As redes neurais convolucionais (CNN) se utilizam de uma arquitetura especial que é particularmente bem adequada para classificar imagens. O uso dessa arquitetura torna as redes convolucionais rápidas de treinar, o que é vantajoso para trabalhar com redes profundas. Hoje, a CNN ,ou alguma variante próxima, é usada na maioria dos modelos para reconhecimento de imagem.
Neste artigo, vamos entender como criar e treinar uma (CNN) simples para classificar dígitos manuscritos de um conjunto de dados popular.


Figura 1: dataset MNIST ( imagem:en.wikipedia.org/wiki/MNIST_database)
Pré-requisito
Embora cada etapa seja detalhada neste tutorial, certamente quem já possui algum conhecimento teórico sobre o funcionamento da CNN será beneficiado. Além disso, é bom ter algum conhecimento prévio do TensorFlow2 , mas não é necessário.
Rede Neural Convolucional
Ao longo dos anos, o CNN se popularizou como técnica para a classificação de imagens para visões computacionais e tem sido usada nos domínios da saúde. Isso indica que o CNN é um modelo de deep learning confiável para uma previsão automatizada de ponta a ponta. Ele essencialmente extrai recursos ‘úteis’ de uma entrada fornecida automaticamente, facilitando nosso trabalho.
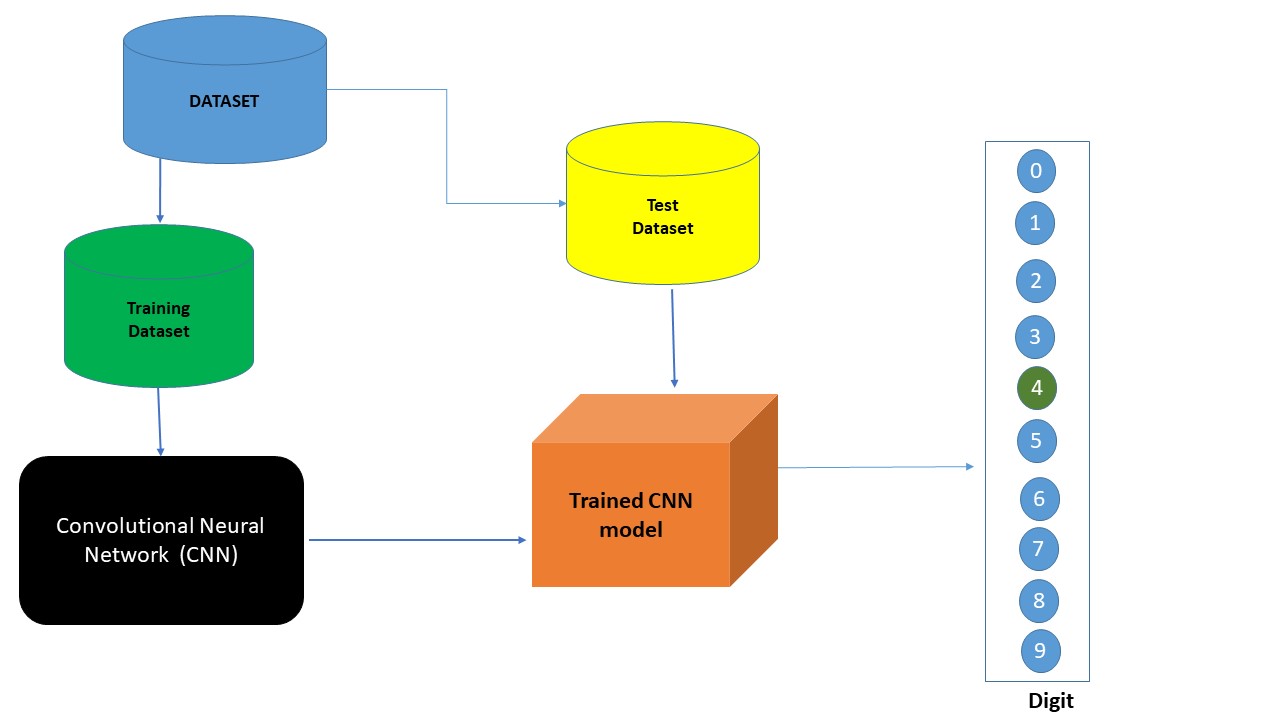

Figura 2: Processo end to end de CNN
Um modelo que utiliza CNN consiste, em suas versões mais simples, em três camadas principais: Camada Convolucional, Camada de Pooling e Camada Totalmente Conectada.
- Camada Convolucional: Esta camada extrai recursos de alto nível dos dados de entrada e os repassa para a próxima camada na forma de mapas de recursos.
- Camada de Pooling: É usada para reduzir as dimensões dos dados aplicando camadas de agrupamento (Pooling). Essa camada recebe cada saída do mapa de recursos da camada convolucional e prepara um mapa de características condensadas.
- Camada Totalmente Conectada: Finalmente, a tarefa de classificação é feita pela camada totalmente conectada. As pontuações de probabilidade são calculadas para cada rótulo de classe por uma função de ativação popularmente chamada de função softmax.
Dataset
O dataset que está sendo usado aqui é o de classificação de dígitos MNIST. O Keras é uma API de deep learning escrita em Python e ele traz consigo o MNIST. Este conjunto de dados consiste em 60.000 imagens de treinamento e 10.000 imagens de teste, o que o torna ideal para quem precisa experimentar o reconhecimento de padrões, pois ele é executado em apenas um minuto.
Quando a API do Keras é chamada, quatro valores são retornados. São eles:
x_train,
y_train,
x_test,
y_test .
Não se preocupe, você será orientado(a) sobre isso.
Carregando o dataset
A linguagem usada aqui é Python. Vamos usar o Google Colab para escrever e executar o código. Você também pode escolher um Jupyter notebook. o Google Colab foi escolhido aqui por fornecer acesso fácil a notebooks a qualquer hora e em qualquer lugar. Também é possível conectar um notebook Colab a um repositório GitHub. Você pode aprender mais sobre o Google Colab aqui.
Além disso, o código usado neste tutorial está disponível neste repositório Github. Portanto, se você se sentir confuso em alguma fase, verifique esse repositório. Para manter este tutorial relevante para todos, explicaremos o código mais crítico.
- Crie e nomeie um notebook.
- Depois de carregar as bibliotecas necessárias, carregue o dataset MNIST conforme mostrado abaixo:
(X_train,y_train),(X_test,y_test)=keras.datasets.mnist.load_data()
Como discutimos anteriormente, este conjunto de dados retorna quatro valores e na mesma ordem mencionada acima: x_train, y_train, x_test e y_test , que são representações para datasets divididos em treinamento e teste.
Muito bem! Você acabou de carregar seu dataset e está pronto para passar para a próxima etapa, que é processar os dados.
Processando o dataset
Os dados devem ser processados e limpos para melhorar sua qualidade. Para que a CNN aprenda é preciso que o dataset não contenha nenhum valor nulo, que tenha todos os dados numéricos e que seja normalizado. Então, aqui vamos realizar algumas etapas para garantir que tudo esteja perfeitamente adequado para um modelo CNN aprender. Daqui em diante, até criarmos o modelo, trabalharemos apenas no dataset de treinamento.
Se você escrever X_train[0], obterá a 0ª imagem com valores entre 0-255, representando a intensidade da cor (preto ao branco). A imagem é uma matriz bidimensional. É claro, não saberemos o que o dígito manuscrito X_train[0] representa, para saber isso escreva y_train[0] e você obterá 5 como saída. Isso significa que a 0ª imagem deste dataset de treinamento representa o número 5.
Vamos normalizar este dataset de treinamento e de teste, colocando os valores entre 0 e 1 conforme mostrado abaixo:
X_train=X_train/255
X_test=X_test/255
Em seguida, precisamos redimensionar a matriz para se adequar a API do Keras. Ela espera que cada entrada tenha 3 dimensões: uma pra linha, uma para a coluna e uma para a cor. Normalmente, essa 3ª dimensão é usada quando trabalhamos com imagens coloridas e temos múltiplos canais de cor (ex: RGB). Porém, como trabalhamos com imagens monocromáticas, essa terceira dimensão terá apenas um elemento.
X_train=X_train.reshape(-1,28,28,1) #conjunto de treinamento
X_test=X_test.reshape(-1,28,28,1) #conjunto de teste
Agora que está tudo em ordem, é hora de criarmos uma rede neural convolucional.
Criação e treinamento de uma CNN
Vamos criar um modelo CNN usando a biblioteca TensorFlow. O modelo é criado da seguinte maneira:
convolutional_neural_network=models.Sequential([ layers.Conv2D(filters=25,kernel_size=(3,3),activation='relu',input_shape=(28,28,1)), layers.MaxPooling2D((2,2)), layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu'), layers.MaxPooling2D((2,2)), layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu'), layers.MaxPooling2D((2, 2)), layers.Flatten(), layers.Dense(64,activation='relu'), layers.Dense(10,activation='softmax')] )
Reserve algum tempo para permitir que todo o código seja absorvido. É importante que você entenda cada parte dele. No modelo CNN criado acima, há uma camada CNN de entrada, seguida por duas camadas CNN ocultas, uma camada densa oculta e, finalmente, uma camada densa de saída. Em termos mais simples, as funções de ativação são responsáveis por tomar decisões de passar o que foi identificado adiante ou não. Em uma rede neural profunda como a CNN, existem muitos neurônios e, com base nas funções de ativação, os neurônios disparam e a rede avança. Se você não entende muito sobre as funções de ativação use ‘relu’, pois ele é mais popular devido sua versatilidade.
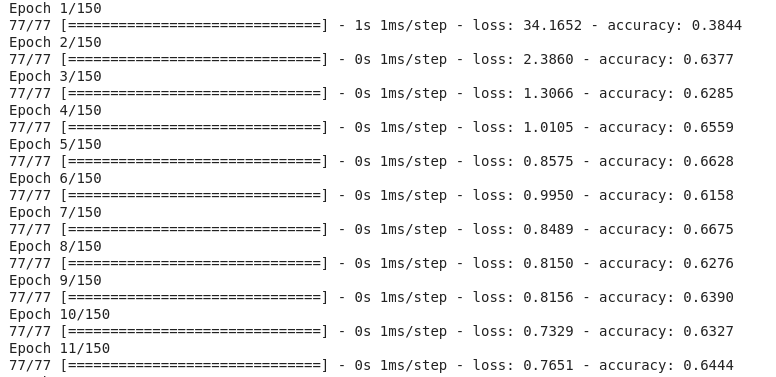
Uma vez que o modelo foi criado, é hora de compilá-lo e treiná- lo . Durante o processo de treino, o modelo percorrerá o dataset e aprenderá os padrões. Ele treinará quantas vezes for definido (as chamadas épocas). Em nosso exemplo, definimos 10 épocas. Durante o processo, o modelo da CNN vai aprender e também cometer erros. Para cada erro (previsões erradas) que o modelo comete, há uma penalidade (ou um custo) e isso é representado no valor da perda (loss) para cada época (veja o GIF abaixo). Resumindo, o modelo deve gerar o mínimo de perda e a maior precisão possível no final da última época.
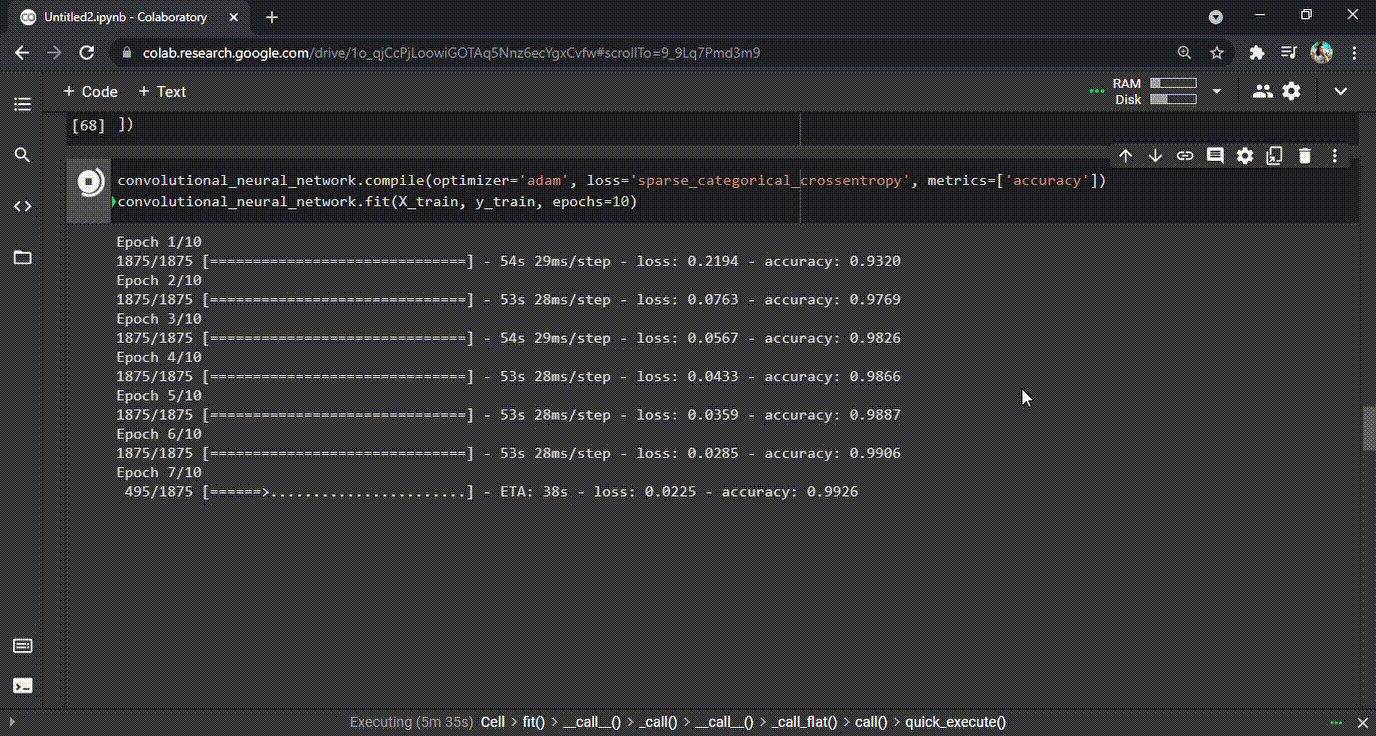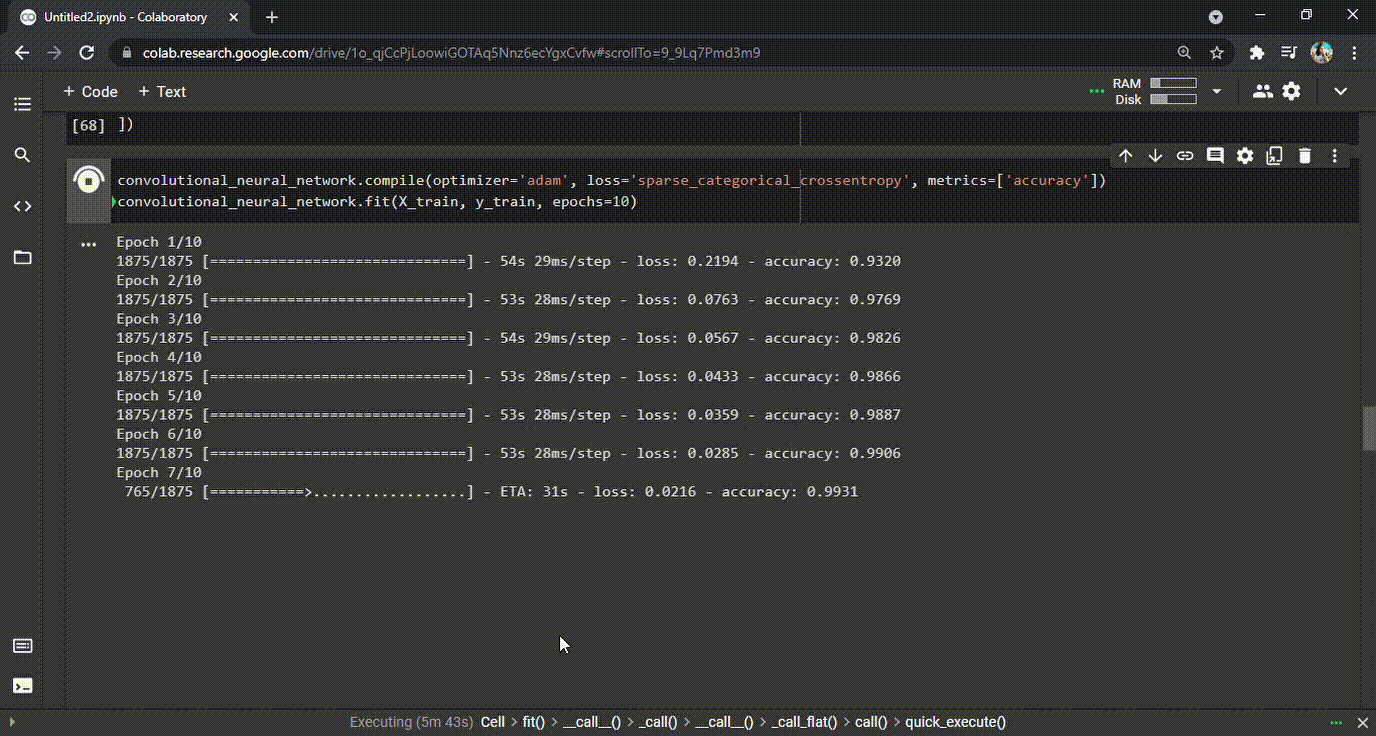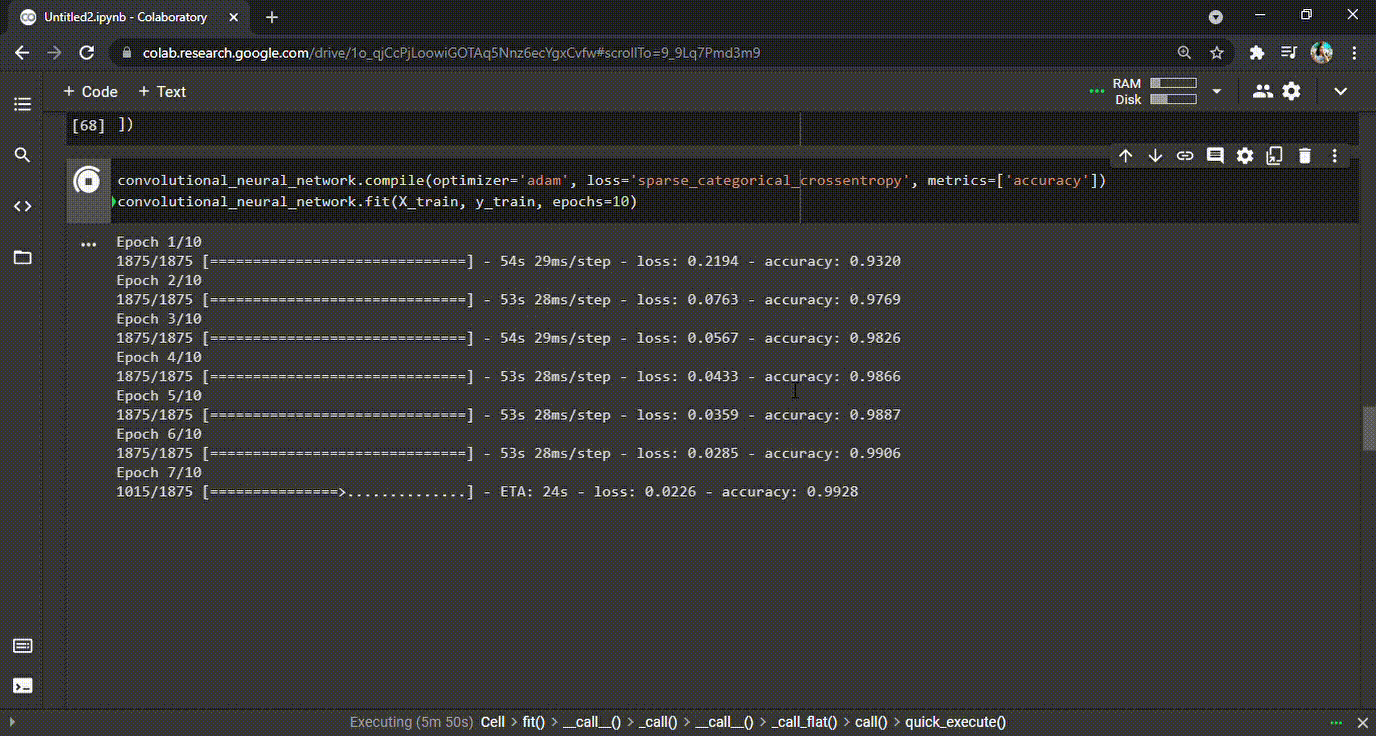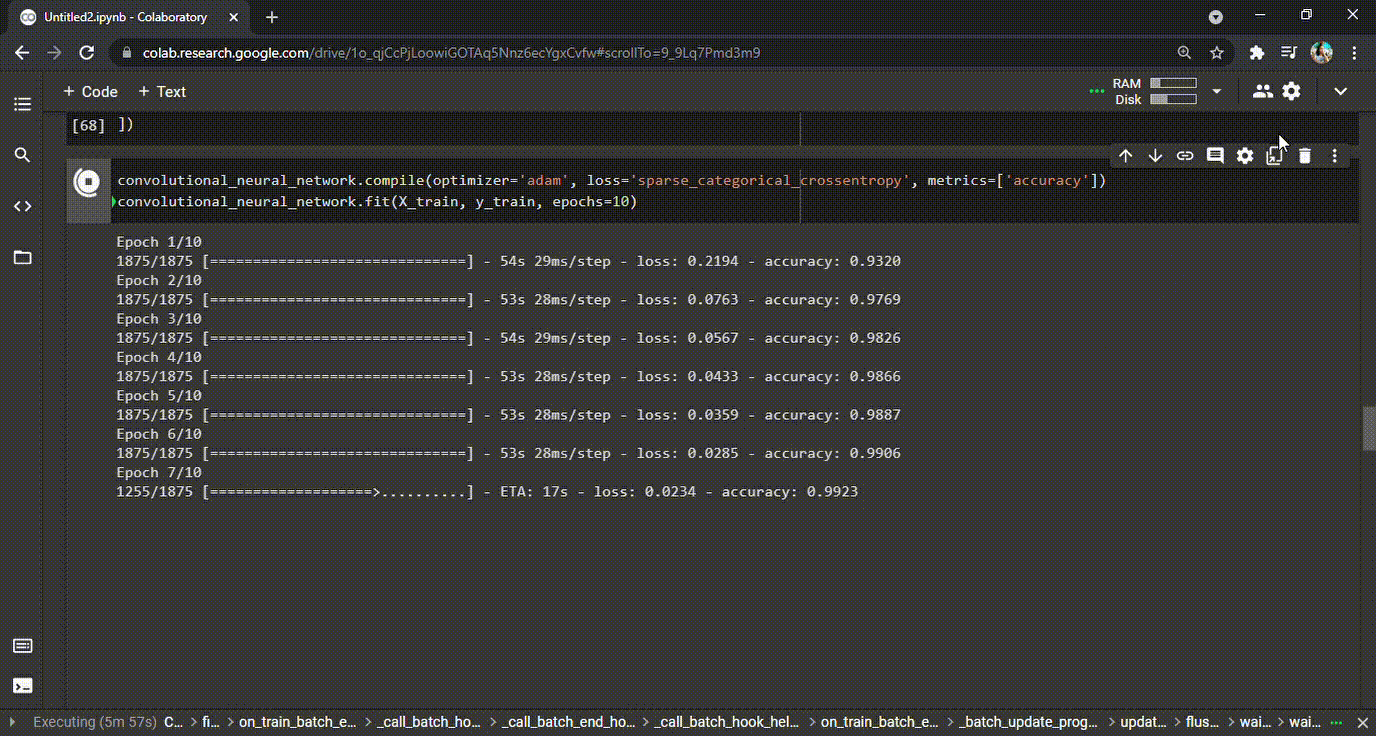

Modelo de treinamento | classificação de dígitos manuscritos CNN
GIF 1: Treinamento CNN e as precisões aprimoradas durante cada época
Fazendo previsões
Para avaliar o modelo CNN assim criado, você pode executar:
convolutional_neural_network.evaluate(X_test,y_test)
É hora de usar nosso conjunto de testes para ver o desempenho do modelo CNN.
y_predicted_by_model=convolutional_neural_network.predict(X_test)
O código acima usará o modelo convolutional_neural_network para fazer previsões para o conjunto de teste e armazená-lo no dataframe y_predicted_by_model. Para cada um dos 10 dígitos possíveis, uma pontuação de probabilidade será calculada. A classe com a pontuação de probabilidade mais alta é a previsão feita pelo modelo. Por exemplo, se você quiser ver qual é o dígito na primeira linha do conjunto de teste:
y_predicted_by_model[0]
A saída será mais ou menos assim:
array([3.4887790e-09,3.4696127e-06,7.7428967e-07,2.9782784e-08,6.3373392e-08,6.1983449e-08,7.4500317e-10,9.9999511e-01,4.2418694e-08,3.8616824e-07],dtype=float32)
Como é realmente difícil identificar o rótulo da classe de saída com a pontuação de probabilidade mais alta, vamos escrever outro código:
np.argmax(y_predicted[0])
E com isso, você obterá um dos dez dígitos como saída (0 a 9). Para saber a representação direta do dígito, aplique o resultado do argmax nas classes do modelo.
Em suma
Após aprender como um dataset é dividido em treinamento e teste, utilizando o MNIST para fazer previsões de dígitos manuscritos de 0 a 9, criamos um modelo CNN treinado no dataset de treinamento. Por fim, com o modelo treinado, as previsões são realizadas.
Incentivamos você a experimentar por conta própria a ajustar os hiperparâmetros do modelo na expectativa de saber se eles são capazes de alcançar precisões mais altas ou não. Se você quer aprender sempre mais, acompanhe esta aula de Redes Neurais Convolucionais. Ficamos felizes em colaborar com a sua aprendizagem!
Referências
- Equipe, K. (nd). Documentação Keras: conjunto de dados de classificação de dígitos MNIST. Keras. https://keras.io/api/datasets/mnist/.
- manav_m. (2021, 1º de maio). CNN para Aprendizado Profundo: Redes Neurais Convolucionais (CNN). Analytics Vidhya. https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/.
- YouTube. (2020, 14 de outubro). Explicação simples da rede neural convolucional | Tutorial de aprendizado profundo 23 (Tensorflow e Python). YouTube. https://www.youtube.com/watch?v=zfiSAzpy9NM&list=PLeo1K3hjS3uvCeTYTeyfe0-rN5r8zn9rw&index=61.
Artigo traduzido Analytics Vidhya : Classification of Handwritten Digits Using CNN.
Fonte de pesquisa: Deep Learning Book