O livro Mathematics for Machine Learning é a dica certa para você que precisa de um apoio nos seus estudos. Escrito para motivar as pessoas a aprenderem conceitos matemáticos a obra não se destina a cobrir técnicas avançadas sobre o assunto, mas pretende fornecer as habilidades matemáticas necessárias para isso.
Conteúdo
Este exemplar pretende simplificar o conhecimento sobre matemática para Machine Learning, introduzindo os conceitos matemáticos com um mínimo de pré-requisitos. As ferramentas matemáticas fundamentais necessárias para entender ML que são apresentadas na primeira parte do livro incluem:
Álgebra linear;
Geometria Analítica;
Decomposição de Matriz;
Cálculo Vetorial;
Otimização;
Probabilidade e estatística.
Esses tópicos são tradicionalmente ensinados em cursos distintos, tornando difícil para os alunos de ciência de dados ou profissionais da área, aprenderem matemática com eficiência. Na segunda parte do livro serão apresentados os seguintes problemas de aprendizado de máquina central:
Quando os modelos encontram os dados;
Regressão linear;
Redução de dimensionalidade com análise de componente principal;
Estimativa de densidade com modelos de mistura gaussiana;
Classificação com máquinas de vetores de suporte.
Público direcionado
Para alunos e outras pessoas com formação matemática, o livro irá oferecer um ponto de partida para a matemática para Machine Learning. Para aqueles que estão aprendendo matemática pela primeira vez, os métodos contidos no livro ajudam a construir intuição e experiência prática com a aplicação de conceitos matemáticos. Cada capítulo inclui exemplos trabalhados e exercícios para testar a compreensão, além de tutoriais de programação oferecidos no site do livro.
Avaliação
De acordo com a opinião dos leitores, Mathematics for Machine Learning é um livro com explicações claras e objetivas sobre matemática aplicada ao aprendizado de Máquina.O livro é muito bem avaliado por seus leitores na Amazon, recebendo uma nota 4.6 de 5 com mais de 100 opiniões.
Autores
Marc Peter Deisenroth é Diretor da DeepMind em Inteligência Artificial no Departamento de Ciência da Computação da University College London. Suas áreas de pesquisa incluem aprendizagem eficiente em dados, modelagem probabilística e tomada de decisão autônoma. Em 2018, ele foi agraciado com o Prêmio do Presidente de Pesquisador de Excelência em Início de Carreira no Imperial College London.
Aldo Faisal lidera o Brain and Behavior Lab do Imperial College London, onde é professor dos Departamentos de Bioengenharia e Computação e membro do Data Science Institute. Faisal estudou Ciência da Computação e Física na Universität Bielefeld (Alemanha). Obteve Ph.D. em Neurociência Computacional na Universidade de Cambridge e tornou-se Pesquisador Júnior no Laboratório de Aprendizagem Computacional e Biológica.
Cheng Soon Ong é Cientista de Pesquisa Principal do Grupo de Pesquisa de Aprendizado de Máquina, Data61 e professor da Australian National University. Sua pesquisa se concentra em permitir a descoberta científica, estendendo os métodos estatísticos de Aprendizado de Máquina. Possui Ph.D. em Ciência da Computação na Australian National University e pós-doctor no Instituto Max Planck de Cibernética Biológica e no Laboratório Friedrich Miescher.
Por tratar-se de uma nova ameaça, sabe-se muito pouco sobre o coronavírus (Sars-CoV-2). Esse fator dá grande abertura para disseminação de fake news (como ficou popularmente conhecido o compartilhamento de informações falsas), que podem ir desde supostos métodos de prevenção, tratamentos caseiros, cura do vírus e até mesmo tratamentos controversos recomendados por médicos, mesmo que não haja comprovação ou evidência científica para tais. Tudo isso pode dificultar o trabalho de órgãos de saúde, prejudicar a adoção de medidas de distanciamento social pela população e acarretar aumentos dos números de infectados e de morte pelo vírus.
Para diminuir os impactos dessa desinformação, diversos sites de checagem de fatos têm ferramentas que identificam e classificam (manualmente) tais notícias. Em geral, essas ferramentas poderiam fazer uso de algoritmos de aprendizagem de máquina para classificação de notícias. Diante dessa problemática, é evidente a necessidade de elaborar mecanismos e ferramentas que possam combater eficientemente o caos das fakes news.
Por isso, durante as disciplinas de Aprendizagem de Máquina e Mineração de Dados (Programa de Pós-graduação em Ciência da Computação da Universidade Federal do Ceará (MDCC-UFC)), nós(Andreza Fernandes, Felipe Marcel, Flávio Carneiro e Marianna Ferreira) propusemos um detector de fake news para analisar notícias sobre o COVID-19 divulgadas em redes sociais. Nosso objetivo é ajudar a população quanto ao esclarecimento da veracidade dessas informações.
Agora, detalharemos o processo de desenvolvimento desse detector de fake news.
Objetivos do projeto
Formar uma base dados de textos com notícias falsas e verdadeiras acerca do COVID-19;
Diminuir enviesamento das notícias;
Experimentar diferentes representações textuais;
Experimentar diferentes abordagens clássicas de aprendizagem de máquina e deep learning;
Construir um BOT no Telegram que ajude na detecção de notícias falsas relacionadas ao COVID-19.
Entendendo as terminologias usadas
Para o entendimento dos experimentos realizadas, vamos conceituar alguns pontos chaves e técnicas de Processamento de Linguagem Natural.
Tokenização: Esse processo transforma todas as palavras de um texto, dado como entrada, em elementos (conhecidos como tokens) de um vetor.
Remoção de Stopwords: Consiste na remoção de palavras de parada, como “a”, “de”, “o”, “da”, “que”, “e”, “do”, dentre outras, pois na maioria das vezes não são informações relevantes para a construção do modelo.
Bag of words: É uma representação simplificada e esparsa dos dados textuais. Consiste em gerar uma bolsa de palavras do vocabulário existente no dado, que constituirá as features do dataset. Para cada sentença é assinalado um “1” nas colunas que apresentam as palavras que ocorrem na sentença e “0” nas demais.
Term Frequency – Inverse Document Frequency (TF-IDF): Indica a importância de uma palavra em um documento. Enquanto TF está relacionada à frequência do termo, IDF busca balancear a frequência de termos mais comuns/frequentes que outros.
Word embeddings: É uma forma utilizada para representar textos, onde palavras que possuem o mesmo sentido têm uma representação muito parecida. Essa técnica aprende automaticamente, a partir de um corpus de dados, a correlação entre as palavras e o contexto, possibilitando que palavras que frequentemente ocorrem em contextos similares possuam uma representação vetorial próxima. Essa representação possui a vantagem de ter um grande poder de generalização e apresentar baixo custo computacional, uma vez que utiliza representações densas e com poucas dimensões, em oposição a técnicas esparsas, como Bag of Words. Para gerar o mapeamento entre dados textuais e os vetores densos mencionados, existem diversos algoritmos disponíveis, como Word2Vec e FastText, os quais são utilizados neste trabalho.
Out-of-vocabulary (OOV): Consiste nas palavras presentes no dataset que não estão presentes no vocabulário da word embedding, logo, elas não possuem representação vetorial.
Edit Distance: Métrica que quantifica a diferença entre duas palavras, contando o número mínimo de operações necessárias para transformar uma palavra na outra.
Metodologia
Agora iremos descrever os passos necessários para a obtenção dos resultados, geração dos modelos e escolha daquele com melhor performance para a efetivação do nosso objetivo.
Obtenção dos Dados
Os dados utilizados para a elaboração dos modelos foram adquiridos das notícias falsas brasileiras sobre o COVID-19, dispostos noChequeado, e de um web crawler dos links das notícias, utilizadas para comprovar que a notícia é falsa no Chequeado, para formar uma base de notícias verdadeiras. Além disso também foi realizado um web crawler para obtenção de notícias doFato Ou Fakedo G1.
Originalmente, os dados obtidos do Chequeado possuíam as classificações “Falso”, “Enganoso”, “Parcialmente falso”, “Dúbio”, “Distorcido”, “Exagerado” e “Verdadeiro mas”, que foram mapeadas todas para “Falso”. Com isso, transformamos nosso problema em classificação binária.
No final, obtivemos um dataset com 1.753 notícias, sendo 808 fakes, simbolizada como classe 0, e 945 verdadeiras, classe 1, com um vocabulário de tamanho 3.698. Com isso, dividimos o nosso dado em conjunto de treino e teste, com tamanhos de 80% e 20%, respectivamente.
Pré-processamento
Diminuição do viés. Ao trabalhar e visualizar os dados, notamos que algumas notícias verdadeiras vinham com palavras e sentenças que enviesavam e deixavam bastante claro para os algoritmos o que é fake e o que é verdadeiro, como: “É falso que”, “#Checamos”, “Verificamos que” e etc. Com isso, removemos essas sentenças e palavras, a fim de diminuir o enviesamento das notícias.
Limpeza textual. Após a etapa anterior, realizamos a limpeza do texto, consistindo em remoção de caracteres estranhos e sinais de pontuação e uso do texto em caixa baixa.
Tokenização. A partir do texto limpo, inicializamos o processo de tokenização das sentenças.
Remoção das Stopwords. A partir das sentenças tokenizadas, removemos as stopwords.
Representação textual
Análise exploratória
A partir do pré-processamento dos dados brutos, inicializamos o processo de análise exploratória dos dados. Verificamos o tamanho do vocabulário do nosso dataset, que totaliza 3.698 palavras.
Análise do Out-of-vocabulary. Com isso, verificamos o tamanho do nosso out-of-vocabulary em relação às word embeddings pré-treinadas utilizadas, totalizando 32 palavras. Um fato curioso é que palavras chaves do nosso contexto encontram-se no out-of-vocabulary e acabam sendo mapeadas para palavras que não tem muita conexão com o seu significado. Abaixo é possível ver algumas dessas palavras mais à esquerda, e a palavra a qual foram mapeadas mais à direita.
Mapeamento de palavras
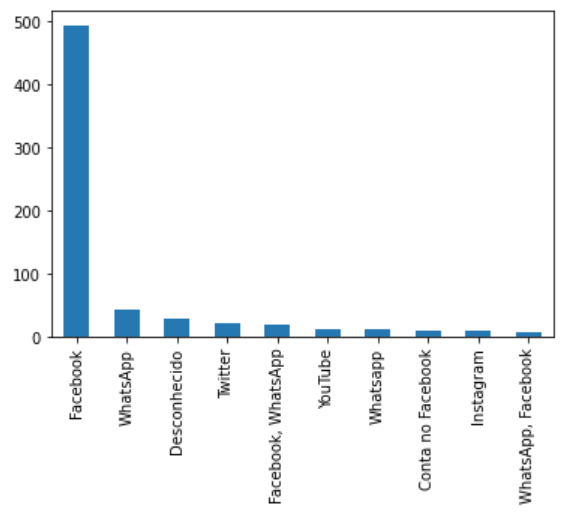
Análise da frequência das fake news por rede social. O dado bruto original advindo do Chequeado possui uma coluna que diz sobre a mídia social em que a fake news foi divulgada. Após uma análise visual superficial, apenas plotando a contagem dos valores dessa coluna (que acarreta até na repetição de redes sociais), notamos que os maiores veículos de propagação de fake news são o Facebook e Whatsapp.
Frequência de fake news por rede social
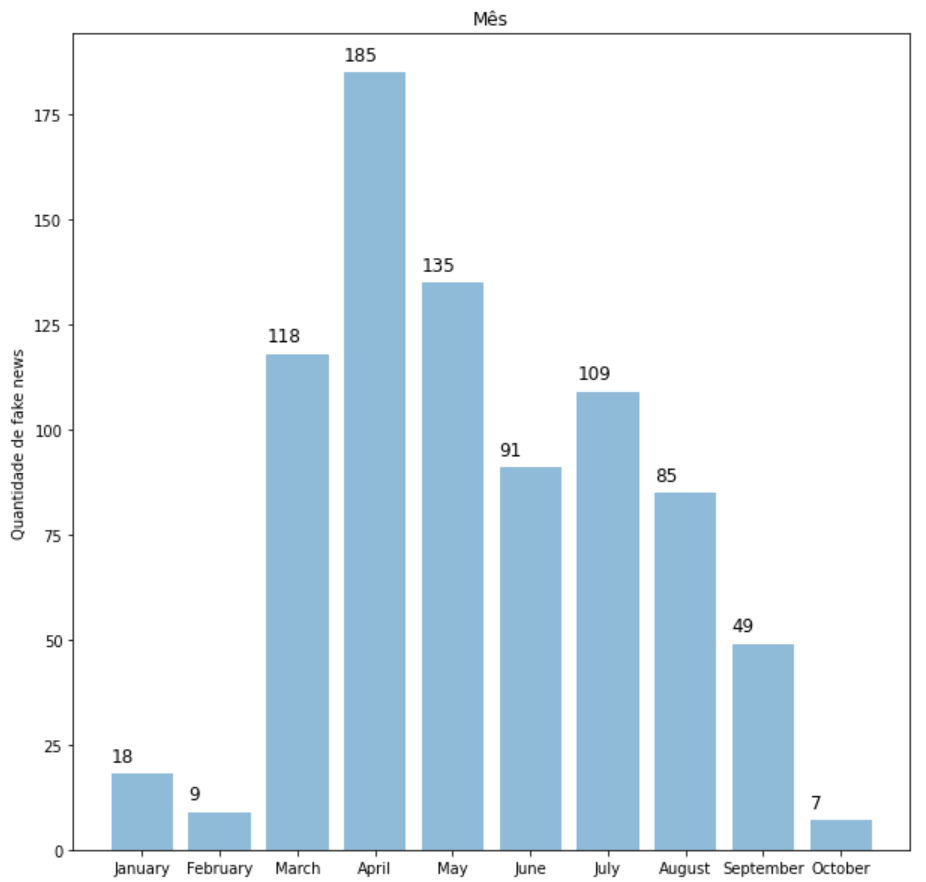
Análise da quantidade de fake news ao longo dos meses. O dado bruto original advindo do Chequeado também possui uma coluna que informava a data de publicação da fake news. Após realizar uma análise visual da distribuição da quantidade de fake news ao longo dos meses, notamos que o maior número de fake news ocorreu em abril, mês em que a doença começou a se espalhar com maior velocidade no território brasileiro. De acordo com o G1, em 28 de abril, o Brasil possuía 73.235 casos do novo coronavírus (Sars-CoV-2), com 5.083 mortes. Além disso, foi nesse mês que começaram a surgir os boatos de combate do Coronavírus via Cloroquina, além de remédios caseiros.
Volume de fake news relacionadas ao COVID-19 ao longo dos meses
Análise da Word Cloud. Com as sentenças tokenizadas, também realizamos uma visualização usando a técnica de Word Cloud, que apresenta as palavras do vocabulário em um tamanho proporcional ao seu número de ocorrência no todo. Com essa técnica, realizamos duas visualizações, uma para as notícias verdadeiras e outra para as fake news.
Nuvem de palavras nas notícias falsas
Nuvem de palavras nas notícias verdadeiras
Divisão treino e teste
A divisão dos conjuntos de dados entre treino e teste foi feita com uma distribuição de 80% e 20% dos dados, respectivamente.Os dados de treino foram ainda divididos em um novo conjunto de treino e um de validação, com uma distribuição de 80% e 20% respectivamente.
Aplicação dos modelos
Para gerar os modelos, escolhemos algoritmos e técnicas clássicas de aprendizagem de máquina, tais como técnicas atuais e bastante utilizadas em competições, sendo eles:
Regressão Logística (*): exemplo de classificador linear;
K-NN (*): exemplo de modelo não-paramétrico;
Análise Discriminante Gaussiano (*): exemplo de modelo que não possui hiperparâmetros;
Árvore de Decisão: exemplo de modelo que utiliza abordagem da heurística gulosa;
Random Forest: exemplo de ensemble de bagging de Árvores de Decisão;
SVM: exemplo de modelo que encontra um ótimo global;
XGBoost: também um ensemble amplamente utilizado em competições do Kaggle;
LSTM-Dense: exemplo de arquitetura que utiliza deep learning.
Os algoritmos foram utilizados por meio de implementações próprias (aqueles demarcados com *) e uso da biblioteca scikit-learn e keras. Para todos os algoritmos, com exceção daqueles que não possuem hiperparâmetros e LSTM-Dense, realizamos Grid Search em busca dos melhores hiperparâmetros e realizamos técnicas de Cross Validation para aqueles utilizados por meio do Scikit-Learn, com k fold igual a 5.
Obtenção das métricas
As métricas utilizadas para medir a performance dos modelos foram acurácia, Precision, Recall, F1-score e ROC.
Tabela 1. Resultados das melhores representações por algoritmo
MODELOS
PRECISION
RECALL
F1-SCORE
ACCURACY
ROC
XGBoost BOW e TF-IDF*
1
1
1
1
1
SVM BOW E TF-IDF*
1
1
1
1
1
Regressão Logística BOW
0.7560
0.7549
0.7539
0.7549
0.7521
LSTM FASTTEXT
0.7496
0.7492
0.7493
0.7492
0.7492
Random Forest TF-IDF
0.7407
0.7407
0.7402
0.7407
0.7388
Árvore de Decisão TF-IDF
0.7120
0.7122
0.7121
0.7122
0.7111
Análise Discriminante Gaussiano Word2Vec
0.7132
0.7122
0.7106
0.7122
0.7089
k-NN FastText
0.6831
0.6809
0.6775
0.6638
0.6550
Tabela 2. Resultados das piores representações por algoritmo
MODELOS
PRECISION
RECALL
F1-SCORE
ACCURACY
ROC
XGBoost Word2Vec
0.7238
0.7236
0.7227
0.7236
0.7211
SVM Word2Vec
0.7211
0.7179
0.7151
0.7179
0.7135
Árvore de Decisão Word2Vec
0.6391
0.6353
0.6351
0.6353
0.6372
Random Forest Word2Vec
0.6231
0.6210
0.6212
0.6210
0.62198
Regressão Logística FastText
0.6158
0.5982
0.5688
0.59829
0.5858
Análise Discriminante Gaussiano TF-IDF
0.5802
0.5811
0.5801
0.5811
0.5786
k-NN BOW
0.5140
0.5099
0.5087
0.5042
0.5127
LSTM WORD2VEC (*)
0.4660
0.4615
0.4367
0.4615
0.4717
Resultados
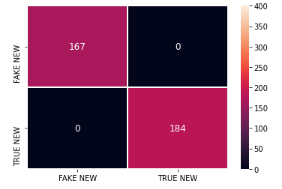
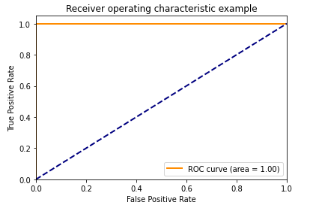
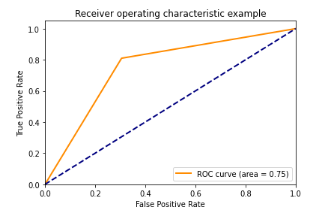
Com os resultados apresentados percebemos que os modelos SVM e XGBoost com as representações TF-IDF e BOW atingiram as métricas igual a 100%. Isso pode ser um grande indicativo de sobreajuste do modelo aos dados. Abaixo podemos visualizar a matriz de confusão e a curva ROC dos mesmos.
Matriz de confusão
Curva ROC
Logo após vem a Regressão Logística com métricas em torno de ~75.49%! Abaixo podemos visualizar sua matriz de confusão e a curva ROC.
Matriz de confusão
Curva ROC
Exemplos de classificações da Regressão Logística
True Positive (corretamente classificada)
Texto que diz que vitamina C e limão combatem o coronavírus
True Negative (corretamente classificada)
Notícia divulgada em 2015 pela TV italiana RAI comprova que o novo coronavírus foi criado em laboratório pelo governo chinês.
False Positive (erroneamente classificada)
Vitamina C com zinco previne e trata a infecção por coronavírus
False Negative (erroneamente classificada)
Que neurocientista britânico publicou estudo mostrando que 80% da população é imune ao novo coronavírus
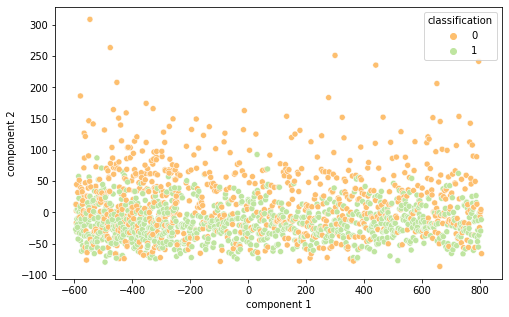
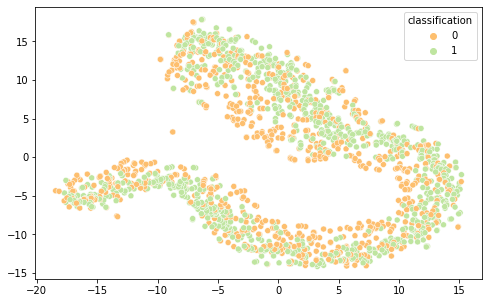
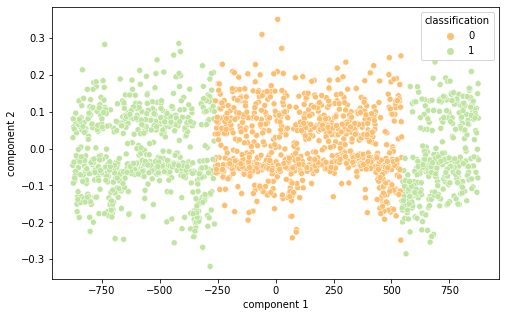
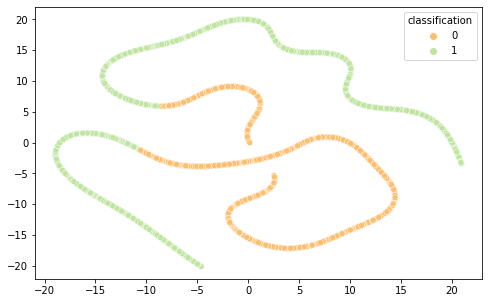
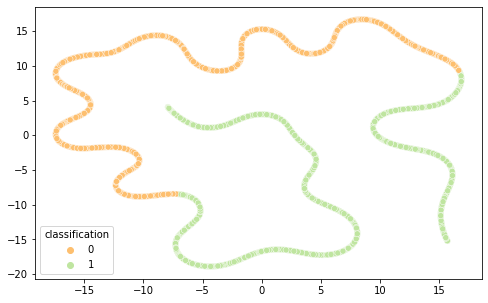
Intrigados com os resultados, resolvemos visualizar as diferentes representações de dados em 2 componentes principais (visto a alta dimensionalidade do dado, o que prejudica a análise do que está acontecendo de fato) por meio das técnicas de PCA e T-SNE, separando por cor de acordo com sua classificação.
É interessante notar que as representações de word embeddings utilizadas possui uma representação bastante confusa e misturada.Já as representações TF-IDF e Bag of Words são facilmente separáveis.
FastText PCA(Semelhante ao Word2Vec)
FastText T-SNE
Word2Vec T-SNE
BOW PCA (Semelhante ao TF-IDF)
BOW T-SNE
TF-IDF T-SNE
Conclusão
A base de dados utilizada para obtenção dos modelos foi obtida por meio do site Chequeado, e, posteriormente, houve o enriquecimento dessa base por meio do web crawler, totalizando 1.383 registros, sendo 701 fake news e 682 notícias verdadeiras.
Para representação textual foram utilizadas as técnicas Bag of Words, TF-IDF e Word embeddings Word2Vec e FastText de 300 dimensões com pesos pré-treinados obtidas por meio da técnica CBOW com dimensões, disponibilizadas pelo Núcleo Interinstitucional de Linguística Computacional (NILC). Para gerar os modelos foram utilizados os algoritmos Regressão Logística, kNN, Análise Discriminante Gaussiano, Árvore de Decisão, Random Forest, Gradient Boosting, SVM e LSTM-Dense. Para avaliação dos modelos foi utilizado as métricas Acurácia, Precision, Recall, F1-score, AUC-ROC e matriz de confusão.
Considerando os experimentos e os resultados, conclui-se que o objetivo principal deste trabalho, gerar modelos capazes de classificar notícias extraídas de redes sociais relacionadas ao COVID-19 como falsas e verdadeiras, foi alcançado com êxito. Como resultados, vimos que os modelos SVM e XGBoost com TF-IDF e BOW atingiram 100% nas métricas, com grandes chances de terem se sobreajustado aos dados. Com isso, consideramos como melhor modelo a Regressão Logística com a representação BOW, atingindo as métricas com valores próximos a 75.49%.
O pior classificador foi o kNN com o BOW e LSTM-Dense com Word2Vec, porém é importante ressaltar que este último não contou com Grid Search e foi treinado com poucas épocas. No geral, as melhores representações foram a TF-IDF e BOW e a pior o Word2Vec.
Para este projeto houveram algumas dificuldades, sendo a principal delas a formação da base de dados, visto que o contexto pandêmico do COVID-19 é algo novo e devido à limitação da API do Twitter em relação ao tempo para extrair os tweets, que era originalmente a ideia da base de dados para esse projeto. Além disso, também houve a dificuldade de remoção do viés dos dados.
Como trabalhos futuros, visamos:
Ampliar a base de dados;
Investigar o que levou ao desempenho do SVM, XGBOOST com as representações TF-IDF e BOW.
Analisar performance dos modelos utilizando outras word embeddings pré-treinadas, como o BERT, Glove e Wang2vec.
Investigar o uso do modelo pré-treinado do BERT e com fine-tuned.
Aplicar PCA Probabilístico
Utilizar arquiteturas de deep learning mais difundidas na comunidade científica.
Se você quer fazer parte de um time com pessoas criativas, curiosas, comunicativas e com paixão por criar, aprender e testar novas tecnologias, então esta é a sua oportunidade! O Insight está buscando novos profissionais, veja aqui as seis funções disponíveis e não se esqueça de acessar o link com a descrição completa de cada vaga.
Processos de segurança de: rede, aplicação, endpoints, dados, identidade, bancos de dados, e infraestrutura, nuvem, mobile e planejamento de recuperação de desastres
Para concorrer a esta vaga envie seu currículo em anexo para o email jobs@insightlab.ufc.br com o assunto “[JOB32] Cyber Security”.
O Insight Lab divulga mais um processo seletivo para pesquisadores. O objetivo é apoiar pesquisas de ponta em Ciência da Computação, Estatística e áreas relacionadas, em particular, cujo tema envolvam uso de inteligência computacional em Big Data para Segurança Pública.
Vagas para:
Pesquisadores doutores na área de Ciência da Computação ou correlatas;
Modalidade: Bolsade pesquisa ASTEF
Valor: R$ 2.000,00 mensais
Período: 12 meses
Propostas de pesquisa:
Cada pesquisador poderá submeter candidatura para apenas 1 (um) problema de pesquisa:
Análise de Redes Complexas.
Geração e Manutenção semi-automática das documentações dos artefatos produzidos no projeto.
Abaixo de cada problema, são listados alguns subproblemas a fim de auxiliar os candidatos na sua escolha.
Análise de Redes Complexas.
1.Geração de Redes Temporais de Relacionamento a partir de trajetórias de criminosos.
2.Análise de Redes Temporais de Relacionamento para identificação de comportamento delitivo.
3.Geração de medidas de centralidade para identificação de nós influentes na rede.
Geração e Manutenção semi-automática das documentações dos artefatos produzidos no projeto.
A partir dos artefatos produzidos no projeto, criar modelos de aprendizagem que gerem (semi) automaticamente textos de documentação.
Estratégias de atualização (semi) automática dos modelos de aprendizagem.
Etapas da seleção
Período de envio de propostas: 03/11/2020 – 06/11/2020
Divulgação dos pesquisadores selecionados através de e-mail: 09/11/2020
Início da pesquisa: 11/11/2020
Formulário
A inscrição deve ser realizada por meio do preenchimento de formulário no Google Forms. Os candidatos serão avaliados pela qualidade das suas publicações no problema de pesquisa escolhido.
O Insight apresenta aqui o livro “Machine Learning: A Probabilistic Perspective”, uma obra bem avaliada pelos leitores escrita por Kevin Patrick Murphy. Com um conteúdo extenso, mais de mil páginas, é um livro de companhia para sua carreira profissional que teve sua primeira edição lançado em 2012 e já está na sua quarta versão.
A obraé escrita de maneira informal, acessível e completa com pseudo-código para os algoritmos mais importantes. Possui todos os seus tópicos ilustrados com imagens coloridas e exemplos extraídos de domínios de aplicação como biologia, processamento de texto, visão computacional e robótica. Diferente de um tutorial, ou um livro de receitas de diferentes métodos heurísticos, a obra enfatiza uma abordagem baseada em modelos de princípios, muitas vezes usando a linguagem de modelos gráficos para especificá-los de forma concisa e intuitiva. Quase todos os modelos descritos foram implementados em um pacote de software MATLAB – PMTK (kit de ferramentas de modelagem probabilística) – que está disponível gratuitamente online.
Conteúdo
Com a quantidade cada vez maior de dados em formato eletrônico, a necessidade de métodos automatizados para análise de dados continua a crescer. O objetivo do Machine Learning (ML) é desenvolver métodos que possam detectar automaticamente padrões nos dados e, em seguida, usar esses padrões descobertos para prever dados futuros ou outros resultados de interesse. Este livro está fortemente relacionado aos campos de estatística e dados, fornecendo uma introdução detalhada ao campo e incluindo exemplos.
Com uma introdução abrangente e independente ao campo do Machine Learning, este livro traz uma abordagem probabilística unificada. A obra combina amplitude e profundidade no tema, oferecendo material de base necessário em tópicos como probabilidade, otimização e álgebra linear, bem como discussão de desenvolvimentos recentes no campo, incluindo campos aleatórios condicionais, regularização L1 e Deep Learning.
Público-alvo
A leitura é indicada para estudantes de graduação de nível superior, de nível introdutório e estudantes iniciantes na pós-graduação em ciência da computação, estatística, engenharia elétrica, econométrica ou qualquer outro que tenha a formação matemática apropriada.
É importante que o leitor esteja familiarizado com cálculo multivariado básico, probabilidade, álgebra linear e programação de computador.
Sobre o autor
Kevin P. Murphy é um cientista pesquisador do Google. Anteriormente, ele foi Professor Associado de Ciência da Computação e Estatística na University of British Columbia.
Críticas sobre a obra
Kevin Murphy se destaca em desvendar as complexidades dos métodos de aprendizado de máquina enquanto motiva o leitor com uma série de exemplos ilustrados e estudos de caso do mundo real. O pacote de software que acompanha inclui o código-fonte para muitas das figuras, tornando mais fácil e tentador mergulhar e explorar esses métodos por si mesmo. Uma compra obrigatória para qualquer pessoa interessada em aprendizado de máquina ou curiosa sobre como extrair conhecimento útil de big data.
John Winn, Microsoft Research, Cambridge
Este livro será uma referência essencial para os praticantes do aprendizado de máquina moderno. Ele cobre os conceitos básicos necessários para entender o campo como um todo e os métodos modernos poderosos que se baseiam nesses conceitos. No aprendizado de máquina, a linguagem de probabilidade e estatística revela conexões importantes entre algoritmos e estratégias aparentemente díspares. Assim, seus leitores se articulam em uma visão holística do estado da arte e prontos para construir a próxima geração de algoritmos de Machine Learning.
David Blei, Universidade de Princeton
———— . . . ————
Empolgado para se tornar um profissional mais preparado? Conta aqui, que livro você gostaria que o Insight indicasse?
No último dia 18 de setembro, entrou em vigor a LGPD, Lei Geral de Proteção de Dados. A lei, de modo geral, trata da proteção de dados dos usuários pelas corporações. Estas terão que se adaptar às novas regras de tratamento dos dados de seus clientes e usuários. Toda as empresas, que de alguma forma manipulam dados dos seus clientes, serão atingidas pelas novas regras. Este tipo de lei já existe na União Europeia e vinha sendo discutida aqui no Brasil há alguns anos.
O que é a LGPD?
A lei nº 13.709 foi aprovada em agosto de 2018 no governo do então presidente Michel Temer. O intuito desta lei é regulamentar a coleta e tratamento de dados pessoais para protegê-los, mantendo sua privacidade e dando transparência à relação entre usuários e organizações.
O artigo 20 da Lei Geral de Proteção de Dados declara que todo titular de dados tem o direito de solicitar a revisão de suas decisões tomadas em relação ao tratamento automatizado de suas informações, especialmente quando essas afetem seus interesses, como o perfil profissional, consumo, crédito e dados de personalidade.
O titular, pessoa natural a quem se referem os dados pessoais que são objeto de tratamento, deverá, a partir de agora, autorizar a coleta, uso e tratamento de seus dados. Dessa forma o indivíduo passa a ter autonomia sobre suas próprias informações, adquirindo direitos como questionar às organizações quais dados elas armazenam, ter acesso a eles e até mesmo exigir que eles sejam apagados caso estejam em desconformidade com a LGPD.
Mas que dados são esses?
Qualquer informação que identifique um usuário, podendo ser desde um número de telefone a dados sensíveis, aqueles que podem ser usados de maneira discriminatória como raça, etnia, religião, posição política, dados referentes à saúde e vida sexual.
De acordo com a lei, existe ainda a classificação de dado pessoal anonimizado, ou seja, referente à pessoa que não possa ser identificada. Contudo, estes não sofrem a aplicação da lei, salvo se o anonimato for revertido e que estes dados não sejam usados para formação de perfis comportamentais.
Dados anônimos em IA e ML
O uso de Dados anônimos são bastante utilizados em Inteligência Artificial e Machine Learning. No ano de 2019, a empresa de vestuário Hering teve que se explicar ao Idec ( Instituto Brasileiro de Defesa do Consumidor) diante do uso de dados de reconhecimento facial que coleta em uma de suas lojas localizada em São Paulo. De acordo com a empresa, esses dados são anonimizados e sendo assim, não poderiam identificar as pessoas que aparecem nas imagens.
O impacto da LGPD no Big Data
Haverá, diante de toda essa mudança, um grande impacto no que se refere ao Big Data, visto que a obtenção de dados automatizada, como nas técnicas de mineração e geração de profiling, basicamente consiste nas informações em relação a um usuário, via tratamento de dados, o que pode ferir as regras da LGPD se não estiver adaptada.
Isso porque esse tipo de abordagem resulta na obtenção de dados pessoais, a técnica analisa dentre outras coisas, o comportamento das pessoas e suas características, fatores que segundo a LGPD não podem mais ser obtidos sem a legítima autorização do indivíduo, salvo em casos de legítimo interesse.
A LGPD, a princípio, terá esse impacto reestruturante especialmente nessas atividades de coleta e tratamento de informações que são primordiais para a formação desse grande volume de dados que chamamos de Big Data.
Perspectivas esperançosas a longo prazo
Ainda que inicialmente isso represente uma redução desse tipo de atividade, tempo necessário para que as empresas aprendam o modo de fazer e aplicar esse tipo de técnica de maneira segura para garantir o compliance, a regulamentação é de extrema importância para muitos mercados e deve continuar a longo prazo.
Com um ambiente mais seguro e adequado aos direitos de cada consumidor, uma nova era deve surgir com maior confiança e transparência no tratamento de dados nos espaços corporativos, e essa confiança é essencial para que a tecnologia passe por uma manutenção em seu modo de existir em uma sociedade conectada.
A nova edição do nosso webinar já está programada. Agora, o tema debatido será “Por onde começar e o que você deve saber antes de iniciar sua carreira em Ciência de Dados”.
Nesta conversa, cinco profissionais compartilharão suas experiências no mercado de Data Science sobre a perspectiva da evolução da Ciência de Dados e a caracterização atual do mercado, destacando as pesquisas em alta, o perfil do profissional almejado na área e também como acontece o fluxo produtivo entre os setores acadêmico e privado.
Durante o webinar, também será apresentado o curso gratuito e online de Ciência de Dados produzido pelo Insight Lab.
Participantes
José Macêdo: Coordenador do Insight Lab, Cientista-chefe de Dados do Governo do CE e professor da UFC
Regis Pires:Coordenador de Capacitação do Insight Lab, cientista de dados do Íris e professor da UFC
Lívia Almada:Pesquisadora no Insight Lab e professora da UFC
Lucas Peres:Desenvolvedor Full Stack no Insight Lab
André Meireles:Pesquisador no Virtus UFCG e professor na UFC
Agenda
Dia: 16 de setembro
Horário: 16h
A transmissão acontecerá no canal do Insight Lab no Youtube,aqui.
Este evento é feito para você, então se sinta à vontade para enviar suas perguntas através do chat no YouTube, elas serão respondidas no último bloco do webinar.
Você, muitas vezes, deve ter se deparado com cenas futuristas no cinema com carros voadores e robôs que se tornam rivais dos humanos. Pois é, a indústria cinematográfica utiliza muito conhecimento tecnológico, matemático e de programação para ativar a imaginação de grandes diretores. A Ciência de Dados na vida real é fascinante e se torna ainda mais incrível quando vista pela sétima arte.
A nossa playlist, desta vez, traz filmes de ficção, documentários e biografias que tratam como a tecnologia foi adequada para a grande tela. Confira estas oito dicas:
1. O Jogo da Imitação
O Jogo da Imitação, baseado na história real de Alan Turing, narra como um matemático, sem patente militar ou cargo político, conseguiu decifrar os códigos de guerra nazistas e contribuir para o final da 2ª Guerra Mundial.
Com uma equipe de decodificadores trabalhando em uma instalação militar secreta no projeto Ultra, Turing não tinha motivações humanitárias ou patrióticas, mas sim, matemáticas.
Arrogante, tirânico, introvertido e de difícil convívio, ainda mais sob a pressão extrema de sua missão, Alan estava obstinado em decifrar o Enigma. Foi quando teve a ideia de criar uma máquina para decifrar códigos secretos. Se a criação deu certo ou não, você vai precisar assistir o filme para saber.
Inspirado no livro “Alan Turing: The Enigma”, de Andrew Hodges, o filme é um reconhecimento ao pai da computação moderna, interpretado por Benedict Cumberbatch, o Sherlock Holmes da série BBC e Dr. Estranho, Marvel.
2. Her
Her é a história de Theodore (Joaquin Phoenix, o coringa), um escritor de cartas românticas divorciado. Ele adquire um novo sistema operacional, Samantha (Scarlett Johansson), como o sistema se autonomeia, e o configura com voz feminina. Os dois desenvolvem uma relação pessoal que evolui para um relacionamento amoroso marcado por questionamentos presentes em qualquer namoro e por questões particulares, como a dúvida se Samantha está desenvolvendo a capacidade de pensamento próprio ou se seu sentimento por Theodore é um comportamento programado.
3. Estrelas Além do Tempo
A obra lança aos olhos do grande público as histórias de Katherine Johnson (Taraji P. Henson), Dorothy Vaughan (Octavia Spencer) e Mary Jackson (Janelle Monáe), três matemáticas negras da Nasa que trabalharam para tornar possível a viagem espacial de John Glenn ao redor da Terra.
O filme é um dos esforços para tentar corrigir a trajetória da História que continuava falando das conquistas espaciais sem citar os nomes dessas mulheres pioneiras.
Katherine realizou o cálculo da trajetória do voo do Apolo 11, o foguete que levou os homens à Lua pela primeira vez. Dorothy, ao descobrir que a Nasa adquirira o computador IBM, decide aprender e ensinar suas companheiras de departamento a programar. Mary foi a primeira mulher engenheira da Nasa. Essas conquistas se tornaram ainda mais desafiadoras diante da discriminação racial e do machismo presentes em suas vidas.
4. O Círculo
Esse filme apresenta a trajetória de Mae (Emma Watson) dentro da Círculo, uma poderosa empresa do ramo de tecnologia. O que parece o trabalho dos sonhos no início se torna um conflito quando a protagonista entende que as tecnologias da empresa, naturalizadas no cotidiano de milhões de pessoas, são um meio para vigiar os usuários e monopolizar suas informações pessoais. É recriada na ficção a realidade: a perda de nossa privacidade quando nos inserimos nos ambientes virtuais. Você lembra do seu histórico de navegação do dia 14 do mês passado? Algumas das maiores companhias do mundo têm tudo isso muito bem armazenado.
5. Vice – The Future of Work
Lançado em 2019, Vice busca delinear um quadro, diante do presente concretizado da inteligência artificial e das perspectivas para seu desenvolvimento, de qual será a configuração do mercado de trabalho no futuro onde máquinas se apresentarão como uma alternativa mais eficiente em diversas atividades laborais.
Quais vantagens no campo de trabalho a humanidade alcançará? Em quais termos as leis serão redigidas para regularizar uma nova realidade empregatícia? Para quais atividades serão realocados os grupos substituídos por máquinas? Em Vice, eles estão tendo essa conversa.
Apresentada pelo ator Robert Downey Junior, a série mostra o trabalho de alguns dos pesquisadores mais influentes no desenvolvimento do potencial da inteligência artificial. Em nove episódios, vamos acompanhar a quais níveis a IA já chegou e o que se espera que sejamos capazes de produzir com ela no futuro, como o aperfeiçoamento da computação afetiva, onde máquinas aprendem a sentir e reagir de uma forma cada vez mais humana.
7. O Homem que Mudou o Jogo
No filme, baseado em fatos reais, vamos acompanhar a análise de dados sendo usada como estratégia pela equipe de beisebol Oakland Athletics. Diante da falta de dinheiro do time, o treinador Billy Beane (Brad Pitt) se junta ao analista Peter Brand (Jonah Hill), que sugere uma nova metodologia na escolha dos atletas; nela, o foco deixa de ser a contratação de grandes estrelas.
Peter, sabendo que quase tudo deixa seu rastro de dados, analisa as estatísticas sobre atletas medianos e passa a selecionar aqueles que são talentosos em pontos específicos do jogo. Essa estratégia eleva a posição da Oakland Athletics dentro da Liga Americana e passa a ser adotada por outras equipes.
8. The Great Hack
A obra mostra como o uso do Big Data, associado a técnicas de marketing, influenciou a eleição presidencial americana de 2016. A companhia Cambridge Analytica, a partir dos dados que o Facebook forneceu de seus usuários, identificou perfis eleitorais e conseguiu produzir um conteúdo mais personalizado para o público que queria atingir.
The great Hack vem para nos lembrar que os nossos dados estão sendo usados, e nós não sabemos por quem e com quais objetivos.
O laboratório Insight está abrindo novas oportunidades para quem deseja contribuir com trabalhos desafiadores e de impacto social em um ambiente de aprendizado contínuo. Quer fazer parte deste time? Fique atento, as bolsas são para alunos de graduação da UFC e para candidatos celetistas.
Responsável por implementar e executar testes automatizados em aplicações mobile e web; apoiar na especificação de casos de testes; criar e conduzir estratégias de testes de produtos e gerar documentação dos casos de testes.
Conhecimentos desejáveis em: documentação de requisitos funcionais e não funcionais;
documentação em modelo de histórias de usuário; documentação e diagramas de arquitetura de software e tecnologias; teste de software; testes de API; UML; banco de dados; controle de versão com Git e desenvolvimento em ambientes e times ágeis.
Você irá se destacar se: tiver conhecimento em Selenium e JMeter; conhecimento em linguagens de programação (Python, Go, Node, Java, Scala…); experiência com JVM;
Linux.
Carga Horária
20h semanais
Modalidade de Contratação
Bolsa de graduação
Envio de currículo
Até 09 de setembro
Candidatura
Envie seu currículo para o email jobs@insightlab.ufc.br com o assunto “[JOB19] Bolsista em Eng. de Software”.
Responsável por atuar no desenvolvimento de uma plataforma integrada, de alta disponibilidade, distribuída e resiliente da segurança pública; atuar no monitoramento de aplicações em clouds públicas e privadas criar e manter ambientes utilizando Infrastructure as Code; contribuir para a tomada de decisões de arquitetura e tecnologia e compartilhar boas práticas DevOPS com o time de desenvolvimento.
Conhecimentos desejáveis em: banco de dados; controle de versão com Git; experiência em Linux; experiência em Docker e desenvolvimento em ambientes e times ágeis.
Você irá se destacar se tiver: conhecimento em ferramentas de Big Data (Kafka, Spark, Flink, Hadoop); conhecimento em conceitos e ferramentas de Ciência de Dados e Machine Learning; conhecimento em ferramentas de automação (Ansible, Chef, Puppet); cultura DevOps (Kubernetes, OKD, OpenShift, CI & CD, Monitoração, Observabilidade); conhecimento em Elastic Stack, Grafana, InfluxData Stack, Zabbix, linguagens de programação (Python, Go, Node, Java, Scala); experiência com JVM e conhecimento em Cloud (AWS, Azure, Google Cloud Platform).
Carga Horária
40h semanais
Modalidade de Contratação
CLT (Salário + Vale alimentação)
Envio de currículo
09 de setembro
Candidatura
Envie seu currículo para o email jobs@insightlab.ufc.br com o assunto “[JOB20] Analista SRE“.
Você será responsável por atuar no desenvolvimento de aplicativos relacionados à segurança pública e atuar no processo de deploy e gestão do aplicativo na loja.
Conhecimentos desejáveis em: POO; Domínio do Swift; View Code; UIKit e ter familiaridade com UIStackView; Core Data; User Notifications; MapKit; Aplicativo baseado em módulos; Cocoa pods; Requests nativo (sem framework) e controle de versão com Git.
Você irá se destacar setiver: conhecimento em regex; Firebase; Fastlane; SwiftLinter; CloudKit; RXSwift; Combine; experiência com publicação na AppStore/TestFlight e conhecimento básico de Objective C.
Carga Horária
40h semanais
Modalidade de Contratação
CLT (Salário + Vale alimentação)
Envio de currículo
09 de setembro
Candidatura
Envie seu currículo para o email jobs@insightlab.ufc.br com o assunto “[JOB21] Desenvolvedor iOS”.
O livro Python Machine Learning, 3ª edição é um guia abrangente de Machine Learning e Deep Learning com Python. De forma didática, o livro ensina todos os passos necessários servindo como leitura de referência enquanto você cria seus sistemas. Contendo explicações claras e exemplos, o livro inclui todas as técnicas essenciais de Machine Learning (ML).
Neste livro os autores Sebastian Raschka e Vahid Mirjaliliensinam os princípios por trás do ML, permitindo que você construa seus próprios modelos e aplicativos.
Revisado e ampliado para conter TensorFlow 2.0, esta nova edição apresenta aos leitores os novos recursos da API Keras, bem como as últimas adições ao scikit-learn. Ele contém ainda, técnicas de aprendizado por reforço de última geração com base em aprendizado profundo, e uma introdução aos GANs.
Outro conteúdo importante que esta obra traz é o subcampo de Natural Language Processing (NLP), esta obra também te ajudará a aprender como usar algoritmos de Machine Learning para classificar documentos.
Você aprenderá a:
Dominar as estruturas, modelos e técnicas que permitem que as máquinas “aprendam” com os dados;
Usar biblioteca scikit-learn para Machine Learning e TensorFlow para Deep Learning;
Aplicar Machine Learning à classificação de imagens, análise de sentimento, aplicativos inteligentes da Web e treinar redes neurais, GANs e outros modelos;
Descobrir as melhores práticas para avaliar e ajustar modelos;
Prever resultados de destino contínuos usando análise de regressão;
Aprofundar-se em dados textuais e de mídia social usando análise de sentimento
Para quem é este livro
Iniciante em Python e interessado em Machine Learning e Deep Learning, este livro é para você que deseja começar do zero ou ampliar seu conhecimento de ML. Direcionado a desenvolvedores e cientistas de dados que desejam ensinar computadores a aprenderem com dados.
Aproveite a leitura
O livro Python Machine Learning poderá ser seu companheiro nos estudos, seja você um desenvolvedor Python iniciante em ML ou apenas alguém que queira aprofundar seu conhecimento sobre os desenvolvimentos mais recentes.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade