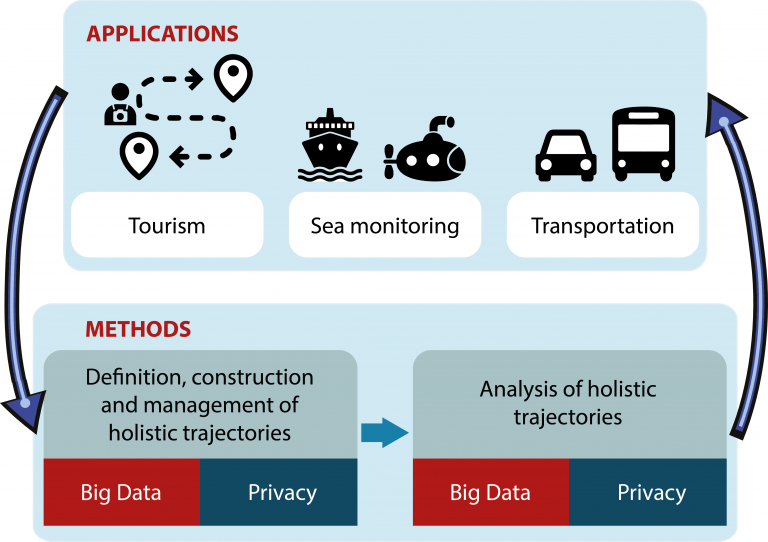

A Ciência de Dados continua em expansão acelerada, conectando profissionais e pesquisadores de diversas áreas. Em 2025, o Brasil será palco de eventos relevantes que abordam tanto a evolução tecnológica quanto os desafios enfrentados por setores específicos. Confira a lista com sete eventos que prometem movimentar o cenário da ciência de dados e áreas correlatas.
![]()

Oil & Gas Summit – Margem Equatorial e Transição Energética
- Local: Fortaleza – Ceará
- Data: 19 a 21 de março
A 1ª edição do Oil & Gas Summit: Margem Equatorial e Transição Energética será realizada no Centro de Eventos do Ceará, Fortaleza-CE, e terá como parceiros e apoiadores a Universidade Federal do Ceará (UFC), a Secretaria do Desenvolvimento Econômico do Governo do Estado do Ceará, a Assembleia Legislativa do Estado do Ceará (ALECE), o Sindi Energia Ceará e o Insight Data Science Lab.
Com a previsão de atrair mais de 50 mil visitantes, o Oil & Gas Summit será um ponto de convergência entre o setor público e privado, pois reunirá líderes, especialistas e stakeholders do mercado e acadêmicos para debater a integração do Norte e Nordeste ao setor de petróleo, gás e energias renováveis.
Ao longo dos três dias do evento, os especialistas convidados vão explorar por meio de painéis, exposições e palestras o potencial dessas regiões em se tornarem centros estratégicos de desenvolvimento industrial. O debate incluirá temas como geração de empregos, diversificação da matriz energética e a exploração de fontes como energia solar, eólica e o Hidrogênio Verde (H2V).
O Oil & Gas Summit será um dos eventos mais importantes de 2025 para pesquisadores e estudantes de ciência de dados, já que se concentra na interseção entre tecnologia e sustentabilidade. O summit irá explorar como a ciência de dados e as tecnologias emergentes estão contribuindo para o desenvolvimento de formas de exploração mais seguras e eficientes de recursos naturais, enquanto aborda os desafios da transição energética. Com especialistas discutindo desde a previsão de demanda energética até a análise de dados geofísicos, o evento unirá indústria e a pesquisa acadêmica.


Simpósio Brasileiro de Banco de Dados –
SBBD 2025
- Local: Fortaleza – Ceará
- Data: Outubro de 2025
O Simpósio Brasileiro de Banco de Dados (SBBD) é a maior conferência da América Latina em Big Data, Engenharia de Dados e Ciência de Dados, promovida pela Sociedade Brasileira de Computação desde 1986. O evento reúne estudantes, pesquisadores e profissionais para debater avanços científicos e soluções inovadoras relacionadas ao manuseio e à análise de dados, com foco em aplicações como modelos de Inteligência Artificial.
Entre os destaques do SBBD estão:
- Apresentação de pesquisas em sessões técnico-científicas que fomentam avanços em ciência básica e aplicada.
- Concurso de Teses e Dissertações que premia trabalhos de excelência de estudantes de mestrado e doutorado.
- Workshops para discussão de projetos de pós-graduação em andamento com especialistas.
- Demonstração de protótipos, onde estudantes exibem softwares inovadores.
- Participação de pesquisadores internacionais, promovendo parcerias e projetos colaborativos.
A 39ª edição do SBBD aconteceu em outubro de 2024, na cidade de Florianópolis-SC. Agora, em outubro de 2025, a conferência chegará a Fortaleza-CE, sob a coordenação de pesquisadores da Universidade Federal do Ceará (UFC) e do Insight Lab, trazendo intensos debates sobre os avanços mais recentes em Ciência de Dados, Big Data e Inteligência Artificial, além de fortalecer conexões entre academia, indústria e governo.


Hack4Dev 2025: Ciência de Dados e Pesquisa Espacial
- Local: Rio de Janeiro – Rio de Janeiro
- Data: 17 a 20 de março de 2025
De 17 a 20 de março de 2025, o Hack4Dev reunirá mentes brilhantes para uma experiência imersiva de ciência de dados aplicada à pesquisa espacial. O evento, sediado no Centro Brasileiro de Pesquisas Físicas (CBPF), é organizado pelo Laboratório de Inteligência Artificial na Física (LAB-IA) e pelo professor Clécio De Bom, em parceria com o Observatório Nacional (ON) e a Universidade Federal do Rio de Janeiro (UFRJ).
Voltado para estudantes de graduação em fase final e profissionais recém-formados com experiência em programação Python, o Hack4Dev oferece uma oportunidade única de trabalhar em soluções inovadoras utilizando aprendizado de máquina para problemas associados aos CubeSats. Esses pequenos satélites têm um papel crescente em pesquisas tecnológicas e científicas e estão no centro dos desafios propostos no hackathon.
Durante os três dias de atividades intensas, os participantes serão desafiados a desenvolver soluções tecnológicas que envolvam análise de dados e modelos preditivos, promovendo a integração de ciência de dados e tecnologia espacial. O evento também incluirá uma competição dinâmica: as melhores equipes em cada hackathon regional serão premiadas, enquanto o projeto de maior destaque nacional receberá o prestigiado Grande Prêmio Hack4Dev 2025.
As inscrições estão abertas até a primeira semana de fevereiro e os interessados passarão por um processo seletivo que avaliará competências técnicas, motivação e disponibilidade para participação presencial. Para quem busca aliar criatividade, conhecimento técnico e paixão por inovação, o Hack4Dev é uma oportunidade imperdível de explorar o impacto da ciência de dados no futuro da pesquisa espacial.


Workshop de Informação, Dados e Tecnologia (WIDaT)
- Local: Marília – São Paulo
- Data: 27 a 29 de maio de 2025
O Workshop de Informação, Dados e Tecnologia (WIDaT) é um evento de destaque no Brasil que conecta academia, indústria e sociedade para explorar as tendências e desafios na gestão de informações, análise de dados e tecnologias emergentes. Focado na inovação e colaboração, o WIDaT atrai pesquisadores, profissionais e estudantes interessados em áreas como Ciência de Dados, Engenharia de Software, Tecnologias da Informação e Inteligência Artificial.
O evento oferece uma programação rica, com palestras de especialistas renomados, apresentações de trabalhos científicos e sessões interativas, como painéis de discussão e workshops práticos. É uma excelente oportunidade para compartilhar experiências, conhecer avanços tecnológicos e estabelecer conexões valiosas com profissionais do setor.
Em 2025, o WIDaT reforça seu compromisso com a disseminação do conhecimento e o desenvolvimento de soluções inovadoras, sendo imperdível para quem deseja se atualizar nas áreas de dados e tecnologia no Brasil.
![]()

Simpósio Brasileiro de Sistemas de Informação (SBSI)
- Local: Recife, Pernambuco
- Data: 19 a 23 de maio de 2025
Entre os dias 19 e 23 de maio de 2025, Recife-PE será palco da 21ª edição do Simpósio Brasileiro de Sistemas de Informação (SBSI), promovido pela Sociedade Brasileira de Computação (SBC). Com organização da Universidade Federal Rural de Pernambuco (UFRPE) e do Centro de Estudos Avançados do Recife (C.E.S.A.R), o evento abordará o tema “Inovação com Equidade, Diversidade e Inclusão em Sistemas de Informação”.
Nesta edição, o SBSI destaca a relevância de incorporar princípios de Equidade, Diversidade e Inclusão (EDI) no desenvolvimento e na aplicação de sistemas de informação. Mais do que apenas avançar tecnologicamente, o evento busca promover debates e soluções que assegurem que as inovações sejam acessíveis, justas e benéficas para todos, considerando diferentes contextos sociais, culturais e econômicos.
O simpósio oferecerá um espaço para a troca de conhecimentos entre pesquisadores, profissionais, empresas e estudantes, com uma programação diversificada que incluirá apresentações de artigos científicos, painéis de discussão, palestras de especialistas, minicursos e pitches de projetos inovadores. Esses momentos serão oportunidades para explorar como os sistemas de informação podem transformar a sociedade de maneira inclusiva e igualitária.


Congresso da Sociedade Brasileira de Computação (CSBC)
- Local: Maceió – Alagoas
- Data: 20 a 24 de julho de 2025
De 21 a 25 de julho de 2025, a cidade de Maceió-AL será sede da 45ª edição do Congresso da Sociedade Brasileira de Computação (CSBC), o maior evento de Ciência da Computação da América Latina. Realizado desde 1978, o CSBC é um ponto de encontro para cientistas, engenheiros, pesquisadores, estudantes, empresas e empreendedores, consolidando-se como um dos principais fóruns de discussão sobre avanços tecnológicos e desafios futuros da área.
Com o tema central “Governança Digital para uma Sociedade Sustentável”, a edição de 2025 propõe uma reflexão sobre o papel da tecnologia na construção de um futuro mais sustentável. Entre os tópicos em destaque estão a transparência na gestão de dados e informações, a participação cidadã em decisões estratégicas e a inovação em serviços públicos e privados, com foco em práticas que promovam o equilíbrio entre desenvolvimento tecnológico e responsabilidade ambiental.
Além de palestras, painéis e apresentações de trabalhos científicos, o CSBC 2025 oferecerá uma rica programação cultural, integrando o conhecimento técnico à celebração da cultura e das belezas naturais de Alagoas. O evento será uma oportunidade para conectar-se com os principais nomes da computação no Brasil e explorar novas perspectivas sobre como a tecnologia pode impulsionar mudanças positivas em nossa sociedade.
Saiba o que está acontecendo! Continue acompanhando o Insight Lab para mais atualizações sobre a área e eventos imperdíveis!