No dia 06 de maio, será realizado o seminário “Políticas Públicas de Enfrentamento à Violência Doméstica e Familiar Contra a Mulher e o Papel do Sistema Judiciário“, organizado pelo Grupo de Pesquisa Estado e Políticas Públicas (EPP/UFRN).
Será apresentado o cenário da violência doméstica e familiar contra a mulher, sobretudo no sistema judiciário cearense e os desafios no desenvolvimento de políticas públicas. Na oportunidade, a idealizadora do “Painel da Mulher” – Software Proteção na Medida – Tribunal de Justiça do Estado do Ceará (TJCE), Profa. Ms. Rebeca Sabóia Quezado, explanará acerca da rede protetiva voltada à conscientização e orientação sobre o tema da violência contra a mulher no contexto estudado.
Palestrantes:
Prof. Dr. José Macêdo: Cientista-chefe de Dados do Governo do Estado do Ceará e Coordenador do Insight Data Science Lab da Universidade Federal do Ceará (UFC). Profa. Ms. Rebeca Sabóia Quezado: Mestre em Direito Privado – Relações privadas, sociedade e desenvolvimento e Docente e Pesquisadora no Insight Data Science Lab da Universidade Federal do Ceará (UFC).
Público-alvo: discentes, docentes, pesquisadores, gestores e demais interessados no tema.
Data: 06/05/2022
Hora: 10h
Google Meet – Vagas limitadas (100 pessoas)
Inscrições:Via SIGAA UFRN – Caminho: SIGAA > Extensão > Eventos > Filtrar evento por departamento > Inserir “Departamento de Políticas Públicas”> Inscrever-se no evento.
O Pandas é uma das bibliotecas mais utilizadas para analisar dados em Python, além de ser uma ferramenta poderosa, flexível e confiável para muitos analistas de dados. Existem algumas funções conhecidas, bem como técnicas não tão formais que podem tornar a vida mais fácil para qualquer analista de dados, seja ele um profissional ou um entusiasta.
Neste artigo, serão discutidas algumas funções úteis e técnicas significativas, todas com exemplos. Com certeza você já usou algumas dessas funções com frequência, mas elas podem não ser tão familiares para todos. No geral, você enriquecerá suas habilidades em Análise de Dados.
No decorrer deste artigo você verá as seguintes funções:
unique e nunique
describe
sort_values
value_counts
isnull
fillna
groupby
map e seu uso para codificação categórica
apply e lambda
pivot
Vamos começar
Antes de usar as funções mencionadas acima, você pode criar um dataframe usando o dataset Kaggle Titanic, você pode baixá-lo aqui . Dessa forma, uma variedade de opções pode ser explorada. Como alternativa, qualquer conjunto de dados de código aberto pode ser usado para a prática.
1. unique e nunique
A função unique no Pandas retorna uma lista dos elementos únicos com base na ocorrência. Esta função é mais rápida do que a unique do NumPy e também inclui valores NaN. Isso é particularmente útil para verificar os diferentes valores em um campo categórico.
data['Embarked'].unique()
Saída:
array (['S', 'C', 'Q', nan], dtype = objeto)
A função Nunique, por outro lado, conta os valores distintos das colunas. Os valores NaN podem ser ignorados. Isso mostra apenas o número de categorias diferentes presentes em uma coluna de um dataframe.
data['Embarked'].nunique()
Saída: 3
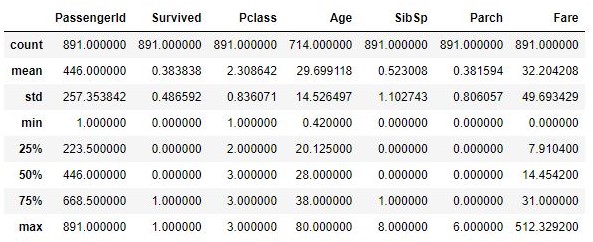
2. describe
Esta função mostra estatísticas descritivas, como média, desvio padrão, máximo, mínimo e outras tendências centrais, além da forma da distribuição. Isso exclui os valores NaN do resumo. Isso é útil para se ter uma ideia sobre a distribuição dos campos de dados e outliers, se houver. O percentil da saída pode ser personalizado mencionando a faixa de percentis no parâmetro da função.
data.describe()
data.describe()
Saída:
3. sort_values
Esta função altera a ordem dos valores em uma coluna classificando-a. Portanto, podemos usar isso para mostrar o dataset de acordo com nossa necessidade, classificando em ordem crescente ou decrescente.
Podemos definir o parâmetro “ascending” verdadeiro ou falso, que por padrão é verdadeiro. Também podemos alterar a classificação por índice ou coluna definindo o parâmetro “eixo” 0 ou 1. Além disso, podemos classificar várias colunas mencionando-as em uma lista, por exemplo:
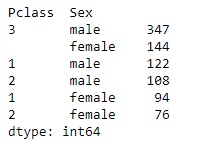
Esta função retorna o valor da contagem para cada item exclusivo presente na coluna. Os valores são exibidos em ordem decrescente para que o elemento mais frequente venha primeiro. Isso exclui os valores nulos. Aqui, veremos o número de homens e mulheres a bordo em diferentes classes, chamando a função value_counts () da seguinte maneira:
data[['Pclass','Sex']].value_counts()
Saída:
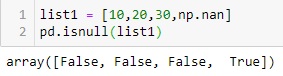
5. isnull
Esta função descobre se há algum valor ausente presente em um objeto do tipo array. Esta função retorna valores booleanos após verificar os valores ausentes. Estamos criando uma lista com um valor nulo e quando ela é passada pela função isnull (), ela dá saída com uma lista booleana.
Isso também pode ser útil quando verificamos se há valores ausentes em um grande dataframe. Podemos calcular o número total de valores ausentes de uma coluna adicionando a função sum () ao final da função isnull (). Aqui, pegamos nosso dataset e verificamos para cada coluna se há algum valor ausente e mostramos o mesmo.
#tirando cada coluna do dataframe
forcolindata.columns:
#verificando se há algum nulo na coluna
ifdata[col].isnull().sum()>0:
#se for nulo, número total de nulos nas colunas armazenadas
Esta função é usada para preencher os valores ausentes com base no método especificado. Fillna usa parâmetros como valor (um valor que é usado para preencher o valor ausente) e método (como bfill, ffill, etc). Em nosso conjunto de dados de exemplo, o campo “Idade” tem um total de 177 valores ausentes. Vamos preenchê-lo com a mediana de “Idade” usando a função fillna ().
O parâmetro “valor” de fillna () também pode ser obtido de outro groupby complexo ou dataframe ou dicionário.
7. groupby
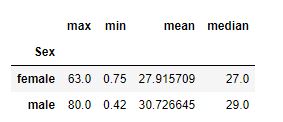
A função Pandas groupby( ) é usada para dividir os dados e ajudar a aplicação de alguma função a eles e no final combinar o resultado para outro objeto. Frequentemente precisamos dividir os dados e aplicar alguma agregação (por exemplo, soma, média, contagem, etc.) ou transformá-los (por exemplo, para preencher valores ausentes ou padronizar dados), a função groupby é útil nessas situações.
# queremos ver para cada campo de gênero máximo, mínimo, média e mediana de idade
A função map ( ) no Pandas é usada para mapear séries e substituir valores de uma série por outro valor associado a um dicionário, série ou função. Esta função é frequentemente usada para substituir valores de uma coluna de um dataframe ou uma série, mas lembre-se que todos os valores têm de ser do mesmo tipo!
Em nosso dataset, suponha que queremos converter o campo de gênero em um campo binário, ou seja, substituir “masculino” pelo valor 1 e feminino pelo valor 0. O mesmo pode ser feito facilmente da seguinte maneira:
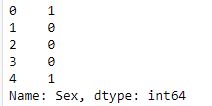
data['Sex'].head()
Saída:
#crie um dicionário para substituir os valores
gender = {'male':1, 'female':0}
#chame a função map e passe o dicionário para mapear os valores da coluna
data['Sex'].map(gender).head()
Saída:
9. apply
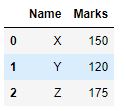
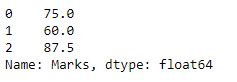
A função apply() no Pandas certamente é uma das funções mais versáteis entre todas. Nós podemos utilizar uma função apply() e ela se aplicará a todo o dataframe (ou a uma série particular). Isso ajuda a modificar os dados de acordo com a condição de uma maneira muito flexível. Vamos ver um exemplo simples, aqui temos um dataframe e uma das colunas tem marcas que queremos converter em uma porcentagem.
Aplicar função também pode ser usada com função anônima ou função lambda. Suponha que tenhamos que converter um campo contínuo como “idade” em uma coluna de faixa etária diferente ou converter um campo categórico em um campo codificado por rótulo e, em seguida, aplicar a função junto com a função lambda é muito útil nessas situações.
data['Age_bin']=data['Age'].apply(lambda x : 1 if x<=30 else
(2 if x&amp;gt;30 and x&amp;lt;=45 else</pre>
&amp;nbsp;(3 if x&amp;gt;45 and x&amp;lt;=60 else 4)))
A coluna Age_bin será criada da seguinte forma
10. pivot
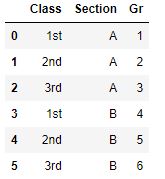
A função pivot remodela o dataset por valores de índice ou coluna. Essa função é basicamente semelhante à tabela dinâmica. Ele usa o valor exclusivo de uma coluna para formar um índice de um dataset. Ao contrário da função groupby, o pivot não oferece suporte à agregação de dados. Veja exemplo abaixo:
Esperamos que estas funções contribuam ainda mais na sua Análise de Dados, especialmente para você que está iniciando no mundo do Python e Pandas. Acompanhe o nosso blog para saber sempre mais!
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade