Olha quem acabou de chegar na internet: nosso “Curso de Introdução ao Docker”. O curso foi ministrado na Universidade Federal do Ceará (UFC), em 2019, e agora está disponível em nosso canal no YouTube.
Gustavo Coutinho: Professor no Instituto Federal de Educação, Ciência e Tecnologia do Ceará (IFCE) e doutorando em Ciências da Computação na Universidade Federal do Ceará (UFC)
Lucas Peres: Desenvolvedor full-stack e doutorando em Ciências da Computação na Universidade Federal do Ceará (UFC)
Regis Pires: Cientista de dados do Insight Lab e do Íris (Lab de Inovação e Dados do Ceará).
A cultura de aprender pela internet ganha novos adeptos todos os dias. A possibilidade de estudar no melhor horário para você, de explorar metodologias, participar de fóruns online com estudantes do mundo todo, de estudar de casa ou de qualquer outro lugar são alguns dos motivos para os cursos online terem crescido tanto.
Este ano, diante da necessidade do isolamento social provocada pela pandemia de COVID-19, temos mais um motivo para buscar as salas de aula virtuais. Confira abaixo cinco cursos online e gratuitos para fazer durante a quarentena. As opções de cursos que serão apresentadas abrangem os três níveis: iniciante, médio e avançado.
*O conteúdo dos cursos indicados é gratuito, mas, se você quiser receber um certificado de conclusão, precisará pagar.
Cursos para iniciantes
1. Aprendizado de Máquina (Machine Learning)
Plataforma: Coursera
Oferecido por: Standford
Carga horária: 54h
Requisitos: não existem exigências iniciais, mas alguma compreensão de cálculo e, especialmente, de Álgebra Linear será importante para aproveitar o curso ao máximo.
Comentários: Andrew Ng, o instrutor deste curso, é uma lenda nos campos de Machine Learning e Inteligência Artificial. Ele é professor em Standford, um dos fundadores da Coursera e desenvolveu um dos primeiros cursos on-line de Machine Learning, que ainda está disponível no YouTube.
Como o curso se descreve:
“Este curso fornece uma ampla introdução ao Aprendizado de Máquina, Datamining e reconhecimento de padrões estatísticos. Os tópicos incluem: (i) Aprendizado supervisionado (algoritmos paramétricos / não paramétricos, máquinas de vetores de suporte, núcleos, redes neurais). (ii) Aprendizagem não supervisionada (agrupamento, redução de dimensionalidade, sistemas de recomendação, aprendizagem profunda). (iii) Boas práticas em aprendizado de máquina (teoria de viés / variância; processo de inovação em aprendizado de máquina e IA).”
Assuntos tratados:
Regressão linear (Linear regression)
Regressão logística (Logistic regression)
Regularização (Regularization)
Redes neurais (Neural Networks)
Máquinas de vetores de suporte (Support Vector Machines)
Aprendizagem não supervisionada (Unsupervised Learning)
Redução de dimensionalidade (Dimensionality Reduction)
Detecção de anomalia (Anomaly Detection)
Sistemas de recomendação (Recommendation Systems)
2. Aprendizado de máquina com Python (Machine Learning with Python)
Plataforma: Coursera
Oferecido por: IBM
Carga horária: 22h
Requisitos: conhecimento em Matemática Básica.
Comentários: apesar do curso ser classificado como de “nível intermediário” pelo Coursera, é um bom ponto de partida para alguém novo no campo. Também é uma boa opção se você estiver procurando por um curso mais curto que o anterior, de Stanford, pois possui uma carga horária bem menor.
Como o curso se descreve:
“Este curso aborda os conceitos básicos de Aprendizado de Máquina usando uma linguagem de programação acessível e conhecida, o Python. Neste curso, analisaremos dois componentes principais: Primeiro, você aprenderá sobre o objetivo do Machine Learning e onde ele é aplicado no mundo real. Segundo, você obterá uma visão geral dos tópicos do Machine Learning, como aprendizado supervisionado versus não supervisionado, avaliação de modelos e algoritmos de aprendizado de máquina.”
Assuntos tratados:
Regressão (Regression)
Classificação (Classification)
Agrupamento (Clustering)
Sistemas de recomendação (Recommendation Systems)
Cursos de nível intermediário
3. Redes Neurais e Aprendizagem Profunda (Neural Networks and Deep Learning)
Plataforma: Coursera
Oferecido por:deeplearning.ai
Carga horária: 30h
Requisitos: Experiência em codificação Python e Matemática do Ensino Médio. Conhecimentos prévios em Machine Learning e/ou em Deep Learning são úteis.
Comentários: depois de dominar os conceitos básicos do Machine Learning e se familiarizar com o Python, o próximo passo é provavelmente familiarizar-se com o TensorFlow, pois muitos algoritmos computacionalmente caros hoje em dia estão sendo executados com ele. Outro check positivo do curso é que Andrew Ng é um dos instrutores.
Como o curso se descreve:
“Neste curso, você aprenderá os fundamentos do Aprendizado Profundo. Quando você terminar esta aula, você irá:
– Entender as principais tendências tecnológicas que impulsionam o Deep Learning
– Ser capaz de construir, treinar e aplicar redes neurais profundas totalmente conectadas
– Saber como implementar redes neurais eficientes (vetorizadas)
– Entender os principais parâmetros na arquitetura de uma rede neural.”
Assuntos tratados:
Introdução à Aprendizagem Profunda (Introduction to Deep Learning)
Noções básicas sobre redes neurais (Neural Networks basics)
Requisitos: conhecimentos de TensorFlow, codificação Python e Matemática do Ensino Médio.
Comentários: curso ideal para ser feito após os cursos indicados acima.
Como o curso se descreve:
“Este curso ensinará como criar redes neurais convolucionais e aplicá-las a dados de imagem. Graças ao aprendizado profundo, a visão por computador está funcionando muito melhor do que apenas dois anos atrás, e isso está permitindo inúmeras aplicações interessantes, desde direção autônoma segura, reconhecimento facial preciso, até leitura automática de imagens radiológicas.”
Assuntos abordados:
Fundamentos de redes neurais convolucionais (Foundations of Convolutional Neural Networks)
Modelos convolucionais profundos: estudos de caso (Deep convolutional models: case studies)
Detecção de objetos (Object detection)
Aplicações especiais: Reconhecimento facial e transferência de estilo neural (Special applications: Face recognition & Neural style transfer)
Oferecido por: National Research University Higher School of Economics
Carga horária: 10 meses, se você conseguir dedicar seis horas por semana
Requisitos: o curso é projetado para aqueles que já estão na indústria, com uma sólida base em Machine Learning e Matemática.
Comentários: essa é uma especialização completa; portanto, tecnicamente, você pode pular qualquer um dos cursos indicados, se achar que não precisa ou se já cobriu esses tópicos no trabalho ou nos cursos anteriores.
Como o curso se descreve:
“Mergulhe nas técnicas modernas de IA. Você ensinará o computador a ver, desenhar, ler, conversar, jogar e resolver problemas do setor. Esta especialização fornece uma introdução ao aprendizado profundo (deep learning), aprendizado por reforço (reinforcement learning), compreensão de linguagem natural (natural language understanding), visão computacional (computer vision) e métodos bayesianos. Os principais profissionais de Aprendizado de Máquina do Kaggle e os cientistas do CERN (European Organization for Nuclear Research) compartilharão sua experiência na solução de problemas do mundo real e ajudarão você a preencher as lacunas entre teoria e prática.”
Assuntos abordados:
Introdução à Aprendizagem Profunda (Introduction to deep learning) – (32hs)
Como Ganhar um Concurso de Ciência de Dados: Aprenda com os Melhores Kagglers (How to Win a Data Science Competition: Learn from Top Kagglers) – (47hs)
Métodos Bayesianos para Aprendizado de Máquina (Bayesian Methods for Machine Learning) – (30hs)
Aprendizagem Prática de Reforço (Practical Reinforcement Learning) – (30hs)
Aprendizagem Profunda em Visão Computacional (Deep Learning in Computer Vision) – (17hs)
Processamento de Linguagem Natural (Natural Language Processing) – (32hs)
Enfrentando Grandes Desafios de Colisor de Hádrons através do Aprendizado de Máquina (Addressing Large Hadron Collider Challenges by Machine Learning) – (24 horas)
A capacidade de classificar e reconhecer certos tipos de dados vem sendo exigida em diversas aplicações modernas e, principalmente, onde o Big Data é usado para tomar todos os tipos de decisões, como no governo, na economia e na medicina. As tarefas de classificação também permitem que pesquisadores consigam lidar com a grande quantidade de dados as quais têm acesso.
Neste post, iremos explorar o que são essas tarefas de classificação, tendo como foco a classificação multi-label (multirrótulo) e como podemos lidar com esse tipo de dado. Todos os processos envolvidos serão bem detalhados ao longo do texto; na parte final da matéria vamos apresentar uma aplicação para que você possa praticar o conteúdo. Prontos? Vamos à leitura! 😉
Diferentes formas de classificar
Livrarias são em sua maioria lugares amplos, às vezes com um espaço para tomar café, e com muitos, muitos livros. Se você nunca entrou em uma, saiba que é um lugar bastante organizado, onde livros são distribuídos em várias seções, como ficção-científica, fotografia, tecnologia da informação, culinária e literatura. Já pensou em como deve ser complicado classificar todos os livros e colocá-los em suas seções correspondentes?
Não parece tão difícil porque esse tipo de problema de classificação é algo que nós fazemos naturalmente todos os dias. Classificação é simplesmente agrupar as coisas de acordo com características e atributos semelhantes. Dentro do Aprendizado de Máquina, ela não é diferente. Na verdade, a classificação faz parte de uma subárea chamada Aprendizado de Máquina Supervisionado, em que dados são agrupados com base em características predeterminadas.
Basicamente, um problema de classificação requer que os dados sejam classificados em duas ou mais classes. Se o problema possui duas classes, ele é chamado de problema de classificação binário, e se possui mais de duas classes, é chamado de problema de classificação multi-class (multiclasse). Um exemplo de um problema de classificação binário seria você escolher comprar ou não um item da livraria (1 para “livro comprado” e 0 para “livro não comprado”). Já foi citado aqui um típico problema de classificação multi-class: dizer a qual seção pertence determinado livro.
O foco deste post está em um variação da classificação multi-class: a classificação multi-label, em que um dado pode pertencer a várias classes diferentes. Por exemplo, o que fazer com um livro que trata de religião, política e ciências ao mesmo tempo?
Como lidar com dados multi-label
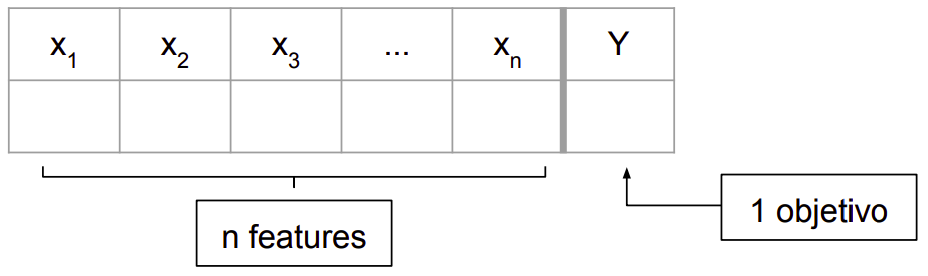
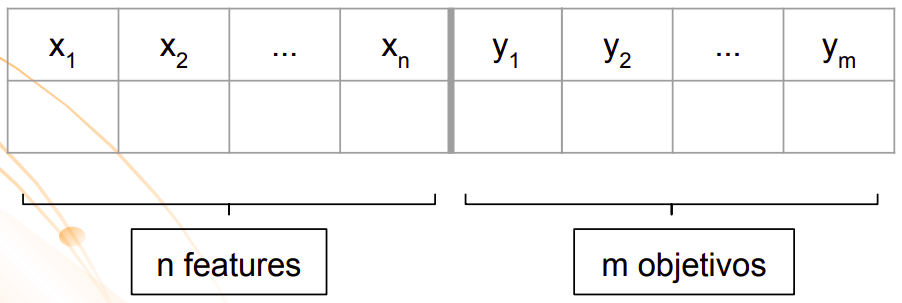
Bem, não sabemos com exatidão como as livrarias resolvem esse problema, mas sabemos que, para qualquer problema de classificação, a entrada é um conjunto de dados rotulado composto por instâncias, cada uma associada a um conjunto de labels (rótulos ou classes).
Conjunto de dados para um problema de classificação multi-class
Conjunto de dados para um problema de classificação multi-label
Para que algo seja classificado, um modelo precisa ser construído em cima de um algoritmo de classificação. Tem como garantir que o modelo seja realmente bom antes mesmo de executar ele? Sim! É por isso que os experimentos para esse tipo de problema normalmente envolvem uma primeira etapa: a divisão dos dados em treino (literalmente o que será usado para treinar o modelo) e teste (o que será usado para validar o modelo).
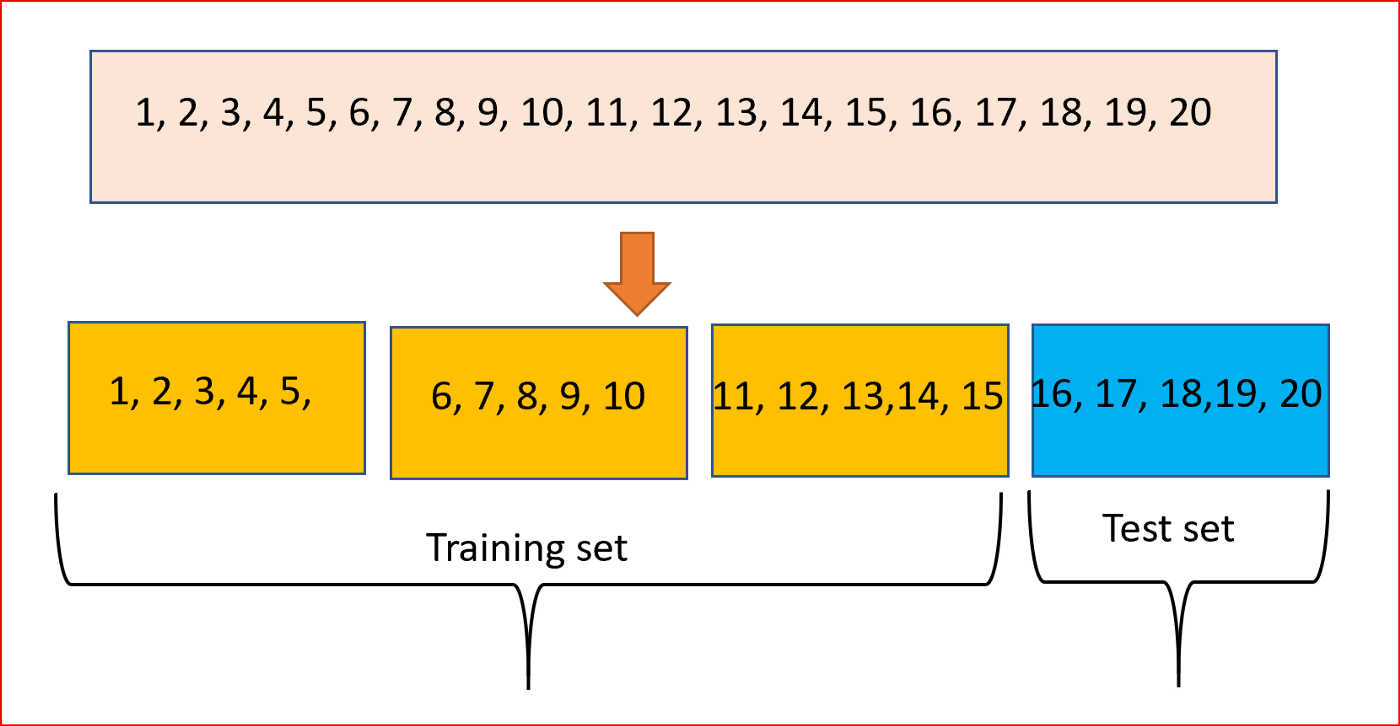
A forma como essa etapa é feita pode variar dependendo da quantidade total do conjunto de dados. Quando os dados são abundantes, utiliza-se um método chamado holdout, em que o dataset (conjunto de dados) é divididoem conjuntos de treino e teste e, às vezes, em um conjunto de validação. Caso os dados sejam limitados, a técnica utilizada para esse tipo de problema é chamada de validação cruzada (cross-validation), que começa dividindo o conjunto de dados em um número de subconjuntos de mesmo tamanho, ou aproximado.
Particionamento dos dados em 4 subconjuntos, 3 para o treino e 1 para o teste
Nas tarefas de classificação, geralmente é usada a versão estratificada desses dois métodos, que divide o conjunto de dados de forma que a proporção de cada classe nos conjuntos de treino e teste sejam aproximadamente iguais a de todo o conjunto de dados. Parece algo simples, mas os algoritmos que realizam esse procedimento o fazem de forma aleatória e não fornecem divisões balanceadas.
Além disso, essa distribuição aleatória pode levar à falta de uma classe rara (que possui poucas ocorrências) no conjunto de teste. A maneira típica como esses problemas são ignorados na literatura é através da remoção completa dessas classes. Isso, no entanto, implica que tudo bem se ignorar esse rótulo, o que raramente é verdadeiro, já que pode interferir tanto no desempenho do modelo quanto nos cálculos das métricas de avaliação.
Agora que a parte teórica foi explicada, vamos à parte prática! 🙂
Apresentação da biblioteca Scikit-multilearn
Sabia que existe uma biblioteca Python voltada apenas para problemas multi-label? Pois é, e ainda possui um nome bem sugestivo: Scikit-multilearn, tudo porque foi construída sob o conhecido ecossistema do Scikit-learn.
O Scikit-multilearn permite realizar diversas operações, mediante as implementações nativas do Python encontradas na biblioteca de métodos populares da classificação multi-label. Caso tenha curiosidade de saber tudo o que ela pode fazer, clique aqui.
A implementação da estratificação iterativa do Scikit-multilearn visa fornecer uma distribuição equilibrada das evidências das classes até uma determinada ordem. Para analisarmos o que isso significa, vamos carregar alguns dados.
Definição do problema
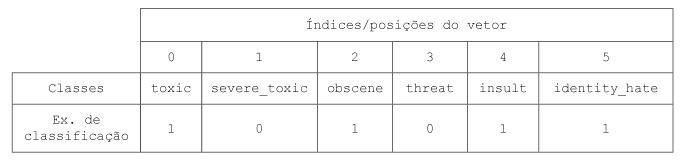
A competição Toxic Comment Classification do Kaggle se trata de um problema de classificação de texto, mais precisamente de classificação de comentários tóxicos. Os participantes devem criar um modelo multi-label capaz de detectar diferentes tipos de toxicidade nos comentários, como ameaças, obscenidade, insultos e ódio baseado em identidade.
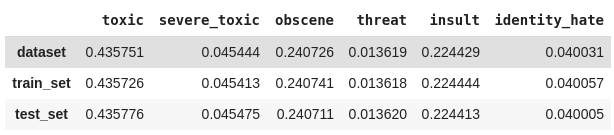
Usaremos como conjunto de dados o conjunto de treino desbalanceado disponível na competição para ilustrar o problema de estratificação de dados multi-label. Esses dados contém um grande número de comentários do Wikipédia, classificados de acordo com os seguintes rótulos:
Avisamos que os comentários desse dataset podem conter texto profano, vulgar ou ofensivo, por isso algumas imagens apresentadas aqui estão borradas. O link para baixar o arquivo train.csv pode ser acessado aqui.
Análise exploratória
Inicialmente, iremos fazer uma breve análise dos dados de modo que possamos resumir as principais características do dataset. Todos os passos até a estratificação estão exemplificados abaixo, com imagens e exemplos em código Python. Se algum código estiver omitido, então alguns trechos são bastante extensos ou se tratam de funções pré-declaradas. Pedimos que acessem o código detalhado, disponível no GitHub, para um maior entendimento.
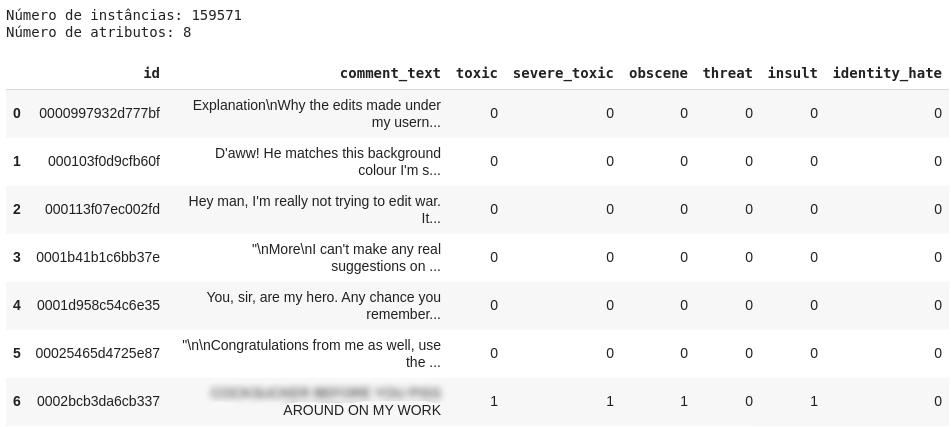
Primeiro, vamos carregar os dados do arquivo train.csv e checar os atributos.
df = pd.read_csv('train.csv')
print('Quantidade de instâncias: {}\nQuantidade de atributos: {}\n'.format(len(df), len(df.columns)))
df[0:7]
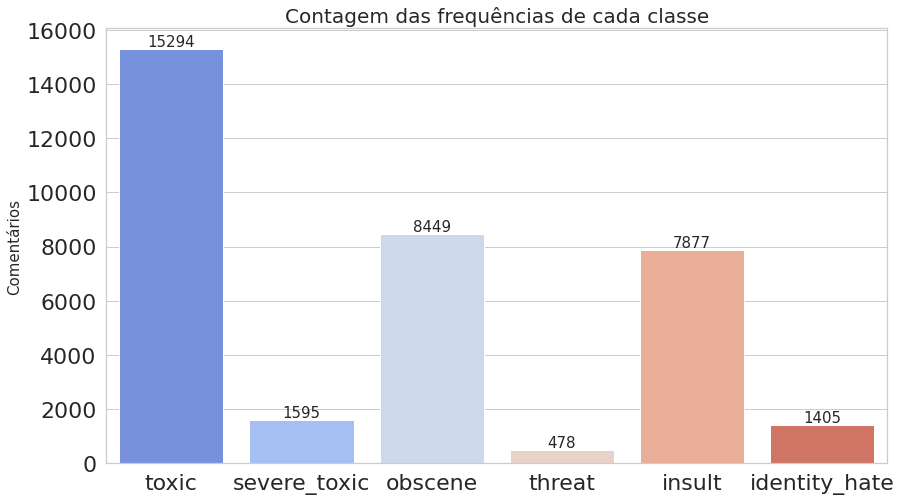
Percebe-se que cada label está representada como uma coluna, onde o valor 1 indica que o comentário possui aquela toxicidade e o valor 0 indica que não. Os 6 primeiros textos listados no dataframe não foram classificados em nenhum tipo de toxicidade. Na verdade, quase 90% desse dataset possui textos sem classificação. Não será um problema para nós, pois o método que iremos utilizar considera apenas as classificações feitas.
Agora, vamos computar as ocorrências de cada classe, ou seja, quantas vezes cada uma aparece, como também contar o número de comentários que foram classificados com uma ou mais classes. Já podemos notar na imagem acima do dataframe que o texto presente no índice 6 foi classificado como toxic, severe_toxic, obscene e insult.
labels = list(df.iloc[:, 2:].columns.values)
labels_count = df.iloc[:, 2:].sum().values
comments_count = df.iloc[:, 2:].sum(axis=1)
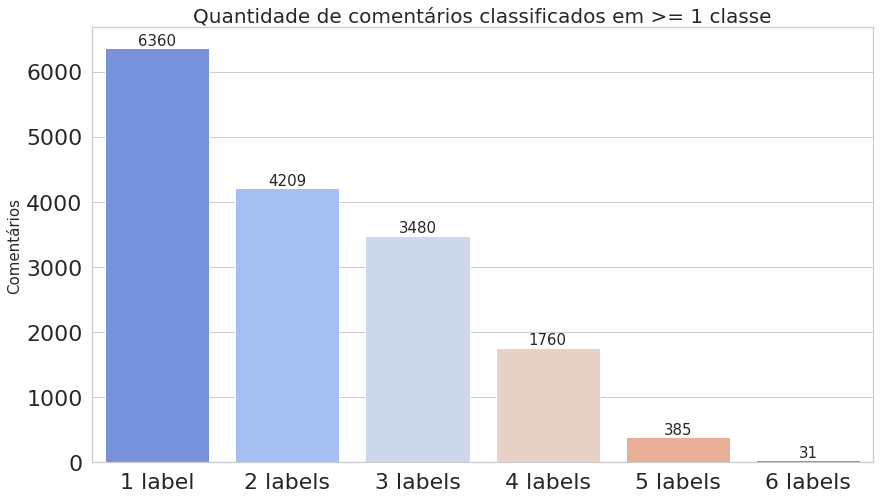
multilabel_counts = (comments_count.value_counts()).iloc[1:]
indexes = [str(i) + ' label' for i in multilabel_counts.index.sort_values()]
plot_histogram_labels(title='Contagem das frequências de cada classe', x_label=labels, y_label=labels_count, labels=labels_count)
plot_histogram_labels(title='Quantidade de comentários classificados em >= 1 classe', x_label=indexes, y_label=multilabel_counts.values, labels=multilabel_counts)
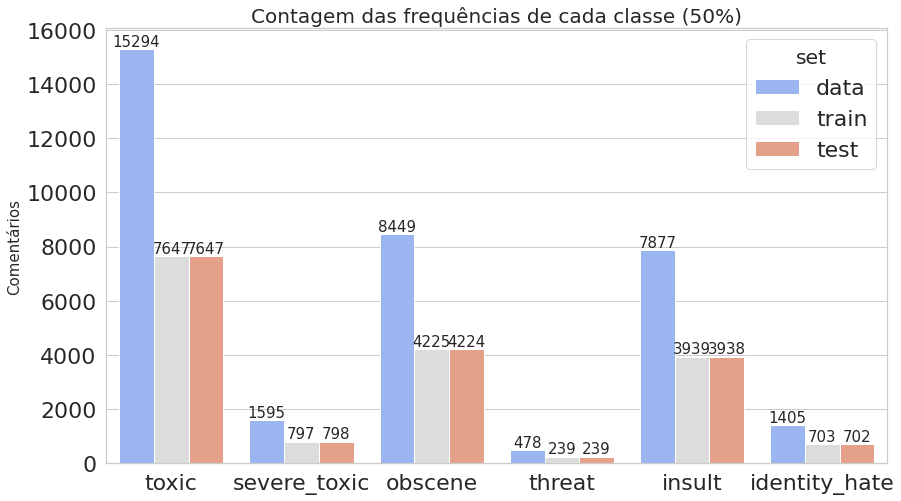
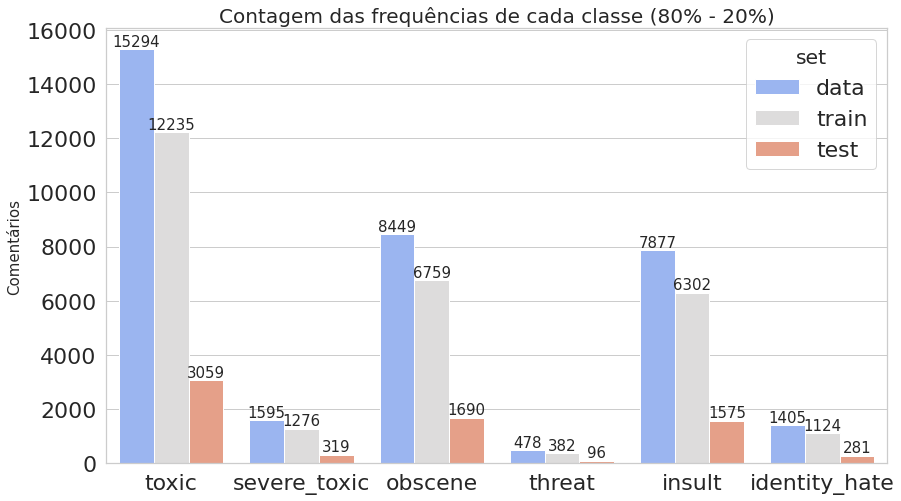
O primeiro gráfico mostra que o dataset é realmente desbalanceado, enquanto o segundo deixa claro que estamos trabalhando com dados multi-label.
Pré-processamento dos dados
O dataset não possui dados faltantes ou duplicados, e nem comentários nulos ou sem classificação (basta olhar como essa análise foi feita aqui no código completo). Apesar de não existirem problemas que podem interferir na qualidade dos dados, um pré-processamento ainda precisa ser feito, pois o intuito é seguir os mesmos passos geralmente realizados até a separação dos dados em treino e teste.
Para esse tipo de problema de classificação de texto, normalmente o pré-processamento envolve o tratamento e limpeza do texto (converter o texto apenas para letras minúsculas, remover as URLs, pontuação, números, etc.), e remoção das stopwords (conjunto de palavras comumente usadas em um determinado idioma). Devemos realizar esse tratamento para que possamos focar apenas nas palavras importantes.
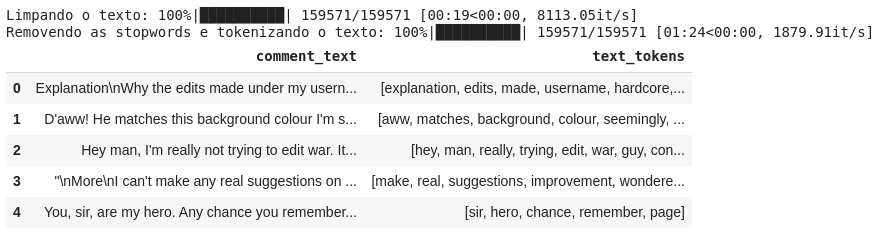
tqdm.pandas(desc='Limpando o texto')
df['text_tokens'] = df['comment_text'].progress_apply(clean_text)
tqdm.pandas(desc='Removendo as stopwords e tokenizando o texto')
df['text_tokens'] = df['text_tokens'].progress_apply(remove_stopwords)
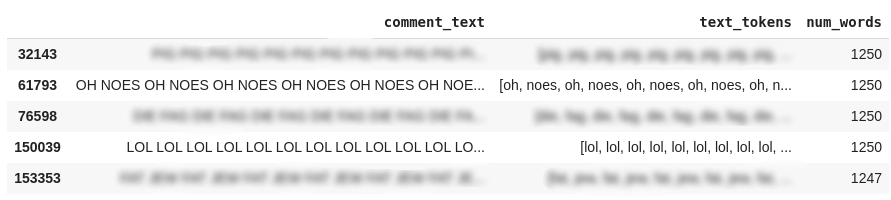
df[['comment_text', 'text_tokens']].head()
Como ilustrado na figura, também foi feito a tokenização do texto, um processo que envolve a separação de cada palavra (tokens) em blocos constituintes do texto, para depois convertê-los em vetores numéricos.
Processo de estratificação
Para divisão do conjunto de dados em conjuntos de treino e teste, usaremos o método iterative_train_test_splitda biblioteca Scikit-multilearn. Antes de prosseguir, esse método assume que possuímos as seguintes matrizes:
Devemos, então, fazer alguns tratamentos para obtermos o X e o y ideais para serem usados como entrada na função. Além disso, também passamos como parâmetro a proporção que desejamos para o teste (o restante será colocado no conjunto de treino). Esse método nos retornará a divisão estratificada do dataset(X_train, y_train, X_test, y_test).
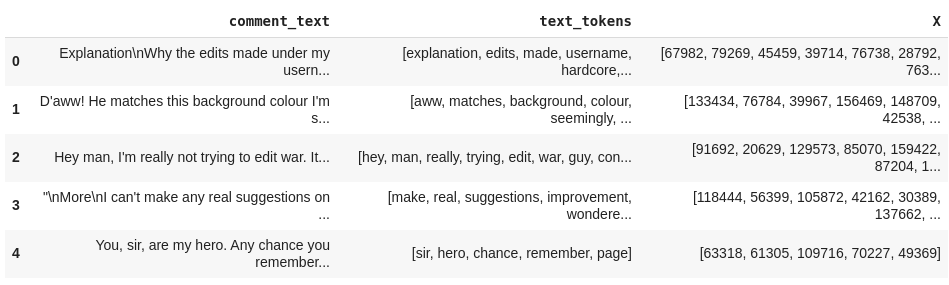
Inicialmente, iremos gerar o X. Até agora o que temos são os tokens do texto, então precisamos mapeá-los para transformá-los em números. Para isso, podemos pegar todas as palavras (tokens) presentes em text_tokens e atribuir a cada uma um id. Assim, criaremos uma espécie de vocabulário.
text_tokens = []
VOCAB = {}
for vet in df['text_tokens'].values:
text_tokens.extend(vet)
text_tokens_set = (list(set(text_tokens)))
for index, word in enumerate(text_tokens_set):
VOCAB[word] = index + 1
print('Quantidade de palavras presentes no texto: {}'.format(len(text_tokens)))
print('Tamanho do vocabulário (palavras sem repetição): {}\n'.format(len(text_tokens_set)))
VOCAB
Com esse vocabulário, conseguimos mapear as palavras para os id’s.
Como o X deve ter a dimensão (número_de_amostras, número_de_instâncias) e como o tamanho de alguns textos deve ser bem maior que de outros, temos que achar o texto com a maior quantidade de palavras e salvar seu tamanho. Depois, fazemos um padding (preenchimento) no restante dos textos, acrescentando 0’s no final de cada vetor até atingir o tamanho máximo estabelecido.
A matriz do y deve conter a dimensão (número_de_amostras, número_de_labels), então pegamos os valores das colunas referentes às classes. Atente para o fato de que cada posição dos vetores presentes em y corresponde a uma classe.
Outra forma de criação do y seria contar as ocorrências das classes para cada texto. Logo, ao invés de utilizar valores binários para indicar que existem palavras pertencentes ou não a um rótulo, colocaríamos os valores das frequências desses rótulos.
from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(maxlen=max_num_words, sequences=df['X'], value=0, padding='post', truncating='post')
y = df[labels].values
print('Dimensão do X: {}'.format(X.shape))
print('Dimensão do y: {}'.format(y.shape))
5. Pronto! Agora podemos fazer a divisão do dataset. Demonstraremos dois exemplos: dividir o dataset em 50% para treino e teste, e dividir em 80% para treino e 20% para teste.
from skmultilearn.model_selection import iterative_train_test_split
# 50% para cada
np.random.seed(42)
X_train, y_train, X_test, y_test = iterative_train_test_split(X, y, test_size=0.5)
# 80% para treino e 20% para teste
np.random.seed(42)
X_train_20, y_train_20, X_test_20, y_test_20 = iterative_train_test_split(X, y, test_size=0.2)
Os conjuntos de treino e teste estão realmente estratificados?
Por fim, iremos analisar se a proporção entre as classes foi realmente mantida.
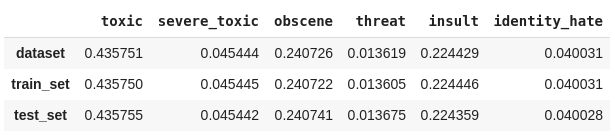
Plotamos novamente os gráficos que contam quantas vezes cada classe aparece, comparando todo o conjunto de dados com os dados de treino e teste obtidos.
plot_histogram_labels('Contagem das frequências de cada classe (50%)', x_label='labels', y_label='ocorr', labels=classif_train_test, hue_label='set', data=inform_train_test)
plot_histogram_labels('Contagem das frequências de cada classe (80% - 20%)', x_label='labels', y_label='ocorr', labels=classif_train_test_20, hue_label='set', data=inform_train_test_20)
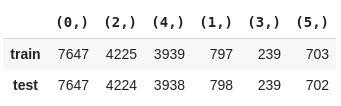
2. Podemos calcular manualmente a proporção das classes dividindo a quantidade de ocorrências de cada classe pelo número total de classificações. Também iremos verificar se a divisão está proporcional utilizando uma métricado Scikit-multilearn que retorna as combinações das classes atribuídas a cada linha.
from collections import Counter
from skmultilearn.model_selection.measures import get_combination_wise_output_matrix
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test, order=1) for combination in row)
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train_20, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test_20, order=1) for combination in row)
}).T.fillna(0.0)
É isso, gente. Esperamos que esse post tenha sido útil, principalmente para quem já enfrentou um problema parecido e não soube o que fazer.
Nem só de álcool gel e máscara consiste o kit quarentena. Hoje, vamos aproveitar a sexta-feira + quarentena para te indicar um novo livro: Learning Geospatial Analysis with Python: Understand GIS fundamentals and perform remote sensing data analysis using Python 3.7.
Dos dez capítulos, o autor, Joel Lawhead, dedica os três primeiros à ambientação dos leitores no cenário da Análise Geoespacial. Para a estruturação de desenvolvimento do tema, divide o campo em suas áreas específicas, como Sistema de Informações Geográficas (SIG), sensoriamento remoto, dados de elevação, modelagem avançada e dados em tempo real. A partir do capítulo 4, o autor inicia o aprofundamento da parte computacional, introduzindo o uso de ferramentas como NumPy, GEOS, Shapely e Python Imaging Library.
O foco do livro é fornecer uma “base sólida no uso da poderosa linguagem e estrutura Python para abordar a análise geoespacial de maneira eficaz”, como afirma o próprio autor. Para isso, Lawhead privilegia a aplicação do tema, sempre que possível, no ambiente Python. O esforço para se concentrar no Python, sem dependências, é um dos grandes diferenciais de “Learning Geospatial Analysis with Python” em relação aos outros materiais disponíveis sobre o assunto.
Veja a divisão do livro por capítulos:
1- Aprendendo sobre Análise Geoespacial com Python.
2- Aprendendo dados geoespaciais.
3- O cenário da tecnologia geoespacial.
4- Python Toolbox Geoespacial.
5- Sistema de Informações Geográficas e Python.
6- Python e Sensoriamento Remoto.
7- Python e Dados de Elevação.
8- Modelagem Geoespacial Avançada de Python.
9- Dados em tempo real.
10- Juntando tudo.
Conheça o autor*:
Joel Lawhead é um profissional de gerenciamento de projetos certificado pelo PMI, um profissional de GIS certificado e o diretor de informações da NVision Solutions Inc., uma empresa premiada especializada em integração de tecnologia geoespacial e engenharia de sensores para NASA, FEMA, NOAA, Marinha dos EUA , e muitas outras organizações comerciais e sem fins lucrativos.
*Trecho extraído de amazon.com.
Aproveita que está aqui com a gente e leia também:
12 bibliotecas do Python para análise de dados espaço-temporais (Parte 1) – (Parte 2)
Na era da informação na qual vivemos, ouve-se muito sobre o valor dos dados que geramos cotidianamente e, por consequência, sobre a demanda de profissionais criada para realizar a análise dos mesmos. Isso posto, podemos então dizer seguramente que a atuação tendência do momento é a de Cientista de Dados. Mas essa não é a única profissão com alta demanda (e boas remunerações) por aí: você já ouviu falar sobre o Engenheiro de Dados? Não? Então segue a leitura, neste post nós vamos te contar tudo sobre essa carreira, quais atividades são desempenhadas nela e quais as habilidades necessárias para se tornar um bom Engenheiro de Dados.
Mas afinal, o que é um Engenheiro de Dados?
Antes de entrarmos em uma definição é necessário termos em mente que, nos times modernos de Ciência de Dados, é cada vez mais comum encontrar papéis bem definidos a fim de facilitar todo o fluxo de trabalho na empresa. Nesses times existem pelo menos três papéis distintos:
O Engenheiro de Dados, responsável por assegurar, através de linguagens de programação, que os dados sejam limpos, confiáveis e disponíveis para acesso em alta performance sempre que necessário;
O Analista de Dados, que utiliza ferramentas de business intelligence, planilhas e linguagens de programação para categorizar e descrever os dados já existentes;
O Cientista de Dados, que faz uso dos dados para realizar predições e extração de conhecimento desses dados.
Ou seja, podemos definir o Engenheiro de Dados como a pessoa que é responsável por preparar os dados para uso analítico e operacional, gerenciando os processos de ETL (Extract, Transform, Load), pipelines de execução e o fluxo de trabalho dos dados.
Qual a atuação do Engenheiro de Dados?
Embora o Engenheiro de Dados tenha suas atribuições bem definidas, ele trabalha em conjunto com os Analistas e Cientistas de Dados. As principais atividades de um Engenheiro de Dados envolvem:
Construir e manter os sistemas de pipelines dos dados da empresa
O pipeline dos dados abrange os processos pelos quais os dados passam na empresa, definindo para onde e qual setor eles irão. O Engenheiro de Dados é responsável pela criação desses pipelines, além de mantê-los funcionando sempre da melhor forma possível. O engenheiro deve entender quais as melhores ferramentas a serem utilizadas, bem como conhecer as tecnologias e frameworks existentes, combinando-as para facilitar o processo de pipeline no negócio da empresa.
Limpar e organizar os dados de forma útil
Um Engenheiro de Dados assegura que os dados estejam limpos, organizados, confiáveis e preparados para qualquer caso de uso. A organização dos dados é uma das principais atividades do engenheiro e envolve tarefas como transformar dados bagunçados e brutos em dados realmente úteis. O engenheiro também é responsável por responder questões como: “o quão bons são esses conjuntos de dados?”, “o quão relevantes eles são para o objetivo procurado?” e “existe uma fonte de dados melhor?”, de modo que seu trabalho possa auxiliar o Cientista de Dados no processo de extração de conhecimento.
O que devo saber para me tornar um Engenheiro de Dados?
Para se tornar um Engenheiro de Dados, seu conhecimento deve abranger muitas áreas como: formatação de arquivos, processamento de dados em streaming e em batches, SQL, armazenamento de dados, gerenciamento de clusters, banco de dados transacionais, frameworks para web, visualização de dados e, até mesmo, machine learning.
Como observado, a lista de conhecimentos requeridos pode ser grande, mas você já tem um bom ponto de partida caso possua algumas dessas skills:
Conhecimentos de Linux e uso de linhas de comando;
Experiência com linguagens de programação como Java, Python e Scala;
Conhecimentos de SQL;
Entendimento de como funcionam sistemas distribuídos em geral e quais as principais diferenças em relação a armazenamentos tradicionais e sistemas de processamento;
Profundo entendimento dos ecossistemas existentes, incluindo ingestão (Kafka, Kinesis), frameworks de processamento (Spark, Flink), e engines de armazenamento (HDFS, Hbase, Kudu, etc);
Conhecimentos de como processar e acessar dados.
E é isso, caro leitor. Esperamos que este post tenha sido útil para introduzir um pouco dessa profissão tão fascinante. Caso queira ler um pouco mais a respeito, este artigo explica muito bem a diferença entre o engenheiro e o cientista de dados.
O Insight Lab está com vagas para o cargo de “Desenvolvedor(a) Full Stack”.
Nessa função você deverá:
atuar no desenvolvimento de uma plataforma integrada, de alta disponibilidade, distribuída e resiliente da segurança pública;
contribuir para a tomada de decisões de arquitetura e tecnologia;
Conhecimentos desejáveis
desenvolvimento web básico (HTML, CSS e JavaScript);
desenvolvimento web com frameworks JavaScript (React, Vue, Angular…);
desenvolvimento e consumo de APIs REST (Scala, Java, Python, Node.js …);
desenvolvimento de microserviços (Lagom, Spring Cloud, …);
bases de dados relacionais e não relacionais (PostgreSQL, MongoDB, Redis, ElasticSearch…);
padrões de projeto e clean code;
Estamos abertos à submissão de profissionais de todos os níveis. A definição do nível e salário será mediante a três etapas: entrevista, desafio técnico e negociação.
Se você possui o perfil descrito e deseja se desenvolver dentro de uma empresa altamente inovadora e com profissionais de grande reconhecimento no mercado e no meio acadêmico, envie seu currículo para jobs@insightlab.ufc.br.
*O e-mail deve conter o seguinte título: [JOB16] Desenvolvedor Full Stack.
-Para mais informações sobre esta vaga, clique aqui.
Você pode conhecer sua futura equipe de colegas aqui.
Para saber mais detalhes de nossa história e atuação no mercado, fique à vontade para navegar pelo site e acessar nossas redes sociais.
Desde o final do milênio passado, uma palavra relativamente desconhecida começou a ser propagada: “streaming”. Timidamente no início e geralmente em áreas mais técnicas, foi gradualmente emergindo até se tornar onipresente.
De plataformas de áudio (Spotify, Deezer, Apple Music, YouTube Music, Amazon Music,Tidal, entre outras) e de vídeo (Youtube, Netflix, Vimeo, DailyMotion, Twitch, entre outras) a aplicações mais específicas, o streaming passou a ser uma palavra do cotidiano dos devs.
Geralmente, o termo vem acompanhado de outro já bem conhecido: Big Data, o qual podemos entender como conjuntos de dados (dataset) tão grandes que não podem ser processados e gerenciados utilizando soluções clássicas como sistemas de banco de dados relacionais (SGBD). Podemos ter streaming de dados fora do contexto de Big Data, porém é bem comum essas palavras virem em um mesmo contexto.
Neste instante, o desenvolvedor já quer fazer um “hello world” e já pergunta: “qual o melhor framework de streaming?” (falar no melhor é quase sempre generalista e enviesado, o termo “mais adequado” é mais realista, opinião do autor). Vamos entender o que é streaming de dados e o que podemos entender como “tempo real”.
Streaming de dados
Para uma melhor concepção do que é streaming de dados, primeiro vamos entender o que é processamento de dados em batch (lote em português ou, um termo mais antigo, “batelada”).
As tarefas computacionais geralmente são chamadas de jobs e podem executar em processos ou threads. Os que podem ser executados sem a interação do usuário final ou ser agendados para execução são chamados de batch jobs. Um exemplo é um programa que lê um arquivo grande e gera um relatório.
Frameworks
Na era do Big Data, surgiram vários modelos de programação e frameworks capazes de executar jobs em batch de forma otimizada e distribuída. Um deles é o modelo de programação MapReduce que foi introduzido e utilizado inicialmente pela Google como um framework que possui três componentes principais: uma engine de execução MapReduce, um sistema de arquivo distribuído chamado Google File System (GFS) e um banco de dados NoSQL chamado BigTable.
Podemos citar vários outros frameworks que possuem capacidade de processamento de dados em larga escala, em paralelo e com tolerância a falhas como: Apache Hadoop, Apache Spark, Apache Beam e Apache Flink (falaremos mais dele adiante). Frameworks que executam processamento em batch geralmente são utilizados para ETL (Extract Transform Load).
Processamento de datasets em forma de streaming
Uma outra forma de processar datasets é em forma de streaming. Aqui, já deixamos uma dica importante: streaming não é melhor que batch, são duas formas diferentes de processar dados e cada uma delas possui suas particularidades e aplicações.
Então, sem mais delongas, o que é um processamento de dados em streaming? De acordo com o excelente (e super indicado) livro “Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing”, podemos definir streaming como “um tipo de engine de processamento de dados projetado para tratar datasets infinitos”.
A primeira coisa a se ter em mente é que os dados virão infinitamente (unbounded), diferente do processamento em batch que é finito, e não há como garantir a ordem em que os mesmos chegam. Para isso existe uma série de estratégias (ou heurísticas) que tenta mitigar tais questões e cada uma delas com seus pontos fortes e fracos. Como diz o ditado: “There is no free lunch”!
Quando tratamos de datasets, podemos falar de duas estruturas importantes: tabelas, como uma visão específica do dado em um ponto específico do tempo, como acontece nos SGBDs tradicionais, e streams, como uma visão elemento a elemento durante a evolução de um dataset ao longo do tempo.
Dois eixos de funcionamento: sources e sinks
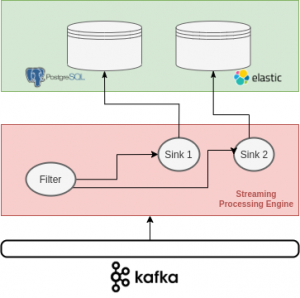
O dataset no processamento de streams funciona com duas pontas: sources e sinks. O source representa uma conexão de entrada e o sink uma de saída no seu streaming. Para clarear, podemos fazer uma analogia bem simples: pensem em uma caixa d’água que é enchida por meio de uma ligação de canos da companhia de água da sua cidade. Essa caixa d’água dá vazão para as torneiras e chuveiros da casa por meio da ligação hidráulica de sua residência. Nessa abstração, nosso dataset é a água contida na caixa d’água, nosso source é a ligação com a companhia de água e, finalmente, os sinks são as torneiras e chuveiros.
Levando agora para um exemplo real, podemos ter um sistema de streaming codificado em um framework/engine de processamento distribuído que poderia ser Apache Flink, Apache Storm, Apache Flume, Apache Samza, dentre outros, que recebe mensagens por meio da leitura de um sistema de mensageria (source) como Apache Kafka, por exemplo, processa-as em tempo real filtrando apenas aquelas que contiverem determinadas palavras-chave e envia uma saída para o Elasticsearch (sink 1) e outras para um banco de dados relacional PostgreSQL (sink 2).
O eixo temporal
Agora que já sabemos o que é um streaming de dados, vamos ao outro eixo: o temporal.
Entendemos o tempo como algo contínuo e que nunca para. Não se assustem! Aqui não iremos tratar questões físicas, como a teoria da relatividade. Nós, enquanto devs, tratamos o tempo como contínuo.
Para uma aplicação que processa streaming, cada dado que entra na nossa engine possui três abstrações de tempo: event time, ingestion time e processing time. O event time representa a hora em que cada evento individual é gerado na fonte de produção, ingestion time o tempo em que os eventos atingem o aplicativo de processamento streaming eprocessing time o tempo gasto pela máquina para executar uma operação específica no aplicativo de processamento de streaming.
Event time, ingestion time e processing time
Afinal de contas, a minha aplicação de streaming processa dados em tempo real? Aí vem a resposta que ninguém gosta de ouvir: “depende do contexto”, ou se preferir, “isso é relativo”. Vamos ao exemplo anterior da leitura de mensagens do Kafka e escrita no Elasticsearch e PostgreSQL, detalhando os tempos do processamento:
Event time
2020-01-01 01:45:55.127
Ingestion time
2020-01-01 01:45:57.122
Processing time
2020-01-01 01:45:57.912
O Ingestion time é responsável por qualquer atraso no processamento do dado e sua possível flutuação assim que o processamento “consome” a mensagem.
Quanto maior a diferença entre o tempo de geração da mensagem (event time) e o tempo que a mensagem chega a engine de streaming (ingestion time), menos “tempo real” será seu processamento. Por isso costumamos, falar em artigos científicos, em tempo “quase-real”. A diferença entre a hora da geração e a que a mensagem é processada é de 2 segundos e 784 milissegundos. Isso representa o “atraso” de apenas uma mensagem. Agora imaginem um throughput de 100 mil mensagens por segundo! Essa diferença de tempo tende a aumentar se o sistema não conseguir consumir e processar essa quantidade de mensagens à medida que chegam.
Mais uma dica de Big Data e streaming: não menospreze os milissegundos. Em grandes volumes, eles fazem muita diferença.
A ordenação dos dados
Outra questão que precisamos estar preparados é o problema que ocorre quando recebemos os dados de mais de uma fonte (source) ou a fonte de dados está com os event times fora de ordem. Se tivermos uma aplicação onde a ordem desses eventos importe, é necessário que haja uma heurística que trate dessa ordenação ou mesmo deste descarte dos dados fora de ordem. A maioria dos frameworks de streaming implementam alguma dessas heurísticas.
Um dos frameworks mais utilizados pelos devs, o Apache Flink possui o conceito de watermarks (marcas d’água). A ideia central é: quando um dado é “carimbado” com uma watermarks, a engine supõe que nenhum dado com tempo inferior (passado) irá chegar.
Como não podemos ter essa certeza, o framework espera que o desenvolvedor escolha como quer tratar esses casos: não toleramos dados com watermarks inferior à última reconhecida (atrasado) ou o framework espera um determinado tempo (10 segundos, por exemplo), ordena as mensagens e envia para processamento. O que chegar fora dessa janela de tempo será descartado. Há a possibilidade ainda de tratar esses dados que seriam descartados, mas fica fora do escopo deste post.
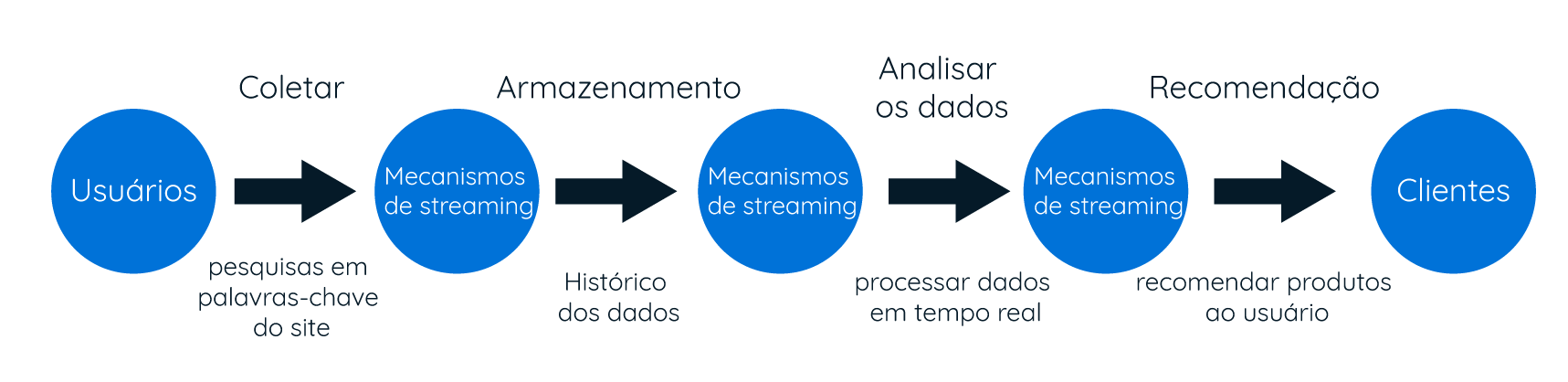
O case Alibaba
Um exemplo real da utilização de streaming de dados em tempo real em um ambiente de Big Data é o case do gigante chinês Alibaba, um grupo de empresas que possui negócios e aplicações focadas em e-commerce, incluindo pagamentos on-line, business-to-business, motor de busca e serviços de computação em nuvem.
Seus dois produtos mais conhecidos são o site de e-commerce (Alibaba.com) e os serviços em nuvem (Alibaba Cloud). O grupo lançou oficialmente em 2016 uma plataforma utilizada para busca e recomendação utilizando Apache Flink. Os mecanismos de recomendação filtram os dados dentro da plataforma de streaming utilizando algoritmos e dados históricos para recomendar os itens mais relevantes ao usuário.
Passos fundamentais para o trabalho com streaming de dados
Neste ponto, já entendemos o que é um streaming de dados e o quão tempo-real ele pode ser. Para finalizarmos, deixaremos algumas dicas para quem quer enveredar por essa área tão onipresente no mercado dev:
Entenda os conceitos de streaming de dados antes de escolher um framework e começar a codar (de novo a dica do livro: Streaming Systems). Isso envolve o conceito de sources, sinks, pipeline, agregações de tempo;
Esteja preparado para grande volumes de dados e altos throughput: isso pode parar sua aplicação por falta de recursos como espaço, memória e processamento;
Pense distribuído! A maioria dos frameworks de streaming possuem o conceito de cluster. Dessa forma, sua aplicação conseguirá escalar horizontalmente e estar preparada para grandes volumes;
Escove os bits. Essa é uma expressão bem dev. Entenda bem a linguagem e o framework que você está utilizando. Tire o máximo deles. Uma estrutura de dados inadequada ou ineficiente para o caso, um laço desnecessário, uma serialização/deserialização onde não é preciso podem minar o desempenho da sua aplicação.
Por último e não menos importante: teste de carga! Faça testes levando sua aplicação ao extremo para identificar possíveis gargalos. Isso não substitui os testes unitários e afins. A finalidade é outra: ver o quanto sua aplicação consegue processar de dados.
É isso aí, pessoal. Espero que tenha suscitado uma vontade de aprender mais sobre streaming de dados em tempo real e suas aplicações.
O 1º Hackathon promovido pelo Tribunal de Contas do Estado do Ceará aconteceu no SebraeLab, entre 24 e 26 de janeiro. O evento reuniu 33 profissionais e estudantes de diversas áreas ligadas à análise de dados, agrupados em oito equipes.
Como publicado pelo próprio TCE-CE, o desafio norteador do Hackathon foi o de “desenvolver uma solução para ler dados abertos dos diversos municípios e do governo do estado do Ceará, encontrar indícios e publicar informações, permitindo a checagem pelos cidadãos”.
Conheça as equipes, e seus temas, com melhor colocação na maratona:
Baião de dados
Centralizar dados dos portais de transparência municipais (macashare.org)
Digimon
Busca de indícios de fraudes e irregularidades em licitações municipais
A ordem de classificação de cada uma das três equipes finalistas será divulgada nesta quinta-feira (30) durante cerimônia na sede do TCE-CE. A premiação seguirá a seguinte ordem: R$ 15.000,00 para o primeiro lugar, R$ 10.000,00 para o 2º e R$ 5.000,00 para o 3º colocado.
Em muitos momentos de nossa carreira, e muito mais no início, o que mais queremos é poder conversar com profissionais presentes há mais tempo no mercado e conhecer suas experiências na área. O cientista de dados do Insight Lab, Valmiro Ribeiro, mestre em Sistemas e Computação, Inteligência Artificial e Processamento de Imagens pela UFRN, selecionou oito dicas fundamentais para quem quer se especializar na área de Ciência de Dados.
A partir daqui, a conversa é com Valmiro Ribeiro:
Uma pergunta bastante comum feita para um cientista de dados é: Como posso me tornar um cientista de dados?
Uma resposta adequada para essa pergunta deve levar em consideração vários fatores, como a área de atuação, afinidade com matemática, afinidade com modelagem de problemas, etc. Contudo, apesar de não existir uma resposta definitiva, aqui vão algumas dicas que julgo essenciais tanto para quem está começando na área quanto para aqueles que já possuem experiência.
1 – Domine a base de conhecimentos da área
É comum na área de ciência de dados que os profissionais possuam backgrounds em diferentes áreas, mas independente de qual área eles tenham vindo, todos devem dominar os conhecimentos básicos da área. Conhecimentos de Programação, Algoritmos e Estruturas de Dados, Aprendizado de Máquinas, Estatística, Probabilidade, Álgebra Linear, Raciocínio Lógico e Banco de Dados são indispensáveis.
2 – Crie um portfólio
A maneira mais fácil de provar para o mundo seus conhecimentos em Data Science é ter um bom portfólio, pois através dele você poderá demonstrar seu conhecimento prático na área. O Github é frequentemente utilizado por cientistas de dados como portfólio, onde são publicados projetos acadêmicos e pessoais, resoluções de desafios conhecidos e soluções resultantes de competições de Data Science, como Hackathons e as competições do Kaggle. Existem outras práticas comuns, mas o principal ponto sempre deve ser mostrar seus conhecimentos para o mundo.
3 – Saiba quais são seus pontos fortes, e principalmente os fracos
Como dito antes, é comum na área de Data Science que as pessoas possuam backgrounds diferentes, e isso faz com que os pontos fortes e pontos fracos de cada um sejam diferentes entre si. Um estatístico pode não ter conhecimentos vastos sobre Banco de Dados, assim como um biotecnologista pode não ser tão bom com Estatística. Dito isso, conhecer suas qualidades e defeitos como cientista de dados é primordial, pois assim você poderá trabalhar em suprimir essas fraquezas e também saberá como pode contribuir melhor nos projetos que você se envolve.
4 – Estude o domínio dos problemas
Um cientista de dados é responsável, entre outras coisas, por extrair informações, validar, descartar e criar hipóteses a respeito dos dados, e isso não é possível sem conhecer o domínio do problema que está sendo abordado. Conhecer o problema permite interpretar dados e resultados de maneira mais eficiente, melhorando todos os processos do ciclo de vida de um projeto de Data Science.
5 – Saiba se comunicar
Cientistas de Dados precisam ser bons contadores de história. Habilidades de comunicação são indispensáveis para quem deseja ingressar nessa carreira, afinal, você precisa traduzir suas descobertas para comunicá-las de forma clara para os outros envolvidos nos projetos. Aqui as competências técnicas e interpessoais andam de mãos dadas. Você deve saber utilizar ferramentas de visualização de dados de maneira efetiva, criando gráficos e tabelas que possam comunicar as suas ideias, ao mesmo tempo que você precisa saber apresentar suas ideias, problemas e resultados para pessoas diferentes.
6 – Participe de competições
Todos os pontos mencionados anteriormente se encontram aqui, pois provavelmente é participando de competições de Data Science que você terá suas primeiras experiências resolvendo problemas reais. Competições, como as do Kaggle e dos hackathons, permitem que você aplique e expanda seus conhecimentos além da teoria, incrementam seu portfólio, permitem que você estude problemas em contextos reais e requerem que você comunique seus resultados de forma clara com uma comunidade, além de permitir que você aprenda novas técnicas/ferramentas e realize uma autoavaliação no fim do processo.
7 – Faça Networking
Conhecer outras pessoas da área (ou de áreas correlacionadas) é fundamental porque te ajuda a conhecer novas ferramentas e pegar dicas com pessoas com experiências diferentes, além de ser uma boa forma de divulgar seu portfólio e compartilhar seus conhecimentos. Lembre-se que um cientista de dados dificilmente trabalhará sozinho, por isso, é importante participar de grupos de estudo, de meet-ups e de comunidades de Data Science para fazer networking.
8 – Continue aprendendo e tentando
Talvez a parte mais difícil de ingressar na área seja manter-se constantemente aprendendo e tentando coisas novas diante dos desafios. Para isso, é preciso ser resiliente e não desistir com o surgimento de novos obstáculos. Você vai começar sem entender muitas coisas, participará de competições sem obter resultados que você julgue satisfatórios, vai reprovar em seleções de emprego, mas tudo isso faz parte da jornada. O importante nessa etapa é usar essas experiências para organizar-se e cobrir seus pontos fracos e melhorar seus pontos fortes.
Creio que essas dicas tenham deixado claro que o caminho para se tornar um cientista de dados não envolve apenas competências técnicas, mas também várias habilidades interpessoais, as quais podem ser subestimadas inicialmente. Finalmente, se você tem interesse de ingressar na área e/ou aprofundar seus conhecimentos, continue acompanhando nossas matérias! Bons estudos!
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade