Se durante a sua vida profissional ou acadêmica, o grande problema foi encontrar tempo para ler, hoje, a realidade é outra. Pensando nisso o Insight Lab resolveu te dar uma ajudinha com dicas de leitura para você se aprimorar. Incluímos na lista obras técnicas e literárias que te trarão um conteúdo valioso e produtivo para sua carreira. Confira a lista.
Do mesmo criador da biblioteca Pandas, este volume é um guia para quem está no início da formação como programador. Ele ajuda a entender o funcionamento e a combinação de ferramentas para o tratamento de dados dentro do ambiente Python.
A obra é desenvolvida em seções curtas, o que torna a informação mais focada, isso ajudará o programador iniciante a identificar claramente os pontos centrais sem entrar em expansões ainda difíceis de entender.
Neste livro você aprenderá, a partir do zero, como os algoritmos e as ferramentas mais essenciais de data science funcionam. Entenderá a desempenhar bibliotecas, estruturas, módulos e stacks do data science ao mesmo tempo que se aprofunda no tema sem precisar, necessariamente, entender de data science.
O livro reflete sobre o que significa a organização dos dados em gráficos, a quem essas informações visuais serão
apresentadas, e dentro de qual contexto. Para a autora a visualização dos dados é o ponto onde as informações devem estar mais sistematizadas, não podendo se tornar um enigma para quem observa.
Ao longo dos capítulos o livro nos mostra processos de concepção dos elementos para a visualização de dados e traz muitos exemplos de antes e depois, ou seja, exemplos de gráficos que não transmitem corretamente a mensagem e, em seguida, uma versão alternativa onde a informação foi apresentada de forma clara e eficiente.
Um dos melhores livros prático sobre Machine Learning. Seja para iniciante na área ou para quem já atua e precisa de um complemento.
De maneira prática, o livro mostra como utilizar ferramentas simples e eficientes para implementar programas capazes de aprender com dados. Utilizando exemplos concretos, uma teoria mínima e duas estruturas Python, prontas para produção, o autor ajuda você a adquirir uma compreensão intuitiva dos conceitos e ferramentas na construção de sistemas inteligentes.
Direcionado principalmente para desenvolvedores, pesquisadores e analistas de Python que desejam executar análises geoespaciais, de modelagem e GIS com o Python.
O livro é uma ótima dica para quem deseja entender o mapeamento e a análise digital e quem usa Python ou outra linguagem de script para automação ou processamento de dados manualmente.
O livro foi feito para programadores que desejam se familiarizar com a Linguagem de Programação Scala para escrever programas concorrentes, escaláveis e reativos. Não é preciso ter experiência em programação para entender os conceitos explicados no livro. Porém, caso tenha, isso o ajudará a aprender melhor os conceitos.
O autor começa analisando os conceitos básicos da linguagem, sintaxe, tipos de dados principais, literais, variáveis e muito mais. A partir daí, o leitor será apresentado às suas estruturas de dados e aprenderá como trabalhar com funções de alta ordem.
7 – The man who solved the market: how Jim Simons Launched the quant revolution de Gregory Zuckerman
Em tradução livre – O homem que resolveu o mercado: como Jim Simons lançou a Revolução Quant. Um livro não técnico, conta a história de Jim Simons, um matemático que começou a usar estatísticas para negociar ações, em uma época em que todo mundo no mercado usava apenas instintos e análises fundamentais tradicionais.
Obviamente, todo mundo ficou cético em relação a seus métodos, mas depois de anos gerenciando seu fundo de investimentos e obtendo resultados surpreendentes, as pessoas acabaram cedendo e começaram a reconhecer o poder dos chamados quant hedge funds, que desempenham um papel enorme no setor financeiro nos dias atuais.
8 – Feature Engineering for Machine Learning de Alice Zheng e Amanda Casari
Embora a Engenharia de Recursos seja uma das etapas mais importantes no fluxo de trabalho da Ciência de Dados, às vezes ela é ignorada. Este livro é uma boa visão geral desse processo, incluindo técnicas detalhadas, advertências e aplicações práticas.
Ele vem com a explicação matemática e o código Python para a maioria dos métodos, portanto, você precisa de um conhecimento técnico razoável para seguir adiante.
9 – The book of why de Judea Pearl e Dana Mackenzie
Muitas vezes nos dizem que “a correlação não implica causalidade”. Quando você pensa sobre isso, no entanto, o conceito de causalidade não é muito claro: o que exatamente isso significa?
Este livro conta a história de como vemos a causalidade de uma perspectiva filosófica e, em seguida, apresenta as ferramentas e modelos matemáticos para entendê-la. Isso mudará a maneira como você pensa sobre causa e efeito.
10 –Moneyball de Michael Lewis
Esta é a história de Billy Beane e Paul DePodesta, que foram capazes de levar o Oakland Athletics, um pequeno time de beisebol, através de uma excelente campanha na Major League Baseball, escolhendo jogadores negligenciados baratos.
Como eles fizeram isso? Usando dados. Isso mudou a maneira como as equipes escolhem seus jogadores, o que anteriormente era feito exclusivamente por olheiros e seus instintos. A história também inspirou um filme com o mesmo nome, e ambos são obras-primas.
Fonte: crb8.org.br
O que achou das dicas? Que mais livros você incluiria? Compartilha com a gente!
Até onde uma ideia pode chegar? “Até o céu!”, diria Santos-Dumont.
É, Santos, elas podem ir além. Elas vão mais longe, e são muito mais significativas, quando são compartilhadas e se juntam a uma outra ideia.
Falando em ideias se encontrando, a gente já pensa no TED Talks, um evento que começou em 1984 juntando tecnologia, entretenimento e design, com seu slogan “Ideas worth spreading”. O TED é um dos eventos de maior audiência do mundo, e se tornou o fenômeno que conhecemos quando passou a disponibilizar as palestras gratuitamente nos meios online. A partir daí, as palestras puderam ser espalhadas em uma outra escala, chegando a um público de milhões.
O Ted é uma ideia que se espalhou e, com 36 anos de existência, já trouxe ao palco algumas das pessoas mais inspiradoras, criativas e inovadoras do campo da tecnologia. Em meio a esse universo de grandes conversas, hoje, nós vamos compartilhar a nossa lista dos 10 melhores Ted Talks de IA, dados e tecnologia.
A forma como a lista está ordenada não significa uma ordem de preferência. Olha as palestras que nós escolhemos:
A inteligência artificial está ficando mais inteligente rapidamente. Dentro deste século, sugerem pesquisas, uma IA de computador poderá ser tão “inteligente” quanto um ser humano. E então, diz Nick Bostrom, nos ultrapassará: “A inteligência das máquinas é a última invenção que a humanidade precisará fazer”. Filósofo e tecnólogo, Bostrom nos pede que pensemos muito sobre o mundo que estamos construindo agora, impulsionado por máquinas pensantes. Nossas máquinas inteligentes ajudarão a preservar a humanidade e nossos valores ou terão valores próprios?
Você nunca viu dados sendo apresentados assim. Com o drama e a urgência de um apresentador de esportes, o guru das estatísticas Hans Rosling desmascara mitos sobre o chamado “mundo em desenvolvimento”.
O aprendizado de máquina não é apenas para tarefas simples, como avaliar o risco de crédito e classificar e-mails. Hoje, ele é capaz de fazer aplicações muito mais complexas, como classificar dissertações e diagnosticar doenças. Com esses avanços, surge uma pergunta desconfortável: um robô fará o seu trabalho no futuro?
Quando uma criança muito jovem olha para uma foto, ela pode identificar elementos simples: “gato”, “livro”, “cadeira”. Agora, os computadores estão ficando inteligentes o suficiente para fazer isso também. O que vem depois? Em uma palestra arrebatadora, a especialista em visão computacional Fei-Fei Li, codiretora do Stanford’s Human-Centered AI Institute, descreve o estado da arte, incluindo o banco de dados de 15 milhões de fotos que sua equipe construiu para “ensinar” um computador a entender imagens, e as principais ideias que estão por vir.
Conheça a AIVA, uma inteligência artificial que foi treinada na arte da composição musical lendo mais de 30.000 das melhores partituras da história. Em uma palestra e demonstração hipnotizantes, Pierre Barreau toca composições criadas pela AIVA e compartilha seu sonho: criar trilhas sonoras originais ao vivo baseadas em nossos humores e personalidades.
Vivemos em um mundo administrado por algoritmos, programas de computador que tomam decisões ou resolvem problemas para nós. Nesta conversa engraçada e fascinante, Kevin Slavin mostra como os algoritmos modernos determinam os preços das ações, as táticas de espionagem e até os filmes que você assiste. Mas ele pergunta: se dependemos de algoritmos complexos para gerenciar nossas decisões diárias – quando começamos a perder o controle?
Nesta conversa informativa e inspiradora, Sebastian Thrun discute o progresso do aprendizado profundo, por que não devemos temer a IA e como a sociedade será melhor se o trabalho tedioso for feito com a ajuda de máquinas. “Apenas 1% das coisas interessantes já foram inventadas”, diz Thrun. “Eu acredito que todos nós somos insanamente criativos … [IA] nos permitirá transformar a criatividade em ação”.
Neste TEDx, a pesquisadora da MITRE Corporation, Jaya Tripathi, apresenta métodos fundamentais em Ciência de Dados ao descrever seu processo para chegar à verdade em sua pesquisa sobre demografia e dependência.
Os algoritmos de IA tomam decisões importantes sobre você o tempo todo. Mas o que acontece quando essas máquinas são construídas com viés humano codificado em seus sistemas? A tecnóloga Kriti Sharma explora como a falta de diversidade na tecnologia está se infiltrando em nossa IA, e oferece três maneiras pelas quais podemos começar a criar algoritmos mais éticos.
Quão inteligentes nossas máquinas podem nos tornar? Tom Gruber, co-criador da Siri, quer criar uma “IA humanística” que aumente e colabore conosco, em vez de competir (ou substituir). Ele compartilha sua visão sobre um futuro em que a IA nos ajuda a alcançar um desempenho sobre-humano na percepção, criatividade e função cognitiva, desde turbinar nossas habilidades de design até nos ajudar a lembrar tudo o que lemos e o nome de todos que já conhecemos. “Estamos no meio de um renascimento na IA”, diz Gruber. “Toda vez que uma máquina fica mais inteligente, nós ficamos mais inteligentes”.
E você, quais Ted Talks mais te marcaram? Compartilha com a gente nos comentários.
*Os resumos apresentados sobre as palestras foram adaptados do site do TED.
Diante de um cenário tão complexo quanto o atual, onde grande parte da população se sente desorientada e assustada, é fundamental difundir informações corretas e claras. Por isso, estamos lançando o 1º webinar do Insight Lab: “Como os modelos epidemiológicos são aplicados ao Covid-19: entendendo casos reais”.
Com transmissão online e gratuita no YouTube, o evento acontecerá nesta quarta-feira (20 de maio), começando às 16h, e contará com cinco especialistas que esclarecerão, através de casos reais observados na pandemia de 2020, os modelos epidemiológicos usados para entender e prever o comportamento do Covid-19 entre as populações.
Faça parte da conversa!
Serviço
Dia: 20 de maio
Horário: 16h
Clique aqui para acessar o webinar e adicionar um lembrete na agenda.
Olha quem acabou de chegar na internet: nosso “Curso de Introdução ao Docker”. O curso foi ministrado na Universidade Federal do Ceará (UFC), em 2019, e agora está disponível em nosso canal no YouTube.
Gustavo Coutinho: Professor no Instituto Federal de Educação, Ciência e Tecnologia do Ceará (IFCE) e doutorando em Ciências da Computação na Universidade Federal do Ceará (UFC)
Lucas Peres: Desenvolvedor full-stack e doutorando em Ciências da Computação na Universidade Federal do Ceará (UFC)
Regis Pires: Cientista de dados do Insight Lab e do Íris (Lab de Inovação e Dados do Ceará).
Para quem está de quarenta, todo dia é um ótimo dia de leitura.
Então, se você já tem uma lista de livros para ler neste período, anota mais um!
O livro Learning Scala Programming de Vikas Sharma, foi feito para programadores que desejam se familiarizar com a Linguagem de Programação Scala para escrever programas concorrentes, escaláveis e reativos. Não é preciso ter experiência em programação para entender os conceitos explicados no livro. Porém, caso tenha, isso o ajudará a aprender melhor os conceitos.
SAIBA MAIS
Scala é uma linguagem de programação de uso geral que suporta paradigmas de programação funcional e orientada a objetos. Devido ao seu design e versatilidade, as aplicações em Scala foram estendidas a uma ampla variedade de campos, como Ciência de Dados e Computação Distribuída.
Apesar de ser uma linguagem baseada na JVM (Java Virtual Machine) de uso geral, como Java, Scala fornece uma vantagem com as primitivas funcionais. Scala também possui um sistema de tipagem rico, o que o torna mais expressivo. Usando sistemas de tipagens, os desenvolvedores podem escrever aplicações menos propensas a erros em tempo de execução.
O LIVRO
O autor começa analisando os conceitos básicos da linguagem, sintaxe, tipos de dados principais, literais, variáveis e muito mais. A partir daí, o leitor será apresentado às suas estruturas de dados e aprenderá como trabalhar com funções de alta ordem.
Além disso, o livro apresenta conceitos como pattern matching, case classes e recursos de programação funcional. Em seguida, você aprenderá como trabalhar com os recursos de orientação a objetos em Scala e sobre programação assíncrona e reativa, onde será apresentado ao framework Akka. Há ainda o aprendizado sobre a interoperabilidade do Scala e Java.
Com tudo isso, este livro fornece todos os elementos essenciais necessários para escrever programas usando Scala. Ele tem todos os blocos de construção básicos que alguém novo em Scala pode querer saber sobre ele, além dos motivos para usá-lo. Um dos principais objetivos deste livro é permitir que você escolha uma construção específica acima de outra.
O AUTOR
Vikas Sharma é desenvolvedor de software e evangelista de tecnologia de código aberto. Ele tenta manter as coisas simples, o que o ajuda a escrever um código limpo e gerenciável. Ele investiu muito tempo aprendendo e implementando o código do Scala e é autor de cursos de vídeo de Scala. Sharma também trabalha como desenvolvedor no SAP Labs.
Depois de ler este livro, você estará familiarizado nesta linguagem de programação e em seus recursos e poderá escrever programas escaláveis, concorrentes e reativos em Scala.
Esta leitura será uma companheira em sua jornada de aprendizado e no desenvolvimento de aplicações em Scala.
A cultura de aprender pela internet ganha novos adeptos todos os dias. A possibilidade de estudar no melhor horário para você, de explorar metodologias, participar de fóruns online com estudantes do mundo todo, de estudar de casa ou de qualquer outro lugar são alguns dos motivos para os cursos online terem crescido tanto.
Este ano, diante da necessidade do isolamento social provocada pela pandemia de COVID-19, temos mais um motivo para buscar as salas de aula virtuais. Confira abaixo cinco cursos online e gratuitos para fazer durante a quarentena. As opções de cursos que serão apresentadas abrangem os três níveis: iniciante, médio e avançado.
*O conteúdo dos cursos indicados é gratuito, mas, se você quiser receber um certificado de conclusão, precisará pagar.
Cursos para iniciantes
1. Aprendizado de Máquina (Machine Learning)
Plataforma: Coursera
Oferecido por: Standford
Carga horária: 54h
Requisitos: não existem exigências iniciais, mas alguma compreensão de cálculo e, especialmente, de Álgebra Linear será importante para aproveitar o curso ao máximo.
Comentários: Andrew Ng, o instrutor deste curso, é uma lenda nos campos de Machine Learning e Inteligência Artificial. Ele é professor em Standford, um dos fundadores da Coursera e desenvolveu um dos primeiros cursos on-line de Machine Learning, que ainda está disponível no YouTube.
Como o curso se descreve:
“Este curso fornece uma ampla introdução ao Aprendizado de Máquina, Datamining e reconhecimento de padrões estatísticos. Os tópicos incluem: (i) Aprendizado supervisionado (algoritmos paramétricos / não paramétricos, máquinas de vetores de suporte, núcleos, redes neurais). (ii) Aprendizagem não supervisionada (agrupamento, redução de dimensionalidade, sistemas de recomendação, aprendizagem profunda). (iii) Boas práticas em aprendizado de máquina (teoria de viés / variância; processo de inovação em aprendizado de máquina e IA).”
Assuntos tratados:
Regressão linear (Linear regression)
Regressão logística (Logistic regression)
Regularização (Regularization)
Redes neurais (Neural Networks)
Máquinas de vetores de suporte (Support Vector Machines)
Aprendizagem não supervisionada (Unsupervised Learning)
Redução de dimensionalidade (Dimensionality Reduction)
Detecção de anomalia (Anomaly Detection)
Sistemas de recomendação (Recommendation Systems)
2. Aprendizado de máquina com Python (Machine Learning with Python)
Plataforma: Coursera
Oferecido por: IBM
Carga horária: 22h
Requisitos: conhecimento em Matemática Básica.
Comentários: apesar do curso ser classificado como de “nível intermediário” pelo Coursera, é um bom ponto de partida para alguém novo no campo. Também é uma boa opção se você estiver procurando por um curso mais curto que o anterior, de Stanford, pois possui uma carga horária bem menor.
Como o curso se descreve:
“Este curso aborda os conceitos básicos de Aprendizado de Máquina usando uma linguagem de programação acessível e conhecida, o Python. Neste curso, analisaremos dois componentes principais: Primeiro, você aprenderá sobre o objetivo do Machine Learning e onde ele é aplicado no mundo real. Segundo, você obterá uma visão geral dos tópicos do Machine Learning, como aprendizado supervisionado versus não supervisionado, avaliação de modelos e algoritmos de aprendizado de máquina.”
Assuntos tratados:
Regressão (Regression)
Classificação (Classification)
Agrupamento (Clustering)
Sistemas de recomendação (Recommendation Systems)
Cursos de nível intermediário
3. Redes Neurais e Aprendizagem Profunda (Neural Networks and Deep Learning)
Plataforma: Coursera
Oferecido por:deeplearning.ai
Carga horária: 30h
Requisitos: Experiência em codificação Python e Matemática do Ensino Médio. Conhecimentos prévios em Machine Learning e/ou em Deep Learning são úteis.
Comentários: depois de dominar os conceitos básicos do Machine Learning e se familiarizar com o Python, o próximo passo é provavelmente familiarizar-se com o TensorFlow, pois muitos algoritmos computacionalmente caros hoje em dia estão sendo executados com ele. Outro check positivo do curso é que Andrew Ng é um dos instrutores.
Como o curso se descreve:
“Neste curso, você aprenderá os fundamentos do Aprendizado Profundo. Quando você terminar esta aula, você irá:
– Entender as principais tendências tecnológicas que impulsionam o Deep Learning
– Ser capaz de construir, treinar e aplicar redes neurais profundas totalmente conectadas
– Saber como implementar redes neurais eficientes (vetorizadas)
– Entender os principais parâmetros na arquitetura de uma rede neural.”
Assuntos tratados:
Introdução à Aprendizagem Profunda (Introduction to Deep Learning)
Noções básicas sobre redes neurais (Neural Networks basics)
Requisitos: conhecimentos de TensorFlow, codificação Python e Matemática do Ensino Médio.
Comentários: curso ideal para ser feito após os cursos indicados acima.
Como o curso se descreve:
“Este curso ensinará como criar redes neurais convolucionais e aplicá-las a dados de imagem. Graças ao aprendizado profundo, a visão por computador está funcionando muito melhor do que apenas dois anos atrás, e isso está permitindo inúmeras aplicações interessantes, desde direção autônoma segura, reconhecimento facial preciso, até leitura automática de imagens radiológicas.”
Assuntos abordados:
Fundamentos de redes neurais convolucionais (Foundations of Convolutional Neural Networks)
Modelos convolucionais profundos: estudos de caso (Deep convolutional models: case studies)
Detecção de objetos (Object detection)
Aplicações especiais: Reconhecimento facial e transferência de estilo neural (Special applications: Face recognition & Neural style transfer)
Oferecido por: National Research University Higher School of Economics
Carga horária: 10 meses, se você conseguir dedicar seis horas por semana
Requisitos: o curso é projetado para aqueles que já estão na indústria, com uma sólida base em Machine Learning e Matemática.
Comentários: essa é uma especialização completa; portanto, tecnicamente, você pode pular qualquer um dos cursos indicados, se achar que não precisa ou se já cobriu esses tópicos no trabalho ou nos cursos anteriores.
Como o curso se descreve:
“Mergulhe nas técnicas modernas de IA. Você ensinará o computador a ver, desenhar, ler, conversar, jogar e resolver problemas do setor. Esta especialização fornece uma introdução ao aprendizado profundo (deep learning), aprendizado por reforço (reinforcement learning), compreensão de linguagem natural (natural language understanding), visão computacional (computer vision) e métodos bayesianos. Os principais profissionais de Aprendizado de Máquina do Kaggle e os cientistas do CERN (European Organization for Nuclear Research) compartilharão sua experiência na solução de problemas do mundo real e ajudarão você a preencher as lacunas entre teoria e prática.”
Assuntos abordados:
Introdução à Aprendizagem Profunda (Introduction to deep learning) – (32hs)
Como Ganhar um Concurso de Ciência de Dados: Aprenda com os Melhores Kagglers (How to Win a Data Science Competition: Learn from Top Kagglers) – (47hs)
Métodos Bayesianos para Aprendizado de Máquina (Bayesian Methods for Machine Learning) – (30hs)
Aprendizagem Prática de Reforço (Practical Reinforcement Learning) – (30hs)
Aprendizagem Profunda em Visão Computacional (Deep Learning in Computer Vision) – (17hs)
Processamento de Linguagem Natural (Natural Language Processing) – (32hs)
Enfrentando Grandes Desafios de Colisor de Hádrons através do Aprendizado de Máquina (Addressing Large Hadron Collider Challenges by Machine Learning) – (24 horas)
O Insight Lab é formado por um time multidisciplinar de pesquisadores que vão desde de alunos de graduação a especialistas. Com o propósito de desenvolver pesquisas na área de Data Science, que possam beneficiar a outros pesquisadores e a sociedade em geral, nossos pesquisadores estão sempre atentos às necessidades que as mudanças e as novas tecnologias proporcionam.
Observamos com isso, por exemplo, que o crescente uso de sensores GPS e barateamento de tecnologias móveis, nos últimos anos, têm gerado um grande volume de dados de trajetórias. Esses dados podem trazer respostas para facilitar diversas atividades que impactam diretamente na vida das pessoas. Pensando nisso, o quê um Cientista de Dados pode fazer a partir daí?
O que é uma trajetória?
Bem, antes de tudo é muito importante entendermos o que é uma trajetória. Uma trajetória é uma sequência de pontos cronologicamente ordenados, que representam o movimento de um objeto em um espaço geográfico. Cada ponto é formado por uma marcação de tempo e coordenadas geoespaciais (latitude,longitude). As trajetórias podem representar movimentos de diferentes objetos, como:pessoas, veículos e animais.
O que podemos fazer com os dados de trajetória?
Esse tipo de dado é muito valioso não só para a Computação, mas também para áreas como Geografia, Sociologia e Urbanização, sendo bastantes utilizados para aplicações como: sistemas de transporte inteligentes e computação urbana; análise de mobilidade sustentável; no rastreamento de fenômenos naturais e identificação de padrões de migração animal e etc.
Como trabalhar com esse dado?
Para que seja possível extrair informações dos dados e realizar análises consistentes dos mesmos, é preciso que um conjunto de atividades de mineração de dados, que veremos em mais detalhes a seguir, sejam executadas. Embora haja um grande volume de trabalhos e aplicações, nota-se a ausência de softwares e ferramentas que possam auxiliar pesquisadores em todo o processo para lidar e extrair as informações que esses dados possam oferecer.
Com isso, nós do Insight Data Science Lab estamos trabalhando para a elaboração de uma biblioteca open-source para Python que contemple o conjunto de etapas e atividades para lidar com esses dados: o PyMove!
O que é o PyMove?
O PyMove surgiu em meados de 2018 com o objetivo de ser uma biblioteca Python extensível que comporte um grande número de operações dentro das etapas de mineração de dados de trajetória!
O PyMove propõe :
Uma sintaxe familiar e semelhante ao Pandas;
Documentação clara;
Extensibilidade, já que você pode implementar sua estrutura de dados principal manipulando outras estruturas de dados, como o Dask DataFrame, matrizes numpy, etc., além de adicionar novos módulos;
Flexibilidade, pois o usuário pode alternar entre diferentes estruturas de dados;
Operações para pré-processamento de dados, mineração de padrões e visualização de dados.
Modelagem do Pymove
Estrutura de dados
A atual estrutura do PyMove é fortemente influenciada pelo trabalho de Yu Zheng, o qual propõe um paradigma que serve como um guia para realizar trabalhos de mineração de dados de trajetória. A figura 2.1.1 mostra a versão adaptada desse paradigma adotada no PyMove.
Figura 2.1.1. Um paradigma para mineração de trajetória. Fonte: Adaptado de [4]
A seguir, iremos destrinchar cada etapa citada na figura 2.1.1.
Pré-processamento
O pré-processamento de dados é uma etapa de extrema importância na mineração dos dados. Nela são realizadas atividades com o objetivo de melhorar a qualidade do dados para obtenção de melhores resultados em processamentos e análises futuras. Existem quatro técnicas básicas para esta etapa: filtragem de ruído, detecção de pontos de parada, compressão e segmentação de trajetória.
Filtragem de ruído
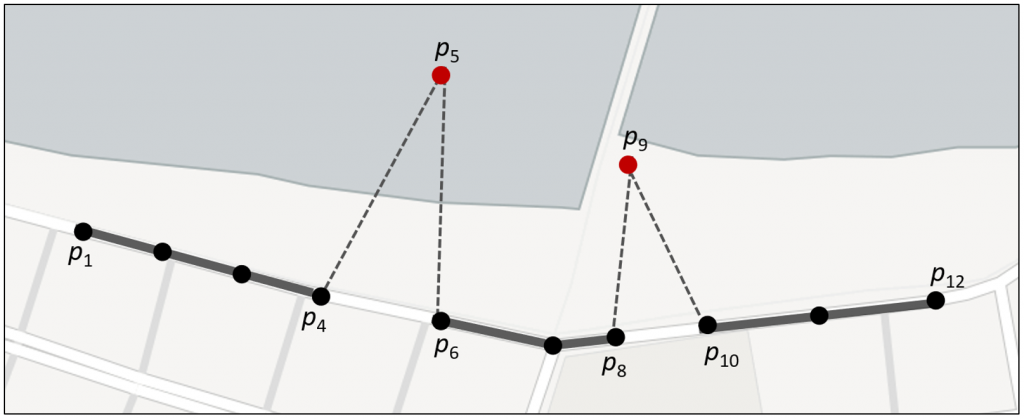
Alguns pontos da trajetória podem estar inconsistentes devido a problemas nos dispositivos de coleta de dados, na comunicação, ou em outros fatores externos, tais pontos são denominados ruídos. As técnicas de filtragem de ruído procuram realizar a remoção ou alinhamento desses dados ruidosos com a rede de ruas. Os pontos p5 e p9 na Figura 3.1 são, neste contexto, dados com ruído.
Figura 3.1. Trajetória com pontos lidos incorretamente. Fonte: adaptado de [1]
Detecção de pontos de parada
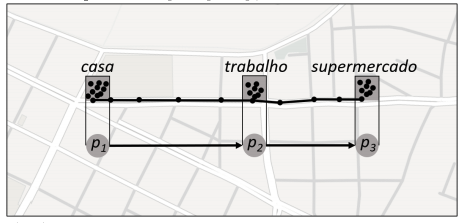
Pontos onde os objetos ficaram parados ou se movimentando ao redor, por um determinado limite de tempo, são chamados pontos de parada. Estes pontos podem representar: shoppings, atrações turísticas, postos de gasolina, restaurantes, entre outros. Os pontos de parada nos permitem representar uma trajetória como uma sequência de pontos com significado.
A figura 3.2 mostra uma trajetória, após a execução de um algoritmo, para detectar pontos de parada onde são encontrados três pontos de parada: casa, trabalho e supermercado. Esses pontos podem representar essa trajetória, como pontos p1, p2 e p3, respectivamente.
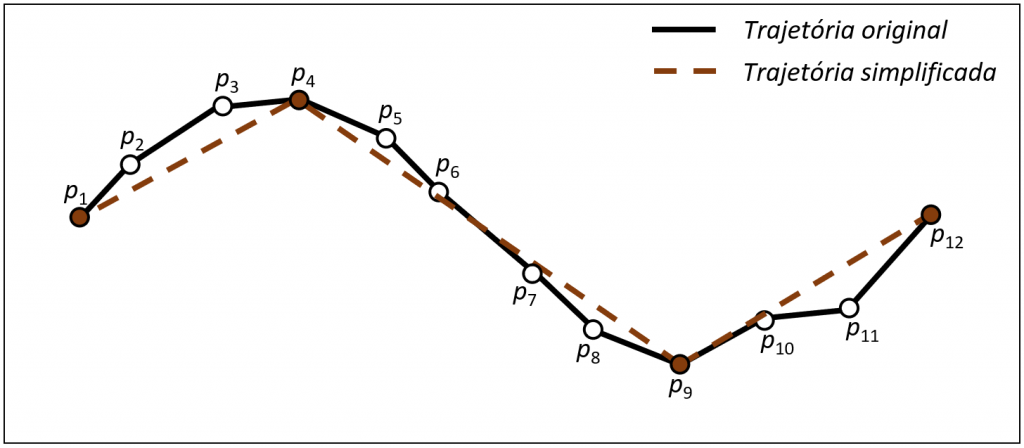
Compressão
Tem como objetivo reduzir o tamanho dos dados de trajetória através de um conjunto de técnicas, com o objetivo de evitar sobrecarga de processamento e minimizar a carga no armazenamento de dados, gerando uma representação mais compactada que descreve a trajetória de um objeto.
Figura 3.2. Resultado da execução de um algoritmo de detecção de pontos de parada. Fonte: adaptado de [2].
Na Figura 3.3 podemos ver o resultado da compressão de uma trajetória, inicialmente ela é representada por doze pontos, mas após a compressão este número é reduzido para quatro pontos.
Figura 3.3. Demonstração da aplicação de uma técnica de compreensão de dados de trajetórias. Fonte: adaptado de [2].
Segmentação
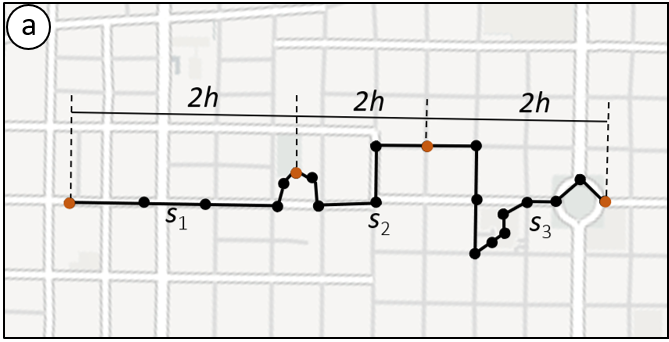
Nesta etapa, a trajetória é subdividida em segmentos, de tal forma que os dados pertencentes ao mesmo segmento tenham comportamento homogêneo. A segmentação ajuda a descobrir padrões sobre os dados, diminui a complexidade computacional e é um passo obrigatório para processos de análise, como a clusterização e a classificação. A Figura 3.4 apresenta um exemplo de segmentação de trajetória pelo tempo fixo de duas horas, resultando em três novos segmentos.
Figura 3.4. Segmentação de uma trajetória com base no intervalo de tempo igual a duas horas. Fonte: adaptado de [2]
Map-matching
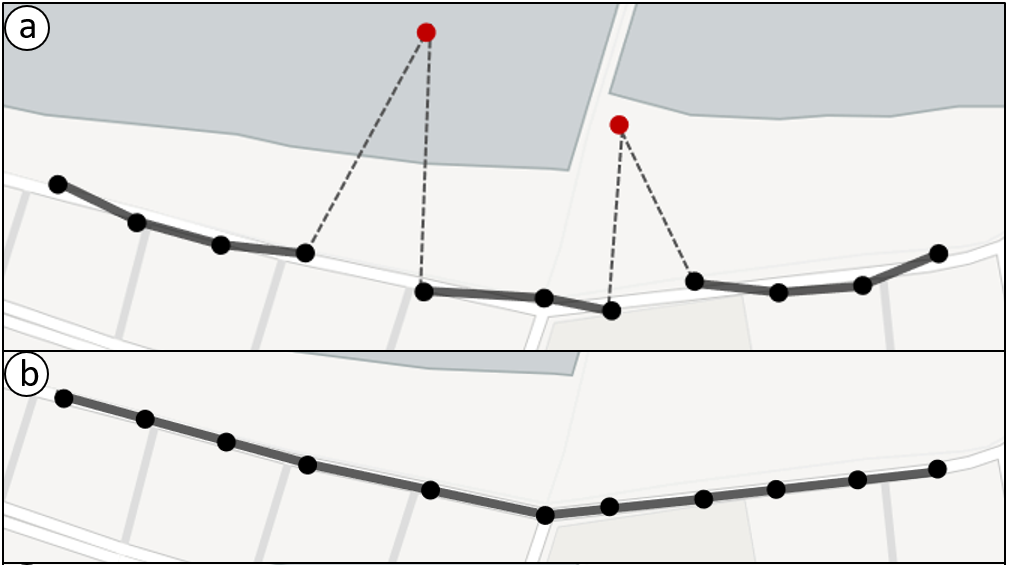
Como foi mencionado acima, os pontos gerados em uma trajetória podem não corresponder precisamente à real localização de onde o objeto em movimento passou, (figura 3.5-a).
Esta falta de precisão não é desejável para alguns tipos de aplicações, entre elas: as que trabalham com análise de fluxo de trânsito ou serviços de navegação (ZHENG,2015). Para resolver esses e outros problemas, são aplicados algoritmos de map-matching, que têm como objetivo alinhar os pontos da trajetória com a rede de ruas, (figura 3.5-b).
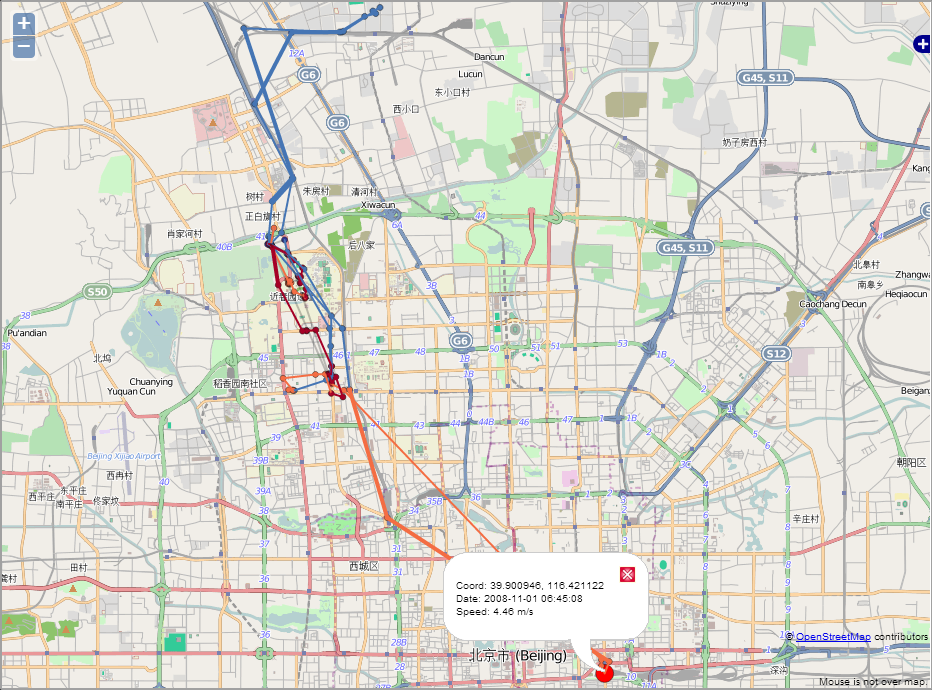
Figura 3.5 (a e b). Uma trajetória, antes e depois da aplicação do Map-matching. Fonte: adaptado de [1].
Indexação e recuperação de trajetórias
Durante o processo de mineração de dados de trajetórias, acabamos por precisar acessar frequentemente diferentes segmentos e amostras das trajetórias. Com o grande volume de dados, esses acessos podem demandar tempo e processamento. Por isso, é necessário a adoção de técnicas eficazes para o gerenciamento desses dados, oferecendo a recuperação rápida dos dados.
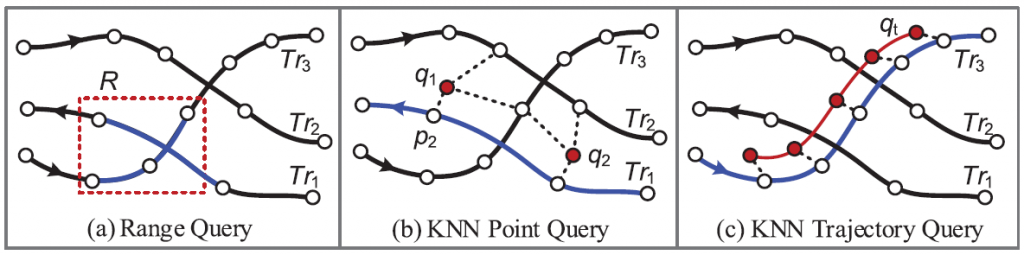
Os dois principais tipos de consultas, mostrado na Figura 2.1.1 – Um paradigma para mineração de trajetória.
KNN: esse tipo de consulta recupera as K, primeiras trajetórias com a distância agregada mínima, para alguns pontos ou uma trajetória específica.
Nas consultas de pontos buscamos por trajetórias que possuam uma boa conexão com os locais/pontos pesquisados, em vez de saber se a trajetória é semelhante à consulta em forma.
Nas consulta por trajetória buscamos encontrar os registros que possuam uma rota ou segmento de trajetória parecida. Essa consulta necessita da definição de uma função que delimite a similaridade e distância entre trajetórias.
Intervalo de consultas: recuperam os dados de trajetórias que estão contidos em um espaço ou intervalo. Essa técnica contém três abordagens para consultas de intervalo espaço-temporal.
A primeira abordagem considera o tempo como a terceira dimensão além das informações que delimitam o espaço geográfico.
A segunda abordagem divide um período em vários intervalos de tempo, criando um índice espacial individual.
A terceira abordagem leva em consideração o espaço geográfico, dividindo-o em grades, as chamadas grids, e cria um índice temporal para as trajetórias que caem em cada célula dessa grade. Cada segmento que cai em uma grade é representado por um ponto com as coordenadas iguais ao ponto com horário inicial e o ponto com horário final do segmento.
A Figura 4 mostra as técnicas para melhoria da indexação e recuperação de dados e segmentos de trajetórias. Em (a) é mostrada a técnica de Intervalo de consulta. Nela são recuperados os pontos e segmentos de trajetórias dentro da região retangular tracejada em vermelho. Já em (b) e (c) são mostradas o uso da técnica de consulta via KNN, sendo a primeira consultas por pontos e a segunda consulta por segmentos de trajetórias similares.
Figura 4. Demonstração das abordagens utilizadas para indexação e recuperação de trajetórias. Fonte: adaptado de [4].
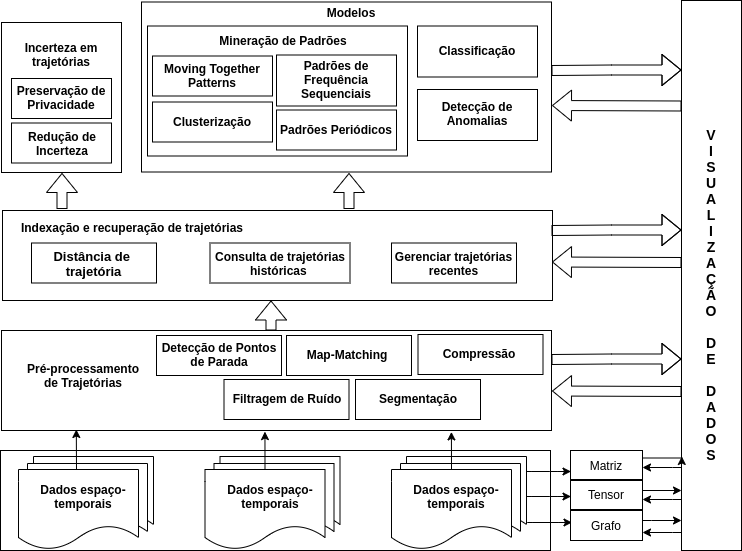
Modelos
Muitas aplicações exigem informações instantâneas a partir dos dados de trajetória, como é o caso de aplicações de guia de viagens ou detecção de anomalias de tráfego. Essas informações exigem algoritmos eficazes e muitas vezes são adquiridas por meio de técnicas de mineração de dados. Essas técnicas podem ser enquadradas em áreas, como classificação, detecção de anomalias, mineração de padrões e incertezas da trajetória. Abaixo é explorado o conceito de cada uma dessas técnicas.
Classificação
Trajetórias e segmentos podem ser classificados de diferentes modos e em diferentes categorias, como em: tipo de atividade, modos de transporte e até mesmo o movimento, através do uso de técnicas e algoritmos de aprendizado supervisionado.
Em geral, a classificação da trajetória é composta por três etapas principais:
Utilização de métodos de segmentação da trajetória para prover segmentos;
Extração de características de cada segmento;
Criação de modelos para classificar cada segmento.
Detecção de anomalias
Anomalias, no contexto de dados espaço temporais, consistem em pontos ou até mesmo segmentos de uma trajetória que possuem um comportamento anormal. Não segue o padrão dos dados que representam uma trajetória, como é o caso dos pontos destacados em vermelho na Figura 3.1. Essas anomalias podem ser desencadeados por diversos eventos como: um acidente de trânsito, que obriga os carros a mudarem rapidamente de velocidade, um desvio de uma rota comum por conta de uma obra ou por estar perdido no caminho. A etapa de detecção de anomalias, se preocupa em encontrar esses pontos e/ou segmentos que violem um certo padrão de uma trajetória.
Mineração de padrões
Diferentes padrões de mobilidade podem ser identificados numa trajetória individual ou em um conjunto de trajetórias. Os padrões de mobilidade de trajetória em quatro categorias: Clusterização de trajetórias, MovingTogetherPatterns, , Padrões Periódicos e Padrões de Frequências Sequenciais.
Clusterização: as técnicas dessa categoria têm como finalidade agrupar trajetórias em busca de algum padrão ou característica que diferenciem grupos.
Moving Together Patterns: essa categoria reúne técnicas que procuram detectar indivíduos e/ou objetos que se movem juntos por determinado período de tempo, sendo bastante útil para detectar padrões. Esses padrões podem ter diversas aplicações, como ajudar a entender fenômenos de migração e tráfego de espécies.
Padrões Periódicos: reúne técnicas que procuram identificar comportamentos e padrões temporais em trajetórias, como a ida a um dentista durante um intervalo de tempo, ou até mesmo os animais, que migram anualmente de um lugar a outro. A análise deste tipo de padrão auxilia na previsão de comportamentos futuros do objeto e na compressão de dados.
Padrões de Frequências Sequenciais: reúne técnicas que possuem a finalidade de encontrar padrões onde objetos partilhem a mesma sequência de localização, num período similar de tempo. Os pontos da sequência não necessariamente precisam ser pontos consecutivos na trajetória original. Essas técnicas são amplamente utilizados em aplicações como recomendação de trajetória, predição de localização, compressão de dados.
Incerteza em trajetórias
Indivíduos e objetos realizam movimentos contínuos em determinados locais em que trafegam. Porém, devido à limitação de algumas aplicações ou por questão de economia de energia dos sensores, os dados que representam essa trajetória são enviados periodicamente. Desse modo, a localização desse indivíduo e/ou objeto será incerta, ou até mesmo desconhecida, entre dois pontos que descrevem sua trajetória.
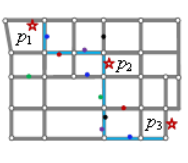
Na Figura 6 é perceptível que entre dois pontos é possível tomar caminhos diferentes, por exemplo: partindo do ponto p1 é possível chegar ao ponto p2 de diferentes formas. Este contexto ocasiona a incerteza dos caminhos tomados entre pontos de uma trajetória.
Nessa linha de pesquisa, há duas sub-áreas, descritas a seguir:
Redução de incertezas: consiste em desenvolver técnicas que visam diminuir a incerteza da trajetória entre dois pontos.
Preservação de privacidade: consiste em desenvolver técnicas que visam ampliar a incerteza de trajetórias sem afetar a qualidade de um serviço ou o uso desses dados, visando proteger um usuário do vazamento de privacidade causado pela divulgação de suas trajetórias.
Figura 6. Demonstração de uma trajetória formada por três pontos, p1, p2 e p3. Fonte: adaptado de [4].
Visualização de trajetórias
A aplicação de técnicas de visualização de dados nos grandes volumes de dados de trajetórias podem facilitar a compreensão do comportamento de objetos em movimento, como veículos e descoberta de tráfego, social, geoespacial e até padrões econômicos. Essas visualizações podem ser combinadas com procedimentos de processamento dos dados, visando diminuir, limpar e filtrar os dados.
Para visualizar dados de trajetória são necessárias técnicas que exploram canais visuais como cor, tamanho, forma, orientação aplicadas a diferentes marcas como pontos, linhas, áreas, volumes e superfícies para representar estes dados, transformando-os em representações visuais apropriadas.
Há diferentes técnicas de visualização a serem aplicadas como:
Gráfico de Linhas: visualizações orientadas ao tempo enfatiza a exibição de padrões, periodicidade, tendências e anormalidade dos dados de trajetória. Nesse tipo de representação é amplamente utilizado gráfico de linhas, onde o eixo X delimita o tempo e o Y outra característica do dado, como os picos de velocidade de uma trajetória.
Mapa estáticos: são abordagens bastante comuns para representar informações de localização geográfica, como a análise de trajetórias de mobilidade ou fluxo de tráfego em uma rede distribuída. Convencionalmente, uma trajetória é representada por uma linha ou uma curva, podendo explorar combinações de variáveis, como cor, tamanho e direção, em relação às suas propriedades.
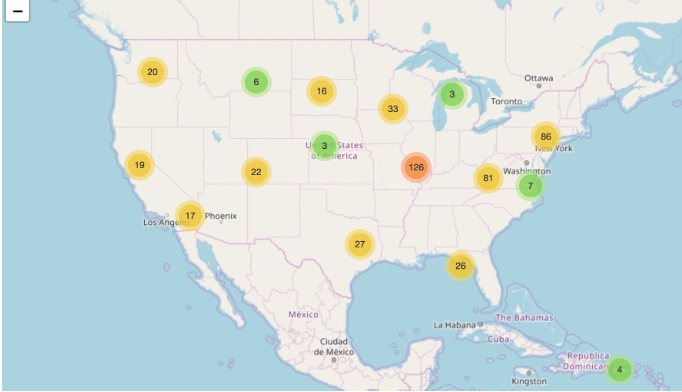
Clusters: Quando há uma grande massa de dados de trajetória, pode haver sobreposição de pontos em uma visualização. Com isso as visualizações com clusters em mapas ajudam bastante em análises, visto que um grupo de pontos que em determinado momento se sobrepunham, tornam-se um só. Essa técnica permite obter uma visão geral rápida de seus conjuntos de clusters.
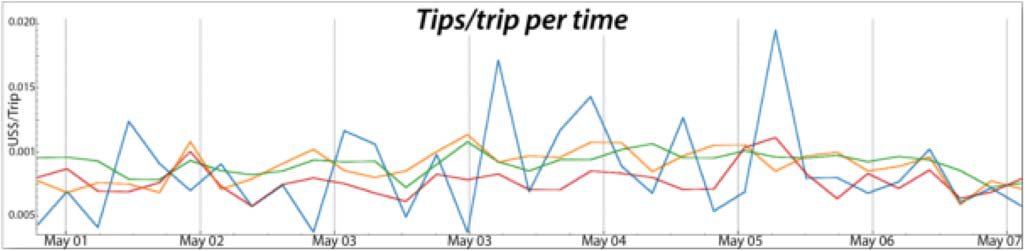
Visualização dos dados de gorjetas das viagens de táxis fazendo uso do gráfico de linhas para demonstrar a quantidade de gorjetas obtidas pelas viagens de táxi no período de tempo de 1 a 7 de maio de 2011. Cada linha representa a gorjeta por viagem em uma região. Fonte: Wei Chen, Fangzhou Guo, and Fei-Yue Wang. A survey of traffic data visualization. IEEE Transactions on Intelligent Transportation Systems, 16:2970–2984, 12 2015.
Exploração do uso de recursos visuais para visualização em mapas estáticos. Fonte: adaptado de [3].
Mapas de Calor: Essa visualização é gerada a partir de uma matriz de células, onde cada célula é colorida de forma gradiente com base em valores ou função dos dados, sendo bastante útil quando é necessário gerar visualizações para grande volume de dados, fornecendo uma visão geral dos maiores e menores valores dos dados.
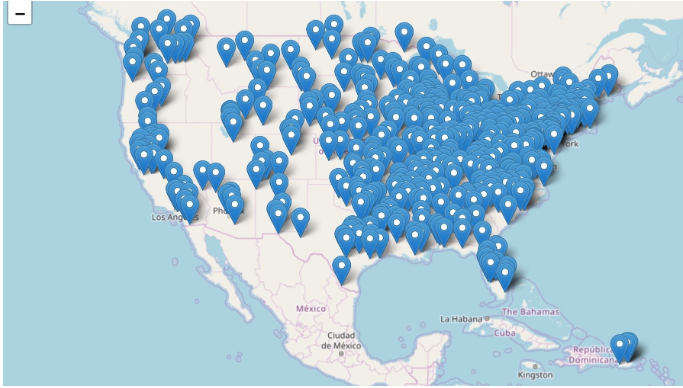
Visualização de todos os pontos sob um mapa gerado pelo Folium. Fonte: documentação Folium.
Utilização da técnica de cluster para visualizar os pontos sob um mapa gerado pelo Folium. Fonte: documentação Folium.
Depois de explorar mais sobre a arquitetura do PyMove e vislumbrar o mundo dos dados de trajetória, agora vamos botar a mão na massa!
Neste tutorial iremos entender como representar dados de trajetória no PyMove, aplicar funções de pré-processamento e visualização de dados existentes no PyMove!
Para isso, vamos utilizar o conjunto de dados utilizado neste trabalho, o Geolife GPS trajectory dataset, [5]. Ele é resultado da coleta realizada no projeto Geolife, da Microsoft Research Asia, por 178 usuários por mais de quatro anos. Esses dados registram uma grande variedade de movimentos de dos usuários, incluindo não só caminhos rotineiros, como também atividades esportivas e de lazer, amplamente distribuídos em mais de 30 cidades da China e em algumas cidades localizadas nos EUA e na Europa.
Esse conjunto de dados possui 17.621 trajetórias, registradas por GPS, com uma distância total de 1.251.654 quilômetros e duração de 48.203 horas. Os dados estão dispostos em 182 pastas, numeradas de 000 à 181, onde cada uma simbolizava um usuário. Os arquivos que contém os dados de localização possuem os valores separados por vírgula, onde representam, respectivamente, a latitude, longitude, campo sem valor, altitude, número de dias que passaram após a data 30/12/1999, data e tempo.
Por limitações de processamento e em busca de diversidade, nesse trabalho são utilizados os dados dos usuários 000, 010, 011 e 100, totalizando em 1.206.506 pontos de trajetórias.
Quarto, vamos instalar as dependências da nossa biblioteca! COMANDO 4: cd PyMove python setup.py install
Quinto, agora é só usar! COMANDO 5: import pymove
Referências:
[1] G. A. M. Gomes, E. Santos, and C. A. Vidal. VISUALIZAÇÃO INTERATIVA DE DINÂMICAS DE TRÁFEGO ATRAVÉS DE DADOS DE TRAJETÓRIAS. PhD thesis, PD thesis, Universidade Federal do Ceará, 2018.
[2] G. A. M. Gomes, E. Santos, and C. A. Vidal. VISUALIZAÇÃO INTERATIVA DE DINÂMICAS DE TRÁFEGO ATRAVÉS DE DADOS DE TRAJETÓRIAS. PhD thesis, PD thesis, Universidade Federal do Cear´a, 2018.
[3] Tiago Gon¸calves, Ana Afonso, and Bruno Martins. Visualization techniques of trajectory data: Challenges and imitations. CEUR Workshop Proceedings, 1136, 01 2013.
[4] Yu Zheng. Trajectory data mining: An overview. ACM Transaction on Intelligent Systems and Technology, September 2015.
[5] Yu Zheng, Hao Fu, Xing Xie, Wei-Ying Ma, and Quannan Li. GeoLife User Guide 1.2. Microsoft Reasearch Asia, 2(April 2007):31–34, 2011
A capacidade de classificar e reconhecer certos tipos de dados vem sendo exigida em diversas aplicações modernas e, principalmente, onde o Big Data é usado para tomar todos os tipos de decisões, como no governo, na economia e na medicina. As tarefas de classificação também permitem que pesquisadores consigam lidar com a grande quantidade de dados as quais têm acesso.
Neste post, iremos explorar o que são essas tarefas de classificação, tendo como foco a classificação multi-label (multirrótulo) e como podemos lidar com esse tipo de dado. Todos os processos envolvidos serão bem detalhados ao longo do texto; na parte final da matéria vamos apresentar uma aplicação para que você possa praticar o conteúdo. Prontos? Vamos à leitura! 😉
Diferentes formas de classificar
Livrarias são em sua maioria lugares amplos, às vezes com um espaço para tomar café, e com muitos, muitos livros. Se você nunca entrou em uma, saiba que é um lugar bastante organizado, onde livros são distribuídos em várias seções, como ficção-científica, fotografia, tecnologia da informação, culinária e literatura. Já pensou em como deve ser complicado classificar todos os livros e colocá-los em suas seções correspondentes?
Não parece tão difícil porque esse tipo de problema de classificação é algo que nós fazemos naturalmente todos os dias. Classificação é simplesmente agrupar as coisas de acordo com características e atributos semelhantes. Dentro do Aprendizado de Máquina, ela não é diferente. Na verdade, a classificação faz parte de uma subárea chamada Aprendizado de Máquina Supervisionado, em que dados são agrupados com base em características predeterminadas.
Basicamente, um problema de classificação requer que os dados sejam classificados em duas ou mais classes. Se o problema possui duas classes, ele é chamado de problema de classificação binário, e se possui mais de duas classes, é chamado de problema de classificação multi-class (multiclasse). Um exemplo de um problema de classificação binário seria você escolher comprar ou não um item da livraria (1 para “livro comprado” e 0 para “livro não comprado”). Já foi citado aqui um típico problema de classificação multi-class: dizer a qual seção pertence determinado livro.
O foco deste post está em um variação da classificação multi-class: a classificação multi-label, em que um dado pode pertencer a várias classes diferentes. Por exemplo, o que fazer com um livro que trata de religião, política e ciências ao mesmo tempo?
Como lidar com dados multi-label
Bem, não sabemos com exatidão como as livrarias resolvem esse problema, mas sabemos que, para qualquer problema de classificação, a entrada é um conjunto de dados rotulado composto por instâncias, cada uma associada a um conjunto de labels (rótulos ou classes).
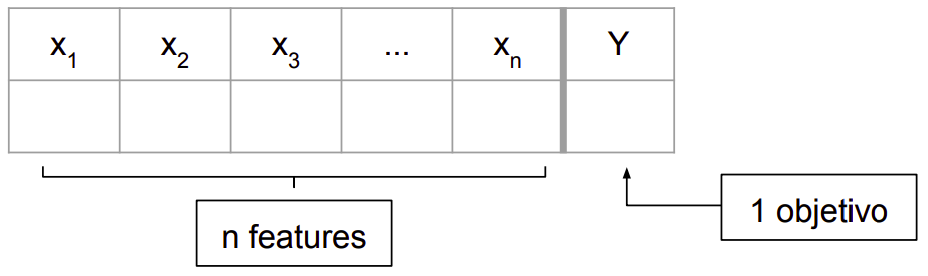
Conjunto de dados para um problema de classificação multi-class
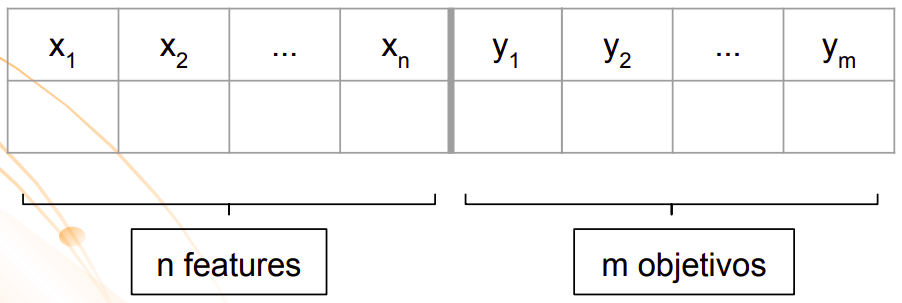
Conjunto de dados para um problema de classificação multi-label
Para que algo seja classificado, um modelo precisa ser construído em cima de um algoritmo de classificação. Tem como garantir que o modelo seja realmente bom antes mesmo de executar ele? Sim! É por isso que os experimentos para esse tipo de problema normalmente envolvem uma primeira etapa: a divisão dos dados em treino (literalmente o que será usado para treinar o modelo) e teste (o que será usado para validar o modelo).
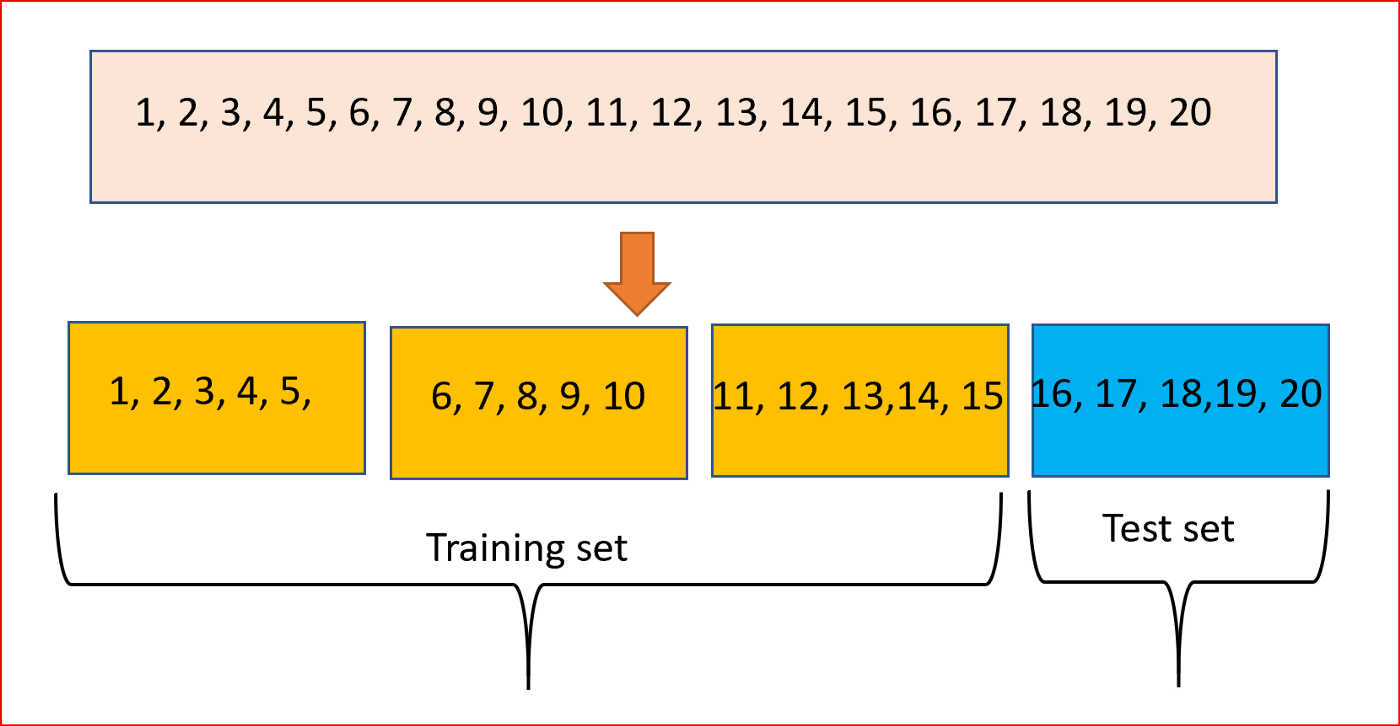
A forma como essa etapa é feita pode variar dependendo da quantidade total do conjunto de dados. Quando os dados são abundantes, utiliza-se um método chamado holdout, em que o dataset (conjunto de dados) é divididoem conjuntos de treino e teste e, às vezes, em um conjunto de validação. Caso os dados sejam limitados, a técnica utilizada para esse tipo de problema é chamada de validação cruzada (cross-validation), que começa dividindo o conjunto de dados em um número de subconjuntos de mesmo tamanho, ou aproximado.
Particionamento dos dados em 4 subconjuntos, 3 para o treino e 1 para o teste
Nas tarefas de classificação, geralmente é usada a versão estratificada desses dois métodos, que divide o conjunto de dados de forma que a proporção de cada classe nos conjuntos de treino e teste sejam aproximadamente iguais a de todo o conjunto de dados. Parece algo simples, mas os algoritmos que realizam esse procedimento o fazem de forma aleatória e não fornecem divisões balanceadas.
Além disso, essa distribuição aleatória pode levar à falta de uma classe rara (que possui poucas ocorrências) no conjunto de teste. A maneira típica como esses problemas são ignorados na literatura é através da remoção completa dessas classes. Isso, no entanto, implica que tudo bem se ignorar esse rótulo, o que raramente é verdadeiro, já que pode interferir tanto no desempenho do modelo quanto nos cálculos das métricas de avaliação.
Agora que a parte teórica foi explicada, vamos à parte prática! 🙂
Apresentação da biblioteca Scikit-multilearn
Sabia que existe uma biblioteca Python voltada apenas para problemas multi-label? Pois é, e ainda possui um nome bem sugestivo: Scikit-multilearn, tudo porque foi construída sob o conhecido ecossistema do Scikit-learn.
O Scikit-multilearn permite realizar diversas operações, mediante as implementações nativas do Python encontradas na biblioteca de métodos populares da classificação multi-label. Caso tenha curiosidade de saber tudo o que ela pode fazer, clique aqui.
A implementação da estratificação iterativa do Scikit-multilearn visa fornecer uma distribuição equilibrada das evidências das classes até uma determinada ordem. Para analisarmos o que isso significa, vamos carregar alguns dados.
Definição do problema
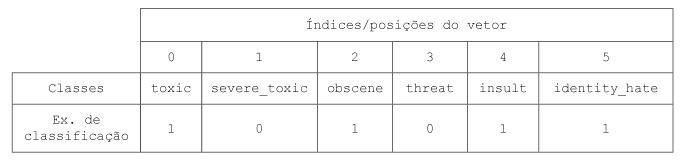
A competição Toxic Comment Classification do Kaggle se trata de um problema de classificação de texto, mais precisamente de classificação de comentários tóxicos. Os participantes devem criar um modelo multi-label capaz de detectar diferentes tipos de toxicidade nos comentários, como ameaças, obscenidade, insultos e ódio baseado em identidade.
Usaremos como conjunto de dados o conjunto de treino desbalanceado disponível na competição para ilustrar o problema de estratificação de dados multi-label. Esses dados contém um grande número de comentários do Wikipédia, classificados de acordo com os seguintes rótulos:
Avisamos que os comentários desse dataset podem conter texto profano, vulgar ou ofensivo, por isso algumas imagens apresentadas aqui estão borradas. O link para baixar o arquivo train.csv pode ser acessado aqui.
Análise exploratória
Inicialmente, iremos fazer uma breve análise dos dados de modo que possamos resumir as principais características do dataset. Todos os passos até a estratificação estão exemplificados abaixo, com imagens e exemplos em código Python. Se algum código estiver omitido, então alguns trechos são bastante extensos ou se tratam de funções pré-declaradas. Pedimos que acessem o código detalhado, disponível no GitHub, para um maior entendimento.
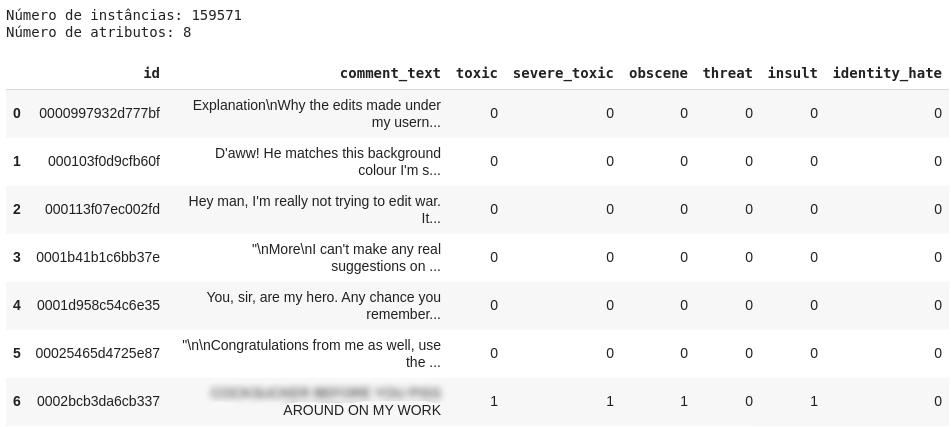
Primeiro, vamos carregar os dados do arquivo train.csv e checar os atributos.
df = pd.read_csv('train.csv')
print('Quantidade de instâncias: {}\nQuantidade de atributos: {}\n'.format(len(df), len(df.columns)))
df[0:7]
Percebe-se que cada label está representada como uma coluna, onde o valor 1 indica que o comentário possui aquela toxicidade e o valor 0 indica que não. Os 6 primeiros textos listados no dataframe não foram classificados em nenhum tipo de toxicidade. Na verdade, quase 90% desse dataset possui textos sem classificação. Não será um problema para nós, pois o método que iremos utilizar considera apenas as classificações feitas.
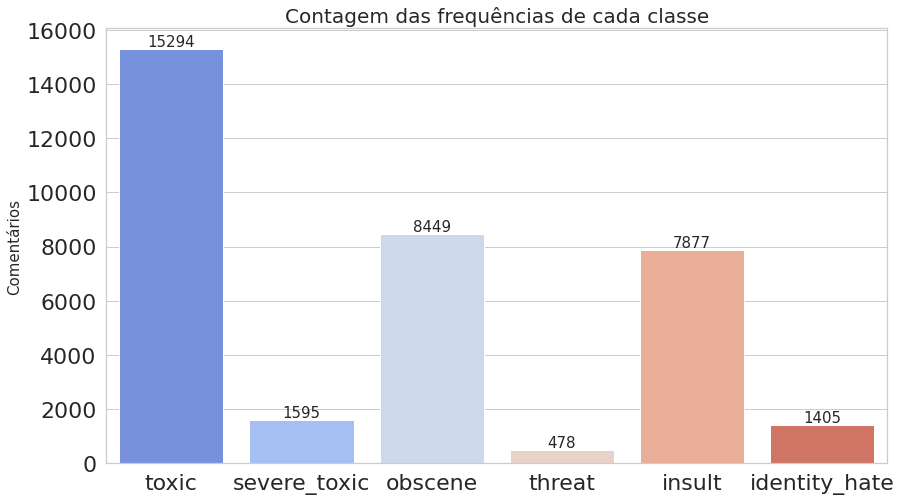
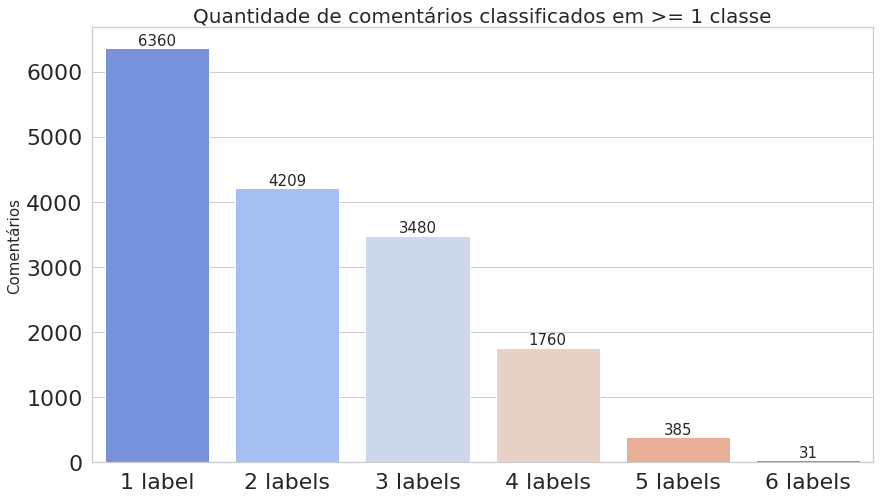
Agora, vamos computar as ocorrências de cada classe, ou seja, quantas vezes cada uma aparece, como também contar o número de comentários que foram classificados com uma ou mais classes. Já podemos notar na imagem acima do dataframe que o texto presente no índice 6 foi classificado como toxic, severe_toxic, obscene e insult.
labels = list(df.iloc[:, 2:].columns.values)
labels_count = df.iloc[:, 2:].sum().values
comments_count = df.iloc[:, 2:].sum(axis=1)
multilabel_counts = (comments_count.value_counts()).iloc[1:]
indexes = [str(i) + ' label' for i in multilabel_counts.index.sort_values()]
plot_histogram_labels(title='Contagem das frequências de cada classe', x_label=labels, y_label=labels_count, labels=labels_count)
plot_histogram_labels(title='Quantidade de comentários classificados em >= 1 classe', x_label=indexes, y_label=multilabel_counts.values, labels=multilabel_counts)
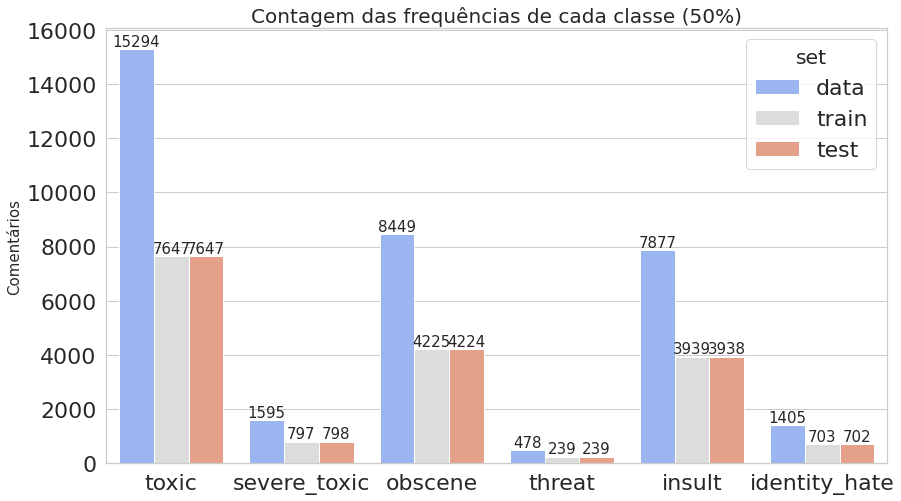
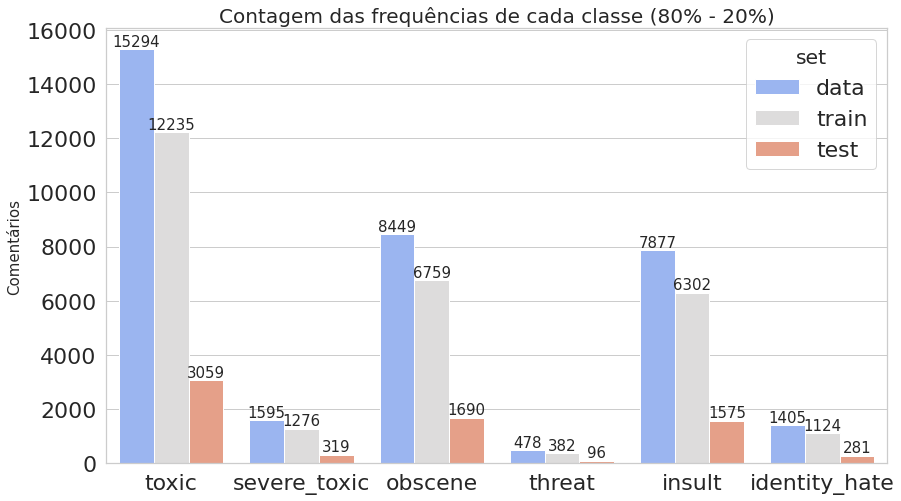
O primeiro gráfico mostra que o dataset é realmente desbalanceado, enquanto o segundo deixa claro que estamos trabalhando com dados multi-label.
Pré-processamento dos dados
O dataset não possui dados faltantes ou duplicados, e nem comentários nulos ou sem classificação (basta olhar como essa análise foi feita aqui no código completo). Apesar de não existirem problemas que podem interferir na qualidade dos dados, um pré-processamento ainda precisa ser feito, pois o intuito é seguir os mesmos passos geralmente realizados até a separação dos dados em treino e teste.
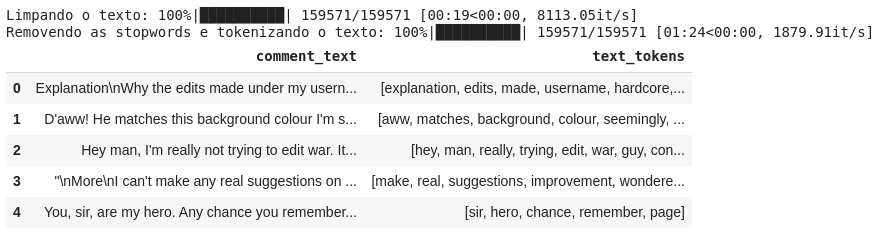
Para esse tipo de problema de classificação de texto, normalmente o pré-processamento envolve o tratamento e limpeza do texto (converter o texto apenas para letras minúsculas, remover as URLs, pontuação, números, etc.), e remoção das stopwords (conjunto de palavras comumente usadas em um determinado idioma). Devemos realizar esse tratamento para que possamos focar apenas nas palavras importantes.
tqdm.pandas(desc='Limpando o texto')
df['text_tokens'] = df['comment_text'].progress_apply(clean_text)
tqdm.pandas(desc='Removendo as stopwords e tokenizando o texto')
df['text_tokens'] = df['text_tokens'].progress_apply(remove_stopwords)
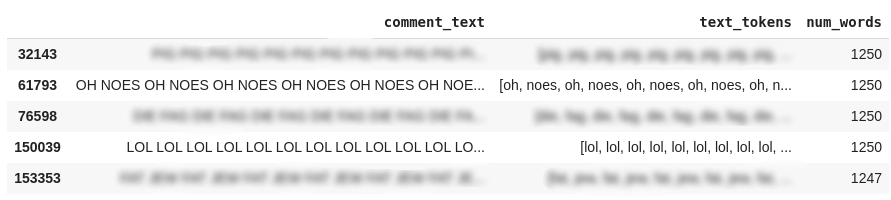
df[['comment_text', 'text_tokens']].head()
Como ilustrado na figura, também foi feito a tokenização do texto, um processo que envolve a separação de cada palavra (tokens) em blocos constituintes do texto, para depois convertê-los em vetores numéricos.
Processo de estratificação
Para divisão do conjunto de dados em conjuntos de treino e teste, usaremos o método iterative_train_test_splitda biblioteca Scikit-multilearn. Antes de prosseguir, esse método assume que possuímos as seguintes matrizes:
Devemos, então, fazer alguns tratamentos para obtermos o X e o y ideais para serem usados como entrada na função. Além disso, também passamos como parâmetro a proporção que desejamos para o teste (o restante será colocado no conjunto de treino). Esse método nos retornará a divisão estratificada do dataset(X_train, y_train, X_test, y_test).
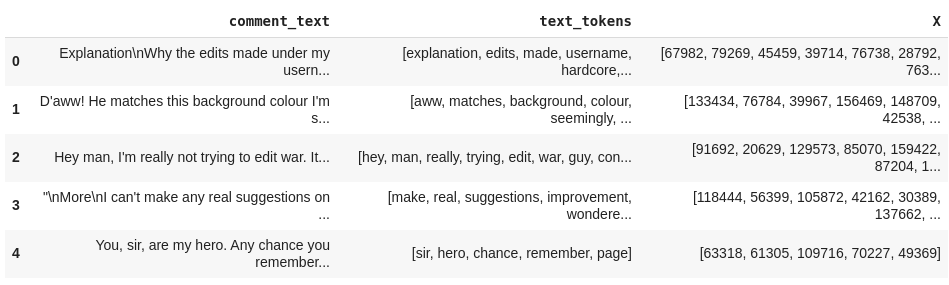
Inicialmente, iremos gerar o X. Até agora o que temos são os tokens do texto, então precisamos mapeá-los para transformá-los em números. Para isso, podemos pegar todas as palavras (tokens) presentes em text_tokens e atribuir a cada uma um id. Assim, criaremos uma espécie de vocabulário.
text_tokens = []
VOCAB = {}
for vet in df['text_tokens'].values:
text_tokens.extend(vet)
text_tokens_set = (list(set(text_tokens)))
for index, word in enumerate(text_tokens_set):
VOCAB[word] = index + 1
print('Quantidade de palavras presentes no texto: {}'.format(len(text_tokens)))
print('Tamanho do vocabulário (palavras sem repetição): {}\n'.format(len(text_tokens_set)))
VOCAB
Com esse vocabulário, conseguimos mapear as palavras para os id’s.
Como o X deve ter a dimensão (número_de_amostras, número_de_instâncias) e como o tamanho de alguns textos deve ser bem maior que de outros, temos que achar o texto com a maior quantidade de palavras e salvar seu tamanho. Depois, fazemos um padding (preenchimento) no restante dos textos, acrescentando 0’s no final de cada vetor até atingir o tamanho máximo estabelecido.
A matriz do y deve conter a dimensão (número_de_amostras, número_de_labels), então pegamos os valores das colunas referentes às classes. Atente para o fato de que cada posição dos vetores presentes em y corresponde a uma classe.
Outra forma de criação do y seria contar as ocorrências das classes para cada texto. Logo, ao invés de utilizar valores binários para indicar que existem palavras pertencentes ou não a um rótulo, colocaríamos os valores das frequências desses rótulos.
from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(maxlen=max_num_words, sequences=df['X'], value=0, padding='post', truncating='post')
y = df[labels].values
print('Dimensão do X: {}'.format(X.shape))
print('Dimensão do y: {}'.format(y.shape))
5. Pronto! Agora podemos fazer a divisão do dataset. Demonstraremos dois exemplos: dividir o dataset em 50% para treino e teste, e dividir em 80% para treino e 20% para teste.
from skmultilearn.model_selection import iterative_train_test_split
# 50% para cada
np.random.seed(42)
X_train, y_train, X_test, y_test = iterative_train_test_split(X, y, test_size=0.5)
# 80% para treino e 20% para teste
np.random.seed(42)
X_train_20, y_train_20, X_test_20, y_test_20 = iterative_train_test_split(X, y, test_size=0.2)
Os conjuntos de treino e teste estão realmente estratificados?
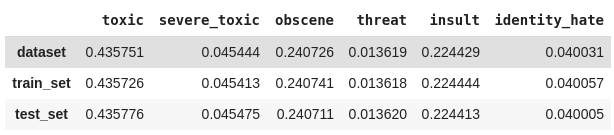
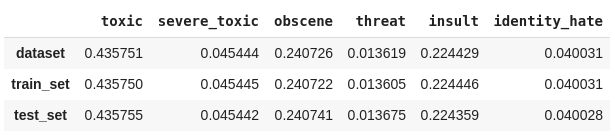
Por fim, iremos analisar se a proporção entre as classes foi realmente mantida.
Plotamos novamente os gráficos que contam quantas vezes cada classe aparece, comparando todo o conjunto de dados com os dados de treino e teste obtidos.
plot_histogram_labels('Contagem das frequências de cada classe (50%)', x_label='labels', y_label='ocorr', labels=classif_train_test, hue_label='set', data=inform_train_test)
plot_histogram_labels('Contagem das frequências de cada classe (80% - 20%)', x_label='labels', y_label='ocorr', labels=classif_train_test_20, hue_label='set', data=inform_train_test_20)
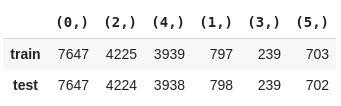
2. Podemos calcular manualmente a proporção das classes dividindo a quantidade de ocorrências de cada classe pelo número total de classificações. Também iremos verificar se a divisão está proporcional utilizando uma métricado Scikit-multilearn que retorna as combinações das classes atribuídas a cada linha.
from collections import Counter
from skmultilearn.model_selection.measures import get_combination_wise_output_matrix
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test, order=1) for combination in row)
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train_20, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test_20, order=1) for combination in row)
}).T.fillna(0.0)
É isso, gente. Esperamos que esse post tenha sido útil, principalmente para quem já enfrentou um problema parecido e não soube o que fazer.
Nem só de álcool gel e máscara consiste o kit quarentena. Hoje, vamos aproveitar a sexta-feira + quarentena para te indicar um novo livro: Learning Geospatial Analysis with Python: Understand GIS fundamentals and perform remote sensing data analysis using Python 3.7.
Dos dez capítulos, o autor, Joel Lawhead, dedica os três primeiros à ambientação dos leitores no cenário da Análise Geoespacial. Para a estruturação de desenvolvimento do tema, divide o campo em suas áreas específicas, como Sistema de Informações Geográficas (SIG), sensoriamento remoto, dados de elevação, modelagem avançada e dados em tempo real. A partir do capítulo 4, o autor inicia o aprofundamento da parte computacional, introduzindo o uso de ferramentas como NumPy, GEOS, Shapely e Python Imaging Library.
O foco do livro é fornecer uma “base sólida no uso da poderosa linguagem e estrutura Python para abordar a análise geoespacial de maneira eficaz”, como afirma o próprio autor. Para isso, Lawhead privilegia a aplicação do tema, sempre que possível, no ambiente Python. O esforço para se concentrar no Python, sem dependências, é um dos grandes diferenciais de “Learning Geospatial Analysis with Python” em relação aos outros materiais disponíveis sobre o assunto.
Veja a divisão do livro por capítulos:
1- Aprendendo sobre Análise Geoespacial com Python.
2- Aprendendo dados geoespaciais.
3- O cenário da tecnologia geoespacial.
4- Python Toolbox Geoespacial.
5- Sistema de Informações Geográficas e Python.
6- Python e Sensoriamento Remoto.
7- Python e Dados de Elevação.
8- Modelagem Geoespacial Avançada de Python.
9- Dados em tempo real.
10- Juntando tudo.
Conheça o autor*:
Joel Lawhead é um profissional de gerenciamento de projetos certificado pelo PMI, um profissional de GIS certificado e o diretor de informações da NVision Solutions Inc., uma empresa premiada especializada em integração de tecnologia geoespacial e engenharia de sensores para NASA, FEMA, NOAA, Marinha dos EUA , e muitas outras organizações comerciais e sem fins lucrativos.
*Trecho extraído de amazon.com.
Aproveita que está aqui com a gente e leia também:
12 bibliotecas do Python para análise de dados espaço-temporais (Parte 1) – (Parte 2)
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade