O Insight Lab é formado por um time multidisciplinar de pesquisadores que vão desde de alunos de graduação a especialistas. Com o propósito de desenvolver pesquisas na área de Data Science, que possam beneficiar a outros pesquisadores e a sociedade em geral, nossos pesquisadores estão sempre atentos às necessidades que as mudanças e as novas tecnologias proporcionam.
Observamos com isso, por exemplo, que o crescente uso de sensores GPS e barateamento de tecnologias móveis, nos últimos anos, têm gerado um grande volume de dados de trajetórias. Esses dados podem trazer respostas para facilitar diversas atividades que impactam diretamente na vida das pessoas. Pensando nisso, o quê um Cientista de Dados pode fazer a partir daí?
O que é uma trajetória?
Bem, antes de tudo é muito importante entendermos o que é uma trajetória. Uma trajetória é uma sequência de pontos cronologicamente ordenados, que representam o movimento de um objeto em um espaço geográfico. Cada ponto é formado por uma marcação de tempo e coordenadas geoespaciais (latitude,longitude). As trajetórias podem representar movimentos de diferentes objetos, como:pessoas, veículos e animais.
O que podemos fazer com os dados de trajetória?
Esse tipo de dado é muito valioso não só para a Computação, mas também para áreas como Geografia, Sociologia e Urbanização, sendo bastantes utilizados para aplicações como: sistemas de transporte inteligentes e computação urbana; análise de mobilidade sustentável; no rastreamento de fenômenos naturais e identificação de padrões de migração animal e etc.
Como trabalhar com esse dado?
Para que seja possível extrair informações dos dados e realizar análises consistentes dos mesmos, é preciso que um conjunto de atividades de mineração de dados, que veremos em mais detalhes a seguir, sejam executadas. Embora haja um grande volume de trabalhos e aplicações, nota-se a ausência de softwares e ferramentas que possam auxiliar pesquisadores em todo o processo para lidar e extrair as informações que esses dados possam oferecer.
Com isso, nós do Insight Data Science Lab estamos trabalhando para a elaboração de uma biblioteca open-source para Python que contemple o conjunto de etapas e atividades para lidar com esses dados: o PyMove!
O que é o PyMove?
O PyMove surgiu em meados de 2018 com o objetivo de ser uma biblioteca Python extensível que comporte um grande número de operações dentro das etapas de mineração de dados de trajetória!
O PyMove propõe :
- Uma sintaxe familiar e semelhante ao Pandas;
- Documentação clara;
- Extensibilidade, já que você pode implementar sua estrutura de dados principal manipulando outras estruturas de dados, como o Dask DataFrame, matrizes numpy, etc., além de adicionar novos módulos;
- Flexibilidade, pois o usuário pode alternar entre diferentes estruturas de dados;
- Operações para pré-processamento de dados, mineração de padrões e visualização de dados.
Modelagem do Pymove
Estrutura de dados
A atual estrutura do PyMove é fortemente influenciada pelo trabalho de Yu Zheng, o qual propõe um paradigma que serve como um guia para realizar trabalhos de mineração de dados de trajetória. A figura 2.1.1 mostra a versão adaptada desse paradigma adotada no PyMove.

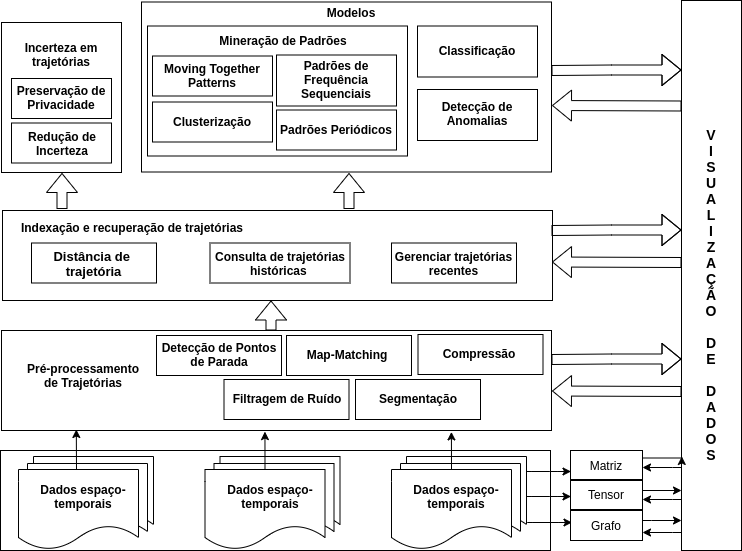
A seguir, iremos destrinchar cada etapa citada na figura 2.1.1.
Pré-processamento
O pré-processamento de dados é uma etapa de extrema importância na mineração dos dados. Nela são realizadas atividades com o objetivo de melhorar a qualidade do dados para obtenção de melhores resultados em processamentos e análises futuras. Existem quatro técnicas básicas para esta etapa: filtragem de ruído, detecção de pontos de parada, compressão e segmentação de trajetória.
Filtragem de ruído
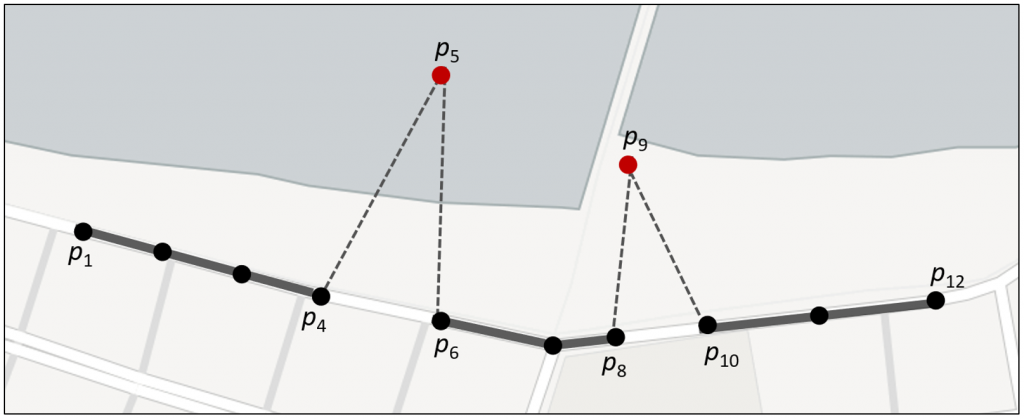
Alguns pontos da trajetória podem estar inconsistentes devido a problemas nos dispositivos de coleta de dados, na comunicação, ou em outros fatores externos, tais pontos são denominados ruídos. As técnicas de filtragem de ruído procuram realizar a remoção ou alinhamento desses dados ruidosos com a rede de ruas. Os pontos p5 e p9 na Figura 3.1 são, neste contexto, dados com ruído.

Detecção de pontos de parada
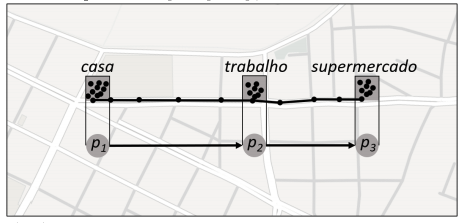
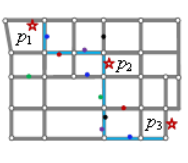
Pontos onde os objetos ficaram parados ou se movimentando ao redor, por um determinado limite de tempo, são chamados pontos de parada. Estes pontos podem representar: shoppings, atrações turísticas, postos de gasolina, restaurantes, entre outros. Os pontos de parada nos permitem representar uma trajetória como uma sequência de pontos com significado.
A figura 3.2 mostra uma trajetória, após a execução de um algoritmo, para detectar pontos de parada onde são encontrados três pontos de parada: casa, trabalho e supermercado. Esses pontos podem representar essa trajetória, como pontos p1, p2 e p3, respectivamente.
Compressão
Tem como objetivo reduzir o tamanho dos dados de trajetória através de um conjunto de técnicas, com o objetivo de evitar sobrecarga de processamento e minimizar a carga no armazenamento de dados, gerando uma representação mais compactada que descreve a trajetória de um objeto.

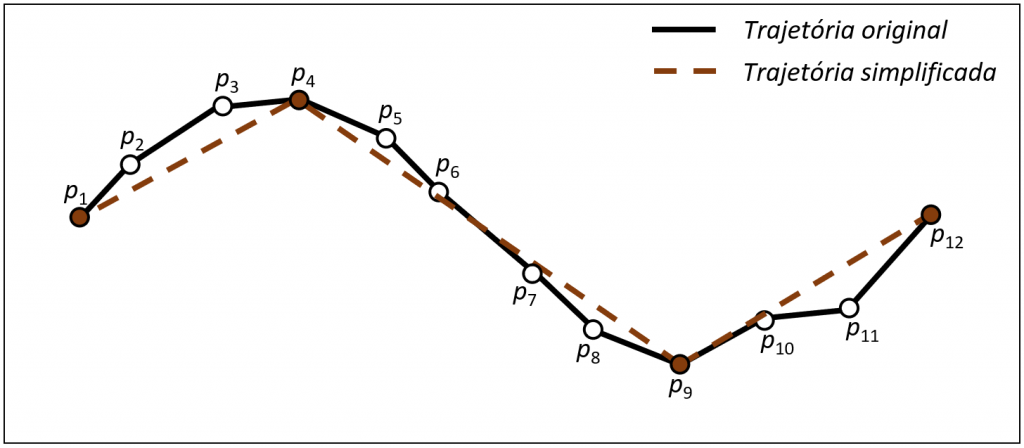
Na Figura 3.3 podemos ver o resultado da compressão de uma trajetória, inicialmente ela é representada por doze pontos, mas após a compressão este número é reduzido para quatro pontos.

Segmentação
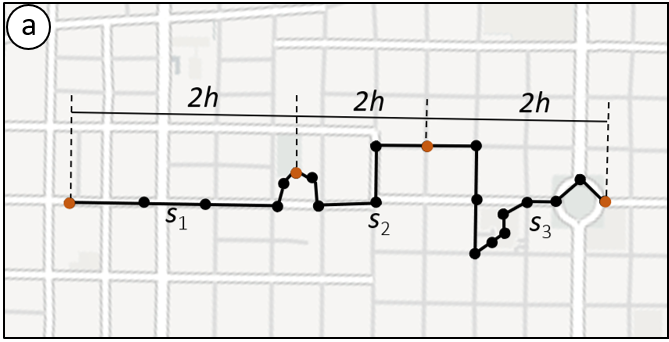
Nesta etapa, a trajetória é subdividida em segmentos, de tal forma que os dados pertencentes ao mesmo segmento tenham comportamento homogêneo. A segmentação ajuda a descobrir padrões sobre os dados, diminui a complexidade computacional e é um passo obrigatório para processos de análise, como a clusterização e a classificação. A Figura 3.4 apresenta um exemplo de segmentação de trajetória pelo tempo fixo de duas horas, resultando em três novos segmentos.

Map-matching
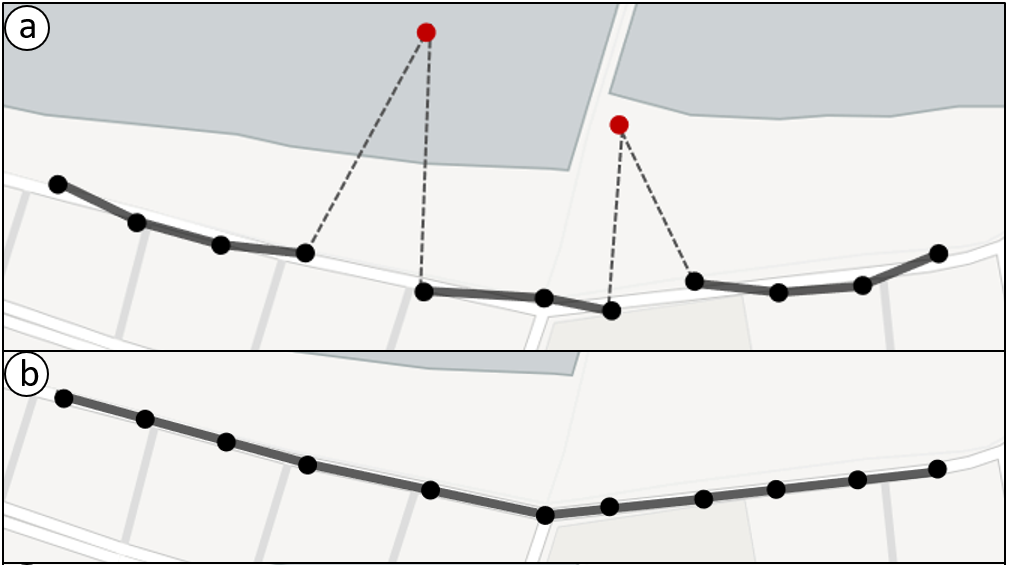
Como foi mencionado acima, os pontos gerados em uma trajetória podem não corresponder precisamente à real localização de onde o objeto em movimento passou, (figura 3.5-a).
Esta falta de precisão não é desejável para alguns tipos de aplicações, entre elas: as que trabalham com análise de fluxo de trânsito ou serviços de navegação (ZHENG,2015). Para resolver esses e outros problemas, são aplicados algoritmos de map-matching, que têm como objetivo alinhar os pontos da trajetória com a rede de ruas, (figura 3.5-b).

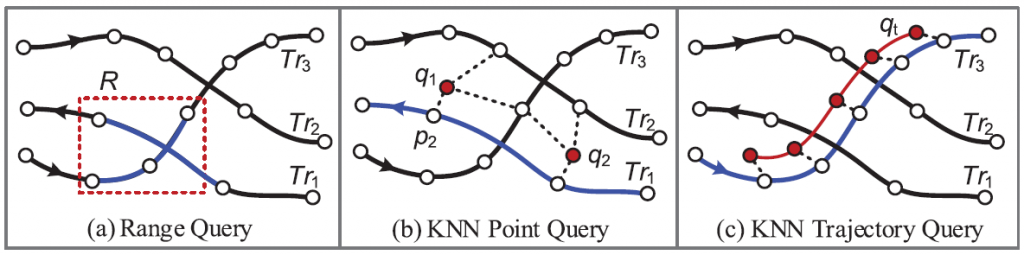
Indexação e recuperação de trajetórias
Durante o processo de mineração de dados de trajetórias, acabamos por precisar acessar frequentemente diferentes segmentos e amostras das trajetórias. Com o grande volume de dados, esses acessos podem demandar tempo e processamento. Por isso, é necessário a adoção de técnicas eficazes para o gerenciamento desses dados, oferecendo a recuperação rápida dos dados.
Os dois principais tipos de consultas, mostrado na Figura 2.1.1 – Um paradigma para mineração de trajetória.
- KNN: esse tipo de consulta recupera as K, primeiras trajetórias com a distância agregada mínima, para alguns pontos ou uma trajetória específica.
Nas consultas de pontos buscamos por trajetórias que possuam uma boa conexão com os locais/pontos pesquisados, em vez de saber se a trajetória é semelhante à consulta em forma.
Nas consulta por trajetória buscamos encontrar os registros que possuam uma rota ou segmento de trajetória parecida. Essa consulta necessita da definição de uma função que delimite a similaridade e distância entre trajetórias.
- Intervalo de consultas: recuperam os dados de trajetórias que estão contidos em um espaço ou intervalo. Essa técnica contém três abordagens para consultas de intervalo espaço-temporal.
- A primeira abordagem considera o tempo como a terceira dimensão além das informações que delimitam o espaço geográfico.
- A segunda abordagem divide um período em vários intervalos de tempo, criando um índice espacial individual.
- A terceira abordagem leva em consideração o espaço geográfico, dividindo-o em grades, as chamadas grids, e cria um índice temporal para as trajetórias que caem em cada célula dessa grade. Cada segmento que cai em uma grade é representado por um ponto com as coordenadas iguais ao ponto com horário inicial e o ponto com horário final do segmento.
A Figura 4 mostra as técnicas para melhoria da indexação e recuperação de dados e segmentos de trajetórias. Em (a) é mostrada a técnica de Intervalo de consulta. Nela são recuperados os pontos e segmentos de trajetórias dentro da região retangular tracejada em vermelho. Já em (b) e (c) são mostradas o uso da técnica de consulta via KNN, sendo a primeira consultas por pontos e a segunda consulta por segmentos de trajetórias similares.

Modelos
Muitas aplicações exigem informações instantâneas a partir dos dados de trajetória, como é o caso de aplicações de guia de viagens ou detecção de anomalias de tráfego. Essas informações exigem algoritmos eficazes e muitas vezes são adquiridas por meio de técnicas de mineração de dados. Essas técnicas podem ser enquadradas em áreas, como classificação, detecção de anomalias, mineração de padrões e incertezas da trajetória. Abaixo é explorado o conceito de cada uma dessas técnicas.
Classificação
Trajetórias e segmentos podem ser classificados de diferentes modos e em diferentes categorias, como em: tipo de atividade, modos de transporte e até mesmo o movimento, através do uso de técnicas e algoritmos de aprendizado supervisionado.
Em geral, a classificação da trajetória é composta por três etapas principais:
- Utilização de métodos de segmentação da trajetória para prover segmentos;
- Extração de características de cada segmento;
- Criação de modelos para classificar cada segmento.
Detecção de anomalias
Anomalias, no contexto de dados espaço temporais, consistem em pontos ou até mesmo segmentos de uma trajetória que possuem um comportamento anormal. Não segue o padrão dos dados que representam uma trajetória, como é o caso dos pontos destacados em vermelho na Figura 3.1. Essas anomalias podem ser desencadeados por diversos eventos como: um acidente de trânsito, que obriga os carros a mudarem rapidamente de velocidade, um desvio de uma rota comum por conta de uma obra ou por estar perdido no caminho. A etapa de detecção de anomalias, se preocupa em encontrar esses pontos e/ou segmentos que violem um certo padrão de uma trajetória.
Mineração de padrões
Diferentes padrões de mobilidade podem ser identificados numa trajetória individual ou em um conjunto de trajetórias. Os padrões de mobilidade de trajetória em quatro categorias: Clusterização de trajetórias, Moving Together Patterns, , Padrões Periódicos e Padrões de Frequências Sequenciais.
- Clusterização: as técnicas dessa categoria têm como finalidade agrupar trajetórias em busca de algum padrão ou característica que diferenciem grupos.
- Moving Together Patterns: essa categoria reúne técnicas que procuram detectar indivíduos e/ou objetos que se movem juntos por determinado período de tempo, sendo bastante útil para detectar padrões. Esses padrões podem ter diversas aplicações, como ajudar a entender fenômenos de migração e tráfego de espécies.
- Padrões Periódicos: reúne técnicas que procuram identificar comportamentos e padrões temporais em trajetórias, como a ida a um dentista durante um intervalo de tempo, ou até mesmo os animais, que migram anualmente de um lugar a outro. A análise deste tipo de padrão auxilia na previsão de comportamentos futuros do objeto e na compressão de dados.
- Padrões de Frequências Sequenciais: reúne técnicas que possuem a finalidade de encontrar padrões onde objetos partilhem a mesma sequência de localização, num período similar de tempo. Os pontos da sequência não necessariamente precisam ser pontos consecutivos na trajetória original. Essas técnicas são amplamente utilizados em aplicações como recomendação de trajetória, predição de localização, compressão de dados.
Incerteza em trajetórias
Indivíduos e objetos realizam movimentos contínuos em determinados locais em que trafegam. Porém, devido à limitação de algumas aplicações ou por questão de economia de energia dos sensores, os dados que representam essa trajetória são enviados periodicamente. Desse modo, a localização desse indivíduo e/ou objeto será incerta, ou até mesmo desconhecida, entre dois pontos que descrevem sua trajetória.
Na Figura 6 é perceptível que entre dois pontos é possível tomar caminhos diferentes, por exemplo: partindo do ponto p1 é possível chegar ao ponto p2 de diferentes formas. Este contexto ocasiona a incerteza dos caminhos tomados entre pontos de uma trajetória.
Nessa linha de pesquisa, há duas sub-áreas, descritas a seguir:
- Redução de incertezas: consiste em desenvolver técnicas que visam diminuir a incerteza da trajetória entre dois pontos.
- Preservação de privacidade: consiste em desenvolver técnicas que visam ampliar a incerteza de trajetórias sem afetar a qualidade de um serviço ou o uso desses dados, visando proteger um usuário do vazamento de privacidade causado pela divulgação de suas trajetórias.

Visualização de trajetórias
A aplicação de técnicas de visualização de dados nos grandes volumes de dados de trajetórias podem facilitar a compreensão do comportamento de objetos em movimento, como veículos e descoberta de tráfego, social, geoespacial e até padrões econômicos. Essas visualizações podem ser combinadas com procedimentos de processamento dos dados, visando diminuir, limpar e filtrar os dados.
Para visualizar dados de trajetória são necessárias técnicas que exploram canais visuais como cor, tamanho, forma, orientação aplicadas a diferentes marcas como pontos, linhas, áreas, volumes e superfícies para representar estes dados, transformando-os em representações visuais apropriadas.
Há diferentes técnicas de visualização a serem aplicadas como:
- Gráfico de Linhas: visualizações orientadas ao tempo enfatiza a exibição de padrões, periodicidade, tendências e anormalidade dos dados de trajetória. Nesse tipo de representação é amplamente utilizado gráfico de linhas, onde o eixo X delimita o tempo e o Y outra característica do dado, como os picos de velocidade de uma trajetória.
- Mapa estáticos: são abordagens bastante comuns para representar informações de localização geográfica, como a análise de trajetórias de mobilidade ou fluxo de tráfego em uma rede distribuída. Convencionalmente, uma trajetória é representada por uma linha ou uma curva, podendo explorar combinações de variáveis, como cor, tamanho e direção, em relação às suas propriedades.
- Clusters: Quando há uma grande massa de dados de trajetória, pode haver sobreposição de pontos em uma visualização. Com isso as visualizações com clusters em mapas ajudam bastante em análises, visto que um grupo de pontos que em determinado momento se sobrepunham, tornam-se um só. Essa técnica permite obter uma visão geral rápida de seus conjuntos de clusters.


- Mapas de Calor: Essa visualização é gerada a partir de uma matriz de células, onde cada célula é colorida de forma gradiente com base em valores ou função dos dados, sendo bastante útil quando é necessário gerar visualizações para grande volume de dados, fornecendo uma visão geral dos maiores e menores valores dos dados.

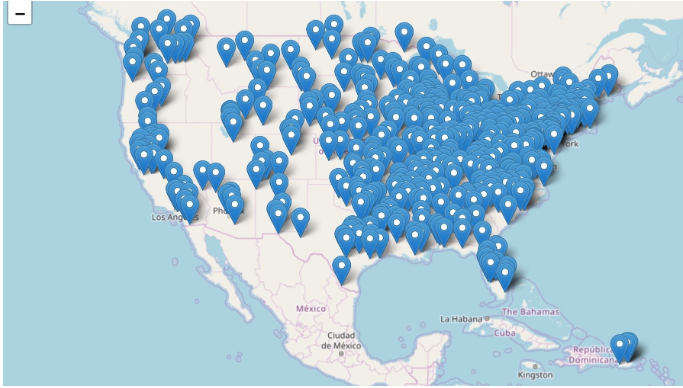

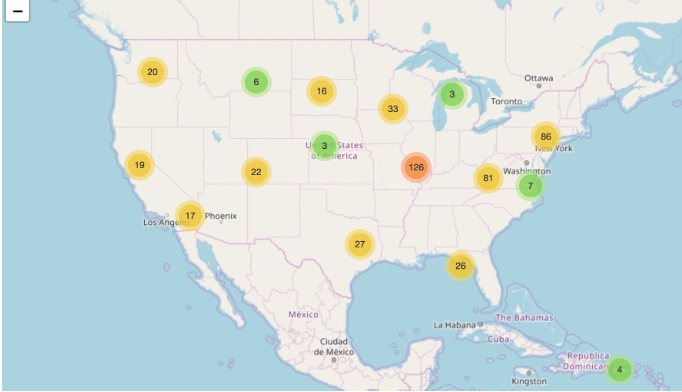
Tutorial
Depois de explorar mais sobre a arquitetura do PyMove e vislumbrar o mundo dos dados de trajetória, agora vamos botar a mão na massa!
Neste tutorial iremos entender como representar dados de trajetória no PyMove, aplicar funções de pré-processamento e visualização de dados existentes no PyMove!
Para isso, vamos utilizar o conjunto de dados utilizado neste trabalho, o Geolife GPS trajectory dataset, [5]. Ele é resultado da coleta realizada no projeto Geolife, da Microsoft Research Asia, por 178 usuários por mais de quatro anos. Esses dados registram uma grande variedade de movimentos de dos usuários, incluindo não só caminhos rotineiros, como também atividades esportivas e de lazer, amplamente distribuídos em mais de 30 cidades da China e em algumas cidades localizadas nos EUA e na Europa.
Esse conjunto de dados possui 17.621 trajetórias, registradas por GPS, com uma distância total de 1.251.654 quilômetros e duração de 48.203 horas. Os dados estão dispostos em 182 pastas, numeradas de 000 à 181, onde cada uma simbolizava um usuário. Os arquivos que contém os dados de localização possuem os valores separados por vírgula, onde representam, respectivamente, a latitude, longitude, campo sem valor, altitude, número de dias que passaram após a data 30/12/1999, data e tempo.
Por limitações de processamento e em busca de diversidade, nesse trabalho são utilizados os dados dos usuários 000, 010, 011 e 100, totalizando em 1.206.506 pontos de trajetórias.
Instalação do PyMove
Primeiro, vamos clonar o repositório!
COMANDO 1: git clone -b developer https://github.com/InsightLab/PyMove
Segundo, vamos criar um ambiente!
COMANDO 2: conda create -n pymove pip python=3.7
Terceiro, acesse o ambiente recém criado.
COMANDO 3: conda activate pymove
Quarto, vamos instalar as dependências da nossa biblioteca!
COMANDO 4: cd PyMove python setup.py install
Quinto, agora é só usar!
COMANDO 5: import pymove
Referências:
[1] G. A. M. Gomes, E. Santos, and C. A. Vidal. VISUALIZAÇÃO INTERATIVA DE DINÂMICAS DE TRÁFEGO ATRAVÉS DE DADOS DE TRAJETÓRIAS. PhD thesis, PD thesis, Universidade Federal do Ceará, 2018.
[2] G. A. M. Gomes, E. Santos, and C. A. Vidal. VISUALIZAÇÃO INTERATIVA DE DINÂMICAS DE TRÁFEGO ATRAVÉS DE DADOS DE TRAJETÓRIAS. PhD thesis, PD thesis, Universidade Federal do Cear´a, 2018.
[3] Tiago Gon¸calves, Ana Afonso, and Bruno Martins. Visualization techniques of trajectory data: Challenges and imitations. CEUR Workshop Proceedings, 1136, 01 2013.
[4] Yu Zheng. Trajectory data mining: An overview. ACM Transaction on Intelligent Systems and Technology, September 2015.
[5] Yu Zheng, Hao Fu, Xing Xie, Wei-Ying Ma, and Quannan Li. GeoLife User Guide 1.2. Microsoft Reasearch Asia, 2(April 2007):31–34, 2011