
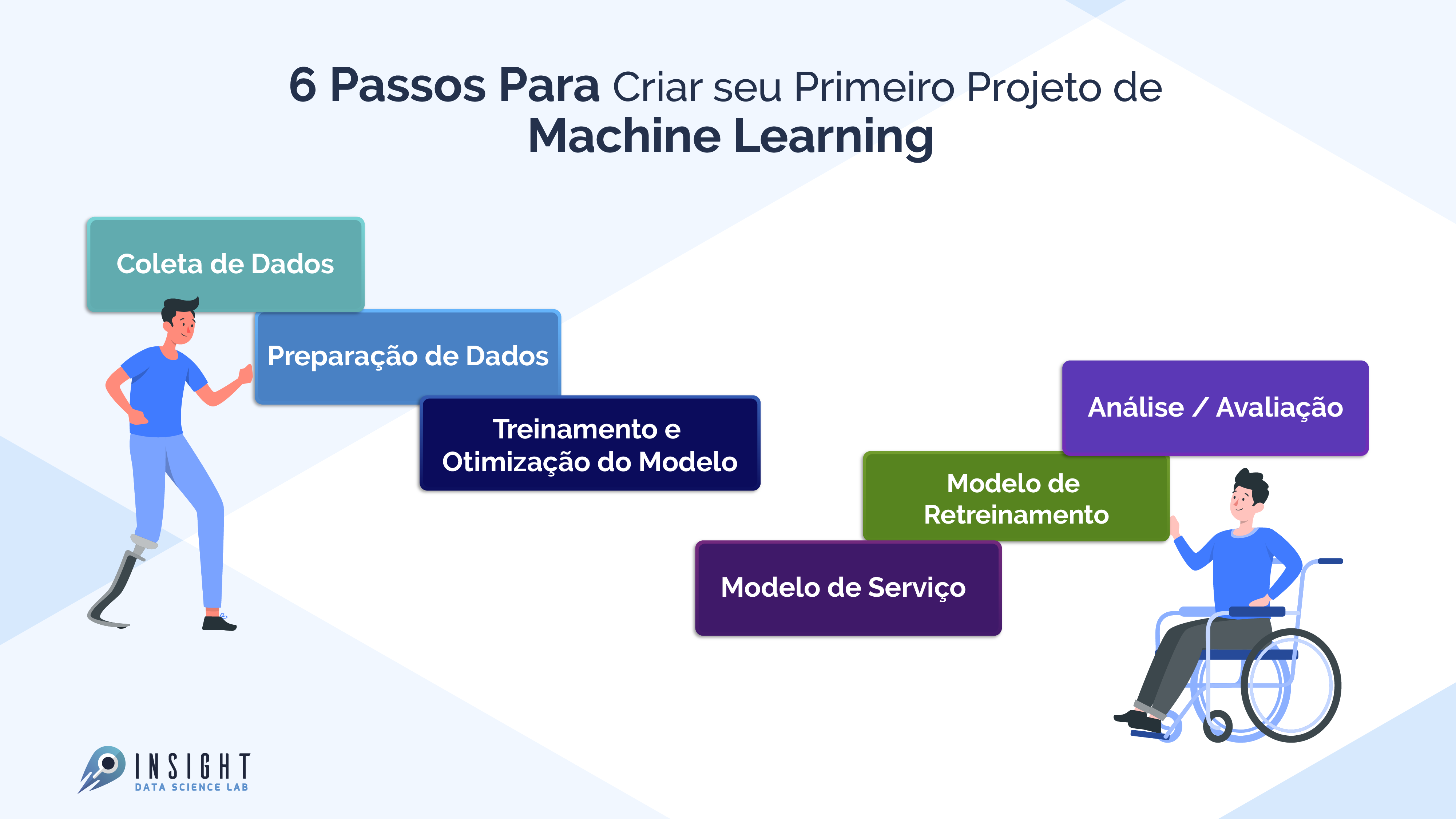
6 passos Para Criar Seu Primeiro Projeto de Machine Learning
Aqui você verá as várias etapas envolvidas em um projeto de Machine Learning (ML). Existem etapas padrões que você deve seguir para um projeto de Ciência de Dados. Para qualquer projeto, primeiro, temos que coletar os dados de acordo com nossas necessidades de negócios. A próxima etapa é limpar os dados como remover valores, remover outliers, lidar com conjuntos de dados desequilibrados, alterar variáveis categóricas para valores numéricos, etc.
Depois do treinamento de um modelo, use vários algoritmos de aprendizado de máquina e aprendizado profundo. Em seguida, é feita a avaliação do modelo usando diferentes métricas, como recall, pontuação f1, precisão, etc. Finalmente, a implantação do modelo na nuvem e retreiná-lo. Então vamos começar:
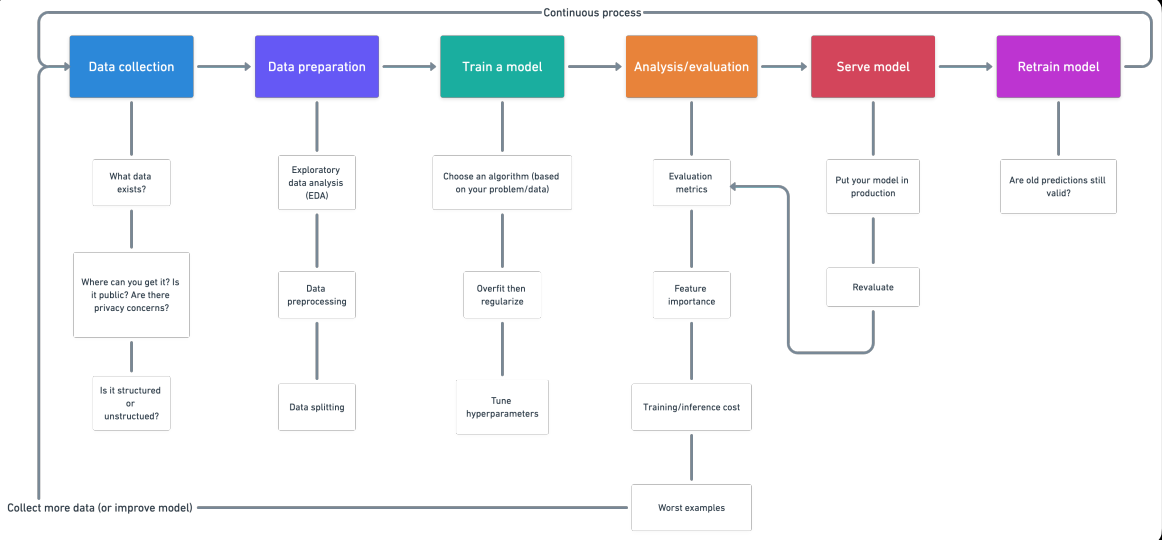
Fluxo de trabalho do projeto de Aprendizado de Máquina
1. Coleta de dados
Perguntas a serem feitas:
- Que problema deve ser resolvido?
- Que dados existem?
- Onde você pode obter esses dados? São públicos?
- Existem preocupações com a privacidade?
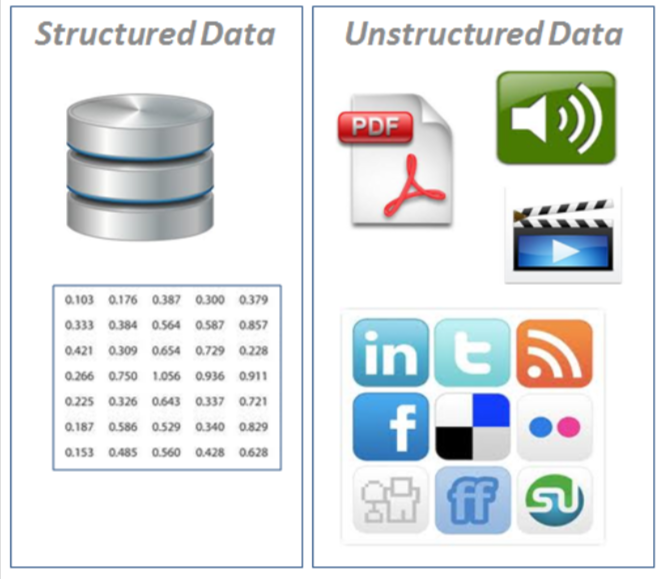
- É estruturado ou não estruturado?
Tipos de dados
Dados estruturados: aparecem em formato tabular (estilo linhas e colunas, como o que você encontraria em uma planilha do Excel). Ele contém diferentes tipos de dados, por exemplo: numéricos, categóricos, séries temporais.
- Nominal / categórico – Uma coisa ou outra (mutuamente exclusivo). Por exemplo, para balanças de automóveis, a cor é uma categoria. Um carro pode ser azul, mas não branco. Um pedido não importa.
- Numérico: qualquer valor contínuo em que a diferença entre eles importa. Por exemplo, ao vender casas o valor de R$ 107.850,00 é maior do que R$ 56.400,00.
- Ordinal: Dados que têm ordem, mas a distância entre os valores é desconhecida. Por exemplo, uma pergunta como: como você classificaria sua saúde de 1 a 5? 1 sendo pobre, 5 sendo saudável. Você pode responder 1,2,3,4,5, mas a distância entre cada valor não significa necessariamente que uma resposta de 5 é cinco vezes melhor do que uma resposta de 1.
- Séries temporais: dados ao longo do tempo. Por exemplo, os valores históricos de venda de Bulldozers de 2012-2018.
Dados não estruturados: dados sem estrutura rígida (imagens, vídeo, fala, texto em linguagem natural)
2. Preparação de dados
2.1 Análise Exploratória de Dados (EDA), aprendendo sobre os dados com os quais você está trabalhando
- Quais são as variáveis de recursos (entrada) e as variáveis de destino (saída)? Por exemplo, para prever doenças cardíacas, as variáveis de recursos podem ser a idade, peso, frequência cardíaca média e nível de atividade física de uma pessoa. E a variável de destino será a informação se eles têm ou não uma doença.
- Que tipo de dado você tem? Estruturado, não estruturado, numérico, séries temporais. Existem valores ausentes? Você deve removê-los ou preenchê-los com imputação de recursos.
- Onde estão os outliers? Quantos deles existem? Por que eles estão lá? Há alguma pergunta que você possa fazer a um especialista de domínio sobre os dados? Por exemplo, um médico cardiopata poderia lançar alguma luz sobre seu dataset de doenças cardíacas?
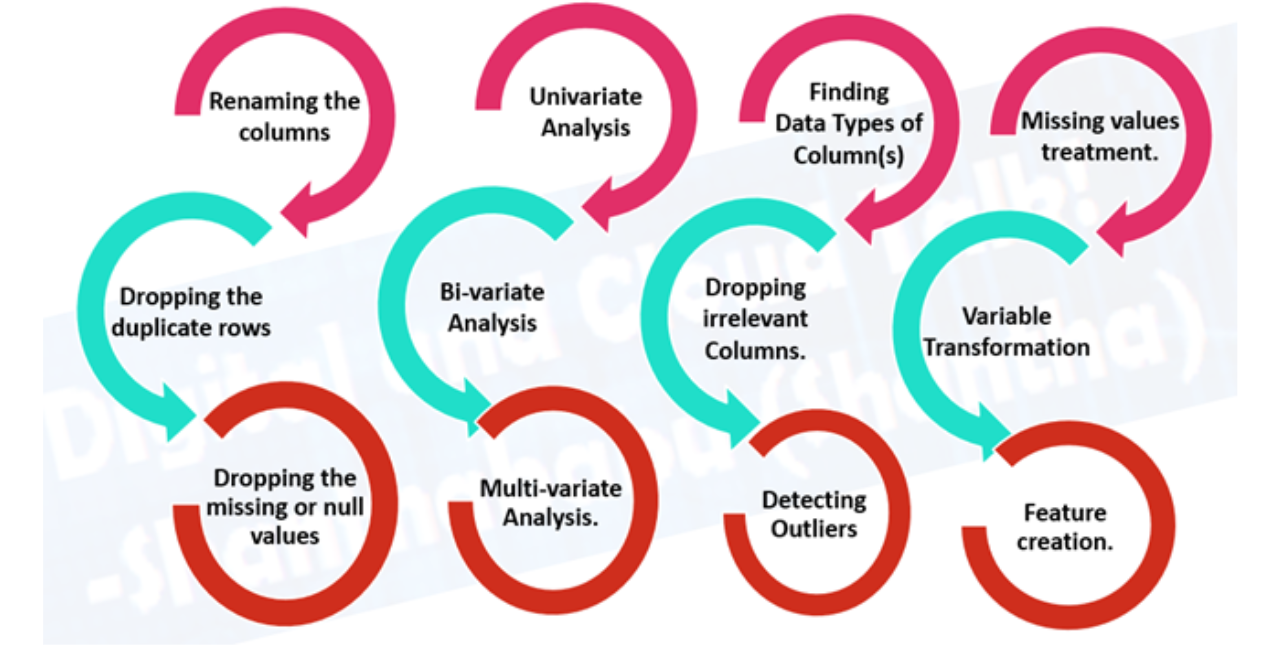
2.2 Pré-processamento de dados, preparando seus dados para serem modelados.
- Imputação de recursos: preenchimento de valores ausentes, um modelo de aprendizado de máquina não pode aprender com dados que não estão lá.
- Imputação única: Preencha com a média, uma mediana da coluna;
- Múltiplas imputações: modele outros valores ausentes e com o que seu modelo encontrar;
- KNN (k-vizinhos mais próximos): Preencha os dados com um valor de outro exemplo semelhante;
- Imputação aleatória, última observação transportada (para séries temporais), janela móvel e outros.
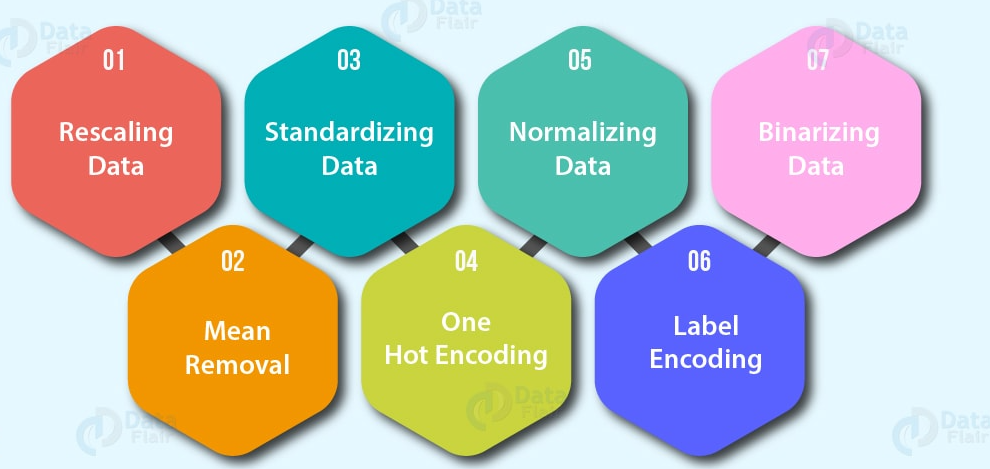
- Codificação de recursos (transformando valores em números). Um modelo de aprendizado de máquina exige que todos os valores sejam numéricos.
- Uma codificação rápida: Transforme todos os valores exclusivos em listas de 0 e 1, onde o valor de destino é 1 e o resto são 0s. Por exemplo, quando as cores de um carro são verdes, vermelhas, azuis, verdes, o futuro das cores de um carro seria representado como [1, 0 e 0] e um vermelho seria [0, 1 e 0].
- Codificador de rótulo: Transforme rótulos em valores numéricos distintos. Por exemplo, se suas variáveis de destino forem animais diferentes, como cachorro, gato, pássaro, eles podem se tornar 0, 1 e 2, respectivamente.
- Codificação de incorporação: aprenda uma representação entre todos os diferentes pontos de dados. Por exemplo, um modelo de linguagem é uma representação de como palavras diferentes se relacionam entre si. A incorporação também está se tornando mais amplamente disponível para dados estruturados (tabulares).
- Normalização de recursos (dimensionamento) ou padronização: quando suas variáveis numéricas estão em escalas diferentes (por exemplo, number_of_bathroom está entre 1 e 5 e size_of_land entre 500 e 20000 pés quadrados), alguns algoritmos de aprendizado de máquina não funcionam muito bem. O dimensionamento e a padronização ajudam a corrigir isso.
- Engenharia de recursos: transforma os dados em uma representação (potencialmente) mais significativa, adicionando conhecimento do domínio.
- Decompor;
- Discretização: transformando grandes grupos em grupos menores;
- Recursos de cruzamento e interação: combinação de dois ou mais recursos;
- Características do indicador: usar outras partes dos dados para indicar algo potencialmente significativo.
- Seleção de recursos: selecionar os recursos mais valiosos de seu dataset para modelar. Potencialmente reduzindo o overfitting e o tempo de treinamento (menos dados gerais e menos dados redundantes para treinar) e melhorando a precisão.
- Redução de dimensionalidade: Um método comum de redução de dimensionalidade, PCA ou análise de componente principal, toma um grande número de dimensões (recursos) e usa álgebra linear para reduzi-los a menos dimensões. Por exemplo, digamos que você tenha 10 recursos numéricos, você poderia executar o PCA para reduzi-los a 3;
- Importância do recurso (pós-modelagem): ajuste um modelo a um dataset, inspecione quais recursos foram mais importantes para os resultados e remova os menos importantes;
- Os métodos Wrapper geram um subconjunto “candidato”, contendo atributos selecionados no conjunto de treinamento, e utilizam a precisão resultante do classificador para avaliar o subconjunto de atributos “candidatos”.
- Lidando com desequilíbrios: seus dados têm 10.000 exemplos de uma classe, mas apenas 100 exemplos de outra?
- Colete mais dados (se puder);
- Use o pacote scikit-learn-contrib imbalanced- learn;
- Use SMOTE: técnica de sobreamostragem de minoria sintética. Ele cria amostras sintéticas de sua classe secundária para tentar nivelar o campo de jogo.
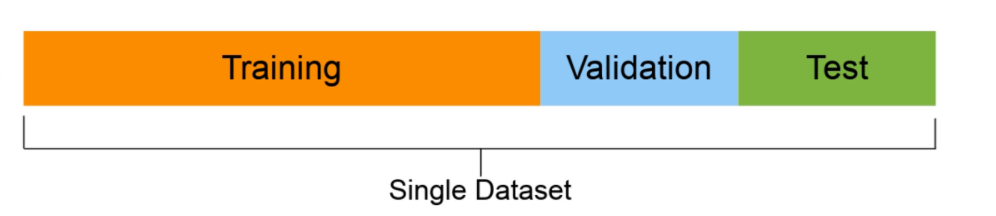
2.3 Divisão de dados
- Conjunto de treinamento: geralmente o modelo aprende com 70-80% dos dados;
- Conjunto de validação: normalmente os hiperparâmetros do modelo são ajustados com 10-15% dos dados;
- Conjunto de teste: geralmente o desempenho final dos modelos é avaliado com 10-15% dos dados. Se você fizer certo os resultados no conjunto de teste fornecerão uma boa indicação de como o modelo deve funcionar no mundo real. Não use este dataset para ajustar o modelo.
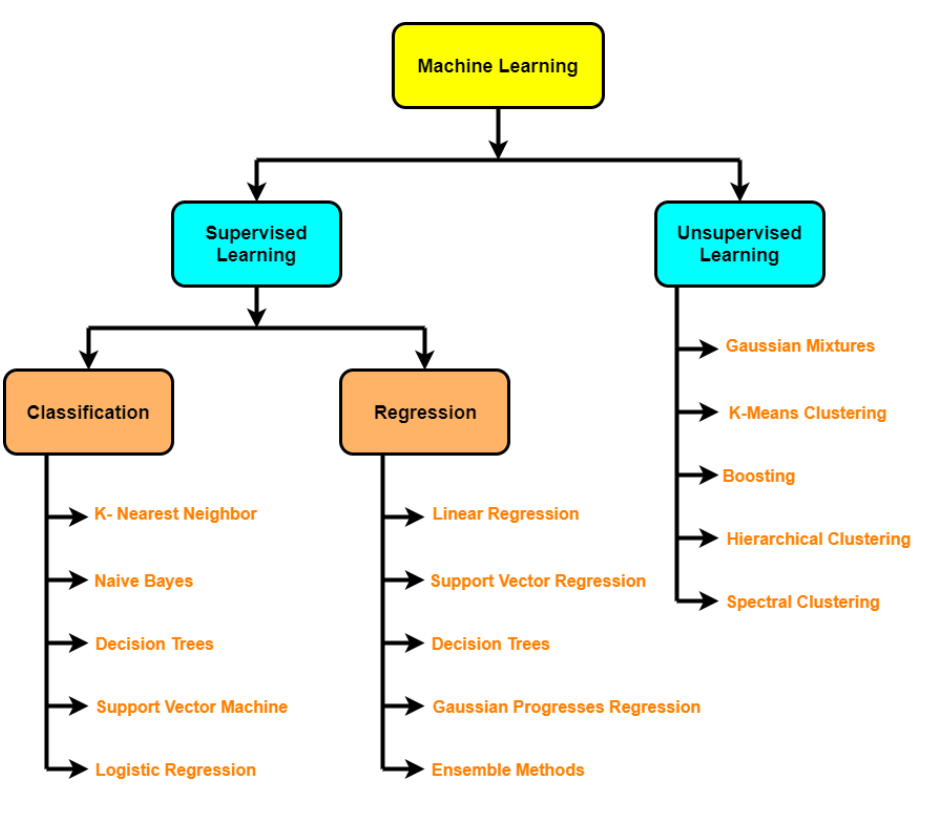
3. Treinamento e Otimização do Modelo
Escolha de algoritmos
- Algoritmos supervisionados – Regressão Linear, Regressão Logística, KNN, SVMs, Árvore de decisão e florestas aleatórias, AdaBoost / Gradient Boosting Machine (boosting);
- Algoritmos não supervisionados – Clustering, redução de dimensionalidade (PCA, Autoencoders, t-SNE), Uma detecção de anomalia.
Tipos de aprendizagem
- Aprendizagem em lote;
- Aprendizagem online;
- Aprendizagem de transferência;
- Aprendizado ativo;
- Ensembling.
Plataforma para detecção e segmentação de objetos.
- Engenharia de atributos
- Seleção de atributos
- Tipos de Algoritmos e Métodos: Filter Methods, Wrapper Methods, Embedded Methods;
- Seleção de Features com Python;
- Testes estatísticos: podem ser usados para selecionar os atributos que possuem forte relacionamento com a variável que estamos tentando prever. Os métodos disponíveis são:
- f_classif: é adequado quando os dados são numéricos e a variável alvo é categórica.
- mutual_info_classif é mais adequado quando não há uma dependência linear entre as features e a variável alvo.
- f_regression aplicado para problemas de regressão.
- Chi2: Mede a dependência entre variáveis estocásticas, o uso dessa função “elimina” os recursos com maior probabilidade de serem independentes da classe e, portanto, irrelevantes para a classificação;
- Recursive Feature Elimination – RFE: Remove recursivamente os atributos e constrói o modelo com os atributos remanescentes, ou seja, os modelos são construídos a partir da remoção de features;
- Feature Importance: Métodos ensembles como o algoritmo Random Forest, podem ser usados para estimar a importância de cada atributo. Ele retorna um score para cada atributo, quanto maior o score, maior é a importância desse atributo.
Ajuste e regularização
- Underfitting – acontece quando seu modelo não funciona tão bem quanto você gostaria. Tente treinar para um modelo mais longo ou mais avançado.
- Overfitting – acontece quando sua perda de validação começa a aumentar ou quando o modelo tem um desempenho melhor no conjunto de treinamento do que no conjunto de testes.
- Regularização: uma coleção de tecnologias para prevenir / reduzir overfitting (por exemplo, L1, L2, Dropout, Parada antecipada, Aumento de dados, normalização em lote).
Ajuste de hiperparâmetros – execute uma série de experimentos com configurações diferentes e veja qual funciona melhor.
4. Análise / Avaliação
Avaliação de métricas
- Classificação – Acurácia, precisão, recall, F1, matriz de confusão, precisão média (detecção de objeto);
- Regressão – MSE, MAE, R ^ 2;
- Métrica baseada em tarefas – por exemplo, para um carro que dirige sozinho, você pode querer saber o número de desengates.
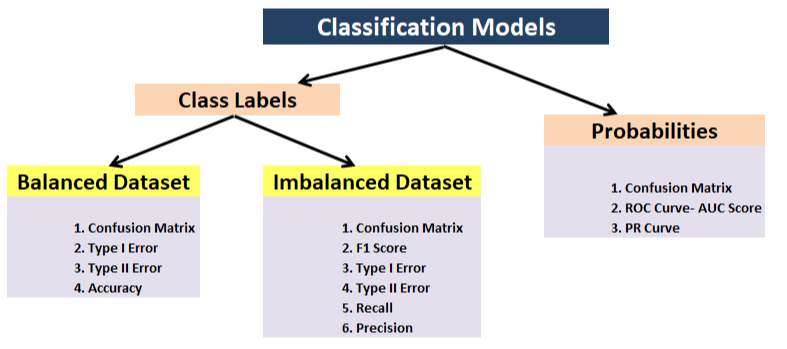
- Engenharia de atributos
- Custo de treinamento / inferência.
5. Modelo de Serviço (implantação de um modelo)
Coloque o modelo em produção;
- Ferramentas que você pode usar: TensorFlow Servinf, PyTorch Serving, Google AI Platform, Sagemaker;
- MLOps: onde a engenharia de software encontra o aprendizado de máquina, basicamente toda a tecnologia necessária em torno de um modelo de aprendizado de máquina para que funcione na produção.

- Usar o modelo para fazer previsões;
- Reavaliar.
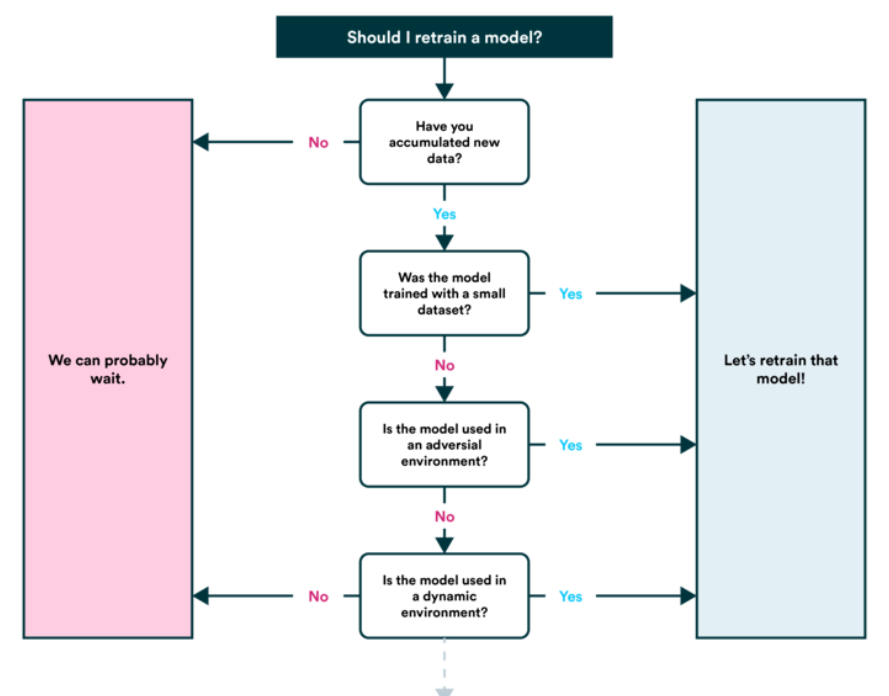
6. Modelo de retreinamento
O modelo ainda é válido para novas cargas de trabalho?
- Veja o desempenho do modelo após a veiculação (ou antes da veiculação) com base em várias métricas de avaliação e reveja as etapas acima conforme necessário. Lembre-se de que o aprendizado de máquina é muito experimental, então é aqui que você deverá rastrear seus dados e experimentos;
- Você também verá que as previsões do seu modelo começam a “envelhecer” ou “flutuar”, como quando as fontes de dados mudam ou atualizam (novo hardware, etc.). É quando você deverá retreiná-lo.
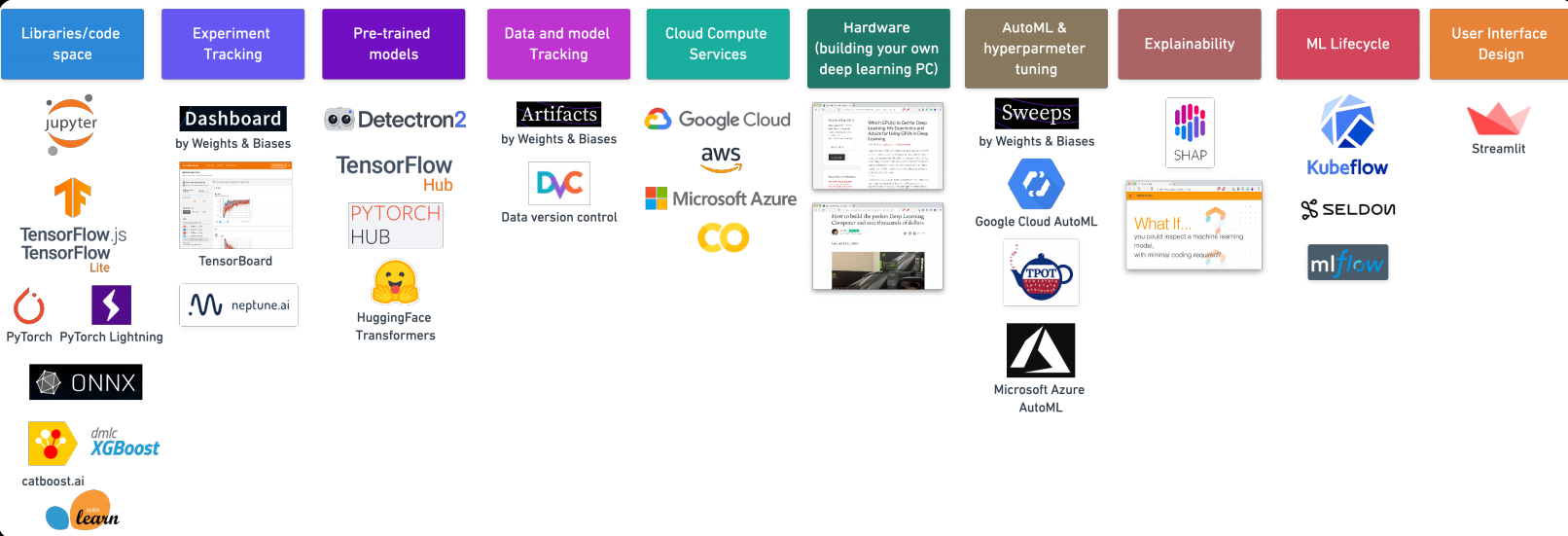
Ferramentas de Aprendizado de Máquina
Fonte: Analytics Vidhya
O que você achou desse guia? Contribua, deixe uma sugestão nos comentários!

