Yuval Noah Harari, conhecido por suas obras amplamente discutidas como Sapiens e Homo Deus, oferece em Nexus: Uma breve história das redes de informação, da Idade da Pedra à inteligência artificial uma abordagem profunda e esclarecedora sobre o papel das redes de informação na evolução da humanidade. Combinando a narrativa histórica com a análise de dados, Harari explora como a comunicação e o compartilhamento de informações moldaram civilizações e continuam a influenciar o mundo atual, em especial com a ascensão da inteligência artificial.
Redes de Informação: da Pré-História ao digital
Harari traça o desenvolvimento das redes de informação desde as primeiras formas de comunicação entre tribos nômades, passando pela invenção da escrita, até os sistemas modernos de comunicação digital. Ele argumenta que o compartilhamento de informações sempre foi uma peça-chave para a evolução social e tecnológica. As civilizações que dominaram a criação e manutenção de redes eficientes prosperaram, enquanto aquelas que não conseguiram acompanhar ficaram para trás. No contexto contemporâneo, Harari destaca o impacto das plataformas digitais e algoritmos, que organizam e distribuem uma quantidade colossal de dados diariamente.
A ascensão da Inteligência Artificial e o futuro das redes
Um ponto central do livro é a análise de como a inteligência artificial está redefinindo as redes de informação. Harari aborda o conceito de que as IAs, além de processar dados de maneira mais eficiente, também estão moldando como interagimos com a informação, afetando a privacidade, a autonomia e as tomadas de decisão em diversas áreas, como saúde, trabalho e política. Ele sugere que o domínio das redes de IA pode se tornar o próximo grande diferencial de poder entre nações e corporações no século XXI.
Impacto para o futuro da Ciência de Dados
Para pesquisadores e profissionais da área de ciência de dados, Nexus oferece insights valiosos sobre a evolução histórica e as possíveis tendências futuras da coleta e análise de dados. O livro reforça a importância do entendimento não só das ferramentas e técnicas envolvidas, mas também das implicações sociais e éticas que acompanham a manipulação de grandes volumes de informação.
Yuval Noah Harari em Nexus nos convida a refletir sobre a importância crescente das redes de informação e como a humanidade tem moldado e sido moldada por elas ao longo dos milênios. Com uma narrativa rica e acessível, o livro é uma leitura essencial para todos que desejam entender o papel dos dados e da inteligência artificial no futuro da sociedade global. O livro traz reflexões cruciais sobre o uso ético e estratégico dos dados no desenvolvimento de tecnologias que podem impactar a vida cotidiana.
Quando o ChatGPT foi lançado, as pessoas ficaram impressionadas com as possibilidades que ele oferecia, desde a escrita de um simples e-mail até o desenvolvimento de códigos complexos. A inauguração da ferramenta marcou um grande avanço na inteligência artificial, superando expectativas com sua habilidade de gerar respostas mais precisas e contextualmente relevantes.
Mas no fervilhante e imparável mundo da inteligência artificial, diversas ferramentas têm surgido como alternativas ao ChatGPT, cada uma com suas características e benefícios específicos.
Neste artigo vamos explorar algumas das melhores opções disponíveis em 2024, destacando suas funcionalidades, integrações e diferenças principais. Se você está procurando uma IA que se integre perfeitamente ao ecossistema do Google, uma ferramenta poderosa para criação de conteúdo, ou uma solução focada em privacidade, aqui você encontrará a alternativa ideal para suas necessidades.
Google Gemini (anteriormente Bard)
Esta IA se destaca por integrar-se ao ecossistema do Google. Gemini aproveita o vasto conjunto de dados e capacidades de pesquisa do Google, tornando-se uma ferramenta poderosa para aqueles que usam Google Docs, Sheets, Gmail e Slides, por exemplo. As principais funcionalidades incluem entrada por voz e integração com serviços do Google. No entanto, enfrenta dificuldades em oferecer respostas criativas e realizar tarefas de raciocínio complexo.
Microsoft Copilot
Incorporado no Windows 11 e no Edge, o Copilot utiliza o GPT-4 em combinação com a pesquisa do Bing. Oferece acesso em tempo real à internet, geração de imagens e resultados interativos. É especialmente útil para usuários do ecossistema Microsoft. As principais desvantagens incluem anúncios ocasionais nas respostas e dificuldade de acessar o histórico de conversas.
Claude 3
Desenvolvido pela Anthropic, o Claude oferece interações complexas e sensíveis ao contexto. Entre suas habilidades, suporta o upload e a análise de documentos. O Claude se destaca na escrita criativa e na manutenção de um estilo consistente, mas carece de recursos avançados como geração de imagens e interpretação de código.
Writesonic
Focado na criação de conteúdo, o Writesonic fornece conteúdo otimizado para SEO para blogs, anúncios e postagens em redes sociais. Executado no GPT-4, oferece funcionalidades como geração de imagens e conversas baseadas em tendências, sendo ideal para equipes de marketing. Os problemas incluem consistência de memória.
Meta AI
Utilizando o modelo Llama 3, o Meta AI está disponível em plataformas como WhatsApp, Instagram e Messenger. Suporta geração de imagens e tem um bom desempenho em várias tarefas, mas está limitado a certas regiões e requer uma conta no Facebook.
ClickUp Brain
Integrado na plataforma ClickUp, esta ferramenta de IA é projetada para gestão de projetos e contextos empresariais. Oferece funcionalidades de IA baseadas em funções, resumos de tarefas e perguntas e respostas contextuais, sendo uma ferramenta valiosa para equipes. Está disponível em planos pagos e respeita controles de acesso rigorosos.
AnonChatGPT
Oferece acesso anônimo ao ChatGPT sem necessidade de login. Encaminha prompts para os servidores da OpenAI, proporcionando os benefícios básicos do ChatGPT sem compartilhar informações pessoais. No entanto, só é possível manter uma conversa por vez e necessita de recursos avançados como acesso à internet.
Copy.ai
Conhecido pela sumarização de texto, o Copy.ai é útil para processar textos longos, gerar ideias de conteúdo e escrever descrições para redes sociais. Suporta vários idiomas e oferece planos gratuitos e pagos. A ferramenta é robusta, mas possui uma curva de aprendizado.
Character.AI
Melhor para conversas baseadas em personagens, esta ferramenta permite que os usuários interajam com chatbots inspirados em livros e outros meios. Salva o histórico de conversas com cada personagem e pode ser usada sem uma conta. No entanto, é menos prática para tarefas gerais.
Principais Diferenças
Cada uma das ferramentas apresentadas aqui têm pontos fortes distintos, o que faz com que a necessidade do usuário defina qual a melhor ferramenta. Veja a seguir qual a melhor inteligência artificial em diferentes contextos.
Integração com Ecossistemas: Google Gemini e Microsoft Copilot se destacam pela integração perfeita com seus respectivos ecossistemas, sendo ideais para usuários já investidos em produtos Google ou Microsoft.
Criação de Conteúdo: Writesonic se destaca na geração de conteúdo otimizado para SEO para fins de marketing, enquanto Copy.ai foca na sumarização de texto e criação de conteúdo para redes sociais.
Acesso Anônimo e Simplificado: AnonChatGPT oferece uma vantagem única para usuários que priorizam privacidade e simplicidade, permitindo acesso sem necessidade de conta.
Interações Criativas e Baseadas em Personagens: Character.AI e Claude 3 são mais adequados para escrita criativa e interações baseadas em personagens, oferecendo uma experiência conversacional mais personalizada.
Gestão de Projetos e Contextos Empresariais: ClickUp Brain fornece funcionalidades de IA específicas para negócios, sendo útil para gestão de projetos e colaboração em equipe.
Versatilidade Geral: ChatGPT permanece uma opção versátil, continuamente atualizada para lidar com uma ampla gama de tarefas, desde conversas casuais até a resolução de problemas complexos.
Essas alternativas atendem a diferentes necessidades, permitindo que os usuários escolham com base em seus requisitos específicos e preferências de ecossistema.
O Insight está com inscrições abertas para bolsistas de mestrado e doutorado para o projeto de pesquisa Anamnese Assistida por Inteligência Artificial. Venha fazer parte do nosso time e contribuir com o desenvolvimento de tecnologias de ponta aplicadas aos problemas da sociedade e das organizações.
Os bolsistas serão selecionados por mérito acadêmico, tendo em vista o perfil esperado e os requisitos necessários para realização da pesquisa.
Projeto Anamnese Assistida por Inleligência Artificial do Centro de Referência em Inteligência Artificial (CEREIA).
O objetivo do centro é desenvolver pesquisas voltadas ao uso da inteligência artificial para a resolução de problemas na área da saúde, bem como promover a formação de profissionais para atender esse mercado. O CEREIA foi inaugurado no dia 20 de março pela FAPESP e o Grupo Hapvida NotreDame Intermédica e ocupará uma área de 380 metros quadrados no quinto andar do Condomínio de Empreendedorismo e Inovação da UFC.
No Brasil são realizadas mais de um bilhão de consultas médicas por ano. Neste contexto, anamnese é uma atividade essencial no atendimento médico. Nela são investigados e documentados episódios e fatos relacionados ao paciente, resumindo suas queixas e provendo um ponto inicial para um diagnóstico e por conseguinte um tratamento. Na maioria dos ambientes de atendimento ao paciente, a anamnese é feita de maneira rudimentar: a investigação depende exclusivamente da habilidade do profissional, a documentação é feita através de textos livres e desestruturados e o possível diagnóstico é também manual e dependente do conhecimento do profissional.
As informações da anamnese e exames complementares são importantes para possíveis diagnósticos. O reconhecimento de padrões (pattern recognition) e de critérios de diagnóstico (combinação de sintomas, sinais e resultados de exames) é usado na determinação de um diagnóstico correto. Dessa forma, é essencial a concepção e o desenvolvimento de soluções baseadas em inteligência artificial para auxiliar os profissionais da área da saúde com o objetivo de melhorar o atendimento e a segurança do paciente, assim como reduzir custos.
Sediado na Universidade Federal do Ceará, grupo pretende desenvolver projetos voltados à aplicação de internet das coisas, big data, transformação digital e tecnologias de ponta na prevenção, diagnóstico e terapias de baixo custo (foto: divulgação/Hapvida NotreDame Intermédica)
Número de Vagas
2 bolsas para Mestrado;
1 bolsa para Doutorado;
Período de duração da bolsa
Até 24 meses para bolsa de mestrado e até 48 meses para bolsa de doutorado
Venha fazer parte do time Insight! Estão abertas as inscrições para o processo seletivo destinado à contratação de Designer para atuar no Projeto CEIAS/CRIA HEALTH & WELL-BEING.
Quem somos?
O Insight Lab é um laboratório de pesquisa aplicada em Ciência de Dados e Inteligência Artificial da Universidade Federal do Ceará, envolvendo mais de 100 pessoas, entre pesquisadores, alunos de graduação, mestrado, doutorado e especialistas associados.
O que é o projeto?
O projeto CEIAS/CRIA HEALTH & WELL-BEING é fruto da parceria entre o Insight Data Science Lab, a Fundação Cetrede, o Centro de Referência em Inteligência Artificial (Cria) e a Samsung, e tem como objetivo promover soluções tecnológicas no âmbito da inteligência artificial aplicada à saúde.
Qual o perfil dos nossos colaboradores?
Procuramos por pessoas
com paixão por criar, aprender e testar novas tecnologias;
altamente criativas e curiosas sobre os assuntos, produtos, serviços e pesquisas científicas do Insight Lab;
que tenham habilidades interpessoais e de comunicação;
que trabalharem bem em equipe e com uma gama de pessoas criativas;
que saibam gerenciar demandas de trabalho de forma eficaz e organizada;
Vagas disponíveis
Temos uma vaga para Designer, além de cadastro de reserva.
Você será responsável por
Planejar e elaborar as interfaces dos sistemas e experiência dos usuários.
Modalidade de Contratação
CLT / Home Office
Carga Horária
40 horas semanais
Etapas da seleção
Envio de currículo para pré-seleção
11/04/23 a 13/04/23
Entrevista online
14/04/23 a 17/04/23
Resultado
18/04/23
Perfil da vaga
Procuramos por pessoas
Altamente criativas e curiosas sobre os assuntos, produtos, serviços e pesquisas científicas abordadas no Insight Lab;
Que saibam trabalhar bem em equipe e com uma gama de pessoas criativas;
Que saibam gerenciar demandas de trabalho de forma eficaz e organizada;
Autônomas, autogerenciáveis e proativas.
Requisitos
Usabilidade;
Experiência com UI/UX;
Prototipação de alta fidelidade;
Análise Heurística;
Mindset focado no cliente;
Conhecimentos em técnicas de linguagem simples.
Você deve possuir conhecimentos nas seguintes ferramentas:
Adobe XD, Illustrator, Figma, Sketch ou similares;
Zeplin.
Você se destacará se:
Tiver experiência com desenvolvimento mobile.
Inscrição
Interessado(a)? Acesse o link do formulário para registrar seus dados e enviar seu currículo aqui.
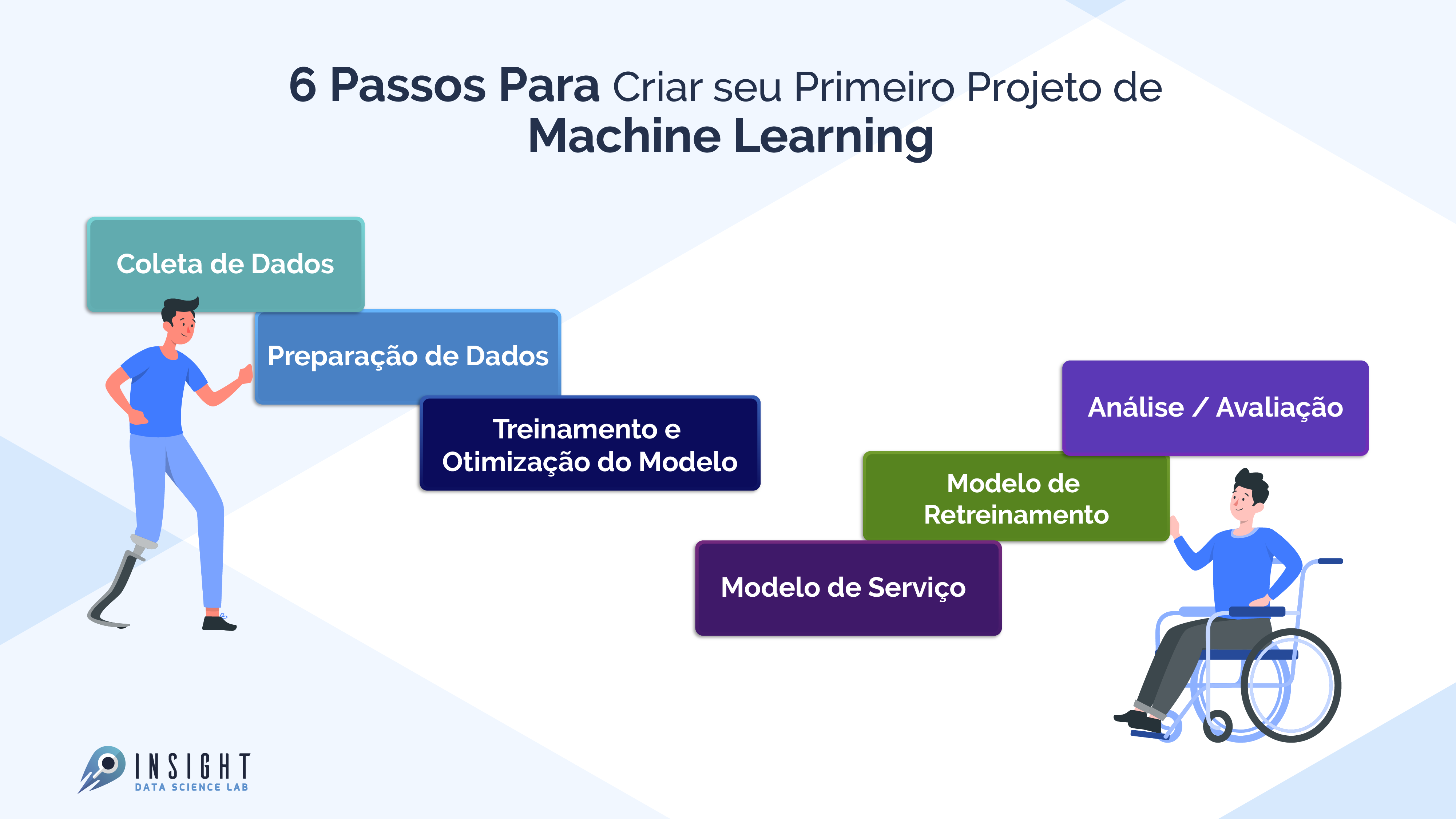
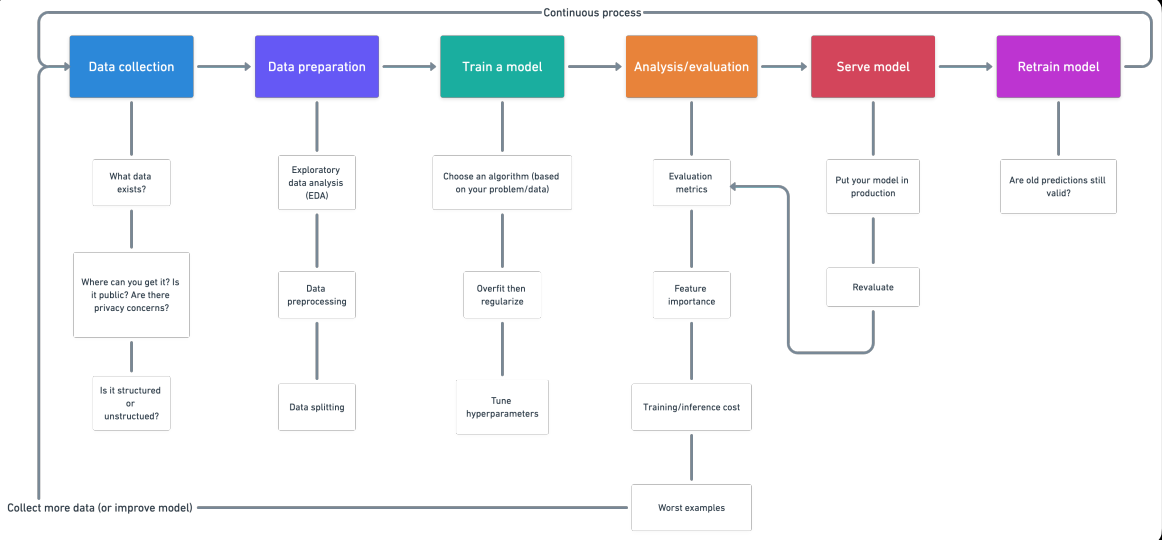
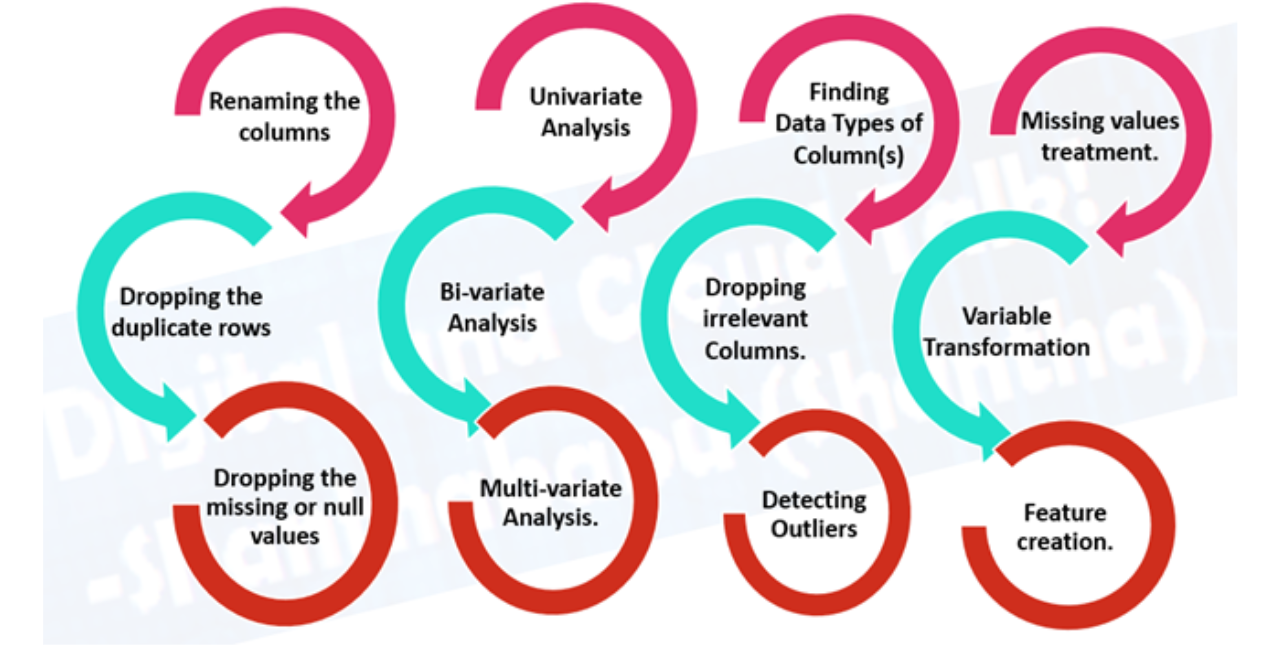
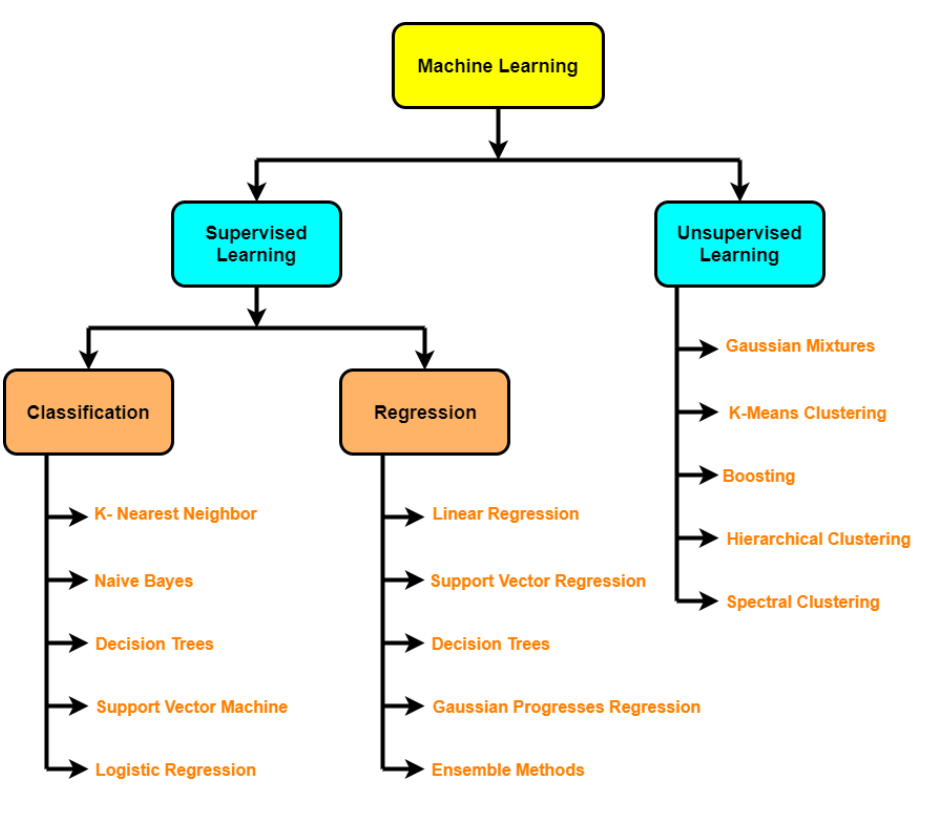
Aqui você verá as várias etapas envolvidas em um projeto de Machine Learning (ML). Existem etapas padrões que você deve seguir para um projeto de Ciência de Dados. Para qualquer projeto, primeiro, temos que coletar os dados de acordo com nossas necessidades de negócios. A próxima etapa é limpar os dados como remover valores, remover outliers, lidar com conjuntos de dados desequilibrados, alterar variáveis categóricas para valores numéricos, etc.
Depois do treinamento de um modelo, use vários algoritmos de aprendizado de máquina e aprendizado profundo. Em seguida, é feita a avaliação do modelo usando diferentes métricas, como recall, pontuação f1, precisão, etc. Finalmente, a implantação do modelo na nuvem e retreiná-lo. Então vamos começar:
Fluxo de trabalho do projeto de Aprendizado de Máquina
1. Coleta de dados
Perguntas a serem feitas:
Que problema deve ser resolvido?
Que dados existem?
Onde você pode obter esses dados? São públicos?
Existem preocupações com a privacidade?
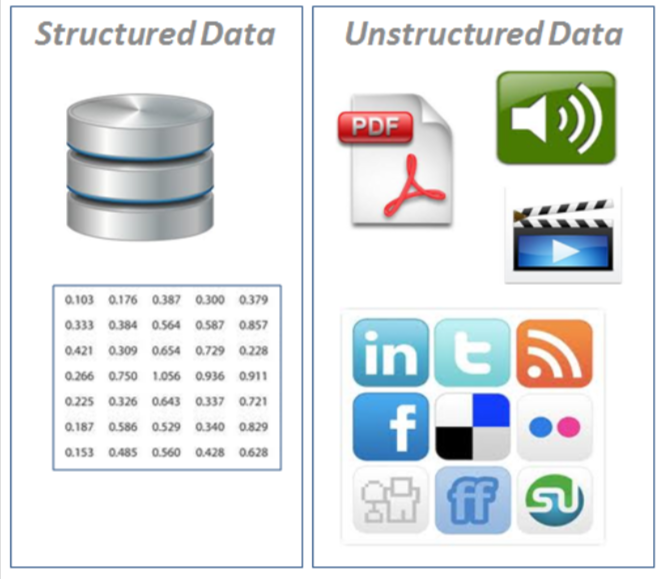
É estruturado ou não estruturado?
Tipos de dados
Dados estruturados: aparecem em formato tabular (estilo linhas e colunas, como o que você encontraria em uma planilha do Excel). Ele contém diferentes tipos de dados, por exemplo: numéricos, categóricos, séries temporais.
Nominal / categórico – Uma coisa ou outra (mutuamente exclusivo). Por exemplo, para balanças de automóveis, a cor é uma categoria. Um carro pode ser azul, mas não branco. Um pedido não importa.
Numérico: qualquer valor contínuo em que a diferença entre eles importa. Por exemplo, ao vender casas o valor de R$ 107.850,00 é maior do que R$ 56.400,00.
Ordinal: Dados que têm ordem, mas a distância entre os valores é desconhecida. Por exemplo, uma pergunta como: como você classificaria sua saúde de 1 a 5? 1 sendo pobre, 5 sendo saudável. Você pode responder 1,2,3,4,5, mas a distância entre cada valor não significa necessariamente que uma resposta de 5 é cinco vezes melhor do que uma resposta de 1.
Séries temporais: dados ao longo do tempo. Por exemplo, os valores históricos de venda de Bulldozers de 2012-2018.
Dados não estruturados: dados sem estrutura rígida (imagens, vídeo, fala, texto em linguagem natural)
2. Preparação de dados
2.1 Análise Exploratória de Dados (EDA), aprendendo sobre os dados com os quais você está trabalhando
Quais são as variáveis de recursos (entrada) e as variáveis de destino (saída)? Por exemplo, para prever doenças cardíacas, as variáveis de recursos podem ser a idade, peso, frequência cardíaca média e nível de atividade física de uma pessoa. E a variável de destino será a informação se eles têm ou não uma doença.
Que tipo de dado você tem? Estruturado, não estruturado, numérico, séries temporais. Existem valores ausentes? Você deve removê-los ou preenchê-los com imputação de recursos.
Onde estão os outliers? Quantos deles existem? Por que eles estão lá? Há alguma pergunta que você possa fazer a um especialista de domínio sobre os dados? Por exemplo, um médico cardiopata poderia lançar alguma luz sobre seu dataset de doenças cardíacas?
2.2 Pré-processamento de dados, preparando seus dados para serem modelados.
Imputação de recursos: preenchimento de valores ausentes, um modelo de aprendizado de máquina não pode aprender com dados que não estão lá.
Imputação única: Preencha com a média, uma mediana da coluna;
Múltiplas imputações: modele outros valores ausentes e com o que seu modelo encontrar;
KNN (k-vizinhos mais próximos): Preencha os dados com um valor de outro exemplo semelhante;
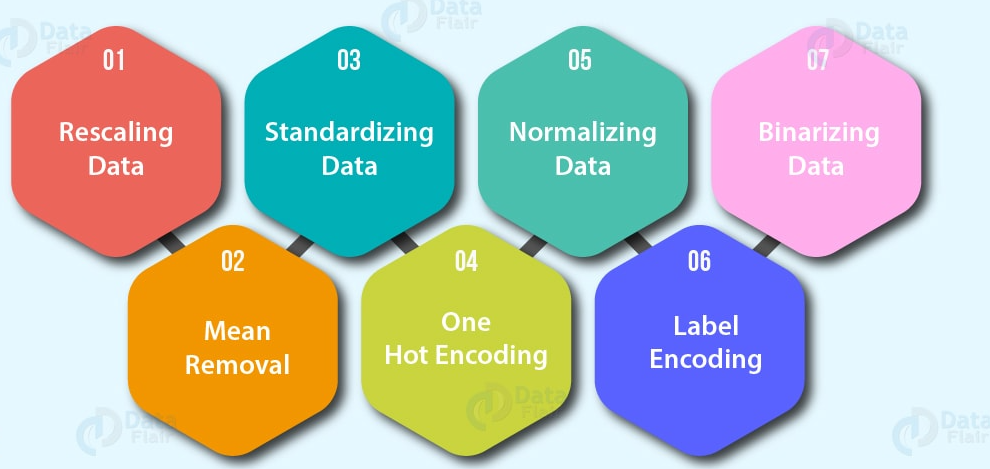
Codificação de recursos (transformando valores em números). Um modelo de aprendizado de máquina exige que todos os valores sejam numéricos.
Uma codificação rápida: Transforme todos os valores exclusivos em listas de 0 e 1, onde o valor de destino é 1 e o resto são 0s. Por exemplo, quando as cores de um carro são verdes, vermelhas, azuis, verdes, o futuro das cores de um carro seria representado como [1, 0 e 0] e um vermelho seria [0, 1 e 0].
Codificador de rótulo:Transforme rótulos em valores numéricos distintos. Por exemplo, se suas variáveis de destino forem animais diferentes, como cachorro, gato, pássaro, eles podem se tornar 0, 1 e 2, respectivamente.
Codificação de incorporação: aprenda uma representação entre todos os diferentes pontos de dados. Por exemplo, um modelo de linguagem é uma representação de como palavras diferentes se relacionam entre si. A incorporação também está se tornando mais amplamente disponível para dados estruturados (tabulares).
Normalização de recursos (dimensionamento) ou padronização: quando suas variáveis numéricas estão em escalas diferentes (por exemplo, number_of_bathroom está entre 1 e 5 e size_of_land entre 500 e 20000 pés quadrados), alguns algoritmos de aprendizado de máquina não funcionam muito bem. O dimensionamento e a padronização ajudam a corrigir isso.
Engenharia de recursos: transforma os dados em uma representação (potencialmente) mais significativa, adicionando conhecimento do domínio.
Decompor;
Discretização: transformando grandes grupos em grupos menores;
Recursos de cruzamento e interação: combinação de dois ou mais recursos;
Características do indicador: usar outras partes dos dados para indicar algo potencialmente significativo.
Seleção de recursos: selecionar os recursos mais valiosos de seu dataset para modelar. Potencialmente reduzindo o overfitting e o tempo de treinamento (menos dados gerais e menos dados redundantes para treinar) e melhorando a precisão.
Redução de dimensionalidade: Um método comum de redução de dimensionalidade, PCA ou análise de componente principal, toma um grande número de dimensões (recursos) e usa álgebra linear para reduzi-los a menos dimensões. Por exemplo, digamos que você tenha 10 recursos numéricos, você poderia executar o PCA para reduzi-los a 3;
Importância do recurso (pós-modelagem): ajuste um modelo a um dataset, inspecione quais recursos foram mais importantes para os resultados e remova os menos importantes;
Os métodos Wrapper geram um subconjunto “candidato”, contendo atributos selecionados no conjunto de treinamento, e utilizam a precisão resultante do classificador para avaliar o subconjunto de atributos “candidatos”.
Lidando com desequilíbrios: seus dados têm 10.000 exemplos de uma classe, mas apenas 100 exemplos de outra?
Colete mais dados (se puder);
Use o pacote scikit-learn-contribimbalanced- learn;
Use SMOTE: técnica desobreamostragem de minoria sintética. Ele cria amostras sintéticas de sua classe secundária para tentar nivelar o campo de jogo.
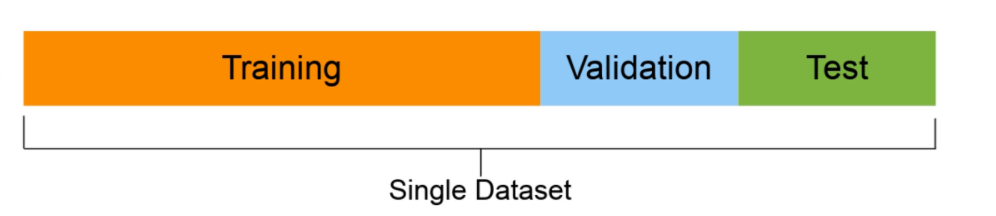
2.3 Divisão de dados
Conjunto de treinamento: geralmente o modelo aprende com 70-80% dos dados;
Conjunto de validação: normalmente os hiperparâmetros do modelo são ajustados com 10-15% dos dados;
Conjunto de teste: geralmente o desempenho final dos modelos é avaliado com 10-15% dos dados. Se você fizer certo os resultados no conjunto de teste fornecerão uma boa indicação de como o modelo deve funcionar no mundo real. Não use este dataset para ajustar o modelo.
Algoritmos não supervisionados – Clustering, redução de dimensionalidade (PCA, Autoencoders, t-SNE), Uma detecção de anomalia.
Tipos de aprendizagem
Aprendizagem em lote;
Aprendizagem online;
Aprendizagem de transferência;
Aprendizado ativo;
Ensembling.
Plataforma para detecção e segmentação de objetos.
Engenharia de atributos
Seleção de atributos
Tipos de Algoritmos e Métodos: Filter Methods, Wrapper Methods, Embedded Methods;
Seleção de Features com Python;
Testes estatísticos: podem ser usados para selecionar os atributos que possuem forte relacionamento com a variável que estamos tentando prever. Os métodos disponíveis são:
f_classif: é adequado quando os dados são numéricos e a variável alvo é categórica.
mutual_info_classif é mais adequado quando não há uma dependência linear entre as features e a variável alvo.
f_regression aplicado para problemas de regressão.
Chi2: Mede a dependência entre variáveis estocásticas, o uso dessa função “elimina” os recursos com maior probabilidade de serem independentes da classe e, portanto, irrelevantes para a classificação;
Recursive Feature Elimination – RFE: Remove recursivamente os atributos e constrói o modelo com os atributos remanescentes, ou seja, os modelos são construídos a partir da remoção de features;
Feature Importance: Métodos ensembles como o algoritmo Random Forest, podem ser usados para estimar a importância de cada atributo. Ele retorna um score para cada atributo, quanto maior o score, maior é a importância desse atributo.
Ajuste e regularização
Underfitting – acontece quando seu modelo não funciona tão bem quanto você gostaria. Tente treinar para um modelo mais longo ou mais avançado.
Overfitting – acontece quando sua perda de validação começa a aumentar ou quando o modelo tem um desempenho melhor no conjunto de treinamento do que no conjunto de testes.
Regularização: uma coleção de tecnologias para prevenir / reduzir overfitting (por exemplo, L1, L2, Dropout, Parada antecipada, Aumento de dados, normalização em lote).
Ajuste de hiperparâmetros – execute uma série de experimentos com configurações diferentes e veja qual funciona melhor.
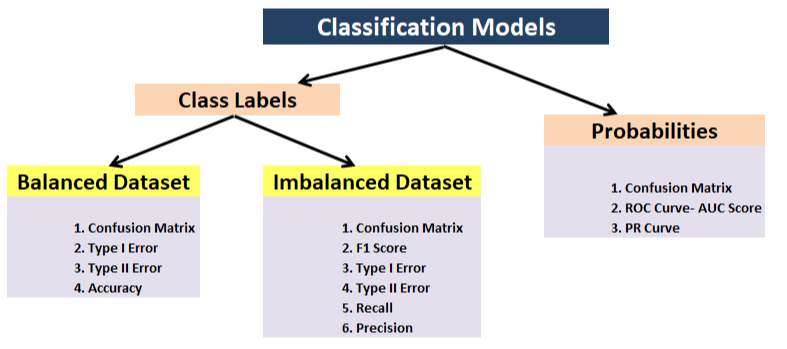
4. Análise / Avaliação
Avaliação de métricas
Classificação – Acurácia, precisão, recall, F1, matriz de confusão, precisão média (detecção de objeto);
Regressão – MSE, MAE, R ^ 2;
Métrica baseada em tarefas – por exemplo, para um carro que dirige sozinho, você pode querer saber o número de desengates.
Engenharia de atributos
Custo de treinamento / inferência.
5. Modelo de Serviço (implantação de um modelo)
Coloque o modelo em produção;
Ferramentas que você pode usar: TensorFlow Servinf, PyTorch Serving, Google AI Platform, Sagemaker;
MLOps: onde a engenharia de software encontra o aprendizado de máquina, basicamente toda a tecnologia necessária em torno de um modelo de aprendizado de máquina para que funcione na produção.
Usar o modelo para fazer previsões;
Reavaliar.
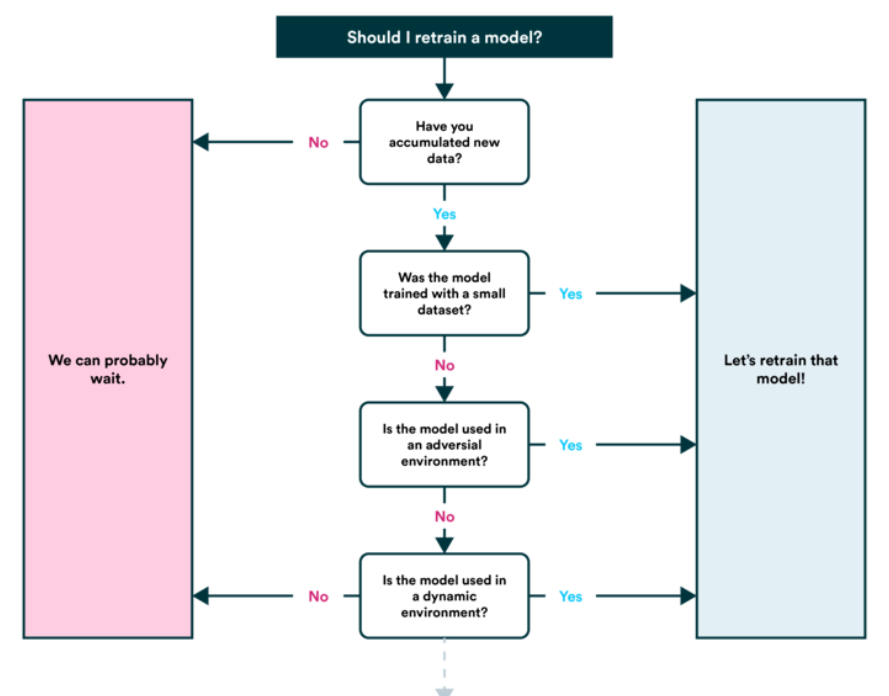
6. Modelo de retreinamento
O modelo ainda é válido para novas cargas de trabalho?
Veja o desempenho do modelo após a veiculação (ou antes da veiculação) com base em várias métricas de avaliação e reveja as etapas acima conforme necessário. Lembre-se de que o aprendizado de máquina é muito experimental, então é aqui que você deverá rastrear seus dados e experimentos;
Você também verá que as previsões do seu modelo começam a “envelhecer” ou “flutuar”, como quando as fontes de dados mudam ou atualizam (novo hardware, etc.). É quando você deverá retreiná-lo.
PLN ou Processamento de Linguagem Natural é a forma como as máquinas entendem e lidam com as linguagens humanas. Esta técnica lida com dados não estruturados de texto e embora seja difícil de dominá-la é fácil de entender seus conceitos.
Cientes disso, devemos entender que a disponibilidade e geração de dados são complexidades envolvidas, em geral, com qualquer tipo de caso de uso de Machine Learning (ML). Mas o PLN é o campo onde esse problema é relativamente menos pronunciado, pois há muitos dados de texto ao nosso redor. Os e-mails que escrevemos, os comentários que postamos, os blogs que escrevemos são alguns exemplos.
Tipos:
1) Reconhecimento de entidade nomeada
O processo de extração de entidades de nomeadas no texto, nome de pessoas, países, organizações, extrai informações úteis que podem ser usadas para vários fins como: classificação, recomendação, análise de sentimento, entre outros.
Um chatbot é o exemplo de uso mais comum. A consulta do usuário é entendida por meio das entidades no texto e respondida de acordo com elas.
2) Resumo do texto
É onde os conceitos-chave do texto são extraídos e o resumo parafraseado é construído em torno dele. Isso pode ser útil em resultados de pesquisas extensos.
3) Tradução
Conversão de texto de uma linguagem para outra. O tradutor do Google é o exemplo mais comum que temos.
4) Fala em texto
Converte voz em dados de texto, sendo o exemplo mais comum os assistentes em nossos smartphones.
5) NLU
Natural Language Understanding é uma forma de entender as palavras e frases no que diz respeito ao contexto. Eles são úteis na análise de sentimento dos comentários de usuários e consumidores. Modelos NLU são comumente usados na criação de chatbot.
6) NLG
Natural Language Generation vai além do processamento da máquina ou da compreensão do texto. Essa é a capacidade das máquinas de escrever conteúdo por si mesmas. Uma rede profunda, usando Transformers GTP-3, escreveu este artigo.
Iniciando
Os insights sobre como o Machine Learning lida com dados não estruturados de texto são apresentados por meio de um exemplo básico de classificação de texto.
Entrada:
Uma coluna de ‘texto’ com comentários de revisão por usuário. Uma coluna de ‘rótulo’ com um sinalizador para indicar se é um comentário positivo ou negativo.
Saída:
A tarefa é classificar os comentários com base no sentimento como positivos ou negativos.
Etapas de pré-processamento
Um pré-processamento será feito para transformar os dados em algoritmos de ML. Como o texto não pode ser tratado diretamente por máquinas, ele é convertido em números. Dessa forma, os dados não estruturados são convertidos em dados estruturados.
NLTK é uma biblioteca Python que pode ajudar você nos casos de uso de PLN e atende muito bem às necessidades de pré-processamento.
1) Remoção de palavras irrelevantes
Palavras irrelevantes ocorrem com frequência e não acrescentam muito significado ao texto. Os mecanismos de pesquisa também são programados para ignorar essas palavras. Podemos citar como exemplo as palavras: de, o, isso, tem, seu, o quê, etc.
A remoção dessas palavras ajuda o código a se concentrar nas principais palavras-chave do texto que adicionam mais contexto.
Aplicando a remoção de palavras irrelevantes a um data frame do Pandas com uma coluna de ‘texto’.
input_df[‘text’] = input_df[‘text’].apply(lambda x: “ “.join(x for x in x.split() if x not in stop))
2) Remoção de emojis e caracteres especiais
Os comentários do usuário são carregados de emojis e caracteres especiais. Eles são representados como caracteres Unicode no texto, denotados como U +, variando de U + 0000 a U + 10FFFF.
Flexão é a modificação de uma palavra para expressar diferentes categorias gramaticais como tempo verbal, voz, aspecto, pessoa, número, gênero e humor. Por exemplo, as derivações de ‘venha’ são ‘veio’, ‘vem’. Para obter o melhor resultado, as flexões de uma palavra devem ser tratadas da mesma maneira. Para lidar com isso usamos a lematização.
A lematização resolve as palavras em sua forma de dicionário (conhecida como lema), para a qual requer dicionários detalhados nos quais o algoritmo pode pesquisar e vincular palavras aos lemas correspondentes.
Por exemplo, as palavras “correr”, “corre” e “correu” são todas formas da palavra “correr”, portanto “correr” é o lema de todas as palavras anteriores.
a) Stemming
Stemming é uma abordagem baseada em regras que converte as palavras em sua palavra raiz (radical) para remover a flexão sem se preocupar com o contexto da palavra na frase. Isso é usado quando o significado da palavra não é importante. A palavra raiz pode ser uma palavra sem sentido em si mesma.
def stemming_text(text):
stem_words = [porter.stem(w) for w in w_tokenizer.tokenize(text)]
return ‘ ‘.join(stem_words)
input_df[‘text’] = input_df[‘text’].apply(lambda x: stemming_text(x))
b) Lematização
A lematização, ao contrário de Stemming, reduz as palavras flexionadas adequadamente, garantindo que a palavra raiz (lema) pertence ao idioma. Embora a lematização seja mais lenta em comparação com a Stemming, ela considera o contexto da palavra levando em consideração a palavra anterior, o que resulta em melhor precisão.
Código de explicação:
w_tokenizer = nltk.tokenize.WhitespaceTokenizer()
lemmatizer = nltk.stem.WordNetLemmatizer()
def lemmatize_text(text):
lemma_words = [lemmatizer.lemmatize(w) for w in w_tokenizer.tokenize(text)]
return ‘ ‘.join(lemma_words)
print(lemmatize_text('study'),
lemmatize_text('studying') ,
lemmatize_text('studies'))
Esta é a etapa em que as palavras são convertidas em números, que podem ser processados pelos algoritmos. Esses números resultantes estão na forma de vetores, daí o nome.
1) Modelo Bag of words
Este é o mais básico dos vetorizadores. O vetor formado contém palavras no texto e sua frequência. É como se as palavras fossem colocadas em um saco. A ordem das palavras não é mantida.
Código de explicação:
from sklearn.feature_extraction.text import CountVectorizer
bagOwords = CountVectorizer()
print(bagOwords.fit_transform(text).toarray())
print('Features:', bagOwords.get_feature_names())
Entrada:
text = [“I like the product very much. The quality is very good.”,
Os vetores dos textos 2 e 5 (ao contrário do que se espera), por serem de sentidos opostos, não diferem tanto. A matriz retornada é esparsa.
2) n-gramas
Ao contrário da abordagem do saco de palavras, a abordagem de n-gram depende da ordem das palavras para derivar seu contexto. O n-gram é uma sequência contígua de “n” itens em um texto, portanto, o conjunto de recursos criado com o recurso n-grams terá um número n de palavras consecutivas como recursos. O valor para “n” pode ser fornecido como um intervalo.
Só porque uma palavra aparece com alta frequência não significa que a palavra acrescenta um efeito significativo sobre o sentimento que procuramos. A palavra pode ser comum a todos os textos de amostra. Por exemplo, a palavra ‘product’ em nossa amostra é redundante e não fornece muitas informações relacionadas ao sentimento. Isso apenas aumenta a duração do recurso.
Frequência do termo (TF) – é a frequência das palavras em um texto de amostra.
Frequência inversa do documento (IDF) – destaca a frequência das palavras em outros textos de amostra. Os recursos são raros ou comuns nos textos de exemplo é a principal preocupação aqui.
Quando usamos ambos os TF-IDF juntos (TF * IDF), as palavras de alta frequência em um texto de exemplo que tem baixa ocorrência em outros textos de exemplo recebem maior importância.
No terceiro texto de exemplo, as palavras de valores ‘broken‘ e ‘delivered‘ são raras em todos os textos e recebem pontuação mais alta do que ‘product‘, que é uma palavra recorrente.
Geralmente, esse tipo de cenário terá um desequilíbrio de classe. Os dados de texto incluíam mais casos de sentimento positivo do que negativo. A maneira mais simples de lidar com o desequilíbrio de classe é aumentando os dados com cópias exatas da classe minoritária (neste caso, os cenários de sentimento negativo). Essa técnica é chamada de sobreamostragem.
Algoritmo de Machine Learning
Após a conclusão das etapas de processamento, os dados estão prontos para serem passados para um algoritmo de ML para ajuste e previsão. Este é um processo iterativo no qual um algoritmo adequado é escolhido e o ajuste do hiperparâmetro é feito.
Um ponto a ser observado aqui é que, aparentemente, como qualquer outro problema de ML, as etapas de pré-processamento devem ser tratadas após a divisão de treinamento e teste.
Código de implementação
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
rnd_mdl = RandomForestClassifier()
rnd_mdl.fit(tfidf_result, input_df[‘label’])
#Using the fitted model to predict from the test data
#test_df is the test data and tfidf_result_test is the preprocessed test text data
output_test_pred = rnd_mdl.predict(tfidf_result_test)
#finding f1 score for the generated model
test_f1_score = f1_score(test_df[‘label’], output_test_pred)
Biblioteca pré-construída
Há uma biblioteca pré-construída em NLTK que pontua os dados de texto com base no sentimento. Ele não precisa dessas etapas de pré-processamento. É denominado nltk.sentiment.SentimentAnalyzer.
Finalizando
Existem muitos modelos avançados de Deep Learning pré-treinados disponíveis para PLN. O pré-processamento envolvido, ao usar essas redes profundas, varia consideravelmente da abordagem de ML fornecida aqui.
Esta é uma introdução simples ao interessante mundo da PLN! É um vasto espaço em constante evolução!
Keras é uma biblioteca aberta de Deep Learning implementada utilizando TensorFlow para diversas linguagens/plataformas, como Python e R, como foco na sua facilidade para utilização. Ela permite modelar e treinar modelos de redes neurais com poucas linhas de código, como você verá no tutorial a seguir.
Nesse tutorial, vamos utilizar o Keras para criar um modelo capaz de classificar se membros de uma população indígena possuem ou não diabetes.
Preparações
Para seguir esse projeto, você precisará ter instalados:
Python 3;
Bibliotecas SciPy e Numpy;
Bibliotecas TensorFlow e Keras;
Jupyter Notebook;
Alternativamente, você pode realizar este tutorial na plataforma Google Colab, que já possui todas as dependências instaladas e prontas para que você execute o tutorial no seu navegador.
Após isso, basta criar um novo notebook com o título “projeto_deep_learning” (ou qualquer outro nome), e iniciar o tutorial.
1. Carregando os dados
Em uma célula, importe as seguintes bibliotecas Python:
from numpy import loadtxt
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
Na célula seguinte, carregue os dados da base Pima Indians Diabetes. Essa base possui inicialmente 9 colunas, sendo as 8 primeiras as entradas e a última o resultado esperado. Todas as entradas dessa base são numéricas, assim como as saídas, o que facilita a computação dos dados por modelos de Deep Learning.
# carregue a base de dados
dataset = loadtxt('https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv', delimiter=',')
Em seguida, utilizando a funcionalidade de slice do Python, separe o conjunto de dados entre “Entradas” (X) e “Saídas” (y).
# separe os dados entre entradas (X) e saídas (y)
X = dataset[:,0:8]
y = dataset[:,8]
2. Criar o modelo utilizando Keras
Agora que nossos dados foram carregados e ajustados entre entradas e saídas, podemos definir nosso modelo utilizando a biblioteca Keras.
Modelos Keras são definidos como uma sequência de camadas. Nesse tutorial, vamos criar um modelo sequencial e adicionar uma camada de cada.
Primeiramente, precisamos garantir que a camada de entrada tem a quantidade correta de inputs de entrada. Isso pode ser especificado no Keras utilizando o argumento input_dim e o ajustando para 8, nosso número de entradas.
Para esse tutorial, vamos utilizar camadas completamente conectadas, que são definidas no Keras pela classe Dense. Esse projeto utilizará 3 camadas, as quais as duas primeiras utilizarão a função de ativação ReLU e a função Sigmoid na última. Podemos especificar o número de neurônios no primeiro argumento, e a função de ativação com o parâmetro activation.
# definir o modelo com keras
# inicializar o modelo sequencial
model = Sequential()
# inicializar a primeira camada, com 12 neurônios, 8 entradas utilizando a função ReLU
model.add(Dense(12, input_dim=8, activation='relu'))
# inicializar a segunda camada com 8 neurônios e a função ReLU
model.add(Dense(8, activation='relu'))
# inicializar a última camada (camada de saída) com um neurônio e a função Sigmoid
model.add(Dense(1, activation='sigmoid'))
3. Compilando o modelo
Com nosso modelo definido, precisamos compilá-lo. A compilação ocorre utilizando bibliotecas como Theano ou TensorFlow, onde a melhor forma de representar a rede para treinar e fazer predições utilizando o hardware disponível é selecionada.
Ao compilar, precisamos especificar algumas propriedades, como a função de perda, otimizador e a métrica que será utilizada para avaliar o modelo. Foge ao escopo do tutorial apresentar esses conceitos, mas vamos utilizar a função de perda de Entropia Cruzada Binária, o otimizador Adam (que utiliza o gradiente descendente) e acurácia como métrica.
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
4. Treinando o modelo
Como nosso modelo definido e compilado, precisamos treiná-lo, ou seja, executar o modelo utilizando nossos dados. Para treinar o modelo, basta chamar a função fit() para o modelo.
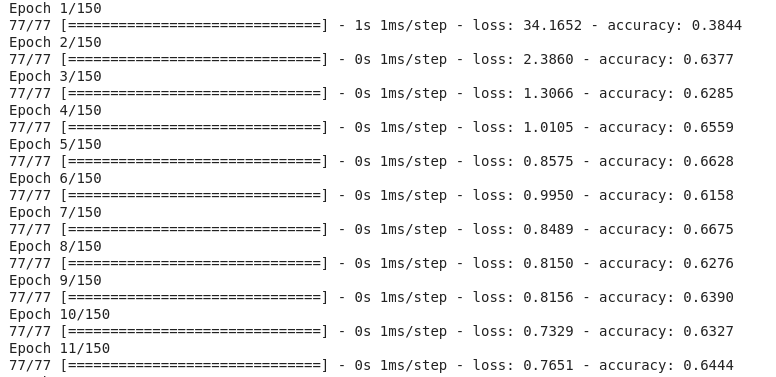
O treinamento ocorre através de épocas, e cada época é dividida em lotes, onde uma época é uma passagem por todas as linhas do conjunto de testes, e um lote é composto de uma ou mais amostras (quantidade definida pelo usuário) consideradas pelo modelo antes que seja feita a atualização dos seus pesos. Aqui, vamos executar 150 épocas com lotes de tamanho 10 (um número considerado pequeno).
# treinar o modelo keras
model.fit(X, y, epochs=150, batch_size=10)
5. Avaliando o modelo
Agora que estamos com nosso modelo treinado, precisamos avaliá-lo. Essa avaliação vai dizer o quão bem o modelo foi construído utilizando o conjunto de dados de treinamento. Esse pequeno projeto foi construído para ser simples, mas você pode separar os dados entre dados de treinamento e de teste para avaliar o desempenho do modelo com novos dados.
Para avaliar como o modelo se comportou para os dados de treinamento, basta passar os mesmos dados de entrada e saída para a função evaluate() . Essa função retorna uma lista com a perda e a acurácia do modelo para o conjunto de dados.
# avaliando o modelo keras
_, accuracy = model.evaluate(X, y)
print('Acurácia: %.2f' % (accuracy*100))
Conclusão
Com esse tutorial, podemos acompanhar em 5 passos o ciclo de vida de um modelo de Deep Learning, da sua concepção até a sua avaliação. Você pode expandir o que foi feito neste tutorial para, por exemplo, ajustar o modelo (é possível obter uma acurácia maior do que a obtida?), salvar o modelo (para utilização em outros projetos), plotar a curva de aprendizado, entre outras ideias.
Para mais tutoriais, continue atento ao nosso Blog.
“Hoje, o Insight indica o livro “Inteligência Artificial” (AI Superpowers – China, Silicon Valley, and the New World Order), escrito por uma das maiores autoridade de IA, Kai-Fuu Lee.
Esse livro nos ajuda a entender as grandes transformações positivas que a inteligência artificial pode trazer e como as maiores potências do mundo, EUA e China, estão desenvolvendo essa ciência dentro de realidades e posições específicas.
As posições de liderança ocupadas por China e Estados Unidos em muitos momentos ganham o contorno de confronto. E isso se reflete nas palavras usadas pelo autor quando afirma que a grande quantidade de engenheiros de IA consistentes será tão importante quanto a qualidade de pesquisadores de elite, e “a China está treinando exatamente esse exército“.
Também é destacado que, apesar dos Estados Unidos serem pioneiros na IA, hoje a China já é um superpotência na área. Isso é resultado, afirma Lee, de aspectos específicos do país asiático, como “dados abundantes, empreendedores tenazes, cientistas de IA bem treinados e um ambiente político favorável”.
No entanto, como alertado em artigo do The Washington Post, “alguns leriam ‘dados abundantes’ como ‘vigilância` e ‘um ambiente de política favorável’ como ‘tomada de decisão de cima para baixo que não é impedida pela opinião pública.’”
Kai-Fuu Lee compartilha conosco uma reflexão sobre o processo desta corrida desenvolvimentista entre Estado Unidos e China e suas implicações. Uma das preocupações destacadas é que o domínio dessas duas potências gere desigualdade global também no campo de IA. Os dois países já são lideranças massivas no resto do mundo, e isso pode se aprofundar se esse poder tecnológico permanecer tão concentrado.
Além disso, o livro trata da antiga e a cada dia renovada preocupação sobre o papel que a IA ocupará no mundo. E isso significa pensar qual lugar nós ocuparemos num mundo tão automatizado por essas máquinas, muito mais adequadas que os seres humanos para certas tarefas, mas frutos da criatividade e inteligência humana.
O autor*
Imagem: vídeo – Como a IA pode salvar nossa humanidade (TED)
Kai-Fu Lee tem uma perspectiva única na indústria de tecnologia global, tendo trabalhado extensivamente entre os Estados Unidos e a China pesquisando, desenvolvendo e investindo em inteligência artificial há mais de 30 anos. Ele é um dos maiores investidores em tecnologia da China, realizando um trabalho pioneiro no campo da IA e trabalhando com vários gigantes da tecnologia dos EUA.
Lee já foi presidente do Google China e ocupou cargos executivos na Microsoft, SGI e Apple, e fundou a Microsoft Research China. Mais tarde renomeado “Microsoft Research Asia”, este instituto treinou a maioria dos líderes de IA na China, incluindo chefes de IA da Baidu, Tencent, Alibaba, Lenovo, Huawei e Haier. Enquanto estava na Apple, Lee liderou projetos de IA em fala e linguagem natural que foram destaques na mídia americana.
Atualmente, Kai-Fuu Lee é o presidente e CEO da Sinovation Ventures, empresa líder de investimentos em tecnologia com foco no desenvolvimento de companhias chinesas de alta tecnologia.
A ciência de dados tem revolucionado praticamente todas as áreas. Na educação, utilizando modelos para uma melhor avaliação de estudantes, na medicina, identificando e prevendo doenças, no futebol, obtendo o máximo valor das escalações de um time.
Neste artigo, apresentaremos 7 exemplos onde a ciência de dados é utilizada como uma poderosa ferramenta, com modelos e algoritmos que ajudam a analisar, prever e, consequentemente, obter melhores resultados em cada uma dessas áreas.
1- Segurança Pública
Em uma ação criminosa existem diversos elementos envolvidos. Informações colhidas anteriormente sobre os suspeitos (a exemplo, a ficha criminal) e sobre a região na qual um crime foi cometido (como entorno e vias de acesso) são fatores importantes na elucidação de delitos.
No entanto, muitas vezes esses dados coletados em diferentes regiões e por diferentes órgãos não estão integradas em uma mesma base de dados, o que prejudica o trabalho dos agentes policiais.
O Ceará tem sido um exemplo do uso inteligente da ciência de dados na segurança pública. Em 2019, o estadoganhou interesse nacional pela grande redução de seus índices criminais. Entre as diversas ações tomadas para atingir esse resultado, um dos maiores destaques é o uso de soluções tecnológicas baseadas em ciência de dados.
Em parceria com a Secretaria da Segurança Pública e Defesa Social (SSPDS), o Insight Lab desenvolveu ferramentas que têm ajudado a entender e combater práticas criminosas.
Conheça algumas dessas ferramentas:
Sistema Policial Indicativo de Abordagem (SPIA)
O Spia tem sido usado no enfraquecimento da mobilidade de criminosos, pois ajuda na identificação de veículos roubados. É um sistema de inteligência artificial que integra as bases de dados de órgãos federais, estaduais e municipais aos dados captados por mais 3.300 câmeras espalhadas pelo Ceará.
Big Data “Odin”
Como apresentado no portal do Governo do Estado do Ceará, o sistema de big data Odin “armazena e cruza dados obtidos por mais de 50 sistemas dos órgãos de segurança e de entidades parceiras. Todas as informações podem ser vistas em tempo real dentro de um painel que simplifica os processos de investigação e de tomadas de decisão, o Cerebrum.”
Portal do Comando Avançado (PCA)
Exclusivo para profissionais da segurança pública do Ceará, é um aplicativo para celular que reúne informações civil e criminal da população cearense, dados de veículos e motoristas, biometria e o reconhecimento facial.
2 – Evasão fiscal e detecção de fraude
Um grande desafio dentro de empresas e organizações é a detecção de fraudes e a evasão fiscal. Uma pequena porcentagem dessas atividades pode representar perdas bilionárias para as instituições.
Entretanto, os avanços na análise de fraudes, com o uso de ciência de dados e o Big Data, são uma perfeita ferramenta para prevenir tais atividades. Além da redução de informações, com essas ferramentas pode-se diferenciar entre contribuinte legítimo e fraudador, utilizando classificação de dados, clustering e reconhecimento de padrão, por exemplo. Diferentes fontes de dados são usadas para a análise, sejam dados estruturados ou não estruturados.
Diversos estudiosos estão empenhados em desvanecer esse problema. Veja um exemplo disso: a partir de dados reais da Secretaria da Fazenda do Estado do Ceará (Sefaz-CE), sete pesquisadores (entre eles o coordenador do Insight Lab, José Macêdo) aplicaram um novo método, ALICIA, para detectar potenciais fraudadores fiscais. Esse método de seleção de recursos é baseado em regras de associação e lógica proposicional.
Os autores explicam que ALICIA é estruturado em três fases:
Ele gera um conjunto de regras de associação relevantes a partir de um conjunto de indicadores de fraude (recursos).
A partir de tais regras de associação, ALICIA constrói um gráfico, cuja estrutura é então usada para determinar as características mais relevantes.
Para conseguir isso, ALICIA aplica uma nova medida de centralidade chamada de Importância Topológica do Recurso.
Os teste feitos com ALICIA em quatro diferentes conjuntos de dados do mundo real mostram sua eficiência superior a outros oito métodos de seleção de recursos. Os resultados mostram que Alicia atinge pontuações de medida F de até 76,88% e supera de forma consistente seus concorrentes.
3 – Saúde
Uma das principais aplicações da ciência de dados é na área da saúde. Esse setor utiliza intensamente data science para descoberta de novas drogas, na prevenção, diagnóstico e tratamento de doenças e no monitoramento da saúde de pacientes.
E durante a pandemia de Covid-19, a ciência de dados foi um dos primeiros auxílios buscados para que se pudesse entender o comportando do vírus na população mundial, criar modelos preditivos sobre seus impactos e divulgar ao público, especialmente através da visualização de dados, estatísticas relacionadas à doença.
Como exemplo de transparência dos dados durante a pandemia, destacamos a plataforma cearense IntegraSUS Analytics.
Como descrito pela Secretaria da Saúde do Ceará, o IntegraSUS Analytics é uma ferramenta com a qual “pesquisadores, profissionais e estudantes de ciência de dados ou de tecnologia da informação poderão ter acesso ao cenário atual da saúde no Estado. Tudo por meio dos códigos e modelos utilizados na construção do IntegraSUS. A plataforma também oferece datasets sobre diferentes áreas da saúde para aprendizado e treinamento.”
Além do IntegraSUS Analytics, o Governo do Estado esteve em parceria com o Insight Lab para desenvolver outras ações de enfrentamento ao Covid-19. Nossos pesquisadores produziram Mapas de Kernel para observar como está acontecendo o espalhamento da doença no Ceará. Junto a isso, a professora Ticiana Linhares comandou o desenvolvimento de um algoritmo de IA para entender a evolução dos sintomas do Covid-19.
Como isso acontece? Através dos textos trocados via chat (Plantão Coronavírus) entre os cidadãos e a Secretaria de Saúde, o algoritmo extrai dessas conversas os sintomas mais frequentes e avalia sua evolução.
4 – Games
Uma das indústrias em maior expansão é a de games. Contabiliza-se atualmente mais de 2 bilhões de jogadores no mundo todo, com estimativas para que esse número passe de 3 bilhões até 2023, segundo o site Statista.
Com esse super número de jogadores e a criação diária de novos jogos, uma enorme quantidade de dados são coletados, tais como o tempo de jogo do usuário, pontos de início e parada e pontuação. Essa coletânea de dados representa uma rica fonte para que especialistas estudem, aprendam e possam otimizar e melhorar os jogos.
Com a ciência de dados aplicada no mercado de jogos, é possível realizar o desenvolvimento, a monetização e o design de games, e ainda melhorar efeitos visuais, por exemplo. Com modelos que permitem a identificação de objetos, jogos tornam-se mais realistas tornando possível diferenciar jogadores pertencentes a equipes diferentes e dar comandos ao personagem específico dentro de um grupo.
A King, empresa criadora do famoso Candy Crush, tem, segundo seu diretor de produtos de serviços, Jonathan Palmer, uma cultura baseada em dados. Na King, depois que um jogo é lançado, ele continua sendo monitorado e os ajustes necessários são feitos. Eles analisam, por exemplo, se um jogo é muito difícil, então eles podem perder jogadores, e se muito fácil, os usuários ficam entediados e abandonam o jogo.
Palmer cita o nível 65 do Candy Crush Saga: “É um nível incrivelmente difícil, tinha seu próprio culto em torno dele. Percebemos que isso estava causando a agitação de muitas pessoas. Usando dados, pudemos dizer: ‘precisamos diminuir um pouco a dificuldade desse nível’.”
5 – Vida Social
O surgimento das redes sociais alterou completamente a forma como nos relacionamos, sejam relacionamentos amorosos, amizades ou relações de trabalho. Nos conectamos diariamente com inúmeras pessoas que jamais vimos. E todas as relações e ações nessas redes deixam extensos rastros de dados que influenciam, entre outras coisas, em quem você conhecerá a seguir.
Não é impressionante como o Facebook sempre acerta nas recomendações de novas amizades? Em artigo do Washington Post é dito que ele se baseia em “really good math”, mais especificamente, o Facebook utiliza um tipo de ciência de dados conhecido como network science, que basicamente busca prever o crescimento da rede social de um usuário baseado no crescimento das redes de usuários semelhantes.
Um outro exemplo é o Tinder. Ele utiliza um algoritmo que visa aumentar a probabilidade de correspondência. Esse algoritmo prioriza correspondências entre usuários ativos, usuários em uma mesma região e usuários que parecem os “tipos” uns dos outros com base em seu histórico de deslize.
6 – Esportes
A indústria do esporte é uma das mais rentáveis do mundo, gerando lucros bilionários todos os anos e, é claro, cheia de dados e estatísticas. Cada esporte está repleto de variáveis a serem estudadas, que vão desde o clima, a fisiologia de cada jogador, as decisões dos árbitros, até as escolhas feitas pelos jogadores durante uma partida. Assim, a ciência de dados vem para “decifrar” o que fazer com esses dados, revelando insights preditivos para a melhor tomada de decisão dentro de cada modalidade de esporte.
Um caso interessante para analisarmos é o da liga de basquete americana. A NBA usa o sistema de análise de arremesso da RSPCT, no qual uma câmera rastreia quando e onde a bola bate em cada tentativa de cesta. Os dados são canalizados para um dispositivo que exibe detalhes da tomada em tempo real e gera insights preditivos.
Leo Moravtchik, CEO da RSPCT, disse à SGV News que “com base em nossos dados … Podemos dizer [a um jogador]: ‘Se você está prestes a dar o último arremesso para ganhar o jogo, não tente do topo da chave, porque sua melhor localização é, na verdade, o canto direito ”
7 – Comércio eletrônico (e-commerce)
O comércio eletrônico (ou e-Commerce) é um tipo de negócio em que empresas e indivíduos compram e vendem coisas pela internet. Nesse tipo de comércio, a interação com os clientes passa por vários pontos, desde o clique em um anúncio e em produtos de interesse, até a compra e avaliação do produto.
Os dados obtidos nas plataformas de e-commerce ajudam os vendedores a construir uma imagem dos consumidores, seus hábitos de compra, quais as estratégias para “transformá-los” em clientes e ainda o tempo que isso leva.
Nesse sentido, a aplicação da ciência de dados permite a previsão da rotatividade de clientes, a segmentação destes, o impulsionamento das vendas com recomendações inteligentes de produtos, a extração de informações úteis das avaliações dos compradores, a previsão de demanda, a otimização de preços e tantas outras possibilidades.
No caso do Airbnb, a ciência de dados ajudou a renovar completamente sua função de pesquisa, destacando áreas mais requisitadas. O algoritmo do Airbnb hoje, nos rankings de busca, dá prioridade a aluguéis que estiverem em uma área com alta densidade de reservas. Antes, entretanto, os melhores aluguéis estavam localizados a uma certa distância dos centros da cidade. Isso implicava que, apesar de encontrar aluguéis legais, os locais não eram tão bons.
Se durante a sua vida profissional ou acadêmica, o grande problema foi encontrar tempo para ler, hoje, a realidade é outra. Pensando nisso o Insight Lab resolveu te dar uma ajudinha com dicas de leitura para você se aprimorar. Incluímos na lista obras técnicas e literárias que te trarão um conteúdo valioso e produtivo para sua carreira. Confira a lista.
Do mesmo criador da biblioteca Pandas, este volume é um guia para quem está no início da formação como programador. Ele ajuda a entender o funcionamento e a combinação de ferramentas para o tratamento de dados dentro do ambiente Python.
A obra é desenvolvida em seções curtas, o que torna a informação mais focada, isso ajudará o programador iniciante a identificar claramente os pontos centrais sem entrar em expansões ainda difíceis de entender.
Neste livro você aprenderá, a partir do zero, como os algoritmos e as ferramentas mais essenciais de data science funcionam. Entenderá a desempenhar bibliotecas, estruturas, módulos e stacks do data science ao mesmo tempo que se aprofunda no tema sem precisar, necessariamente, entender de data science.
O livro reflete sobre o que significa a organização dos dados em gráficos, a quem essas informações visuais serão
apresentadas, e dentro de qual contexto. Para a autora a visualização dos dados é o ponto onde as informações devem estar mais sistematizadas, não podendo se tornar um enigma para quem observa.
Ao longo dos capítulos o livro nos mostra processos de concepção dos elementos para a visualização de dados e traz muitos exemplos de antes e depois, ou seja, exemplos de gráficos que não transmitem corretamente a mensagem e, em seguida, uma versão alternativa onde a informação foi apresentada de forma clara e eficiente.
Um dos melhores livros prático sobre Machine Learning. Seja para iniciante na área ou para quem já atua e precisa de um complemento.
De maneira prática, o livro mostra como utilizar ferramentas simples e eficientes para implementar programas capazes de aprender com dados. Utilizando exemplos concretos, uma teoria mínima e duas estruturas Python, prontas para produção, o autor ajuda você a adquirir uma compreensão intuitiva dos conceitos e ferramentas na construção de sistemas inteligentes.
Direcionado principalmente para desenvolvedores, pesquisadores e analistas de Python que desejam executar análises geoespaciais, de modelagem e GIS com o Python.
O livro é uma ótima dica para quem deseja entender o mapeamento e a análise digital e quem usa Python ou outra linguagem de script para automação ou processamento de dados manualmente.
O livro foi feito para programadores que desejam se familiarizar com a Linguagem de Programação Scala para escrever programas concorrentes, escaláveis e reativos. Não é preciso ter experiência em programação para entender os conceitos explicados no livro. Porém, caso tenha, isso o ajudará a aprender melhor os conceitos.
O autor começa analisando os conceitos básicos da linguagem, sintaxe, tipos de dados principais, literais, variáveis e muito mais. A partir daí, o leitor será apresentado às suas estruturas de dados e aprenderá como trabalhar com funções de alta ordem.
7 – The man who solved the market: how Jim Simons Launched the quant revolution de Gregory Zuckerman
Em tradução livre – O homem que resolveu o mercado: como Jim Simons lançou a Revolução Quant. Um livro não técnico, conta a história de Jim Simons, um matemático que começou a usar estatísticas para negociar ações, em uma época em que todo mundo no mercado usava apenas instintos e análises fundamentais tradicionais.
Obviamente, todo mundo ficou cético em relação a seus métodos, mas depois de anos gerenciando seu fundo de investimentos e obtendo resultados surpreendentes, as pessoas acabaram cedendo e começaram a reconhecer o poder dos chamados quant hedge funds, que desempenham um papel enorme no setor financeiro nos dias atuais.
8 – Feature Engineering for Machine Learning de Alice Zheng e Amanda Casari
Embora a Engenharia de Recursos seja uma das etapas mais importantes no fluxo de trabalho da Ciência de Dados, às vezes ela é ignorada. Este livro é uma boa visão geral desse processo, incluindo técnicas detalhadas, advertências e aplicações práticas.
Ele vem com a explicação matemática e o código Python para a maioria dos métodos, portanto, você precisa de um conhecimento técnico razoável para seguir adiante.
9 – The book of why de Judea Pearl e Dana Mackenzie
Muitas vezes nos dizem que “a correlação não implica causalidade”. Quando você pensa sobre isso, no entanto, o conceito de causalidade não é muito claro: o que exatamente isso significa?
Este livro conta a história de como vemos a causalidade de uma perspectiva filosófica e, em seguida, apresenta as ferramentas e modelos matemáticos para entendê-la. Isso mudará a maneira como você pensa sobre causa e efeito.
10 –Moneyball de Michael Lewis
Esta é a história de Billy Beane e Paul DePodesta, que foram capazes de levar o Oakland Athletics, um pequeno time de beisebol, através de uma excelente campanha na Major League Baseball, escolhendo jogadores negligenciados baratos.
Como eles fizeram isso? Usando dados. Isso mudou a maneira como as equipes escolhem seus jogadores, o que anteriormente era feito exclusivamente por olheiros e seus instintos. A história também inspirou um filme com o mesmo nome, e ambos são obras-primas.
Fonte: crb8.org.br
O que achou das dicas? Que mais livros você incluiria? Compartilha com a gente!
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade