O Insight sabe bem como começar uma semana e nesta, trazemos mais vagas para o projeto de digitalização dos serviços públicos. As vagas disponíveis, desta vez, são para bolsistas alunos de graduação: Desenvolvedor Full Stack, Desenvolvedor Front-end e Desenvolvedor Mobile.
Responsável por atuar no desenvolvimento de aplicações móveis e desenvolver soluções inovadoras.
Habilidades em React native, Git, Gitlab, Firebase, Java e Spring Boot.
Desejável habilidades em React native, Git, Gitlab, Firebase, Java e Spring Boot
Modalidade de Contratação
Bolsa FUNCAP graduação.
Carga Horária
20 horas semanais.
Local de exercício das atividades presenciais
Fortaleza e Quixadá. O candidato deverá escolher o local de exercício no preenchimento do formulário.
Etapas da seleção
Envio do desafio e formulário: 12/08 a 17/08
Entrevistas a partir do dia: 18/08
Resultado: 25/08
Duração do projeto
29 meses
Formulário
Acesse o formulário para registrar seus dados, enviar seu currículo e solucionar o desafio. Você será desclassificado se não enviar o desafio. O candidato deverá enviá-lo mesmo que não esteja concluído.
Os links para os desafios de cada modalidade de vaga estão no formulário.
—————-
Boa sorte e continuem acompanhando nossas redes sociais para mais avisos.
O Pandas é uma das melhores bibliotecas Python para análise de dados. Esta biblioteca open source oferece estrutura de dados de alto nível com um excelente desempenho para simplificar tarefas complicadas de manipulação de dados. Sua grande variedade de ferramentas possibilita traduzir operações complexas com dados em um ou dois comandos, além de possuir métodos internos para agrupar, filtrar e combinar dados.
Conheça agora, os seis truques mais úteis dos Pandas para acelerar sua análise de dados.
Selecionar colunas por tipo de dados;
Converter cadeias de caracteres em números;
Detectar e manipular valores ausentes;
Converter um recurso numérico contínuo em um recurso categórico;
Criar um DataFrame a partir da área de transferência;
Construir um DataFrame a partir de vários arquivos.
Confira aqui o repositório no Github para obter o código-fonte.
1. Selecione colunas por tipos de dados
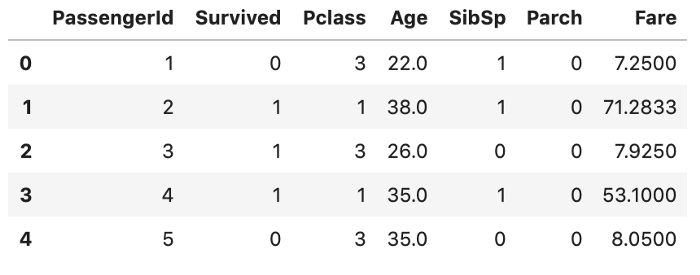
Aqui estão os tipos de dados do DataFrame Titanic:
df.dtypes
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
Digamos que você precise selecionar as colunas numéricas.
df.select_dtypes(include='number').head()
Isso inclui as colunas int e float. Você também pode usar esse método para:
Existem dois métodos para converter uma string em números no Pandas:
O método astype()
O método to_numeric()
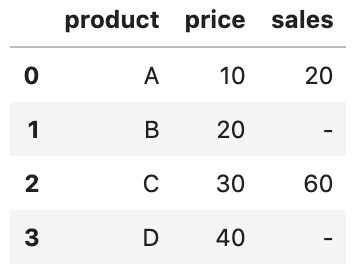
Vamos criar um exemplo de DataFrame para ver a diferença.
df = pd.DataFrame({ 'product': ['A','B','C','D'],
'price': ['10','20','30','40'],
'sales': ['20','-','60','-']
})
As colunas de price e sales são armazenadas como uma cadeia de caracteres e, portanto, resultam em colunas de objeto:
df.dtypes
product object
price object
sales object
dtype: object
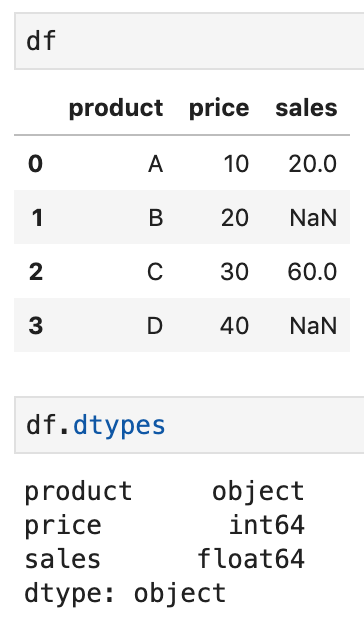
Podemos usar o primeiro método astype()para realizar a conversão na coluna de price da seguinte maneira:
# Use Python type
df['price'] = df['price'].astype(int)
# alternatively, pass { col: dtype }
df = df.astype({'price': 'int'})
No entanto, isso resultaria em um erro se tentássemos usá-lo na coluna desales. Para consertar isso, podemos usar to_numeric()com o argumento errors='coerce'.
Agora, valores inválidos – são convertidos para NaNe o tipo de dado é float.
3. Detectar e manipular valores ausentes
Uma maneira de detectar valores ausentes é usar o método info(). Veja na coluna Non-Null Count.
df.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
Quando o conjunto de dados é grande, podemos contar o número de valores ausentes. df.isnull().sum()retorna o número de valores ausentes para cada coluna.
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
df.isnull().sum().sum() retorna o número total de valores ausentes.
df.isnull().sum().sum()
886
Além disso, também podemos descobrir a porcentagem de valores que estão faltando, executando: df.isna().mean()
PassengerId 0.000000
Survived 0.000000
Pclass 0.000000
Name 0.000000
Sex 0.000000
Age 0.198653
SibSp 0.000000
Parch 0.000000
Ticket 0.000000
Fare 0.000000
Cabin 0.771044
Embarked 0.002245
dtype: float64
Eliminando valores ausentes
Para descartar linhas se houver algum valor NaN:
df.dropna(axis = 0)
Para descartar colunas se houver algum valor NaN:
df.dropna(axis = 1)
Para descartar colunas nas quais mais de 10% dos valores estão ausentes:
df.dropna(thresh=len(df)*0.9, axis=1)
Substituindo valores ausentes
Para substituir todos os valores de NaN por um escalar:
df.fillna(value=10)
Para substituir os valores de NaN pelos valores da linha anterior:
df.fillna(axis=0, method='ffill')
Para substituir os valores de NaN pelos valores da coluna anterior:
df.fillna(axis=1, method='ffill')
Você também pode substituir os valores de NaN pelos valores da próxima linha ou coluna:
# Replace with the values in the next row
df.fillna(axis=0, method='bfill')
# Replace with the values in the next column
df.fillna(axis=1, method='bfill')
A outra substituição comum é trocar os valores de NaN pela média. Por exemplo, para substituir os valores de NaN na coluna Idade pela média.
4. Converta um recurso numérico contínuo em um recurso categórico
Na etapa de preparação dos dados, é bastante comum combinar ou transformar recursos existentes para criar outro mais útil. Uma das maneiras mais populares é criar um recurso categórico a partir de um recurso numérico contínuo.
Observe a coluna Age do dataset do Titanic:
df['Age'].head(8)
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
5 NaN
6 54.0
7 2.0
Name: Age, dtype: float64
Age é um atributo numérico contínuo, mas se você desejar convertê-la em um atributo categórico, por exemplo, converta as idades em grupos de faixas etárias: ≤12, Teen (≤18), Adult (≤60) e Older (>60).
A melhor maneira de fazer isso é usando a função Pandas cut():
import sys
df['ageGroup']=pd.cut(
df['Age'],
bins=[0, 13, 19, 61, sys.maxsize],
labels=['<12', 'Teen', 'Adult', 'Older']
)
Usar a função head(),na coluna age Group, deverá exibir as informações da coluna.
df['ageGroup'].head(8)
0 Adult
1 Adult
2 Adult
3 Adult
4 Adult
5 NaN
6 Adult
7 <12
Name: ageGroup, dtype: category
Categories (4, object): [<12 < Teen < Adult < Older]
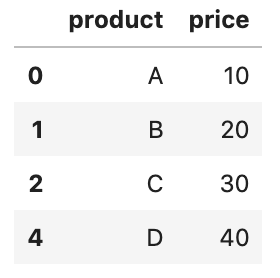
5. Crie um DataFrame a partir da área de transferência
A função Pandas read_clipboard() é uma maneira muito útil de inserir dados em um DataFrame de forma rápida..
Suponha que tenhamos os seguintes dados e desejemos criar um DataFrame a partir dele:
product price
0 A 10
1 B 20
2 C 30
4 D 40
Só precisamos selecionar os dados e copiá-los para a área de transferência. Então, podemos usar a função para ler um DataFrame.
df = pd.read_clipboard ()
df
6. Crie um DataFrame a partir de vários arquivos
Seu dataset pode se espalhar por vários arquivos, mas você pode querer lê-lo em um único DataFrame.
Uma maneira de fazer isso é ler cada arquivo em seu próprio DataFrame, combiná-los e excluir o DataFrame original. Porém, isso seria ineficiente em memória.
Uma solução melhor é usar o módulo interno glob (graças aos truques do Data School Pandas).
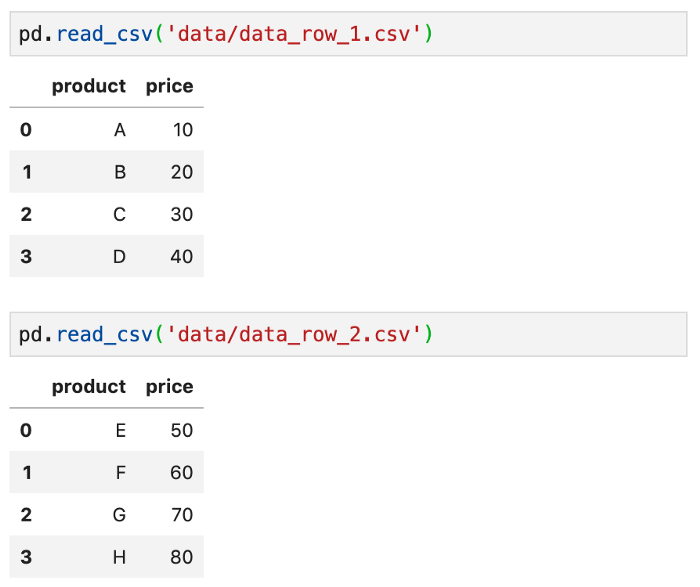
Neste caso, glob() estará procurando no diretório de dados, todos os arquivos CSV que começam com a palavra ” data_row_ “. O glob()recupera nomes de arquivos em uma ordem arbitrária, e é por isso que classificamos a lista usando a função sort().
Para dados em linha
Digamos que nosso dataset esteja distribuído por 2 arquivos em linhas: data_row_1.csv e data_row_2.csv.
Para criar um DataFrame a partir dos 2 arquivos:
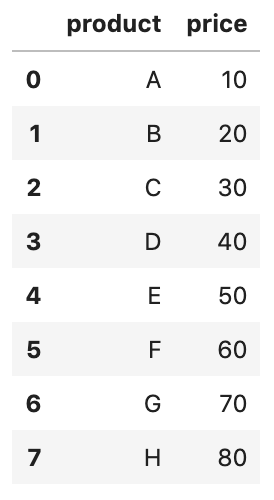
files = sorted(glob('data/data_row_*.csv'))
pd.concat((pd.read_csv(file) for file in files), ignore_index=True)
sorted(glob('data/data_row_*.csv')) recupera nomes de arquivos. Depois disso, lemos cada um dos arquivos usando read_csv()e passamos os resultados para a função concat(), queconectará as linhas em um único DataFrame. Além disso, para evitar um valor duplicado no índice, dizemos ao concat()que ignore o index (ignore_index=True) e, em vez disso, use o índice inteiro padrão.
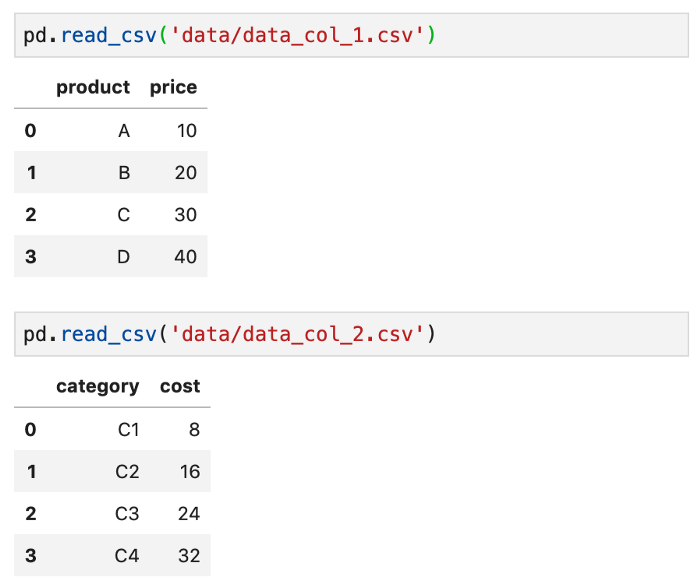
Para dados em colunas
Digamos que nosso dataset esteja distribuído em 2 arquivos em colunas: data_col_1.csv e data_col_2.csv.
Para criar um DataFrame a partir dos 2 arquivos:
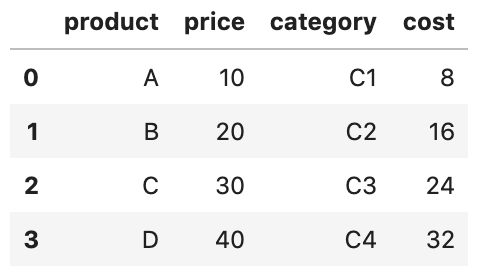
files = sorted(glob('data/data_col_*.csv'))
pd.concat((pd.read_csv(file) for file in files), axis=1)
Desta vez, dizemos à função concat() para conectar ao longo do eixo das colunas.
————-
Isso é tudo!
Obrigada pela leitura e continue acompanhando nossos postagens em Data Science.
O webinar desta quinta-feira, 06/08, irá abordar o projeto de Transformação Digital no Governo do Ceará. O objetivo é fomentar pesquisas que possam viabilizar a melhoria de serviços das secretarias do governo do estado, através da sua digitalização e proporcionar aos cidadãos mais qualidade de vida com a simplificação de processos.
Com este projeto em vigência, o Insight Lab pretende apoiar pesquisas de ponta em Ciência da Computação, Estatística e áreas relacionadas, mas que principalmente, contemplem o tema de inteligência computacional em Big Data na digitalização dos serviços públicos.
O projeto de Pesquisa, Desenvolvimento e Inovação da Transformação Digital do Estado do Ceará é uma parceria entre o Insight Lab, o Laboratório ÍRIS e a FUNCAP.
Vagas
Além de esclarecimentos sobre o projeto com vagas vigentes no edital 02/2020, que terá início agora em 10 de agosto, o webinar também irá tratar sobre as novas vagas para bolsistas e contratações em regime de CLT.
Palestrantes
Davi Romero Pesquisador do Insight lab e professor da UFC
José Macêdo Coordenador do Insight Lab, Cientista-chefe de Dados do Governo do CE e professor da UFC
MariannaFerreira Gestora negocial do Insight Lab
Regis Pires Coordenador de capacitação do Insight Lab,cientista de dados do Íris e professor da UFC.
Ticiana Vasconcelos Coordenadora de pesquisa do Insight Lab,cientista de dados do Íris e professora da UFC.
Agenda
É nesta quinta-feira, 06/08 às 15h.
Transmissão pelo canal do Insight Lab no YouTube. Acesse o link e ative o lembrete.
A semana ainda está no começo e já temos, de novo, ótimas novidades! O Insight está lançando mais oportunidades para quem deseja colaborar no nosso novo projeto, e desta vez, haverá contratações para bolsistas graduados e também em regime CLT – Consolidação das Leis do Trabalho.
As vagas são para os projetos de Pesquisa. Desenvolvimento e Inovação da Transformação Digital do Estado do Ceará. Uma parceria entre o Insight Lab, o Laboratório ÍRIS e a FUNCAP.
O objetivo geral deste projeto é realizar pesquisas científicas e tecnológicas visando o desenvolvimento de soluções para a construção de uma plataforma de governo digital que permita o desenvolvimento de serviços digitais de forma ágil, transparente, eficiente, sustentável, fácil de usar e alinhada com os princípios do serviço público que atenda às necessidades dos cidadãos e dos servidores públicos.
Linhas de Pesquisa
Inteligência Artificial (IA)
Criação automática de modelos para robotizar tarefas
Human into the loop (aprendizado semi-supervisionado)
Robôs de conversação via voz e escrita (exemplo: Alexia)
Transcrição de voz para texto
Processamento de texto (sumarização, extração de entidades, geração de textos, etc)
Explicação de algoritmos de IA para o cidadão
Ciência de Dados
Coleta e monitoramento de streaming de dados para otimização dos serviços
Geração de visualizações semi-automáticas
Experiência do Usuário/Usabilidade
Métodos de avaliação de usabilidade e experiência do usuário
Responsável por atuar no desenvolvimento de aplicações web e por desenvolver soluções inovadoras.
Habilidades em Javascript, Typescript, HTML, CSS, Java, Spring Boot, Git, Gitlab, Python, PostgreSQL e MongoDB.
Desejável conhecimento em Django, Docker, Redis, Scala, Play Framework e Lagom Framework.
Modalidade de Contratação
Bolsa graduação FUNCAP
Candidatura
Acesse o formulário para enviar seus dados, seu currículo e resolver o desafio. Não esqueça de enviar a solução do seu desafio. Vagas somente para Fortaleza!
A seleção estará aberta até o preenchimento da vaga.
Engenheiro de Dados – Analista Pleno (Preenchida)
Responsável por estudar tecnologias que se adequem às necessidades dos produtos; por contribuir para a tomada de decisões tecnológicas; por tornar os dados mais legíveis e por atuar na construção de Data Lakes.
Habilidades em: MongoDB, PostgreSQL, Redis, Python, Jupyter Notebook, Google Colab, Numpy, Pandas, Matplotlib, Kafka, Scikit-Learn, Business Intelligence, Data Lake, Dashboard, Big Data, Git e Gitlab.
Habilidades em Spark e AirFlow serão um diferencial.
Desenvolvedor Front-End Júnior (preenchida)
Responsável por atuar no desenvolvimento de aplicações web e por desenvolver soluções inovadoras.
Habilidades em Javascript, Typescript, HTML, CSS, React Js, Git e Gitlab.
Desejável conhecimento em Node Js, MongoDB, Firebase e Spring Boot.
Líder Técnico – Analista Pleno (preenchida)
Responsável por estudar tecnologias que se adequem às necessidades dos produtos; por contribuir para a tomada de decisões tecnológicas; por atuar na arquitetura e desenvolvimento de plataformas e por liderar squads de desenvolvimento.
Habilidades em UML, Padrões de Projeto, Microsserviços, Javascript, TypeScript, HTML, CSS, Java, Spring Boot, Python, Git, Gitlab, MongoDB, PostgreSQL e Redis.
Desejável conhecimento em Django, Docker, Kafka, Kubernetes, ElasticSearch, Scala, Play Framework e Lagom Framework.
Desenvolvedor Full-Stack Júnior especialista em aplicações móveis (preenchida)
Responsável por atuar no desenvolvimento de aplicações móveis e por desenvolver soluções inovadoras.
Habilidades em React native, Git, Gitlab, Firebase, Java e Spring Boot.
Desejável conhecimento em desenvolvimento nativo para iOS e Android.
Duração do projeto
36 meses
Importante
O Edital 02/2020, lançado anteriormente, contempla o mesmo projeto, porém não vigora sobre as vagas aqui citadas. As vagas aqui publicadas não pertencem a qualquer edital e estão sendo oficialmente regidas pelas regras descritas nos documentos aqui linkados.
Os valores, duração das bolsas e contratações serão informados aos selecionados durante o processo.
———————– ———————–
Boa sorte!
Acompanhe as nossas redes sociais para mais avisos.
O Insight já começa esta semana com o lançando do seu segundo edital para pesquisadores. O Edital Nº 02/2020, lançado hoje, 27/07, selecionará pesquisadores para participar em projetos de pesquisa para Acelerar a Transformação Digital no Estado do Ceará.
A pesquisa científica tem um papel fundamental na inovação tecnológica, no intuito de trazer melhorias e desenvolvimento a sociedade. Com isso, a universidade pública, através do laboratório Insight, pretende contribuir com suas pesquisas em Transformação Digital. O objetivo é proporcionar aos cidadãos melhoria da qualidade de vida com a simplificação de processos, evitando deslocamentos, filas e aglomerações.
Além disso, a digitalização dos serviços públicos traz benefícios na rapidez do atendimento, redução do custo da máquina pública, aumento na eficiência da administração pública e melhoria nos mecanismos de transparência pública.
Perfil dos candidatos
Alunos de graduação, mestrado e doutorado devidamente matriculados em instituições de ensino públicas no Ceará, cujos professores-orientadores possuam a titulação de doutor e trabalhem como docente na Universidade Federal do Ceará.
Temas de Pesquisa
A intenção deste Edital é apoiar pesquisa de ponta em Ciência da Computação, Estatística e áreas relacionadas, em particular, cujo tema envolva uso de inteligência computacional em Big Data para Transformação Digital no Governo do Ceará.
Cada docente deverá escolher um tema para submeter a candidatura, veja as opções:
Integração de dados em larga escala para construção do Data Lake;
Segurança e Privacidade dos dados no Data Lake;
Consulta em Linguagem Natural.;
Comunicação e Gerenciamento de microsserviços;
Uso de Inteligência Artificial para a comunicação com o cidadão;
Mineração de Processos (Process Mining);
Experiência do Usuário;
Recuperação de Informações em Documentos Digitalizados;
Low Code;
Geração de Código usando Processamento de Linguagem Natural;
Geração automática de documentação de sistemas usando Inteligência Artificial.
A lista completa com os sub-problemas de cada problema geral você encontra no edital.
Importante
Somente serão avaliadas propostas submetidas por 1 (um) pesquisador docente acompanhado de 1 (um) aluno. Caso o docente não possua aluno para indicar, o aluno deve ser indicado até Outubro de 2020 e o docente só começará a receber a bolsa quando fizer a indicação do aluno. As candidaturas devem ser realizadas, pelo professor-orientador, através do preenchimento do formulário no Google Forms.
Valor e duração das bolsas:
Graduação: R$ 800,00, 12 meses.
Mestrado: R$ 1.500,00, 12 meses.
Doutorado: R$ 2.500,00, 12 meses.
Professor-orientador: R$ 2.000,00, 12 meses.
Calendário
Até 03/08/2020, envio de propostas.
04/08/2020, divulgação dos selecionados por e-mail.
Nesta semana, o Insight Lab continua sua série de webinars discutindo Projetos de Pesquisa, desta vez, com foco no desenvolvimento.
Nesta edição, vamos saber mais sobre como o Insight Lab lida com o desenvolvimento em um projeto de P&D, a nossa equipe multidisciplinar, a produtificação de uma pesquisa, as ferramentas de tecnologia, a influência do modelo de desenvolvimento nos nossos principais parceiros e também as ações de marketing aplicadas ao laboratório.
Venha conhecer e interagir com alguns dos profissionais que estão à frente do nosso laboratório de pesquisa em Ciência de Dados.
Os profissionais de Ciência de Dados estão cada vez mais requisitados nas organizações e suas habilidades são exigidas de acordo com o perfil de cada empregador. As certificações são uma excelente forma desses profissionais obterem vantagens, permitindo aprimoramento nas suas habilidades. Esta tática serve ainda como uma forma de avaliar o nível das habilidades profissionais de uma equipe.
Se você está procurando por certificações para aumentar suas habilidades específicas e ampliar seu conhecimento na área de dados, pelo menos uma dessas nove certificações servirá para você. Mas antes, saiba da importância dessas certificações.
Por que tirar certificações online?
Agregar habilidades no currículo ou portfólio;
Aumentar as perspectivas de emprego;
Usufruir do acesso a serviços adicionais: serviço de carreira, contratação de laboratórios, revisões;
Fazer uma transição de carreira.
Sendo assim, vamos conferir as 9 principais certificações online para Data Science que você pode começar este ano.
Segundo Rashi Desai da Universidade de Illinois, Chicago, este é o melhor programa de certificação em ciência de dados de nível básico para entusiastas que desejam iniciar sua carreira profissional na área.
Comece compreendendo o que é Ciência de Dados, por que ela é tão popular e depois enriqueça sua formação com a integração de APIs (Application Programming Interface ou Interface de Programação de Aplicativos). Recomendamos aqui este desafio de 9 cursos.
Cursos
What is Data Science?
Open Source tools for Data Science;
Data Science Methodology;
Python for Data Science and AI;
Databases and SQL for Data Science;
Data Analysis with Python;
Data Visualization with Python;
Machine Learning with Python;
Applied Data Science Capstone.
A certificação não requer pré-requisitos. No entanto, se você deseja uma melhor compreensão do aprendizado, sugiro concluir um curso intensivo sobre Python de antemão. No curso 6, você começará a construir projetos a partir do zero, tornando-o uma maneira perfeita de obter alguns projetos sofisticados em seus currículos!
O Tableau está oferecendo descontos em muitas de suas certificações, mas esta: Data Scientist Learning Path é GRATUITA. Uma certificação irmã é o Tableau Data Analyst.
O caminho do Tableau Data Scientist inclui:
Getting Started with Tableau Desktop;
Desktop I: Fundamentals;
Desktop II: Intermediate;
Desktop III: Advanced;
Data Prep;
Visual Analytics;
Data Science with Tableau;
Data Scientist Skills Assessment.
O Tableau oferece três grandes certificações pagas:
Este exame é para aqueles que possuem habilidades e conhecimentos básicos do Tableau Desktop e pelo menos três meses aplicando entendimento e experiência com o Tableau.
Custo: $ 100
Limite de Tempo: 60 minutos
Formato da pergunta: Múltipla escolha, resposta múltipla
A Universidade de Harvard, em parceria com a edX, possui uma Certificação de Ciência de Dados que abrange habilidades fundamentais de programação R, conceitos estatísticos como probabilidade, inferência e modelagem, experiência com pacotes como tidyverse, ggplot2 e dplyr .
A melhor parte dessa certificação é o curso que toca na base de ferramentas essenciais para a prática de cientistas de dados como Unix / Linux, Git e GitHub e RStudio.
Outro ponto alto dessa certificação é o seu realismo, os cursos apresentam aos alunos estudos de caso do mundo real, como:
Tendências mundiais em saúde e economia;
Taxas de criminalidade nos EUA;
A crise financeira de 2007-2008;
Previsão Eleitoral;
Construindo um time de beisebol (inspirado em Moneyball);
A Especialização emBusiness Analytics está hospedada no Coursera, desenvolvido com a Wharton School da Universidade da Pensilvânia. Ele fornece uma boa introdução fundamental à análise de big data nas profissões de negócios, como marketing, recursos humanos, operações e finanças. Os cursos não requerem experiência prévia em análise.
Uma estatística no site diz que 46% dos alunos iniciaram uma nova carreira após concluir esta especialização e 21% dos alunos receberam um aumento ou promoção salarial.
O curso desenvolve no aluno o senso de como o analistas de dados, deve e pode descrever, prever e informar decisões de negócios em áreas específicas. Após concluir a especialização, o aluno desenvolverá uma mentalidade analítica que o ajudará a tomar as melhores decisões baseadas em dados.
A especialização em Advanced Business Analytics está hospedada no Coursera, desenvolvido com a Universidade do Colorado, Boulder. A especialização mescla a linha tênue entre a academia e o mundo dos negócios para combinar aprendizados de profissionais experientes de ambos os domínios para compartilhar as habilidades de análise de dados do mundo real com os alunos.
Segundo o site, 50% dos alunos começaram uma nova carreira depois de concluir esta especialização. É sobre isso que estamos falando!
Depois de concluir esta especialização, você poderá redigir e reconhecer melhor o valor máximo para os acionistas. O curso o conduz por uma experiência completa em extração e manipulação de dados usando SQL e para alavancar técnicas estatísticas para análises descritivas, preditivas e prescritivas para diferentes domínios de negócios. E o mais importante, o curso ensina efetivamente como interpretar e apresentar resultados analíticos para uma tomada de decisão eficiente.
A SAS Academy for Data Science é uma das plataformas de prestígio para aprender o SAS para Data Science. Oferece cursos de curadoria de dados, análise avançada, IA e aprendizado de máquina para avançar sua carreira em dados. Lembre-se, o próprio SAS é um horizonte complicado a ser explorado por iniciantes. Se você estiver pronto para fazer um dos exames abaixo, certifique-se de ter conhecimento completo dos pré-requisitos.
Existem três caminhos básicos na SAS Academy:
Profissional de curadoria de dados (4 cursos | 1 exame | 5 crachás | $ 1295 / ano);
Com o Microsoft Certified Solutions Expert (MCSE), você pode demonstrar um amplo conjunto de habilidades em administração de banco de dados, SQL, criação de soluções de dados em escala corporativa e alavancagem de dados de inteligência de negócios.
O que você vai aprender?
Relatórios de Business Intelligence;
Engenharia de dados com o Azure;
Machine Learning;
Desenvolvimento de Business Intelligence do SQL 2016;
Administração do banco de dados SQL 2016;
Desenvolvimento de banco de dados SQL 2016;
SQL Server 2012/2014.
Existem 3 etapas para garantir esta certificação
1.Trabalhar com a Administração de banco de dados do SQL Server 2012/2014/2016 e obter o Microsoft Certified Solutions Associate para SQL Server. Obtenha conhecimento sobre desenvolvimento de banco de dados, desenvolvimento de (BI) business intelligence , aprendizado de máquina, relatórios de BI ou engenharia de dados com o Azure;
Passar em um exame obrigatório. O portal de certificação também contém recursos de preparação para exames;
(cerca de 50% de perguntas do Machine Learning studio, 40% de Machine Learning service e 10% de perguntas genéricas sobre ciência de dados.)
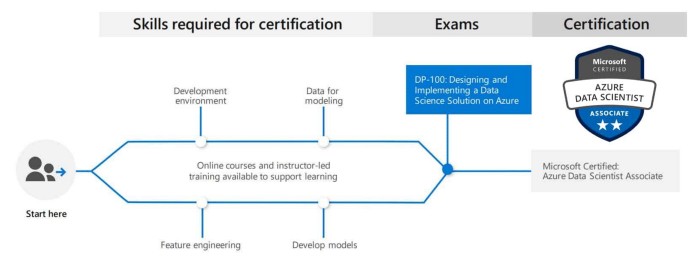
Uma certificação mais leve, e portanto, a última da lista, a Certificação de Cientista de Dados do Microsoft Azure é voltada para alunos que desejam aplicar seus conhecimentos de ciência de dados e aprendizado de máquina para implementar e executar modelos de Machine Learning no Azure.
A parte boa dessa certificação é que você conclui o exame com a implantação de um modelo como serviço.
O caminho é simples: faça um exame e obtenha o certificado.
Habilidades avaliadas:
Configuração de um espaço de trabalho do Azure Machine Learning (30 a 35%);
Execução de experimentos e treinamentos de modelos no Azure (25 a 30%);
Otimização e gerenciamento de modelos criados do Azure (20–25%);
Implementação e consumo de modelos prontos para produção (20–25%).
Uma introdução ao uso do Git para projetos de aprendizado de máquina
O Git é uma plataforma destinada a desenvolvedores para o gerenciamento de projetos e versões de códigos, permitindo desenvolver projetos colaborativos com pessoas do mundo todo. É a rede social dos desenvolvedores.
Como controle de versão, ele tem a capacidade de gerenciar diferentes versões de um mesmo projeto. É possível assim, obter históricos das modificações, permitir que vários programadores trabalhem no mesmo projeto, e permitir um comparativo entre várias versões do projeto.
Essas funcionalidades são essenciais durante o treinamento de um novo modelo de machine learning, em que vários programadores trabalham no mesmo código.
Iniciando o processo
Consideraremos aqui que você já tenha o Git instalado, caso não, aqui está um recurso para fazê-lo. Depois disso, não se esqueça de configurar uma chave SSH.
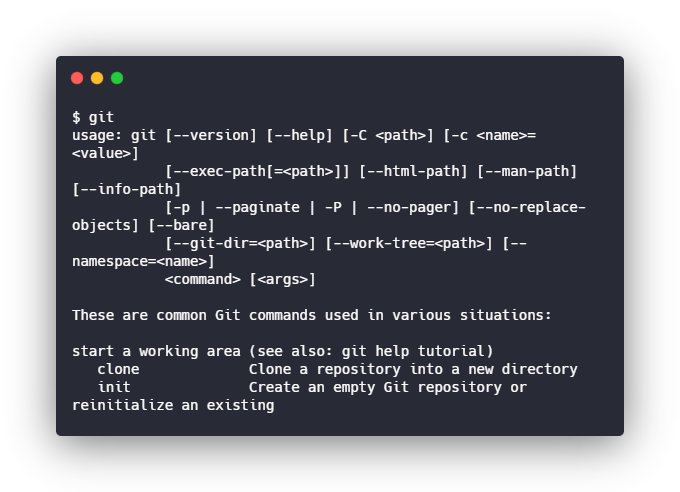
Você deve ver o seguinte ao digitar git na linha de comando no Mac / Linux ou GitBash se estiver no Windows.
1.Init
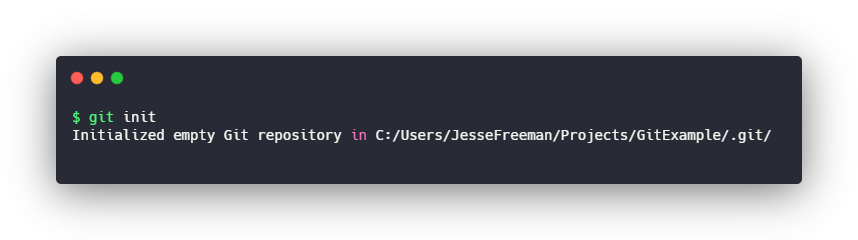
Vamos começar com o comando mais básico, o init. Ele inicializa um projeto Git, uma maneira simples para dizer: “adicione os arquivos necessários ao Git na raiz da pasta em que você está”. Simplesmente acione o comando cd para o diretório do seu projeto e digite o seguinte:
$ git init
Em troca, você receberá uma mensagem dizendo que seu projeto está pronto para a execução.
Você só precisa fazer isso uma vez por projeto.
2. Remote Add
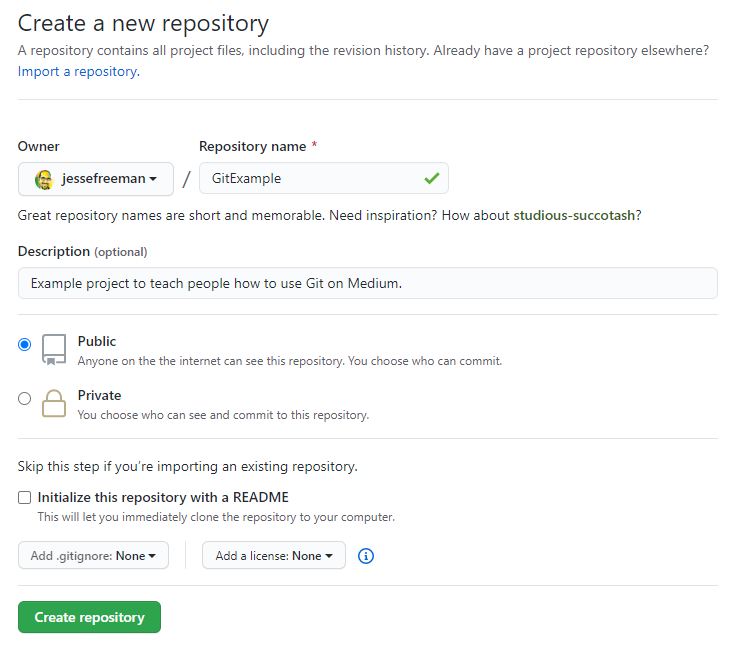
Agora, graças ao comando init, você tem um repositório local para o seu projeto. Você poderá fazer tudo o que precisa para controlar, de maneira satisfatória, seu projeto localmente. Crie um projeto online para aproveitar ao máximo o Git. A maioria dos desenvolvedores têm uma conta GitHub, embora existam boas alternativas como BitBucket e gitlab. De um modo geral esses serviços são semelhantes para quem está iniciando.
Depois de escolher o serviço que você deseja usar, vá em frente e crie um novo projeto.
Depois de criar seu projeto, você receberá um URL personalizado. Neste caso, o gerado para este projeto é:https://github.com/jessefreeman/GitExample.git
Tudo o que precisamos fazer agora é conectar nosso projeto local ao projeto online que criamos. Para fazer isso, você usará o seguinte comando:
$ git remote add origin <PROJECT_URL>
Você também pode se conectar pelo caminho SSH, dependendo do que o serviço Git fornece.
3. Add
Neste ponto, seu projeto está pronto para rastrear versões localmente. Vá em frente e adicione um arquivo ReadMe.txtou algo à pasta. Lembre-se de que o Git ignora pastas vazias. Quando estiver pronto, adicione as alterações ao repositório. A preparação é uma maneira simples de dizer que o Git vai rastrear arquivos específicos até que você esteja pronto para salvar uma versão deles.
Para adicionar arquivos, basta digitar o seguinte comando:
$ git add .
Embora você possa especificar arquivos pelo nome após add, . é um curinga que incluirá automaticamente todos os arquivos que foram alterados desde a última confirmação.
4. Status
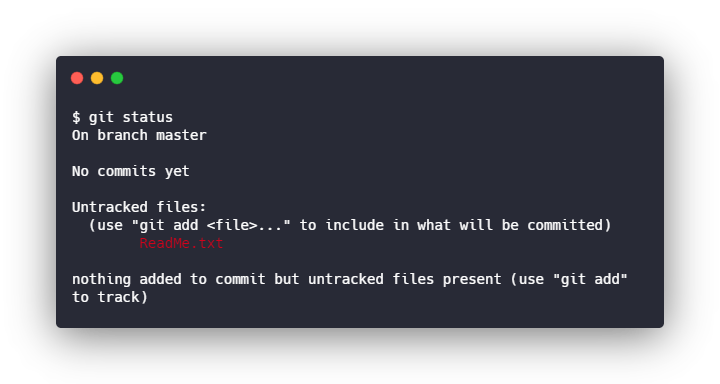
A qualquer momento, você pode obter uma lista dos arquivos no projeto Git e ver se eles estão prontos ou não. Para fazer isso, digite o seguinte comando:
$ git status
Isso dará uma lista de todos os arquivos que o Git vê no diretório.
Você pode ver os arquivos não adicionados no momento em vermelho. Os arquivos prontos para serem salvos aparecerão em verde. A lista de status do arquivo é útil quando você desejar ver se está tudo concluído antes de salvar as alterações.
5. Commit
Depois de organizar os arquivos, você precisará salvar uma versão deles. Chamamos isso de commit. O Git pega os arquivos que você adicionou anteriormente e os compara com a última versão. Em seguida, ele salva os deltas, ou as diferenças, em uma pasta.gitoculta especial na raiz do seu projeto.
Para salvar as alterações, digite o seguinte na linha de comando:
$ git commit -m "Add a message so you know what you did"
Este é provavelmente o mais complexo dos comandos que usamos até agora. Se olharmos para cada parte, estamos ligando commite-m representando a adição de uma mensagem. Por fim, você fornecerá a mensagem de confirmação entre aspas. Dessa forma, depois você poderá olhar no log de confirmação para lembrar as alterações que você fez.
Se você estiver usando o GitHub, existem alguns recursos interessantes que você pode usar ao confirmar seu código. Aqui citaremos, como exemplo, a aba de Issues do repositório, esse local vai permitir a você acompanhar as tarefas, aprimoramentos e bugs de seu projeto. Cada tópico representa um número de identificação exclusivo e você pode vinculá-lo referenciando-o em seu comentário como este:
$ git commit -m "Finished making changes to #1"
O GitHub irá adicionar automaticamente um link do seu commit ao problema. É uma ótima maneira de se manter organizado enquanto você trabalha.
6. Push
A última etapa deste processo é enviar todos os seus commits para o repositório remoto no GitHub. O Git é único, pois permite trabalhar localmente até que você esteja pronto para adicioná-los de volta ao repositório principal. É isso que permite que as equipes trabalhem de forma mais eficiente em seus computadores e depois mesclem tudo de volta para um único projeto.
Lembra-se de quando ligamos nosso projeto local ao projeto online? Agora, quando você diz ao Git para empurrar (to push) as alterações, elas serão copiadas e mescladas no projeto principal. Tudo que você precisa fazer é digitar o seguinte na linha de comando:
$ git push --all
O --allé semelhante ao curinga ., que usamos anteriormente ao preparar nossos arquivos. Essa flag diz ao Git para enviar todas as confirmações recentes para a origem padrão, que é o que definimos com o comando remote add.
Veja e repita
Agora você já conhece os seis comandos mais essenciais para usar o Git:
init Criar um novo projeto
remoteaddorigin Vincular um projeto local a um projeto online
add Adicionar arquivos para acompanhar
status Retornar a uma lista de arquivos no projeto local
commit Salvar as alterações nesses arquivos
push Copiar essas alterações no projeto online
Agora você pode executar as etapas 3 à 6 para continuar salvando as alterações feitas. Não há limite para o número de confirmações que você pode fazer, embora seja necessário limpar o repositório do Github de tempos em tempos, se você fizer muitas alterações.
À medida que você se sentir mais confortável com o Git, verifique como usar o arquivo .gitignorepara excluir itens específicos que você não deseja que sejam rastreados. Aqui, temos um projeto de Jesse Freeman que poderá ser utilizado como referência e que ignora os modelos gerados e alguns dos arquivos de configuração do projeto Python que não são críticos para quem procura executar o projeto localmente.
O Insight Lab, anuncia seu próximo webinar com o tema: O Eixo de Pesquisa em Projetos de P&D – modelo Insight Lab. Desta vez, você terá a oportunidade de assistir a um debate sobre pesquisa com especialistas de referência do nosso laboratório, autores de trabalhos reconhecidos internacionalmente.
Entenda o que é um projeto de pesquisa, as dificuldades, as contribuições, o tempo nos projetos, os projetos de inovação radical ou disruptiva e as práticas do laboratório Insight em P&D.
PARTICIPANTES
José Macedo – Coordenador do Insight Lab, Cientista-chefe de Dados do Governo do CE e Professor da UFC
Ticiana Linhares – Cientista de dados do Insight Lab e do Íris, e Professora da UFC.
Régis Pires – Cientista de dados do Insight Lab e do Íris, e Professor da UFC.
José Florêncio – Coordenador negocial e pesquisador do Insight Lab
PROGRAME-SE
O evento é aberto e destinado a todos os interessados no assunto.
O interesse pela ciência de dados está crescendo rapidamente. Muitos a consideram como a profissão do futuro. O hype relacionado à Big Data e à análise preditiva ilustra isso. (“Big” e “Small”) Data são essenciais para pessoas e organizações, aumentando sua importância. No entanto, não é suficiente se concentrar no armazenamento e análise de dados. Um cientista de dados também precisa relacionar dados a processos operacionais e ser capaz de fazer as perguntas certas.
A relevância da Mineração de Processos
Na última década, Process Mining (Mineração de Processos) surgiu como um novo campo de pesquisa que se concentra na análise de processos usando dados de eventos. As técnicas clássicas de mineração de dados, como classificação, clustering, regressão, aprendizado de regras de associação, não se concentram nos modelos de processos de negócios e geralmente são usadas apenas para analisar uma etapa específica do processo geral.
Mineração de Processos se concentra nos processos fim-a-fim e isso é possível devido à crescente disponibilidade de dados de eventos e novas técnicas de descoberta de processos e verificação de conformidade. A relevância prática da mineração de processos e os interessantes desafios científicos tornaram essa nova área um dos hot topics da ciência de dados.
O que é a mineração de processos?
Primeiro precisamos definir formalmente o que essa nova área aborda. O ponto de partida para a mineração de processos é um log de eventos. Cada evento nesse log refere-se a uma atividade (isto é, uma etapa bem definida em algum processo) e está relacionado a um caso específico (isto é, uma instância do processo).
Os eventos pertencentes a um caso são ordenados e podem ser vistos como uma “execução” do processo. Os logs de eventos podem armazenar informações adicionais sobre eventos. De fato, sempre que possível, as técnicas de mineração de processo usam informações extras, como o recurso (ou seja, pessoa ou dispositivo) que executa ou inicia a atividade, o registro de data e hora do evento ou elementos de dados registrados com o evento (por exemplo, o tamanho de um pedido).
Assim, a mineração de processos visa descobrir, monitorar e melhorar processos reais extraindo conhecimento dos logs de eventos disponíveis nos sistemas de informações atuais. Ao usar process mining é possível descobrir processos reais, checar sua conformidade, quantificar os desvios, descobrir o que causa a variação dos processos, encontrar gargalos, predizer saídas dos processos, entre outros benefícios. O objetivo dessa área é transformar dados de eventos em insights e ações. Process mining é parte integrante da ciência de dados, estimulada pela disponibilidade de dados e pelo desejo de melhorar os processos.
As três classificações de Mineração de Processos
A descoberta de processos constrói um modelo a partir de um log de eventos, sem nenhuma informação a priori. Um exemplo disso é o algoritmo alpha.
Já as técnicas de conformidade visam analisar a compatibilidade de um log de eventos a um modelo de processo já existente. A verificação de conformidade pode ser usada para verificar se a realidade do modelo condiz com o que foi registrado no log e vice-versa.
Por fim, o aprimoramento melhora automaticamente um modelo de processo de acordo com um log de eventos. Enquanto a conformidade mede o alinhamento entre o modelo e a realidade, esse terceiro tipo de mineração de processo visa alterar ou estender o modelo a priori.
Em que contexto é aplicado?
Uma aplicação para mineração de processos é a pesquisa de serviços de saúde. Esse é um campo científico que analisa os workflows e os processos de monitoramento à saúde no que diz respeito à eficiência e eficácia. Um dos seus principais objetivos é o desenvolvimento e implementação de conceitos de assistência médica baseada em evidências. Portanto, esse área busca melhorar a qualidade de atendimentos médicos, considerando que os recursos disponíveis são escassos. Um objetivo importante é a validação de ensaios clínicos na literatura.
No contexto educacional, foi criada uma nova vertente, chamada EPM – Educational Process Mining (Mineração de processos educacionais), que tem como objetivo construir modelos de processos educacionais completos e compactos que sejam capazes de reproduzir todo o comportamento observado. Os resultados da EPM podem ser usados para obter uma melhor compreensão dos processos educacionais subjacentes, gerar recomendações e conselhos para os alunos, fornecer feedback aos alunos, professores e pesquisadores, para detectar precocemente dificuldades de aprendizado.
Já no contexto de Engenharia de Software, foi definida uma subárea chamada Software Process Mining (Mineração de Processos de Software). Nesta área, as pessoas se concentram na análise de rastreamentos de tempo de execução para melhorar a arquitetura e o desempenho dos sistemas de software, e na análise do comportamento do usuário para melhorar o design e a usabilidade dos sistemas de software.
Por fim
Em resumo, as técnicas de mineração de processos podem ser aplicadas em qualquer contexto, desde que seja possível transformar os dados de entrada em logs de eventos. Ela se tornou uma ferramenta vital para as organizações modernas que precisam gerenciar seus processos operacionais complexos, e por conta disso, ela se tornou um dos principais pilares da ciência de dados.
Referências Bibliográficas
BOGARÍN, Alejandro et al. Clustering for improving educational process mining. In: Proceedings of the fourth international conference on learning analytics and knowledge. 2014. p. 11-15.
RUBIN, Vladimir; LOMAZOVA, Irina; AALST, Wil MP van der. Agile development with software process mining. In: Proceedings of the 2014 international conference on software and system process. 2014. p. 70-74.
VAN DER AALST, Wil. Data science in action. In: Process mining. Springer, Berlin, Heidelberg, 2016. p. 3-23.
VAN DER AALST, Wil. Process mining: Overview and opportunities. ACM Transactions on Management Information Systems (TMIS), v. 3, n. 2, p. 1-17, 2012.
VOGELGESANG, Thomas; APPELRATH, H.-Jürgen. Multidimensional process mining: a flexible analysis approach for health services research. In: Proceedings of the Joint EDBT/ICDT 2013 Workshops. 2013. p. 17-22.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade