“Hoje, o Insight indica o livro “Inteligência Artificial” (AI Superpowers – China, Silicon Valley, and the New World Order), escrito por uma das maiores autoridade de IA, Kai-Fuu Lee.
Esse livro nos ajuda a entender as grandes transformações positivas que a inteligência artificial pode trazer e como as maiores potências do mundo, EUA e China, estão desenvolvendo essa ciência dentro de realidades e posições específicas.
As posições de liderança ocupadas por China e Estados Unidos em muitos momentos ganham o contorno de confronto. E isso se reflete nas palavras usadas pelo autor quando afirma que a grande quantidade de engenheiros de IA consistentes será tão importante quanto a qualidade de pesquisadores de elite, e “a China está treinando exatamente esse exército“.
Também é destacado que, apesar dos Estados Unidos serem pioneiros na IA, hoje a China já é um superpotência na área. Isso é resultado, afirma Lee, de aspectos específicos do país asiático, como “dados abundantes, empreendedores tenazes, cientistas de IA bem treinados e um ambiente político favorável”.
No entanto, como alertado em artigo do The Washington Post, “alguns leriam ‘dados abundantes’ como ‘vigilância` e ‘um ambiente de política favorável’ como ‘tomada de decisão de cima para baixo que não é impedida pela opinião pública.’”
Kai-Fuu Lee compartilha conosco uma reflexão sobre o processo desta corrida desenvolvimentista entre Estado Unidos e China e suas implicações. Uma das preocupações destacadas é que o domínio dessas duas potências gere desigualdade global também no campo de IA. Os dois países já são lideranças massivas no resto do mundo, e isso pode se aprofundar se esse poder tecnológico permanecer tão concentrado.
Além disso, o livro trata da antiga e a cada dia renovada preocupação sobre o papel que a IA ocupará no mundo. E isso significa pensar qual lugar nós ocuparemos num mundo tão automatizado por essas máquinas, muito mais adequadas que os seres humanos para certas tarefas, mas frutos da criatividade e inteligência humana.
O autor*
Imagem: vídeo – Como a IA pode salvar nossa humanidade (TED)
Kai-Fu Lee tem uma perspectiva única na indústria de tecnologia global, tendo trabalhado extensivamente entre os Estados Unidos e a China pesquisando, desenvolvendo e investindo em inteligência artificial há mais de 30 anos. Ele é um dos maiores investidores em tecnologia da China, realizando um trabalho pioneiro no campo da IA e trabalhando com vários gigantes da tecnologia dos EUA.
Lee já foi presidente do Google China e ocupou cargos executivos na Microsoft, SGI e Apple, e fundou a Microsoft Research China. Mais tarde renomeado “Microsoft Research Asia”, este instituto treinou a maioria dos líderes de IA na China, incluindo chefes de IA da Baidu, Tencent, Alibaba, Lenovo, Huawei e Haier. Enquanto estava na Apple, Lee liderou projetos de IA em fala e linguagem natural que foram destaques na mídia americana.
Atualmente, Kai-Fuu Lee é o presidente e CEO da Sinovation Ventures, empresa líder de investimentos em tecnologia com foco no desenvolvimento de companhias chinesas de alta tecnologia.
A pandemia de Covid-19 exigiu dos governos medidas eficientes e aceleradas para o enfrentamento da doença. Nesse contexto, a Ciência de Dados trouxe contribuições fundamentais no entendimento do comportamento do vírus e nas tomadas de decisões de combate.
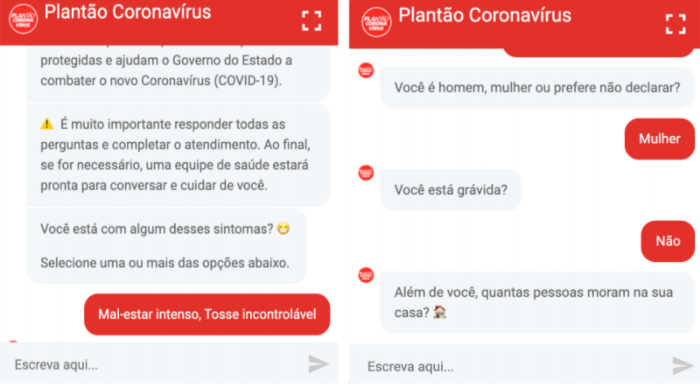
Uma das soluções desenvolvidas e disponibilizadas para a população no Estado do Ceará foi o Plantão Coronavírus, uma plataforma com mecanismos de triagem que, no primeiro momento, utiliza um chatbot para interagir com o paciente a fim de classificar seu estado de saúde em uma das três categorias: verde, amarelo e vermelho, sendo o nível de criticidade da saúde do paciente leve, moderada ou grave, respectivamente.
Trecho da conversa entre o paciente e o chatbot
As interações entre os pacientes e os profissionais de saúde por meio do Plantão Coronavírus geraram muitos dados que precisavam ser minerados, analisados e transformados em informação de valor.
Com esse objetivo, pesquisadores do Insight Lab e do Laboratório Íris desenvolveram o Sintomatic, um modelo computacional criado para auxiliar a Secretaria da Saúde do Ceará no acompanhamento dos pacientes que buscavam algum tipo de serviço de saúde. Além disso, ele contribuiu na descoberta de novos sintomas presentes em vítimas do coronavírus, sejam estes mais frequentes ou raros, e na identificação de comportamentos psicológicos alterados, como ansiedade, angústia e tristeza em pacientes positivos ou não para COVID19.
Conheça neste artigo a metodologia usada pelos pesquisadores para desenvolver esse modelo computacional.
Sintomatic
No serviço de Tele Atendimento gratuito oferecido pelo Governo do Ceará, o paciente inicialmente trocava mensagens com um robô. A partir daí, era triado de acordo com seus sintomas e, posteriormente, encaminhado para uma consulta com um profissional de saúde.
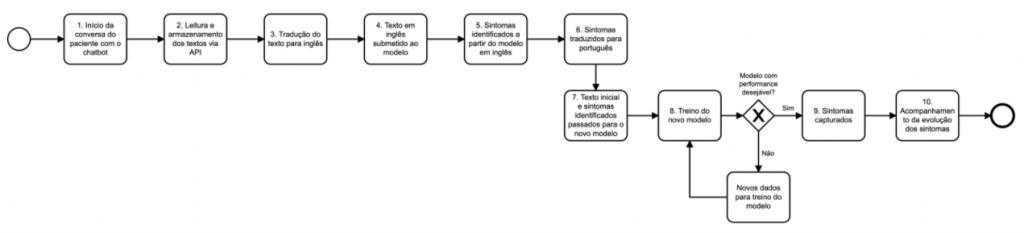
Todo o ciclo de integração com o paciente registrado por meio de textos é passado ao modelo Sintomatic para que este possa detectar sintomas em todas as etapas do atendimento.
No projeto, foi mapeada a identificação de sintomas em texto como um problema de reconhecimento de entidade (em inglês, Named Entity Recognition – NER). NER corresponde à capacidade de identificar as entidades nomeadas nos documentos e rotulá-las em classes definidas de acordo com o tipo de entidade. De forma geral, o robô de captura de sintomas possui uma rede neural que é capaz de reconhecer entidades. Neste caso, uma entidade é um sintoma.
O Sintomatic é uma rede neural que processa textos em Linguagem Natural, capaz de identificar sintomas a partir de mensagens trocadas entre o chatbot e o paciente. Por meio desse processo, o modelo reconhece novos padrões da doença anteriormente inexistentes ou despercebidos, proporcionando grandes ganhos no entendimento da doença.
Aprendizado por transferência (Transfer Learning)
A detecção de sintomas no idioma português foi um desafio, pois, até o momento, não havia de forma pública nenhum modelo capaz de realizar essa tarefa, de acordo com o conhecimento dos cientistas envolvidos. O robô desenvolvido foi treinado através de um processo de aprendizado conhecido como Transfer Learning, ou em português, aprendizado por transferência.
A técnica de aprendizagem por transferência utiliza o conhecimento adquirido ao resolver um problema e aplicá-lo em outro problema diferente, porém relacionado, permitindo progresso rápido e desempenho aprimorado ao modelar a segunda tarefa. Em outras palavras, a transferência de aprendizado é a melhoria do aprendizado em uma nova tarefa através da transferência de conhecimento de uma tarefa relacionada que já foi aprendida.
A inovação tecnológica promovida pelo Sintomatic é um modelo neural pioneiro no reconhecimento de sintomas em português, principalmente porque a língua portuguesa carece de modelos NER.
Etapas de treinamento
Para treinar o Sintomatic foi utilizado o scispaCy, um pacote Python que contém modelos de spaCy para processar textos biomédicos, científicos ou clínicos.
Em particular, há um tokenizador personalizado que adiciona regras de tokenização baseando-se em regras do spaCy, um etiquetador POS e analisador sintático treinado em dados biomédicos e um modelo de detecção de extensão de entidade. Separadamente, também existem modelos NER para tarefas mais específicas.
Para este trabalho, o modelo utilizado foi o en ner bc5cdr md do SciSpacy, em um processo de transfer learning para treinar um novo modelo de reconhecimento e captura de sintomas em português.
A primeira etapa do processo de treino do rastreador foi traduzir os textos que inicialmente estavam em língua portuguesa para o idioma inglês. Em seguida, inserir como parâmetro de entrada cada texto (em inglês) ao modelo do scispacy, analisar o resultado gerado por este modelo e, logo após, traduzir os sintomas capturados pelo modelo do scispacy em inglês para português.
O conjunto de treinamento para o Sintomatic (novo modelo em português), é composto do texto original e os sintomas capturados pelo modelo do scispacy em português. Esse processo foi executado de forma contínua até que a função de erro da rede se estabilizasse.
Ao final, foi possível atingir para o Sintomatic, F1-score de 85.66, o que é competitivo se comparado ao modelo em inglês, que tem F1-score igual a 85.02.
Etapas do processo:
Fluxo dos dados
Nas etapas de translação dos textos foi utilizada a rede de tradução do Google. Atualmente, essas redes de tradução apresentam resultados muito fiéis ao esperado, tornando os ruídos insignificantes quando analisados no contexto deste trabalho.
Um diferencial do Sintomatic é a não necessidade de classificação manual realizada por um humano para reconhecimento de entidades. Em um cenário onde havia vasta quantidade de dados e pouco tempo para processar essas informações, o ganho com a otimização dessa etapa de treino foi crucial no apoio à tomada de decisão.
Boletim Digital
Para o acompanhamento dos dados capturados pelo robô Sintomatic e monitoramento das demais informações sobre a pandemia, foi desenvolvido o Boletim Digital COVID-19 do Ceará. Essa é uma solução tecnológica construída por cientistas de dados onde é feito todo o processo de mineração do dado bruto até sua exposição em painéis gráficos acompanhados de textos explicativos a respeito de cada uma das análises abaixo:
número de pacientes atendidos;
sintomas mais frequentes e raros;
evolução dos sintomas por semana epidemiológica;
sintomas ao longo do tempo.
Veja no vídeoabaixo uma demonstração do funcionamento do Sintomatic:
Atualmente, o Sintomatic é utilizado na plataforma de Tele Atendimento do Estado do Ceará, onde desempenha papel pioneiro na área da saúde.
Você está buscando um ótimo livro sobre processamento de linguagem natural? Então conheça o Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit, dos autores Steven Bird, Ewan Klein e Edward Loper.
O livro é baseado na linguagem de programação Python juntamente com a biblioteca de código aberto Natural Language Toolkit (NLTK) e é uma introdução prática ao importante, e sempre em expansão, campo do Processamento de Linguagem Natural (PLN). Com Natural Language Processing with Python, você aprenderá a escrever programas reais e compreenderá o valor de ser capaz de testar uma ideia por meio da implementação.
Os autores destacam a busca pelo equilíbrio entre teoria e aplicação, assim, a abordagem adotada cobre os fundamentos teóricos e faz uma análise linguística e computacional cuidadosa. É um material que oferece conjuntos de dados ricamente anotados usando uma gama abrangente de estruturas de dados linguísticos e ajuda a compreender os principais algoritmos para analisar o conteúdo e a estrutura da comunicação escrita.
Este livro:
• Extrai informações de texto não estruturado, seja para indicar o tópico ou identificar “entidades nomeadas”.
• Analisa a estrutura linguística no texto, incluindo análise e análise semântica.
• Integra técnicas extraídas de campos tão diversos como linguística e inteligência artificial.
E te ajudará a:
• Entender como os conceitos-chave da PLN e linguística são usados para descrever e analisar a linguagem.
• Compreender como as estruturas de dados e algoritmos são usados em PLN.
• Desvendar como os dados da linguagem são armazenados em formatos padrão e como os dados podem ser usados para avaliar o desempenho das técnicas de PLN.
Estrutura
Capítulos 1-3: Os primeiros capítulos são organizados em ordem de dificuldade conceitual, começando com uma introdução prática ao processamento de linguagem que mostra como explorar textos de interesse usando Python.
Capítulo 4: Neste capítulo sobre programação estruturada consolidam-se os tópicos de programação espalhados pelos capítulos anteriores.
Capítulos 5-7: A partir daqui, o ritmo aumenta e passa-se para a cobertura de tópicos fundamentais no processamento de linguagem: marcação, classificação e extração de informações.
Capítulos 8-10: Examinam-se maneiras de analisar uma frase, reconhecer sua estrutura sintática e construir representações de significado.
Capítulo 11: O capítulo final é dedicado a dados linguísticos e como eles podem ser gerenciados de forma eficaz.
Cada capítulo termina com uma série de exercícios, que são fundamentais para consolidar o conteúdo.
AUTORES
Edward Loper, Ewan Klein e Steven Bird
Steven Bird: Atualmente, professor da Charles Darwin University e Pesquisador Associado Sênior no Linguistic Data Consortium da Universidade da Pensilvânia, foi professor associado do Department of Computer Science and Software Engineering da Universidade de Melbourne. Ele concluiu seu doutorado em fonologia computacional pela Universidade de Edimburgo sob a supervisão de Ewan Klein, também autor de Natural Language Processing with Python. Além disso, Bird passou vários anos como diretor associado do Linguistic Data Consortium, onde liderou uma equipe de P&D para criar modelos e ferramentas para grandes bancos de dados de texto anotado.
Ewan Klein: Professor de Tecnologia da Linguagem na School of Informatics da Universidade de Edimburgo, concluiu seu doutorado em semântica formal na Universidade de Cambridge. Também foi Gerente de Pesquisa do Natural Language Research Group, atuando como responsável pelo processamento de diálogo falado.
Edward Loper: Doutor em aprendizado de máquina para processamento de linguagem natural na Universidade da Pensilvânia. Edward foi aluno de Steven Bird em linguística computacional e se tornou professor assistente, passando a contribuir com o desenvolvimento da NLTK. Além da NLTK, ele ajudou a desenvolver dois pacotes para documentar e testar o software Python: epydoc e doctest.
Por tratar-se de uma nova ameaça, sabe-se muito pouco sobre o coronavírus (Sars-CoV-2). Esse fator dá grande abertura para disseminação de fake news (como ficou popularmente conhecido o compartilhamento de informações falsas), que podem ir desde supostos métodos de prevenção, tratamentos caseiros, cura do vírus e até mesmo tratamentos controversos recomendados por médicos, mesmo que não haja comprovação ou evidência científica para tais. Tudo isso pode dificultar o trabalho de órgãos de saúde, prejudicar a adoção de medidas de distanciamento social pela população e acarretar aumentos dos números de infectados e de morte pelo vírus.
Para diminuir os impactos dessa desinformação, diversos sites de checagem de fatos têm ferramentas que identificam e classificam (manualmente) tais notícias. Em geral, essas ferramentas poderiam fazer uso de algoritmos de aprendizagem de máquina para classificação de notícias. Diante dessa problemática, é evidente a necessidade de elaborar mecanismos e ferramentas que possam combater eficientemente o caos das fakes news.
Por isso, durante as disciplinas de Aprendizagem de Máquina e Mineração de Dados (Programa de Pós-graduação em Ciência da Computação da Universidade Federal do Ceará (MDCC-UFC)), nós(Andreza Fernandes, Felipe Marcel, Flávio Carneiro e Marianna Ferreira) propusemos um detector de fake news para analisar notícias sobre o COVID-19 divulgadas em redes sociais. Nosso objetivo é ajudar a população quanto ao esclarecimento da veracidade dessas informações.
Agora, detalharemos o processo de desenvolvimento desse detector de fake news.
Objetivos do projeto
Formar uma base dados de textos com notícias falsas e verdadeiras acerca do COVID-19;
Diminuir enviesamento das notícias;
Experimentar diferentes representações textuais;
Experimentar diferentes abordagens clássicas de aprendizagem de máquina e deep learning;
Construir um BOT no Telegram que ajude na detecção de notícias falsas relacionadas ao COVID-19.
Entendendo as terminologias usadas
Para o entendimento dos experimentos realizadas, vamos conceituar alguns pontos chaves e técnicas de Processamento de Linguagem Natural.
Tokenização: Esse processo transforma todas as palavras de um texto, dado como entrada, em elementos (conhecidos como tokens) de um vetor.
Remoção de Stopwords: Consiste na remoção de palavras de parada, como “a”, “de”, “o”, “da”, “que”, “e”, “do”, dentre outras, pois na maioria das vezes não são informações relevantes para a construção do modelo.
Bag of words: É uma representação simplificada e esparsa dos dados textuais. Consiste em gerar uma bolsa de palavras do vocabulário existente no dado, que constituirá as features do dataset. Para cada sentença é assinalado um “1” nas colunas que apresentam as palavras que ocorrem na sentença e “0” nas demais.
Term Frequency – Inverse Document Frequency (TF-IDF): Indica a importância de uma palavra em um documento. Enquanto TF está relacionada à frequência do termo, IDF busca balancear a frequência de termos mais comuns/frequentes que outros.
Word embeddings: É uma forma utilizada para representar textos, onde palavras que possuem o mesmo sentido têm uma representação muito parecida. Essa técnica aprende automaticamente, a partir de um corpus de dados, a correlação entre as palavras e o contexto, possibilitando que palavras que frequentemente ocorrem em contextos similares possuam uma representação vetorial próxima. Essa representação possui a vantagem de ter um grande poder de generalização e apresentar baixo custo computacional, uma vez que utiliza representações densas e com poucas dimensões, em oposição a técnicas esparsas, como Bag of Words. Para gerar o mapeamento entre dados textuais e os vetores densos mencionados, existem diversos algoritmos disponíveis, como Word2Vec e FastText, os quais são utilizados neste trabalho.
Out-of-vocabulary (OOV): Consiste nas palavras presentes no dataset que não estão presentes no vocabulário da word embedding, logo, elas não possuem representação vetorial.
Edit Distance: Métrica que quantifica a diferença entre duas palavras, contando o número mínimo de operações necessárias para transformar uma palavra na outra.
Metodologia
Agora iremos descrever os passos necessários para a obtenção dos resultados, geração dos modelos e escolha daquele com melhor performance para a efetivação do nosso objetivo.
Obtenção dos Dados
Os dados utilizados para a elaboração dos modelos foram adquiridos das notícias falsas brasileiras sobre o COVID-19, dispostos noChequeado, e de um web crawler dos links das notícias, utilizadas para comprovar que a notícia é falsa no Chequeado, para formar uma base de notícias verdadeiras. Além disso também foi realizado um web crawler para obtenção de notícias doFato Ou Fakedo G1.
Originalmente, os dados obtidos do Chequeado possuíam as classificações “Falso”, “Enganoso”, “Parcialmente falso”, “Dúbio”, “Distorcido”, “Exagerado” e “Verdadeiro mas”, que foram mapeadas todas para “Falso”. Com isso, transformamos nosso problema em classificação binária.
No final, obtivemos um dataset com 1.753 notícias, sendo 808 fakes, simbolizada como classe 0, e 945 verdadeiras, classe 1, com um vocabulário de tamanho 3.698. Com isso, dividimos o nosso dado em conjunto de treino e teste, com tamanhos de 80% e 20%, respectivamente.
Pré-processamento
Diminuição do viés. Ao trabalhar e visualizar os dados, notamos que algumas notícias verdadeiras vinham com palavras e sentenças que enviesavam e deixavam bastante claro para os algoritmos o que é fake e o que é verdadeiro, como: “É falso que”, “#Checamos”, “Verificamos que” e etc. Com isso, removemos essas sentenças e palavras, a fim de diminuir o enviesamento das notícias.
Limpeza textual. Após a etapa anterior, realizamos a limpeza do texto, consistindo em remoção de caracteres estranhos e sinais de pontuação e uso do texto em caixa baixa.
Tokenização. A partir do texto limpo, inicializamos o processo de tokenização das sentenças.
Remoção das Stopwords. A partir das sentenças tokenizadas, removemos as stopwords.
Representação textual
Análise exploratória
A partir do pré-processamento dos dados brutos, inicializamos o processo de análise exploratória dos dados. Verificamos o tamanho do vocabulário do nosso dataset, que totaliza 3.698 palavras.
Análise do Out-of-vocabulary. Com isso, verificamos o tamanho do nosso out-of-vocabulary em relação às word embeddings pré-treinadas utilizadas, totalizando 32 palavras. Um fato curioso é que palavras chaves do nosso contexto encontram-se no out-of-vocabulary e acabam sendo mapeadas para palavras que não tem muita conexão com o seu significado. Abaixo é possível ver algumas dessas palavras mais à esquerda, e a palavra a qual foram mapeadas mais à direita.
Mapeamento de palavras
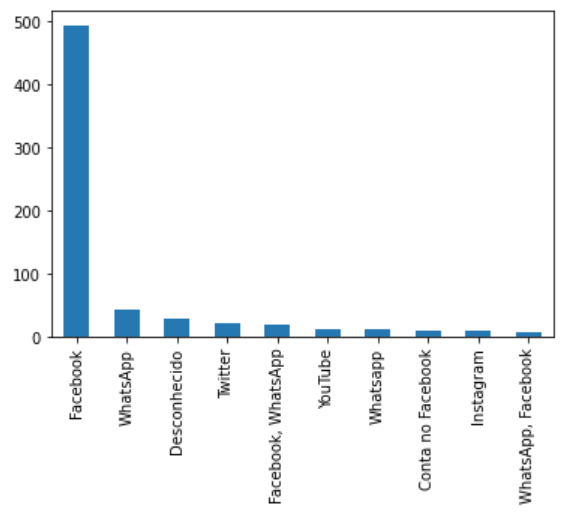
Análise da frequência das fake news por rede social. O dado bruto original advindo do Chequeado possui uma coluna que diz sobre a mídia social em que a fake news foi divulgada. Após uma análise visual superficial, apenas plotando a contagem dos valores dessa coluna (que acarreta até na repetição de redes sociais), notamos que os maiores veículos de propagação de fake news são o Facebook e Whatsapp.
Frequência de fake news por rede social
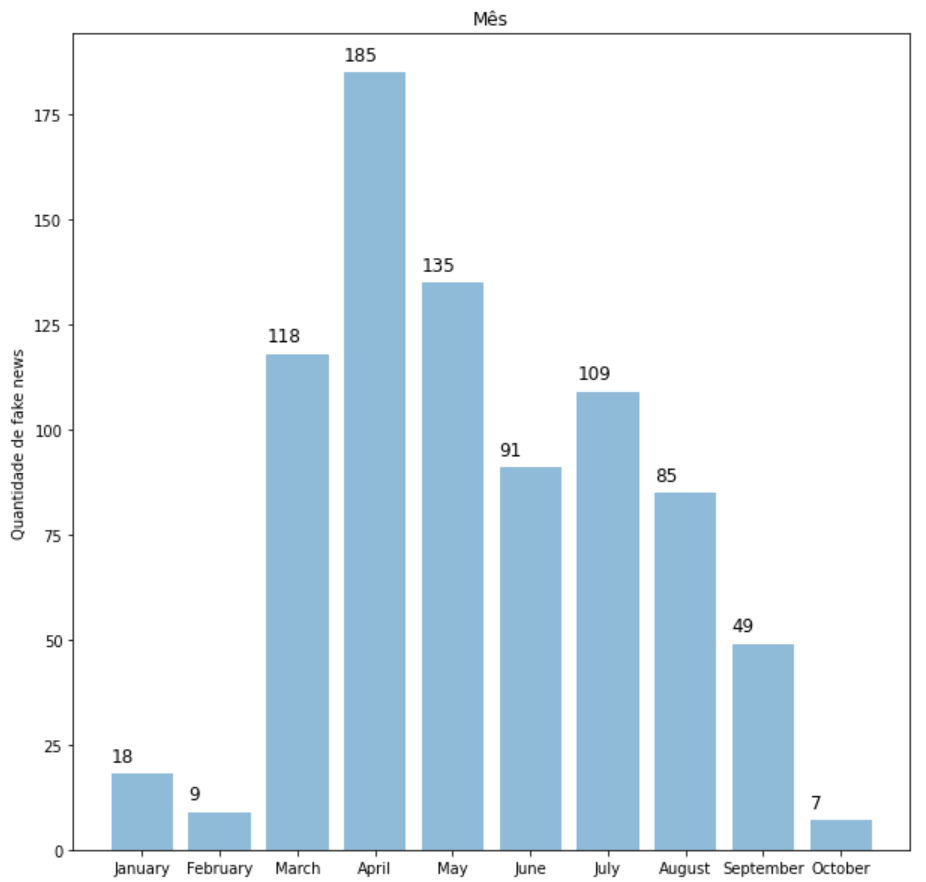
Análise da quantidade de fake news ao longo dos meses. O dado bruto original advindo do Chequeado também possui uma coluna que informava a data de publicação da fake news. Após realizar uma análise visual da distribuição da quantidade de fake news ao longo dos meses, notamos que o maior número de fake news ocorreu em abril, mês em que a doença começou a se espalhar com maior velocidade no território brasileiro. De acordo com o G1, em 28 de abril, o Brasil possuía 73.235 casos do novo coronavírus (Sars-CoV-2), com 5.083 mortes. Além disso, foi nesse mês que começaram a surgir os boatos de combate do Coronavírus via Cloroquina, além de remédios caseiros.
Volume de fake news relacionadas ao COVID-19 ao longo dos meses
Análise da Word Cloud. Com as sentenças tokenizadas, também realizamos uma visualização usando a técnica de Word Cloud, que apresenta as palavras do vocabulário em um tamanho proporcional ao seu número de ocorrência no todo. Com essa técnica, realizamos duas visualizações, uma para as notícias verdadeiras e outra para as fake news.
Nuvem de palavras nas notícias falsas
Nuvem de palavras nas notícias verdadeiras
Divisão treino e teste
A divisão dos conjuntos de dados entre treino e teste foi feita com uma distribuição de 80% e 20% dos dados, respectivamente.Os dados de treino foram ainda divididos em um novo conjunto de treino e um de validação, com uma distribuição de 80% e 20% respectivamente.
Aplicação dos modelos
Para gerar os modelos, escolhemos algoritmos e técnicas clássicas de aprendizagem de máquina, tais como técnicas atuais e bastante utilizadas em competições, sendo eles:
Regressão Logística (*): exemplo de classificador linear;
K-NN (*): exemplo de modelo não-paramétrico;
Análise Discriminante Gaussiano (*): exemplo de modelo que não possui hiperparâmetros;
Árvore de Decisão: exemplo de modelo que utiliza abordagem da heurística gulosa;
Random Forest: exemplo de ensemble de bagging de Árvores de Decisão;
SVM: exemplo de modelo que encontra um ótimo global;
XGBoost: também um ensemble amplamente utilizado em competições do Kaggle;
LSTM-Dense: exemplo de arquitetura que utiliza deep learning.
Os algoritmos foram utilizados por meio de implementações próprias (aqueles demarcados com *) e uso da biblioteca scikit-learn e keras. Para todos os algoritmos, com exceção daqueles que não possuem hiperparâmetros e LSTM-Dense, realizamos Grid Search em busca dos melhores hiperparâmetros e realizamos técnicas de Cross Validation para aqueles utilizados por meio do Scikit-Learn, com k fold igual a 5.
Obtenção das métricas
As métricas utilizadas para medir a performance dos modelos foram acurácia, Precision, Recall, F1-score e ROC.
Tabela 1. Resultados das melhores representações por algoritmo
MODELOS
PRECISION
RECALL
F1-SCORE
ACCURACY
ROC
XGBoost BOW e TF-IDF*
1
1
1
1
1
SVM BOW E TF-IDF*
1
1
1
1
1
Regressão Logística BOW
0.7560
0.7549
0.7539
0.7549
0.7521
LSTM FASTTEXT
0.7496
0.7492
0.7493
0.7492
0.7492
Random Forest TF-IDF
0.7407
0.7407
0.7402
0.7407
0.7388
Árvore de Decisão TF-IDF
0.7120
0.7122
0.7121
0.7122
0.7111
Análise Discriminante Gaussiano Word2Vec
0.7132
0.7122
0.7106
0.7122
0.7089
k-NN FastText
0.6831
0.6809
0.6775
0.6638
0.6550
Tabela 2. Resultados das piores representações por algoritmo
MODELOS
PRECISION
RECALL
F1-SCORE
ACCURACY
ROC
XGBoost Word2Vec
0.7238
0.7236
0.7227
0.7236
0.7211
SVM Word2Vec
0.7211
0.7179
0.7151
0.7179
0.7135
Árvore de Decisão Word2Vec
0.6391
0.6353
0.6351
0.6353
0.6372
Random Forest Word2Vec
0.6231
0.6210
0.6212
0.6210
0.62198
Regressão Logística FastText
0.6158
0.5982
0.5688
0.59829
0.5858
Análise Discriminante Gaussiano TF-IDF
0.5802
0.5811
0.5801
0.5811
0.5786
k-NN BOW
0.5140
0.5099
0.5087
0.5042
0.5127
LSTM WORD2VEC (*)
0.4660
0.4615
0.4367
0.4615
0.4717
Resultados
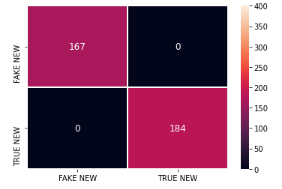
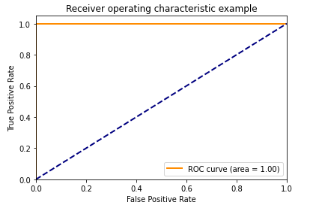
Com os resultados apresentados percebemos que os modelos SVM e XGBoost com as representações TF-IDF e BOW atingiram as métricas igual a 100%. Isso pode ser um grande indicativo de sobreajuste do modelo aos dados. Abaixo podemos visualizar a matriz de confusão e a curva ROC dos mesmos.
Matriz de confusão
Curva ROC
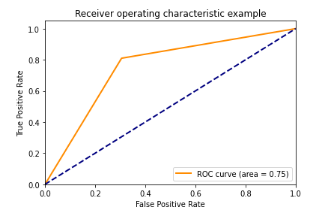
Logo após vem a Regressão Logística com métricas em torno de ~75.49%! Abaixo podemos visualizar sua matriz de confusão e a curva ROC.
Matriz de confusão
Curva ROC
Exemplos de classificações da Regressão Logística
True Positive (corretamente classificada)
Texto que diz que vitamina C e limão combatem o coronavírus
True Negative (corretamente classificada)
Notícia divulgada em 2015 pela TV italiana RAI comprova que o novo coronavírus foi criado em laboratório pelo governo chinês.
False Positive (erroneamente classificada)
Vitamina C com zinco previne e trata a infecção por coronavírus
False Negative (erroneamente classificada)
Que neurocientista britânico publicou estudo mostrando que 80% da população é imune ao novo coronavírus
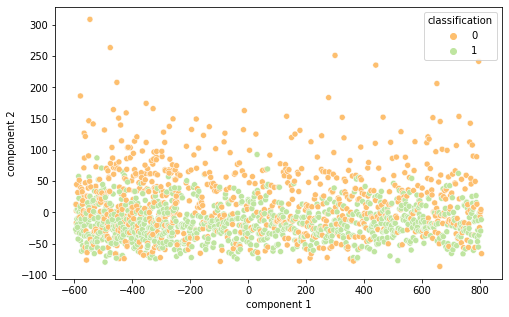
Intrigados com os resultados, resolvemos visualizar as diferentes representações de dados em 2 componentes principais (visto a alta dimensionalidade do dado, o que prejudica a análise do que está acontecendo de fato) por meio das técnicas de PCA e T-SNE, separando por cor de acordo com sua classificação.
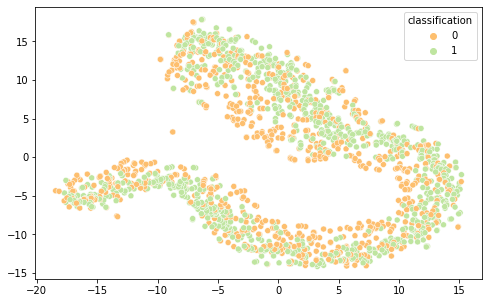
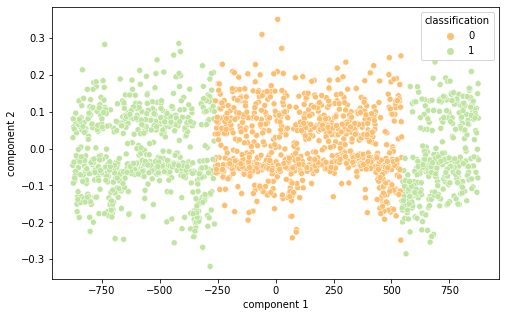
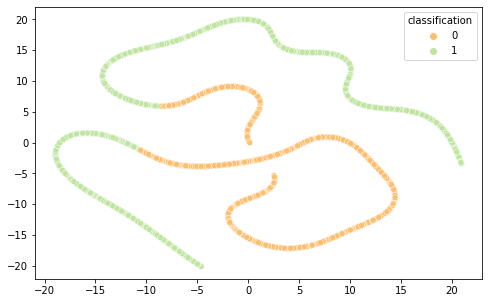
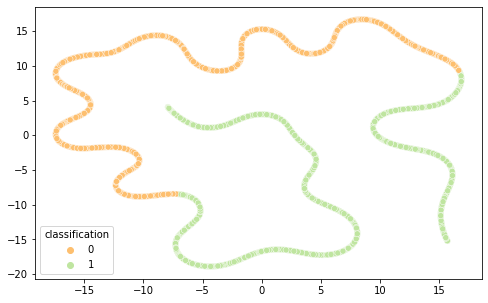
É interessante notar que as representações de word embeddings utilizadas possui uma representação bastante confusa e misturada.Já as representações TF-IDF e Bag of Words são facilmente separáveis.
FastText PCA(Semelhante ao Word2Vec)
FastText T-SNE
Word2Vec T-SNE
BOW PCA (Semelhante ao TF-IDF)
BOW T-SNE
TF-IDF T-SNE
Conclusão
A base de dados utilizada para obtenção dos modelos foi obtida por meio do site Chequeado, e, posteriormente, houve o enriquecimento dessa base por meio do web crawler, totalizando 1.383 registros, sendo 701 fake news e 682 notícias verdadeiras.
Para representação textual foram utilizadas as técnicas Bag of Words, TF-IDF e Word embeddings Word2Vec e FastText de 300 dimensões com pesos pré-treinados obtidas por meio da técnica CBOW com dimensões, disponibilizadas pelo Núcleo Interinstitucional de Linguística Computacional (NILC). Para gerar os modelos foram utilizados os algoritmos Regressão Logística, kNN, Análise Discriminante Gaussiano, Árvore de Decisão, Random Forest, Gradient Boosting, SVM e LSTM-Dense. Para avaliação dos modelos foi utilizado as métricas Acurácia, Precision, Recall, F1-score, AUC-ROC e matriz de confusão.
Considerando os experimentos e os resultados, conclui-se que o objetivo principal deste trabalho, gerar modelos capazes de classificar notícias extraídas de redes sociais relacionadas ao COVID-19 como falsas e verdadeiras, foi alcançado com êxito. Como resultados, vimos que os modelos SVM e XGBoost com TF-IDF e BOW atingiram 100% nas métricas, com grandes chances de terem se sobreajustado aos dados. Com isso, consideramos como melhor modelo a Regressão Logística com a representação BOW, atingindo as métricas com valores próximos a 75.49%.
O pior classificador foi o kNN com o BOW e LSTM-Dense com Word2Vec, porém é importante ressaltar que este último não contou com Grid Search e foi treinado com poucas épocas. No geral, as melhores representações foram a TF-IDF e BOW e a pior o Word2Vec.
Para este projeto houveram algumas dificuldades, sendo a principal delas a formação da base de dados, visto que o contexto pandêmico do COVID-19 é algo novo e devido à limitação da API do Twitter em relação ao tempo para extrair os tweets, que era originalmente a ideia da base de dados para esse projeto. Além disso, também houve a dificuldade de remoção do viés dos dados.
Como trabalhos futuros, visamos:
Ampliar a base de dados;
Investigar o que levou ao desempenho do SVM, XGBOOST com as representações TF-IDF e BOW.
Analisar performance dos modelos utilizando outras word embeddings pré-treinadas, como o BERT, Glove e Wang2vec.
Investigar o uso do modelo pré-treinado do BERT e com fine-tuned.
Aplicar PCA Probabilístico
Utilizar arquiteturas de deep learning mais difundidas na comunidade científica.
Se você quer fazer parte de um time com pessoas criativas, curiosas, comunicativas e com paixão por criar, aprender e testar novas tecnologias, então esta é a sua oportunidade! O Insight está buscando novos profissionais, veja aqui as seis funções disponíveis e não se esqueça de acessar o link com a descrição completa de cada vaga.
Processos de segurança de: rede, aplicação, endpoints, dados, identidade, bancos de dados, e infraestrutura, nuvem, mobile e planejamento de recuperação de desastres
Para concorrer a esta vaga envie seu currículo em anexo para o email jobs@insightlab.ufc.br com o assunto “[JOB32] Cyber Security”.
A ciência de dados tem revolucionado praticamente todas as áreas. Na educação, utilizando modelos para uma melhor avaliação de estudantes, na medicina, identificando e prevendo doenças, no futebol, obtendo o máximo valor das escalações de um time.
Neste artigo, apresentaremos 7 exemplos onde a ciência de dados é utilizada como uma poderosa ferramenta, com modelos e algoritmos que ajudam a analisar, prever e, consequentemente, obter melhores resultados em cada uma dessas áreas.
1- Segurança Pública
Em uma ação criminosa existem diversos elementos envolvidos. Informações colhidas anteriormente sobre os suspeitos (a exemplo, a ficha criminal) e sobre a região na qual um crime foi cometido (como entorno e vias de acesso) são fatores importantes na elucidação de delitos.
No entanto, muitas vezes esses dados coletados em diferentes regiões e por diferentes órgãos não estão integradas em uma mesma base de dados, o que prejudica o trabalho dos agentes policiais.
O Ceará tem sido um exemplo do uso inteligente da ciência de dados na segurança pública. Em 2019, o estadoganhou interesse nacional pela grande redução de seus índices criminais. Entre as diversas ações tomadas para atingir esse resultado, um dos maiores destaques é o uso de soluções tecnológicas baseadas em ciência de dados.
Em parceria com a Secretaria da Segurança Pública e Defesa Social (SSPDS), o Insight Lab desenvolveu ferramentas que têm ajudado a entender e combater práticas criminosas.
Conheça algumas dessas ferramentas:
Sistema Policial Indicativo de Abordagem (SPIA)
O Spia tem sido usado no enfraquecimento da mobilidade de criminosos, pois ajuda na identificação de veículos roubados. É um sistema de inteligência artificial que integra as bases de dados de órgãos federais, estaduais e municipais aos dados captados por mais 3.300 câmeras espalhadas pelo Ceará.
Big Data “Odin”
Como apresentado no portal do Governo do Estado do Ceará, o sistema de big data Odin “armazena e cruza dados obtidos por mais de 50 sistemas dos órgãos de segurança e de entidades parceiras. Todas as informações podem ser vistas em tempo real dentro de um painel que simplifica os processos de investigação e de tomadas de decisão, o Cerebrum.”
Portal do Comando Avançado (PCA)
Exclusivo para profissionais da segurança pública do Ceará, é um aplicativo para celular que reúne informações civil e criminal da população cearense, dados de veículos e motoristas, biometria e o reconhecimento facial.
2 – Evasão fiscal e detecção de fraude
Um grande desafio dentro de empresas e organizações é a detecção de fraudes e a evasão fiscal. Uma pequena porcentagem dessas atividades pode representar perdas bilionárias para as instituições.
Entretanto, os avanços na análise de fraudes, com o uso de ciência de dados e o Big Data, são uma perfeita ferramenta para prevenir tais atividades. Além da redução de informações, com essas ferramentas pode-se diferenciar entre contribuinte legítimo e fraudador, utilizando classificação de dados, clustering e reconhecimento de padrão, por exemplo. Diferentes fontes de dados são usadas para a análise, sejam dados estruturados ou não estruturados.
Diversos estudiosos estão empenhados em desvanecer esse problema. Veja um exemplo disso: a partir de dados reais da Secretaria da Fazenda do Estado do Ceará (Sefaz-CE), sete pesquisadores (entre eles o coordenador do Insight Lab, José Macêdo) aplicaram um novo método, ALICIA, para detectar potenciais fraudadores fiscais. Esse método de seleção de recursos é baseado em regras de associação e lógica proposicional.
Os autores explicam que ALICIA é estruturado em três fases:
Ele gera um conjunto de regras de associação relevantes a partir de um conjunto de indicadores de fraude (recursos).
A partir de tais regras de associação, ALICIA constrói um gráfico, cuja estrutura é então usada para determinar as características mais relevantes.
Para conseguir isso, ALICIA aplica uma nova medida de centralidade chamada de Importância Topológica do Recurso.
Os teste feitos com ALICIA em quatro diferentes conjuntos de dados do mundo real mostram sua eficiência superior a outros oito métodos de seleção de recursos. Os resultados mostram que Alicia atinge pontuações de medida F de até 76,88% e supera de forma consistente seus concorrentes.
3 – Saúde
Uma das principais aplicações da ciência de dados é na área da saúde. Esse setor utiliza intensamente data science para descoberta de novas drogas, na prevenção, diagnóstico e tratamento de doenças e no monitoramento da saúde de pacientes.
E durante a pandemia de Covid-19, a ciência de dados foi um dos primeiros auxílios buscados para que se pudesse entender o comportando do vírus na população mundial, criar modelos preditivos sobre seus impactos e divulgar ao público, especialmente através da visualização de dados, estatísticas relacionadas à doença.
Como exemplo de transparência dos dados durante a pandemia, destacamos a plataforma cearense IntegraSUS Analytics.
Como descrito pela Secretaria da Saúde do Ceará, o IntegraSUS Analytics é uma ferramenta com a qual “pesquisadores, profissionais e estudantes de ciência de dados ou de tecnologia da informação poderão ter acesso ao cenário atual da saúde no Estado. Tudo por meio dos códigos e modelos utilizados na construção do IntegraSUS. A plataforma também oferece datasets sobre diferentes áreas da saúde para aprendizado e treinamento.”
Além do IntegraSUS Analytics, o Governo do Estado esteve em parceria com o Insight Lab para desenvolver outras ações de enfrentamento ao Covid-19. Nossos pesquisadores produziram Mapas de Kernel para observar como está acontecendo o espalhamento da doença no Ceará. Junto a isso, a professora Ticiana Linhares comandou o desenvolvimento de um algoritmo de IA para entender a evolução dos sintomas do Covid-19.
Como isso acontece? Através dos textos trocados via chat (Plantão Coronavírus) entre os cidadãos e a Secretaria de Saúde, o algoritmo extrai dessas conversas os sintomas mais frequentes e avalia sua evolução.
4 – Games
Uma das indústrias em maior expansão é a de games. Contabiliza-se atualmente mais de 2 bilhões de jogadores no mundo todo, com estimativas para que esse número passe de 3 bilhões até 2023, segundo o site Statista.
Com esse super número de jogadores e a criação diária de novos jogos, uma enorme quantidade de dados são coletados, tais como o tempo de jogo do usuário, pontos de início e parada e pontuação. Essa coletânea de dados representa uma rica fonte para que especialistas estudem, aprendam e possam otimizar e melhorar os jogos.
Com a ciência de dados aplicada no mercado de jogos, é possível realizar o desenvolvimento, a monetização e o design de games, e ainda melhorar efeitos visuais, por exemplo. Com modelos que permitem a identificação de objetos, jogos tornam-se mais realistas tornando possível diferenciar jogadores pertencentes a equipes diferentes e dar comandos ao personagem específico dentro de um grupo.
A King, empresa criadora do famoso Candy Crush, tem, segundo seu diretor de produtos de serviços, Jonathan Palmer, uma cultura baseada em dados. Na King, depois que um jogo é lançado, ele continua sendo monitorado e os ajustes necessários são feitos. Eles analisam, por exemplo, se um jogo é muito difícil, então eles podem perder jogadores, e se muito fácil, os usuários ficam entediados e abandonam o jogo.
Palmer cita o nível 65 do Candy Crush Saga: “É um nível incrivelmente difícil, tinha seu próprio culto em torno dele. Percebemos que isso estava causando a agitação de muitas pessoas. Usando dados, pudemos dizer: ‘precisamos diminuir um pouco a dificuldade desse nível’.”
5 – Vida Social
O surgimento das redes sociais alterou completamente a forma como nos relacionamos, sejam relacionamentos amorosos, amizades ou relações de trabalho. Nos conectamos diariamente com inúmeras pessoas que jamais vimos. E todas as relações e ações nessas redes deixam extensos rastros de dados que influenciam, entre outras coisas, em quem você conhecerá a seguir.
Não é impressionante como o Facebook sempre acerta nas recomendações de novas amizades? Em artigo do Washington Post é dito que ele se baseia em “really good math”, mais especificamente, o Facebook utiliza um tipo de ciência de dados conhecido como network science, que basicamente busca prever o crescimento da rede social de um usuário baseado no crescimento das redes de usuários semelhantes.
Um outro exemplo é o Tinder. Ele utiliza um algoritmo que visa aumentar a probabilidade de correspondência. Esse algoritmo prioriza correspondências entre usuários ativos, usuários em uma mesma região e usuários que parecem os “tipos” uns dos outros com base em seu histórico de deslize.
6 – Esportes
A indústria do esporte é uma das mais rentáveis do mundo, gerando lucros bilionários todos os anos e, é claro, cheia de dados e estatísticas. Cada esporte está repleto de variáveis a serem estudadas, que vão desde o clima, a fisiologia de cada jogador, as decisões dos árbitros, até as escolhas feitas pelos jogadores durante uma partida. Assim, a ciência de dados vem para “decifrar” o que fazer com esses dados, revelando insights preditivos para a melhor tomada de decisão dentro de cada modalidade de esporte.
Um caso interessante para analisarmos é o da liga de basquete americana. A NBA usa o sistema de análise de arremesso da RSPCT, no qual uma câmera rastreia quando e onde a bola bate em cada tentativa de cesta. Os dados são canalizados para um dispositivo que exibe detalhes da tomada em tempo real e gera insights preditivos.
Leo Moravtchik, CEO da RSPCT, disse à SGV News que “com base em nossos dados … Podemos dizer [a um jogador]: ‘Se você está prestes a dar o último arremesso para ganhar o jogo, não tente do topo da chave, porque sua melhor localização é, na verdade, o canto direito ”
7 – Comércio eletrônico (e-commerce)
O comércio eletrônico (ou e-Commerce) é um tipo de negócio em que empresas e indivíduos compram e vendem coisas pela internet. Nesse tipo de comércio, a interação com os clientes passa por vários pontos, desde o clique em um anúncio e em produtos de interesse, até a compra e avaliação do produto.
Os dados obtidos nas plataformas de e-commerce ajudam os vendedores a construir uma imagem dos consumidores, seus hábitos de compra, quais as estratégias para “transformá-los” em clientes e ainda o tempo que isso leva.
Nesse sentido, a aplicação da ciência de dados permite a previsão da rotatividade de clientes, a segmentação destes, o impulsionamento das vendas com recomendações inteligentes de produtos, a extração de informações úteis das avaliações dos compradores, a previsão de demanda, a otimização de preços e tantas outras possibilidades.
No caso do Airbnb, a ciência de dados ajudou a renovar completamente sua função de pesquisa, destacando áreas mais requisitadas. O algoritmo do Airbnb hoje, nos rankings de busca, dá prioridade a aluguéis que estiverem em uma área com alta densidade de reservas. Antes, entretanto, os melhores aluguéis estavam localizados a uma certa distância dos centros da cidade. Isso implicava que, apesar de encontrar aluguéis legais, os locais não eram tão bons.
No dia 09 de novembro acontecerá a próxima edição do webinar do Insight Lab: Aplicação de Ciência de Dados em projetos reais. Nesse encontro você conhecerá trabalhos desenvolvidos na disciplina de Ciência de Dados, que faz parte do currículo do Programa de Pós-graduação em Ciência da Computação da Universidade Federal do Ceará (MDCC-UFC). O objetivo dos projetos foi aplicar conceitos de Data Science aprendidos ao longo do semestre na resolução de problemas reais.
Veja os três projetos selecionados para o webinar:
Projeto 1:Detecção de fake news sobre COVID-19 em redes sociais
A sociedade atual enfrenta uma infodemia de fake news sem precedentes. Na maioria das vezes, usuários de redes sociais e leitores de portais de notıcias não conseguem distinguir quais notícias são verdadeiras e quais são falsas.
Neste trabalho é apresentada uma abordagem para detecção de fake news usando técnicas de representação textuais como Word Embeddings, TF-IDF, FastText e Bert, com aplicação de modelos de aprendizagem de máquina clássicos e do estado da arte, como SVM, por exemplo. A partir de experimentos realizados, o modelo que mais se destacou em desempenho foi usado para criação de um bot classificador de fake news sobre COVID-19.
Apresentação: Felipe Marcel
Bacharel em Ciência da Computação pelo IFCE. Mestrando em Ciência da Computação (UFC). Desenvolvedor full stack no Insight Data Science Lab.
Projeto 2:Classificação automática de documentos jurídicos da SEFAZ.
A Secretaria da Fazenda do Estado do Ceará (SEFAZ) armazena diversos documentos jurídicos do governo estadual, entre leis, atos declaratórios, normas explicativas e outros. Este trabalho tem como objetivo automatizar o processo de classificação desses documentos, o que hoje é feito de forma manual, e assim economizar tempo e recursos do Estado.
Apresentação: Lucas Fernandes
Bacharel em Ciência da Computação (UFC). Mestrando em Ciência da Computação (UFC).
Projeto 3: Detecção automática de defeitos em pavimentos asfálticos com a utilização de Redes Neurais Convolucionais
Uma das etapas mais importantes do Gerenciamento da Infraestrutura Viária se refere à avaliação da qualidade funcional dos pavimentos. Além da sua função imprescindível para viabilização do transporte de cargas e de pessoas, o sistema viário precisa ser capaz de oferecer boas condições de trafegabilidade, conforto e segurança. Para isso, comumente é realizado o monitoramento da quantidade e da severidade de defeitos do tipo buracos, trincas, remendos, entre outros, por meio do levantamento visual contínuo, em que são tiradas fotos do pavimento para posterior análise manual.
Este trabalho se propõe a gerar um melhoramento em cadeia nas etapas do gerenciamento de pavimentos, com a implementação de Redes Neurais Convolucionais para detectação e classificação de vários tipos de defeitos, com imagens coletadas com smartphone a bordo de um veículo. Fato que tende a gerar significativa redução nos custos de monitoramento e grande benefício para o usuário final, a sociedade como um todo.
Apresentação: Klayver Paz
Graduando em Engenharia Civil pela UFC.
O evento acontecerá em nosso canal no Youtube com mediação de José Macêdo, coordenador do Insight Lab, e Lucas Peres, desenvolvedor full stack no Insight Lab.
O Insight apresenta aqui o livro “Machine Learning: A Probabilistic Perspective”, uma obra bem avaliada pelos leitores escrita por Kevin Patrick Murphy. Com um conteúdo extenso, mais de mil páginas, é um livro de companhia para sua carreira profissional que teve sua primeira edição lançado em 2012 e já está na sua quarta versão.
A obraé escrita de maneira informal, acessível e completa com pseudo-código para os algoritmos mais importantes. Possui todos os seus tópicos ilustrados com imagens coloridas e exemplos extraídos de domínios de aplicação como biologia, processamento de texto, visão computacional e robótica. Diferente de um tutorial, ou um livro de receitas de diferentes métodos heurísticos, a obra enfatiza uma abordagem baseada em modelos de princípios, muitas vezes usando a linguagem de modelos gráficos para especificá-los de forma concisa e intuitiva. Quase todos os modelos descritos foram implementados em um pacote de software MATLAB – PMTK (kit de ferramentas de modelagem probabilística) – que está disponível gratuitamente online.
Conteúdo
Com a quantidade cada vez maior de dados em formato eletrônico, a necessidade de métodos automatizados para análise de dados continua a crescer. O objetivo do Machine Learning (ML) é desenvolver métodos que possam detectar automaticamente padrões nos dados e, em seguida, usar esses padrões descobertos para prever dados futuros ou outros resultados de interesse. Este livro está fortemente relacionado aos campos de estatística e dados, fornecendo uma introdução detalhada ao campo e incluindo exemplos.
Com uma introdução abrangente e independente ao campo do Machine Learning, este livro traz uma abordagem probabilística unificada. A obra combina amplitude e profundidade no tema, oferecendo material de base necessário em tópicos como probabilidade, otimização e álgebra linear, bem como discussão de desenvolvimentos recentes no campo, incluindo campos aleatórios condicionais, regularização L1 e Deep Learning.
Público-alvo
A leitura é indicada para estudantes de graduação de nível superior, de nível introdutório e estudantes iniciantes na pós-graduação em ciência da computação, estatística, engenharia elétrica, econométrica ou qualquer outro que tenha a formação matemática apropriada.
É importante que o leitor esteja familiarizado com cálculo multivariado básico, probabilidade, álgebra linear e programação de computador.
Sobre o autor
Kevin P. Murphy é um cientista pesquisador do Google. Anteriormente, ele foi Professor Associado de Ciência da Computação e Estatística na University of British Columbia.
Críticas sobre a obra
Kevin Murphy se destaca em desvendar as complexidades dos métodos de aprendizado de máquina enquanto motiva o leitor com uma série de exemplos ilustrados e estudos de caso do mundo real. O pacote de software que acompanha inclui o código-fonte para muitas das figuras, tornando mais fácil e tentador mergulhar e explorar esses métodos por si mesmo. Uma compra obrigatória para qualquer pessoa interessada em aprendizado de máquina ou curiosa sobre como extrair conhecimento útil de big data.
John Winn, Microsoft Research, Cambridge
Este livro será uma referência essencial para os praticantes do aprendizado de máquina moderno. Ele cobre os conceitos básicos necessários para entender o campo como um todo e os métodos modernos poderosos que se baseiam nesses conceitos. No aprendizado de máquina, a linguagem de probabilidade e estatística revela conexões importantes entre algoritmos e estratégias aparentemente díspares. Assim, seus leitores se articulam em uma visão holística do estado da arte e prontos para construir a próxima geração de algoritmos de Machine Learning.
David Blei, Universidade de Princeton
———— . . . ————
Empolgado para se tornar um profissional mais preparado? Conta aqui, que livro você gostaria que o Insight indicasse?
Apresentamos hoje o curso “Imersão em Ciência de Dados”, totalmente gratuito e disponível em nosso canal no YouTube. Essa é uma nova contribuição do Insight Lab para a formação de novos cientistas de dados brasileiros. O curso tem o propósito de ambientar você no campo de Data Science ao apresentar áreas de conhecimento, metodologias e ferramentas que compõem esta ciência.
Conheça os professores que irão te acompanhar neste curso:
Gustavo Coutinho: Professor no Instituto Federal de Educação, Ciência e Tecnologia do Ceará (IFCE), doutorando em Ciência da Computação na Universidade Federal do Ceará (UFC) e pesquisador do Insight Lab.
Regis Pires: Doutor em Ciência da Computação (UFC), professor na Universidade Federal do Ceará (UFC) e coordenador de capacitação e pesquisador do Insight Lab.
José Florêncio: Doutor em Ciência da Computação (UFC) e coordenador negocial e pesquisador do Insight Lab.
Lucas Peres: Doutorando em Ciência da Computação (UFC) e desenvolvedor full stack do Insight Lab.
Lívia Almada: Professora na Universidade Federal do Ceará (UFC), doutoranda em Ciência da Computação (UFC) e pesquisadora do Insight Lab.
Carlos Júnior: Mestre em Ciência da Computação, doutorando em Ciência da Computação (UFC) e pesquisador do Insight Lab.
José Macêdo: Doutor em Ciência da Computação (UFC), professor da UFC e coordenador do Insight Lab.
Ticiana Linhares: Doutora em Ciência da Computação (UFC), professora da UFC e coordenadora de pesquisa do Insight Lab.
Durante as próximas semanas, esta página será atualizada com os links dos novos módulos disponíveis. Então, continue nos acompanhando para receber todas essas informações. Bons estudos!
A nova edição do nosso webinar já está programada. Agora, o tema debatido será “Por onde começar e o que você deve saber antes de iniciar sua carreira em Ciência de Dados”.
Nesta conversa, cinco profissionais compartilharão suas experiências no mercado de Data Science sobre a perspectiva da evolução da Ciência de Dados e a caracterização atual do mercado, destacando as pesquisas em alta, o perfil do profissional almejado na área e também como acontece o fluxo produtivo entre os setores acadêmico e privado.
Durante o webinar, também será apresentado o curso gratuito e online de Ciência de Dados produzido pelo Insight Lab.
Participantes
José Macêdo: Coordenador do Insight Lab, Cientista-chefe de Dados do Governo do CE e professor da UFC
Regis Pires:Coordenador de Capacitação do Insight Lab, cientista de dados do Íris e professor da UFC
Lívia Almada:Pesquisadora no Insight Lab e professora da UFC
Lucas Peres:Desenvolvedor Full Stack no Insight Lab
André Meireles:Pesquisador no Virtus UFCG e professor na UFC
Agenda
Dia: 16 de setembro
Horário: 16h
A transmissão acontecerá no canal do Insight Lab no Youtube,aqui.
Este evento é feito para você, então se sinta à vontade para enviar suas perguntas através do chat no YouTube, elas serão respondidas no último bloco do webinar.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade