Neurais Convolucionais. Ficamos felizes em colaborar com a sua aprendizagem!
Referências
Equipe, K. (nd). Documentação Keras: conjunto de dados de classificação de dígitos MNIST. Keras. https://keras.io/api/datasets/mnist/.
manav_m. (2021, 1º de maio). CNN para Aprendizado Profundo: Redes Neurais Convolucionais (CNN). Analytics Vidhya. https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/.
YouTube. (2020, 14 de outubro). Explicação simples da rede neural convolucional | Tutorial de aprendizado profundo 23 (Tensorflow e Python). YouTube. https://www.youtube.com/watch?v=zfiSAzpy9NM&list=PLeo1K3hjS3uvCeTYTeyfe0-rN5r8zn9rw&index=61.
OBig Data e Inteligência Artificial é um projeto em desenvolvimento pelo Insight Lab e o Ministério da Justiça e Segurança Pública. O objetivo desse projeto é realizar estudos científicos para criar uma plataforma que permitirá integrar e analisar fontes de dados de segurança pública dos estados brasileiros, direcionando, então, a implantação de estratégias para a melhoria da segurança pública.
Entre as ferramentas já disponíveis desse projeto está o Geointeligência, que é um sistema de georreferenciamento aplicado na segurança pública. E desde 2020, essa ferramenta também está sendo usada na área da saúde, pois, devido à pandemia de Covid-19, o Governo do Ceará implementou o Geointeligência para entender a disseminação dessa doença no estado. Importação de eventos é uma das principais funcionalidades do Geointeligência. Implementado utilizando a linguagem de programação Scala com Play Framework, ele é um dos sistemas desenvolvidos por nossa equipe e tem como objetivoanalisar eventos espaço-temporais através de algoritmos que procuram encontrar padrões capazes de ajudar na melhor aplicação de forças tarefas de segurança. Como o Geointeligência é um sistema analítico, ele precisa que os eventos utilizados em suas análises sejam adicionados à sua base. E uma das maneiras mais importantes para fazer isso é a importação através de arquivos do tipo csv ou xlsx.
A importação de arquivos traz a facilidade de qualquer usuário poder importar seus eventos e utilizar o sistema para fazer análises a fim de identificar padrões úteis em seus eventos. Sem a importação de arquivos, nenhuma organização ou usuário poderiam criar análises com seus eventos, e com isso as análises seriam menos eficazes para diversos casos. Tendo isso em vista, a importação de eventos tem a necessidade de ser uma funcionalidade robusta e eficaz para importar eventos em larga escala.
Motivação – Processando muitos eventos
A importação de eventos passou a ser uma funcionalidade muito importante para nossos usuários. Com isso, notamos que a maioria deles tinham que dividir os arquivos de importação em diversos arquivos menores devido à limitação de tamanho e ao tempo que eles esperavam que sua tarefa fosse concluída para, só então, ter uma resposta do sistema.
Por conta disso, nossa equipe resolveu que precisávamos melhorar a eficiência da importação para que fosse possível processar muitos eventos através de um único arquivo e com vários usuários ao mesmo tempo. Quantos eventos nós queríamos ser capazes de processar em um só arquivo?
> Que tal 300.000 eventos?
Arquivos grandes
Em virtude dos requisitos que nós tínhamos à época, nossa implementação inicial da funcionalidade de importação de arquivos era bem simples. Uma vez que o servidor recebesse a requisição HTTP do usuário, ele carregaria todo o arquivo em memória e faria todo o processamento necessário dos eventos contidos nele dentro do escopo dessa mesma requisição, retornando então para o usuário uma resposta com a quantidade de eventos importados.
Dada a necessidade de se importar grandes quantidades de eventos, surgiram dois problemas principais com essa implementação. O arquivo que deveria conter essa maior quantidade de eventos a serem importados precisaria ser significativamente maior, ocasionando um consumo de memória que tornaria progressivamente mais limitada a utilização dessa funcionalidade por múltiplos usuários ao mesmo tempo.
Além disso, mais eventos significavam que a aplicação precisaria gastar proporcionalmente mais tempo para processar um arquivo completo. Por conta disso e pelo fato de a importação ser realizada dentro do escopo de uma requisição HTTP, o usuário poderia precisar esperar por muito tempo até que o upload desse arquivo fosse feito e seus eventos fossem validados e inseridos na base de dados, para só então ter uma resposta e poder seguir utilizando a aplicação, que ficaria “bloqueada” esperando a finalização da requisição.
Devido ao impacto causado pelo consumo de memória e o tempo de espera do usuário durante uma importação, nós precisávamos resolver esses problemas para obtermos uma implementação que suportasse a importação de grandes quantidades de eventos.
Para resolver o problema do consumo de memória, tivemos de elaborar uma estratégia para o processamento do arquivo na qual fosse garantido que o arquivo em si nunca fosse integralmente carregado em memória, o que ampliaria a escalabilidade da aplicação e permitiria, mais facilmente, a possibilidade de importações sendo executadas simultaneamente.
Em paralelo, para resolver o problema de espera do usuário, chegamos à conclusão de que o processamento dos eventos não poderia estar limitado ao escopo de uma requisição do usuário. Isto é, uma vez que o usuário iniciasse uma importação, o Geointeligência deveria ser capaz de respondê-lo que sua requisição de importação fora aceita, mas o processo de importação em si deveria ser executado em segundo plano. Por consequência, uma vez que a importação fosse executada fora do escopo da requisição de importação, o usuário precisaria receber algum tipo de feedback do sistema informando-o quando sua tarefa fosse concluída. Desta forma, nós também tivemos de desenvolver um mecanismo, independente do escopo de uma requisição, capaz de informar ao usuário que sua importação foi concluída.
Disco é mais barato que memória RAM
Com o crescimento no tamanho dos arquivos de importação, a estratégia que nós havíamos implementado já não funcionava. Para resolver isso, uma opção seria guardar todo o arquivo em disco e depois ir carregando apenas partes dele na memória à medida que os eventos contidos nele fossem sendo processados.
Felizmente, para uma linguagem como o Scala, carregar apenas uma parte de um arquivo em memória não é uma tarefa difícil, uma vez que esse arquivo esteja salvo em disco ou em uma base de dados. Para implementar isso, nós utilizamos apenas as abstrações de InputStream e OutputStream nativas da linguagem de programação, sem que houvesse a necessidade da utilização de nenhuma biblioteca externa. Como os arquivos que nós usávamos armazenavam os eventos de modo sequencial, nós tínhamos tudo o que precisávamos para implementar essa arquitetura.
Desta forma, nós implementamos a seguinte estratégia:
Assim que o servidor recebesse a requisição com o arquivo de eventos, ele seria diretamente armazenado em nossa base de dados através de um stream;
Quando necessário, o sistema retiraria, também através de um stream, partes do arquivo contendo blocos de eventos que precisavam ser validados e inseridos;
Cada bloco de eventos seria, então, processado de modo independente, isto é, cada um dos eventos de um bloco deveria passar por uma série de validações antes de serem inseridos em nossa base;
Quando todo o arquivo fosse consumido, isto é, quando todo o seu conteúdo tivesse sido “lido”, e todos os seus eventos fossem processados, o sistema removeria esse arquivo da base.
Utilizando essa estratégia, nós conseguimos controlar de maneira muito mais detalhada o quanto do arquivo seria carregado na memória dos nossos servidores, além de permitir que partes de um mesmo arquivo pudessem ser processadas paralelamente.
O usuário não pode esperar
Importar algumas centenas de eventos no escopo de uma requisição HTTP era algo simples. Processar um arquivo pequeno com essa quantidade de eventos não é uma tarefa tão custosa assim. O usuário ficaria esperando alguns poucos segundos e a tarefa dele estaria concluída.
Acontece que esse padrão de uso não durou muito tempo e logo os usuários precisaram fazer importações na casa dos milhares de eventos. Essas importações demoravam mais, deixando o usuário esperando por vários segundos; isso quando o processo todo conseguia ser executado dentro do tempo limite de uma requisição HTTP.
Isso não estava bom o suficiente. Nós precisávamos permitir que nosso sistema fosse robusto o bastante para permitir importações maiores e gostaríamos também que o usuário não fosse obrigado a ficar esperando sua importação terminar para realizar outras atividades dentro do sistema.
Nós precisávamos que as importações feitas no Geointeligência acontecessem em segundo plano, isto é, uma vez que o usuário iniciasse uma importação, esta deveria acontecer fora do escopo de sua requisição, e o usuário deveria ter alguma forma de verificar se sua tarefa já havia sido concluída.
Para isso, nós utilizamos a ferramenta mais indicada para a nossa necessidade e que estava à nossa disposição: o Akka.
Por que Akka e Akka Cluster?
O Akka é um conjunto de ferramentas que simplifica a construção de aplicativos concorrentes e distribuídos na JVM. Como nossos sistemas são implementados utilizando a linguagem de programação Scala, que roda na JVM, o Akka costuma ser uma ótima ferramenta para nos auxiliar a tornar nossos sistemas mais poderosos. Além disso, o Akka nos traz a possibilidade de trabalhar com o modelo de atores, que facilita o nosso trabalho como desenvolvedores no processo de criação de sistemas concorrentes e distribuídos.
Outro ponto importante é que nossa infraestrutura prevê a possibilidade da criação de múltiplas instâncias da mesma aplicação com o objetivo de suportar uma maior quantidade de usuários durante um momento de estresse do sistema. Desse modo, o Akka, juntamente com o Akka Cluster, nos permitem desenvolver funcionalidades utilizando modelo de atores com o objetivo de tornar transparente para o desenvolvedor questões de gerenciamento e comunicação entre mais de uma instância de um mesmo sistema.
Conversa entre atores
No fim, para conseguirmos que a importação fosse toda processada fora do escopo da requisição do usuário, nós tivemos que fazer grandes mudanças na forma como ela era implementada, substituindo a estratégia anterior por uma baseada no modelo de atores. Resumidamente, essa estratégia utiliza um conjunto de atores, pequenas unidades de processamento capazes de se comunicar entre si através de mensagens, que são responsáveis por executar cada passo da importação.
Para implementar essa arquitetura de atores nós utilizamos a API de atores do Akka, uma vez que ela já abstrai uma porção de detalhes de gerenciamento de threads e bloqueios, tornando o trabalho do desenvolvedor mais focado na construção do sistema em si e nas interações entre os atores.
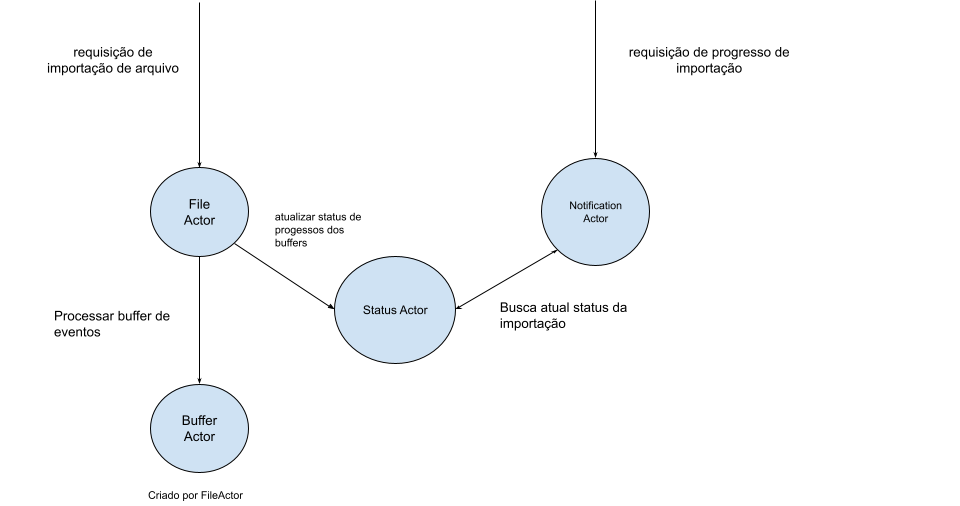
Resumidamente, quando um usuário envia uma requisição de importação para o sistema, o arquivo enviado é imediatamente salvo em nossa base de dados e uma mensagem com informações desse arquivo é enviada para um ator de arquivo (File Actor). As principais responsabilidades desse ator de arquivo são controlar o andamento da importação e carregar o arquivo de importação armazenado na base em partes na memória. Toda essa etapa inicial é executada ainda dentro do escopo da requisição HTTP do usuário, mas a partir desse ponto a execução ocorre em segundo plano.
O ator de arquivo, então, envia uma parte do arquivo para um segundo ator: o ator de blocos de eventos (Buffer Actor). Ele funciona como um buffer, responsável por processar um bloco de eventos, realizando as devidas validações e inserindo os eventos válidos na base. Uma vez que o ator de blocos de eventos tenha inserido todo um bloco de eventos, ele notifica novamente o ator de arquivo com informações desses eventos. O ator de arquivo então envia para um terceiro ator (Status Actor) as informações atualizadas da importação. Esse ator é responsável por manter o estado da importação com informações como quantidade de eventos inseridos e quantidade de erros encontrados.
O ator de arquivos, então, reinicia seu ciclo de execução, retirando partes do arquivo, uma a uma, e enviando-as para o ator de blocos. Por fim, quando o último bloco do arquivo é retirado da base e seus eventos são processados, o ator de arquivo remove esse arquivo da base, completando assim o processo de importação.
Acompanhando o progresso
A evolução da importação para ser processada fora do escopo de uma requisição HTTP não bloqueando o usuário no sistema gerou a necessidade de uma funcionalidade de feedback para o usuário sobre o processamento da importação do seu arquivo de eventos. A nossa arquitetura de atores possui um ator de notificação (Notification Actor) cuja função é justamente disponibilizar informações sobre as importações que estão ocorrendo naquele momento.
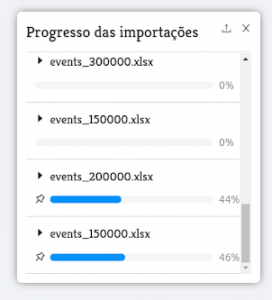
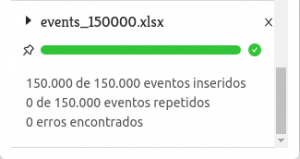
Por isso, surgiu a ideia de criar um canal de comunicação direto entre o front-end e esse ator de notificação através de um Websocket. Sempre que o ator de estado da importação é atualizado com novas informações de importações atuais, ele utiliza esse Websocket para enviar mensagens com o progresso dessas importações para o front-end que, por sua vez, fica responsável por apresentar ao usuário essas informações como indicado na imagem abaixo:
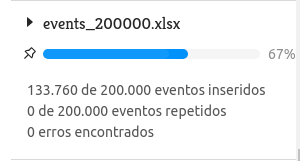
O Geointeligência apresenta cada importação com uma barra de progresso sendo atualizada em tempo real. Ao clicar sobre a importação, o usuário verá mais informações sobre a quantidade de eventos que estão sendo inseridos, repetidos ou se houve erros:
Com essa funcionalidade o usuário tem a todo instante o entendimento do momento atual de sua importação e pode continuar usando o sistema sem precisar esperar que todo o processo seja finalizado.
Capacidade de importação
O Geointeligência passou a importar de forma eficaz uma quantidade significativamente maior de eventos por arquivo. Essa evolução deveu-se àsaída do escopo de uma requisição HTTP, leitura otimizada do arquivo durante processamento, adição do modelo de atores do Akka para processamento de eventos e introdução do Akka Cluster para suportar diversas instâncias
Hoje, nosso sistema consegue importar arquivos com 300 mil eventos em pouco mais de dois minutos, sem que o usuário precise esperar o processamento de todos esses eventos para continuar a utilizar o sistema. O usuário pode fazer uma análise de eventos enquanto outros são importados. Isso melhorou a usabilidade do nosso sistema, permitindo ao usuário utilizar seu tempo para fazer as análises em vez de preparar os dados.
Conclusão
Com tudo isso, nossa equipe encontrou uma ótima forma de lidar com uma importação maciça de eventos sem precisar que o usuário esperasse a finalização de todo o processamento.
A utilização do Akka e de atores trouxe mais responsividade para a funcionalidade e, com isso, a utilização de mensagens assíncronas para informar progresso ao usuário permitiu que nosso sistema se comportasse de maneira mais reativa.
Nossos usuários ganharam tempo de processamento com o uso de modelo de atores para processar partes dos eventos por vez, e além disso, agora eles podem acompanhar todo o processo em tempo real com o progresso visual. A saída do escopo da requisição HTTP trouxe muitas vantagens para a importação no Geointeligência e a utilização do Akka fez com que o desenvolvimento disso fosse bem menos complexo do que poderia ser.
Melhorar a experiência do usuário é sempre um objetivo que devemos procurar dentro de nossos sistemas.
O Insight Lab está com vagas para bolsistas de graduação e graduados para atuarem no Projeto de Aceleração da Transformação Digital do Governo do Ceará. Os selecionados irão trabalhar como desenvolvedor para soluções de Interoperabilidade e receberão bolsa Funcap. Saiba os requisitos para se candidatar.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade