



A capacidade de classificar e reconhecer certos tipos de dados vem sendo exigida em diversas aplicações modernas e, principalmente, onde o Big Data é usado para tomar todos os tipos de decisões, como no governo, na economia e na medicina. As tarefas de classificação também permitem que pesquisadores consigam lidar com a grande quantidade de dados as quais têm acesso.
Neste post, iremos explorar o que são essas tarefas de classificação, tendo como foco a classificação multi-label (multirrótulo) e como podemos lidar com esse tipo de dado. Todos os processos envolvidos serão bem detalhados ao longo do texto; na parte final da matéria vamos apresentar uma aplicação para que você possa praticar o conteúdo. Prontos? Vamos à leitura! 😉
Diferentes formas de classificar
Livrarias são em sua maioria lugares amplos, às vezes com um espaço para tomar café, e com muitos, muitos livros. Se você nunca entrou em uma, saiba que é um lugar bastante organizado, onde livros são distribuídos em várias seções, como ficção-científica, fotografia, tecnologia da informação, culinária e literatura. Já pensou em como deve ser complicado classificar todos os livros e colocá-los em suas seções correspondentes?
Não parece tão difícil porque esse tipo de problema de classificação é algo que nós fazemos naturalmente todos os dias. Classificação é simplesmente agrupar as coisas de acordo com características e atributos semelhantes. Dentro do Aprendizado de Máquina, ela não é diferente. Na verdade, a classificação faz parte de uma subárea chamada Aprendizado de Máquina Supervisionado, em que dados são agrupados com base em características predeterminadas.
Basicamente, um problema de classificação requer que os dados sejam classificados em duas ou mais classes. Se o problema possui duas classes, ele é chamado de problema de classificação binário, e se possui mais de duas classes, é chamado de problema de classificação multi-class (multiclasse). Um exemplo de um problema de classificação binário seria você escolher comprar ou não um item da livraria (1 para “livro comprado” e 0 para “livro não comprado”). Já foi citado aqui um típico problema de classificação multi-class: dizer a qual seção pertence determinado livro.
O foco deste post está em um variação da classificação multi-class: a classificação multi-label, em que um dado pode pertencer a várias classes diferentes. Por exemplo, o que fazer com um livro que trata de religião, política e ciências ao mesmo tempo?
Como lidar com dados multi-label
Bem, não sabemos com exatidão como as livrarias resolvem esse problema, mas sabemos que, para qualquer problema de classificação, a entrada é um conjunto de dados rotulado composto por instâncias, cada uma associada a um conjunto de labels (rótulos ou classes).

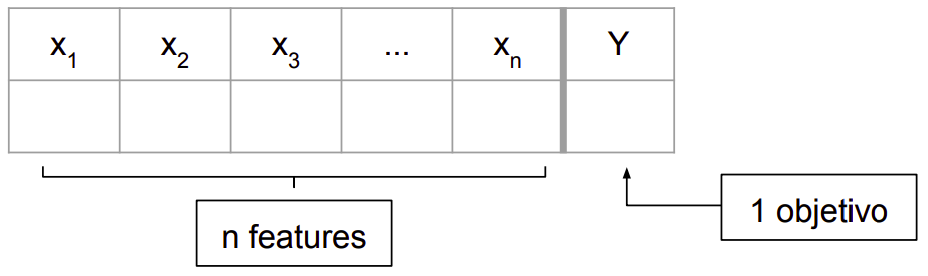

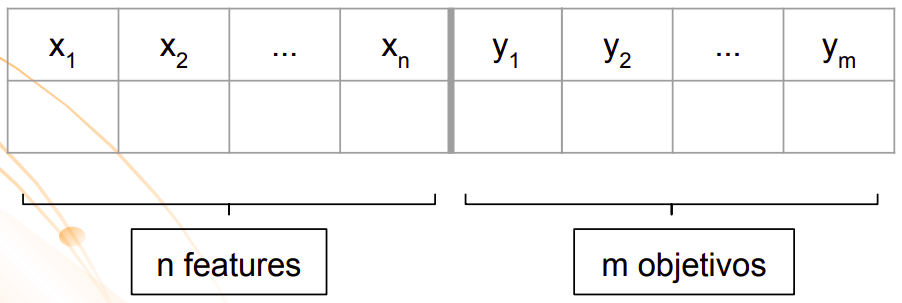
Para que algo seja classificado, um modelo precisa ser construído em cima de um algoritmo de classificação. Tem como garantir que o modelo seja realmente bom antes mesmo de executar ele? Sim! É por isso que os experimentos para esse tipo de problema normalmente envolvem uma primeira etapa: a divisão dos dados em treino (literalmente o que será usado para treinar o modelo) e teste (o que será usado para validar o modelo).
A forma como essa etapa é feita pode variar dependendo da quantidade total do conjunto de dados. Quando os dados são abundantes, utiliza-se um método chamado holdout, em que o dataset (conjunto de dados) é dividido em conjuntos de treino e teste e, às vezes, em um conjunto de validação. Caso os dados sejam limitados, a técnica utilizada para esse tipo de problema é chamada de validação cruzada (cross-validation), que começa dividindo o conjunto de dados em um número de subconjuntos de mesmo tamanho, ou aproximado.

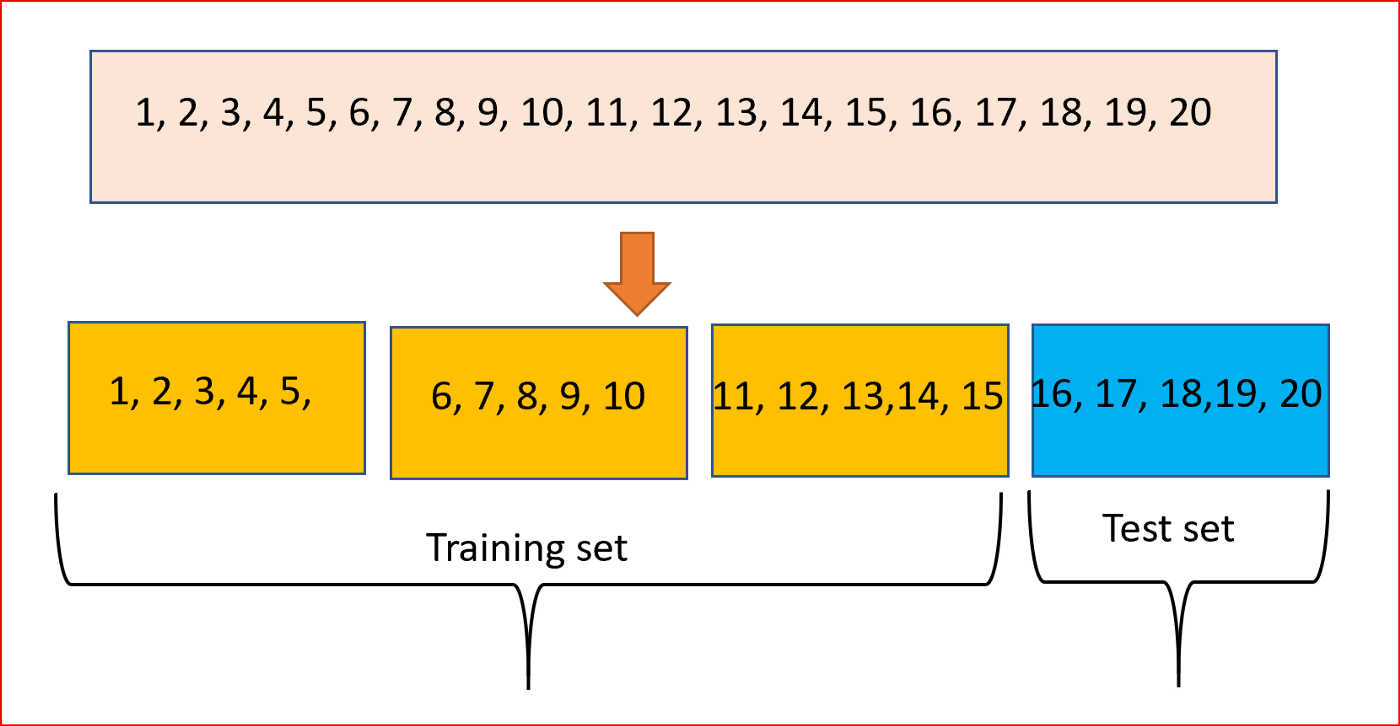
Nas tarefas de classificação, geralmente é usada a versão estratificada desses dois métodos, que divide o conjunto de dados de forma que a proporção de cada classe nos conjuntos de treino e teste sejam aproximadamente iguais a de todo o conjunto de dados. Parece algo simples, mas os algoritmos que realizam esse procedimento o fazem de forma aleatória e não fornecem divisões balanceadas.
Além disso, essa distribuição aleatória pode levar à falta de uma classe rara (que possui poucas ocorrências) no conjunto de teste. A maneira típica como esses problemas são ignorados na literatura é através da remoção completa dessas classes. Isso, no entanto, implica que tudo bem se ignorar esse rótulo, o que raramente é verdadeiro, já que pode interferir tanto no desempenho do modelo quanto nos cálculos das métricas de avaliação.
Agora que a parte teórica foi explicada, vamos à parte prática! 🙂
Apresentação da biblioteca Scikit-multilearn
Sabia que existe uma biblioteca Python voltada apenas para problemas multi-label? Pois é, e ainda possui um nome bem sugestivo: Scikit-multilearn, tudo porque foi construída sob o conhecido ecossistema do Scikit-learn.
O Scikit-multilearn permite realizar diversas operações, mediante as implementações nativas do Python encontradas na biblioteca de métodos populares da classificação multi-label. Caso tenha curiosidade de saber tudo o que ela pode fazer, clique aqui.
A implementação da estratificação iterativa do Scikit-multilearn visa fornecer uma distribuição equilibrada das evidências das classes até uma determinada ordem. Para analisarmos o que isso significa, vamos carregar alguns dados.
Definição do problema
A competição Toxic Comment Classification do Kaggle se trata de um problema de classificação de texto, mais precisamente de classificação de comentários tóxicos. Os participantes devem criar um modelo multi-label capaz de detectar diferentes tipos de toxicidade nos comentários, como ameaças, obscenidade, insultos e ódio baseado em identidade.
Usaremos como conjunto de dados o conjunto de treino desbalanceado disponível na competição para ilustrar o problema de estratificação de dados multi-label. Esses dados contém um grande número de comentários do Wikipédia, classificados de acordo com os seguintes rótulos:


Avisamos que os comentários desse dataset podem conter texto profano, vulgar ou ofensivo, por isso algumas imagens apresentadas aqui estão borradas. O link para baixar o arquivo train.csv pode ser acessado aqui.
Análise exploratória
Inicialmente, iremos fazer uma breve análise dos dados de modo que possamos resumir as principais características do dataset. Todos os passos até a estratificação estão exemplificados abaixo, com imagens e exemplos em código Python. Se algum código estiver omitido, então alguns trechos são bastante extensos ou se tratam de funções pré-declaradas. Pedimos que acessem o código detalhado, disponível no GitHub, para um maior entendimento.
- Primeiro, vamos carregar os dados do arquivo train.csv e checar os atributos.
df = pd.read_csv('train.csv')
print('Quantidade de instâncias: {}\nQuantidade de atributos: {}\n'.format(len(df), len(df.columns)))
df[0:7]
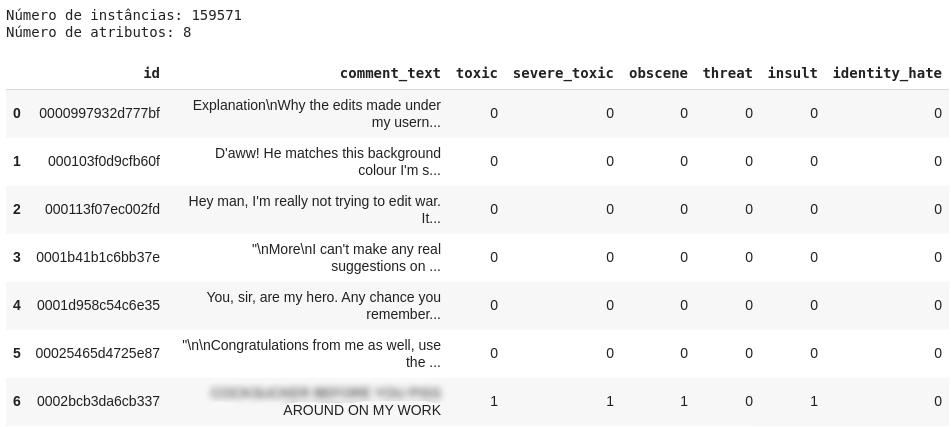

Percebe-se que cada label está representada como uma coluna, onde o valor 1 indica que o comentário possui aquela toxicidade e o valor 0 indica que não. Os 6 primeiros textos listados no dataframe não foram classificados em nenhum tipo de toxicidade. Na verdade, quase 90% desse dataset possui textos sem classificação. Não será um problema para nós, pois o método que iremos utilizar considera apenas as classificações feitas.
- Agora, vamos computar as ocorrências de cada classe, ou seja, quantas vezes cada uma aparece, como também contar o número de comentários que foram classificados com uma ou mais classes. Já podemos notar na imagem acima do dataframe que o texto presente no índice 6 foi classificado como toxic, severe_toxic, obscene e insult.
labels = list(df.iloc[:, 2:].columns.values) labels_count = df.iloc[:, 2:].sum().values comments_count = df.iloc[:, 2:].sum(axis=1) multilabel_counts = (comments_count.value_counts()).iloc[1:] indexes = [str(i) + ' label' for i in multilabel_counts.index.sort_values()] plot_histogram_labels(title='Contagem das frequências de cada classe', x_label=labels, y_label=labels_count, labels=labels_count) plot_histogram_labels(title='Quantidade de comentários classificados em >= 1 classe', x_label=indexes, y_label=multilabel_counts.values, labels=multilabel_counts)

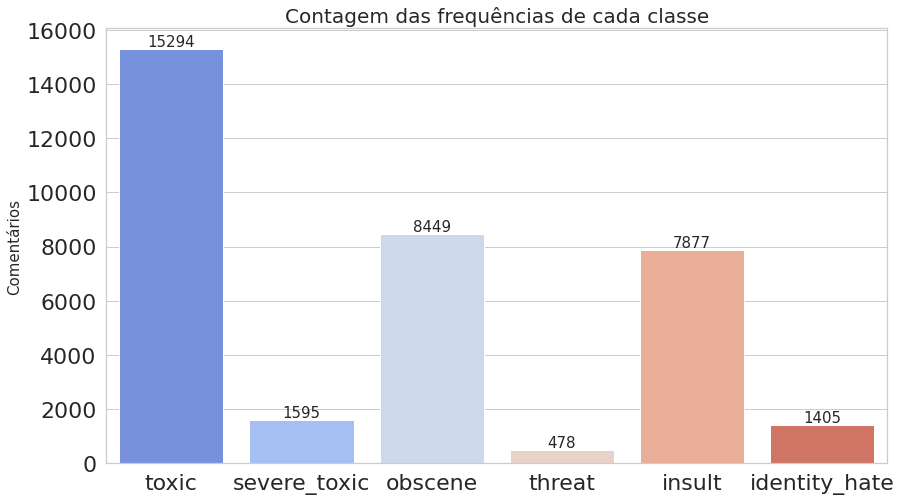
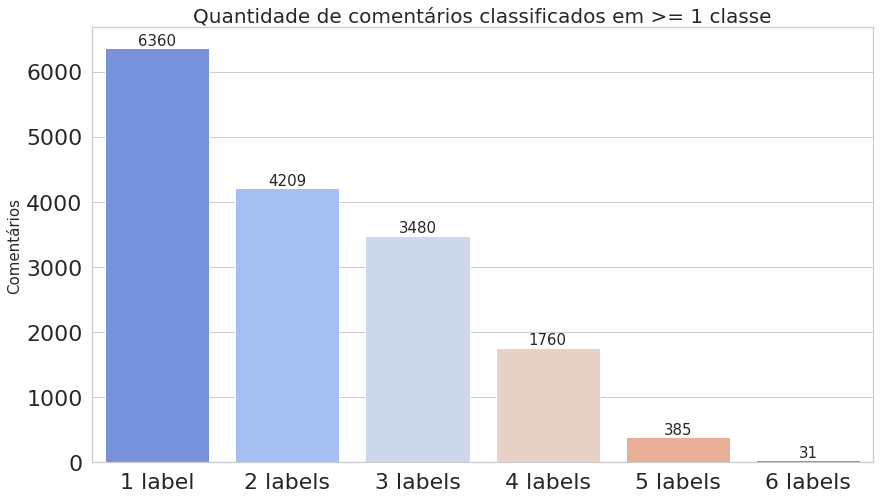

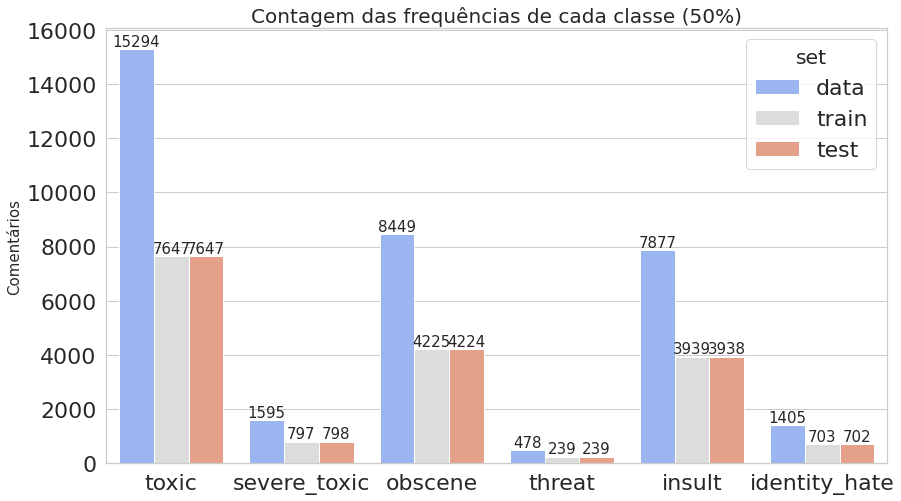
O primeiro gráfico mostra que o dataset é realmente desbalanceado, enquanto o segundo deixa claro que estamos trabalhando com dados multi-label.
Pré-processamento dos dados
O dataset não possui dados faltantes ou duplicados, e nem comentários nulos ou sem classificação (basta olhar como essa análise foi feita aqui no código completo). Apesar de não existirem problemas que podem interferir na qualidade dos dados, um pré-processamento ainda precisa ser feito, pois o intuito é seguir os mesmos passos geralmente realizados até a separação dos dados em treino e teste.
Para esse tipo de problema de classificação de texto, normalmente o pré-processamento envolve o tratamento e limpeza do texto (converter o texto apenas para letras minúsculas, remover as URLs, pontuação, números, etc.), e remoção das stopwords (conjunto de palavras comumente usadas em um determinado idioma). Devemos realizar esse tratamento para que possamos focar apenas nas palavras importantes.
tqdm.pandas(desc='Limpando o texto') df['text_tokens'] = df['comment_text'].progress_apply(clean_text) tqdm.pandas(desc='Removendo as stopwords e tokenizando o texto') df['text_tokens'] = df['text_tokens'].progress_apply(remove_stopwords) df[['comment_text', 'text_tokens']].head()
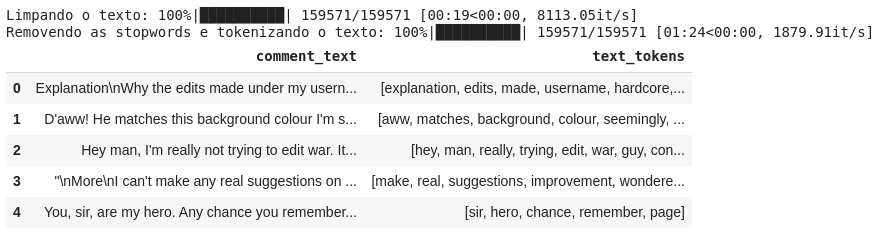

Como ilustrado na figura, também foi feito a tokenização do texto, um processo que envolve a separação de cada palavra (tokens) em blocos constituintes do texto, para depois convertê-los em vetores numéricos.
Processo de estratificação
Para divisão do conjunto de dados em conjuntos de treino e teste, usaremos o método iterative_train_test_split da biblioteca Scikit-multilearn. Antes de prosseguir, esse método assume que possuímos as seguintes matrizes:


Devemos, então, fazer alguns tratamentos para obtermos o X e o y ideais para serem usados como entrada na função. Além disso, também passamos como parâmetro a proporção que desejamos para o teste (o restante será colocado no conjunto de treino). Esse método nos retornará a divisão estratificada do dataset (X_train, y_train, X_test, y_test).
- Inicialmente, iremos gerar o X. Até agora o que temos são os tokens do texto, então precisamos mapeá-los para transformá-los em números. Para isso, podemos pegar todas as palavras (tokens) presentes em text_tokens e atribuir a cada uma um id. Assim, criaremos uma espécie de vocabulário.
text_tokens = []
VOCAB = {}
for vet in df['text_tokens'].values:
text_tokens.extend(vet)
text_tokens_set = (list(set(text_tokens)))
for index, word in enumerate(text_tokens_set):
VOCAB[word] = index + 1
print('Quantidade de palavras presentes no texto: {}'.format(len(text_tokens)))
print('Tamanho do vocabulário (palavras sem repetição): {}\n'.format(len(text_tokens_set)))
VOCAB


- Com esse vocabulário, conseguimos mapear as palavras para os id’s.
from tensorlayer.nlp import words_to_word_ids df['X'] = df['text_tokens'].apply(lambda tokens : words_to_word_ids(tokens, VOCAB)) df[['comment_text', 'text_tokens', 'X']].head()
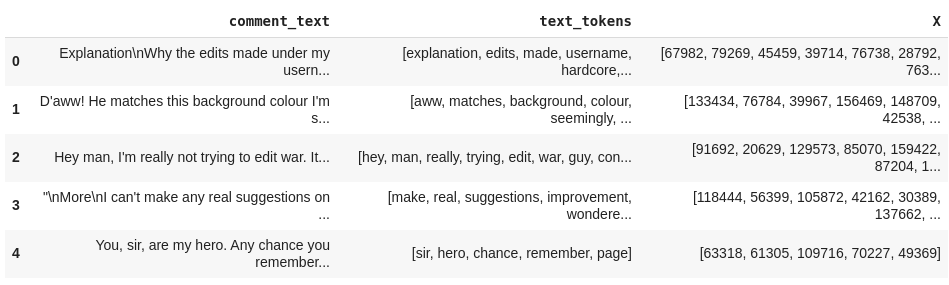

- Como o X deve ter a dimensão (número_de_amostras, número_de_instâncias) e como o tamanho de alguns textos deve ser bem maior que de outros, temos que achar o texto com a maior quantidade de palavras e salvar seu tamanho. Depois, fazemos um padding (preenchimento) no restante dos textos, acrescentando 0’s no final de cada vetor até atingir o tamanho máximo estabelecido.
A matriz do y deve conter a dimensão (número_de_amostras, número_de_labels), então pegamos os valores das colunas referentes às classes. Atente para o fato de que cada posição dos vetores presentes em y corresponde a uma classe.
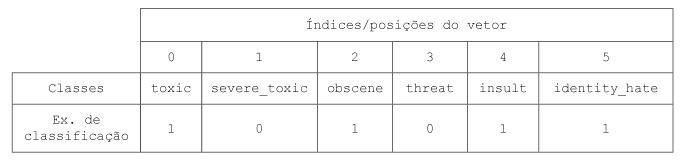

Outra forma de criação do y seria contar as ocorrências das classes para cada texto. Logo, ao invés de utilizar valores binários para indicar que existem palavras pertencentes ou não a um rótulo, colocaríamos os valores das frequências desses rótulos.

df['num_words'] = df['text_tokens'].apply(lambda x : len(x)) max_num_words = df['num_words'].max() df[['comment_text', 'text_tokens', 'num_words']].nlargest(5, 'num_words')

from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(maxlen=max_num_words, sequences=df['X'], value=0, padding='post', truncating='post')
y = df[labels].values
print('Dimensão do X: {}'.format(X.shape))
print('Dimensão do y: {}'.format(y.shape))
![]()

5. Pronto! Agora podemos fazer a divisão do dataset. Demonstraremos dois exemplos: dividir o dataset em 50% para treino e teste, e dividir em 80% para treino e 20% para teste.
from skmultilearn.model_selection import iterative_train_test_split # 50% para cada np.random.seed(42) X_train, y_train, X_test, y_test = iterative_train_test_split(X, y, test_size=0.5) # 80% para treino e 20% para teste np.random.seed(42) X_train_20, y_train_20, X_test_20, y_test_20 = iterative_train_test_split(X, y, test_size=0.2)


Os conjuntos de treino e teste estão realmente estratificados?
Por fim, iremos analisar se a proporção entre as classes foi realmente mantida.
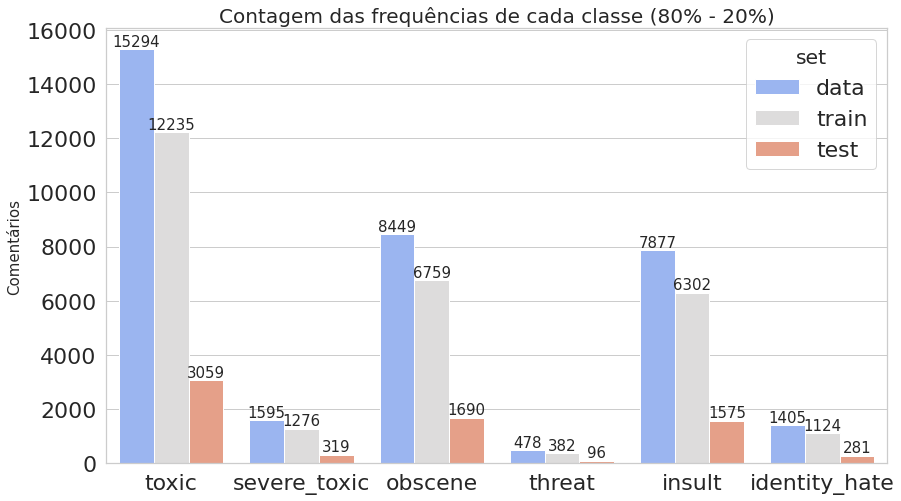
- Plotamos novamente os gráficos que contam quantas vezes cada classe aparece, comparando todo o conjunto de dados com os dados de treino e teste obtidos.
plot_histogram_labels('Contagem das frequências de cada classe (50%)', x_label='labels', y_label='ocorr', labels=classif_train_test, hue_label='set', data=inform_train_test)
plot_histogram_labels('Contagem das frequências de cada classe (80% - 20%)', x_label='labels', y_label='ocorr', labels=classif_train_test_20, hue_label='set', data=inform_train_test_20)
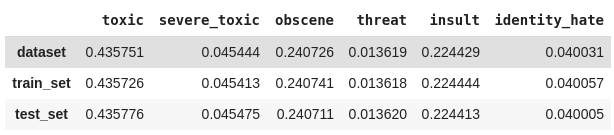
2. Podemos calcular manualmente a proporção das classes dividindo a quantidade de ocorrências de cada classe pelo número total de classificações. Também iremos verificar se a divisão está proporcional utilizando uma métrica do Scikit-multilearn que retorna as combinações das classes atribuídas a cada linha.
prop_data = calculates_labels_proportion(classif_data, labels)
prop_train = calculates_labels_proportion(classif_train, labels)
prop_test = calculates_labels_proportion(classif_test, labels)
result_prop = pd.concat([prop_data, prop_train, prop_test], ignore_index=True)
result_prop.rename(index={
0: 'dataset',
1: 'train_set',
2: 'test_set'}, inplace=True)
result_prop

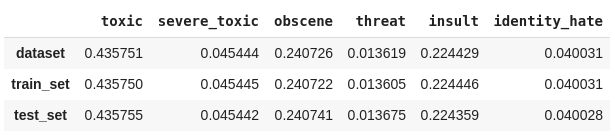
prop_data_20 = calculates_labels_proportion(classif_data, labels)
prop_train_20 = calculates_labels_proportion(classif_train_20, labels)
prop_test_20 = calculates_labels_proportion(classif_test_20, labels)
result_prop_20 = pd.concat([prop_data_20, prop_train_20, prop_test_20], ignore_index=True)
result_prop_20.rename(index={
0: 'dataset',
1: 'train_set',
2: 'test_set'}, inplace=True)
result_prop_20

from collections import Counter
from skmultilearn.model_selection.measures import get_combination_wise_output_matrix
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test, order=1) for combination in row)
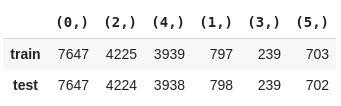

pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train_20, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test_20, order=1) for combination in row)
}).T.fillna(0.0)


É isso, gente. Esperamos que esse post tenha sido útil, principalmente para quem já enfrentou um problema parecido e não soube o que fazer.
Até mais!
Referências
- Multi-label data stratification. 2019. Scikit-multilearn: Multi-Label Classification in Python.
- Sechidis, Konstantinos, Grigorios Tsoumakas, and Ioannis Vlahavas. “On the stratification of multi-label data” Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, Berlin, Heidelberg, 2011.
- Szymański, Piotr, and Tomasz Kajdanowicz. “A network perspective on stratification of multi-label data” arXiv preprint arXiv:1704.08756 (2017).
- Classification Problems. Brilliant.org. Karleigh Moore e Christopher Williams.
- Deep dive into multi-label classification. 2018. Towards Data Science. Kartik Nooney.
Imagens
- K fold and other cross-validation techniques. 2018. Medium. Renu Khandelwal.
- Rotulação Automática. 2016. SlideShare. Felipe Almeida.
