Quando o ChatGPT foi lançado, as pessoas ficaram impressionadas com as possibilidades que ele oferecia, desde a escrita de um simples e-mail até o desenvolvimento de códigos complexos. A inauguração da ferramenta marcou um grande avanço na inteligência artificial, superando expectativas com sua habilidade de gerar respostas mais precisas e contextualmente relevantes.
Mas no fervilhante e imparável mundo da inteligência artificial, diversas ferramentas têm surgido como alternativas ao ChatGPT, cada uma com suas características e benefícios específicos.
Neste artigo vamos explorar algumas das melhores opções disponíveis em 2024, destacando suas funcionalidades, integrações e diferenças principais. Se você está procurando uma IA que se integre perfeitamente ao ecossistema do Google, uma ferramenta poderosa para criação de conteúdo, ou uma solução focada em privacidade, aqui você encontrará a alternativa ideal para suas necessidades.
Google Gemini (anteriormente Bard)
Esta IA se destaca por integrar-se ao ecossistema do Google. Gemini aproveita o vasto conjunto de dados e capacidades de pesquisa do Google, tornando-se uma ferramenta poderosa para aqueles que usam Google Docs, Sheets, Gmail e Slides, por exemplo. As principais funcionalidades incluem entrada por voz e integração com serviços do Google. No entanto, enfrenta dificuldades em oferecer respostas criativas e realizar tarefas de raciocínio complexo.
Microsoft Copilot
Incorporado no Windows 11 e no Edge, o Copilot utiliza o GPT-4 em combinação com a pesquisa do Bing. Oferece acesso em tempo real à internet, geração de imagens e resultados interativos. É especialmente útil para usuários do ecossistema Microsoft. As principais desvantagens incluem anúncios ocasionais nas respostas e dificuldade de acessar o histórico de conversas.
Claude 3
Desenvolvido pela Anthropic, o Claude oferece interações complexas e sensíveis ao contexto. Entre suas habilidades, suporta o upload e a análise de documentos. O Claude se destaca na escrita criativa e na manutenção de um estilo consistente, mas carece de recursos avançados como geração de imagens e interpretação de código.
Writesonic
Focado na criação de conteúdo, o Writesonic fornece conteúdo otimizado para SEO para blogs, anúncios e postagens em redes sociais. Executado no GPT-4, oferece funcionalidades como geração de imagens e conversas baseadas em tendências, sendo ideal para equipes de marketing. Os problemas incluem consistência de memória.
Meta AI
Utilizando o modelo Llama 3, o Meta AI está disponível em plataformas como WhatsApp, Instagram e Messenger. Suporta geração de imagens e tem um bom desempenho em várias tarefas, mas está limitado a certas regiões e requer uma conta no Facebook.
ClickUp Brain
Integrado na plataforma ClickUp, esta ferramenta de IA é projetada para gestão de projetos e contextos empresariais. Oferece funcionalidades de IA baseadas em funções, resumos de tarefas e perguntas e respostas contextuais, sendo uma ferramenta valiosa para equipes. Está disponível em planos pagos e respeita controles de acesso rigorosos.
AnonChatGPT
Oferece acesso anônimo ao ChatGPT sem necessidade de login. Encaminha prompts para os servidores da OpenAI, proporcionando os benefícios básicos do ChatGPT sem compartilhar informações pessoais. No entanto, só é possível manter uma conversa por vez e necessita de recursos avançados como acesso à internet.
Copy.ai
Conhecido pela sumarização de texto, o Copy.ai é útil para processar textos longos, gerar ideias de conteúdo e escrever descrições para redes sociais. Suporta vários idiomas e oferece planos gratuitos e pagos. A ferramenta é robusta, mas possui uma curva de aprendizado.
Character.AI
Melhor para conversas baseadas em personagens, esta ferramenta permite que os usuários interajam com chatbots inspirados em livros e outros meios. Salva o histórico de conversas com cada personagem e pode ser usada sem uma conta. No entanto, é menos prática para tarefas gerais.
Principais Diferenças
Cada uma das ferramentas apresentadas aqui têm pontos fortes distintos, o que faz com que a necessidade do usuário defina qual a melhor ferramenta. Veja a seguir qual a melhor inteligência artificial em diferentes contextos.
Integração com Ecossistemas: Google Gemini e Microsoft Copilot se destacam pela integração perfeita com seus respectivos ecossistemas, sendo ideais para usuários já investidos em produtos Google ou Microsoft.
Criação de Conteúdo: Writesonic se destaca na geração de conteúdo otimizado para SEO para fins de marketing, enquanto Copy.ai foca na sumarização de texto e criação de conteúdo para redes sociais.
Acesso Anônimo e Simplificado: AnonChatGPT oferece uma vantagem única para usuários que priorizam privacidade e simplicidade, permitindo acesso sem necessidade de conta.
Interações Criativas e Baseadas em Personagens: Character.AI e Claude 3 são mais adequados para escrita criativa e interações baseadas em personagens, oferecendo uma experiência conversacional mais personalizada.
Gestão de Projetos e Contextos Empresariais: ClickUp Brain fornece funcionalidades de IA específicas para negócios, sendo útil para gestão de projetos e colaboração em equipe.
Versatilidade Geral: ChatGPT permanece uma opção versátil, continuamente atualizada para lidar com uma ampla gama de tarefas, desde conversas casuais até a resolução de problemas complexos.
Essas alternativas atendem a diferentes necessidades, permitindo que os usuários escolham com base em seus requisitos específicos e preferências de ecossistema.
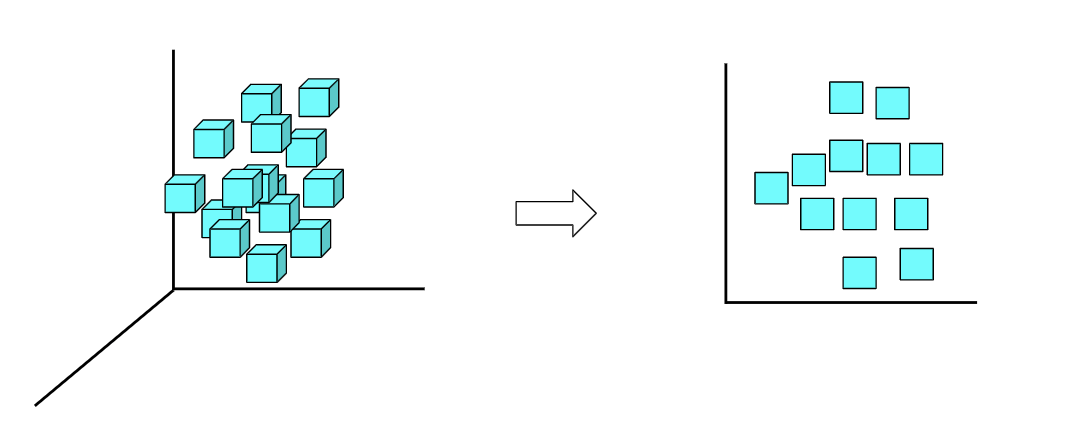
Algoritmos de aprendizado de máquina utilizam parâmetros baseados em dados de treinamento – um subconjunto de dados que representa o conjunto maior. À medida que os dados de treinamento se expandem para representar o mundo de modo mais realista, o algoritmo calcula resultados mais precisos.
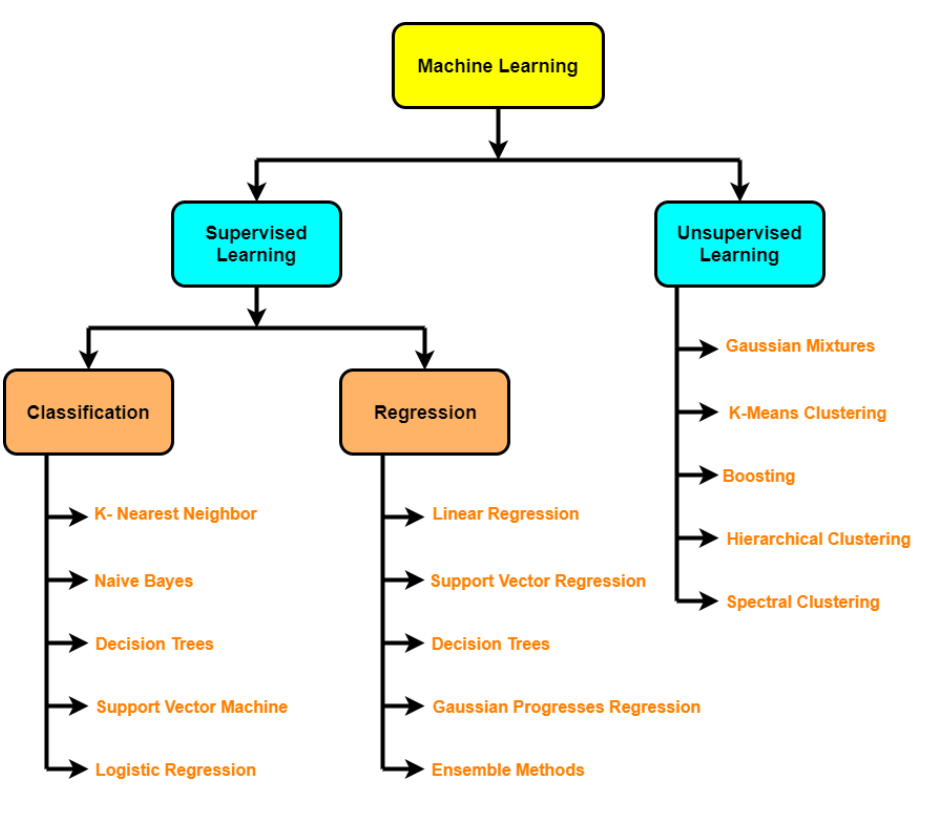
Diferentes algoritmos analisam dados de maneiras diferentes. Geralmente, eles são agrupados pelas técnicas de aprendizado de máquina para as quais são usados: aprendizado supervisionado, aprendizado não supervisionado e aprendizado de reforço. Os algoritmos usados com mais frequência usam a regressão e a classificação para prever categorias de destino, encontrar pontos de dados incomuns, prever valores e descobrir semelhanças.
Tendo isso em mente, vamos conhecer os 5 algoritmos de aprendizado de máquina mais importantes:
Algoritmos de Ensemble Learning;
Algoritmos explicativos;
Algoritmos de agrupamento;
Algoritmos de Redução de Dimensionalidade;
Algoritmos de semelhança.
1. Algoritmos de Ensemble Learning (Random Forests, XGBoost, LightGBM, CatBoost)
O que são algoritmos de Ensemble Learning?
Para entender o que eles são, primeiro você precisa saber o que é o Método Ensemble. Esse método consiste no uso simultâneo de vários modelos para obter melhor desempenho do que um único modelo em si.
Conceitualmente, considere a seguinte analogia:
Imagem Terence Shin
Imagine a seguinte situação: em uma sala de aula é dado o mesmo problema de matemática para um único aluno e para um grupo de alunos. Nessa situação, o grupo de alunos pode resolver o problema de forma colaborativa, verificando as respostas uns dos outros e decidindo por unanimidade sobre uma única resposta. Por outro lado, um aluno, sozinho, não tem esse privilégio – ninguém mais está lá para colaborar ou questionar sua resposta.
E assim, a sala de aula com vários alunos é semelhante a um algoritmo de Ensemble com vários algoritmos menores trabalhando juntos para formular uma resposta final.
Os algoritmos de Ensemble Learning são mais úteis para problemas de regressão e classificação ou problemas de aprendizado supervisionado. Devido à sua natureza inerente, eles superam todos os algoritmos tradicionais de Machine Learning, como Naïve Bayes, máquinas vetoriais de suporte e árvores de decisão.
Algoritmos explicativos permitem identificar e compreender variáveis que possuem relação estatisticamente significativa com o resultado. Portanto, em vez de criar um modelo para prever valores da variável de resposta, podemos criar modelos explicativos para entender as relações entre as variáveis no modelo.
Do ponto de vista da regressão, há muita ênfase nas variáveis estatisticamente significativas. Por quê? Quase sempre, você estará trabalhando com uma amostra de dados, que é um subconjunto de toda a população. Para tirar conclusões sobre uma população, dada uma amostra, é importante garantir que haja significância suficiente para fazer uma suposição confiável.
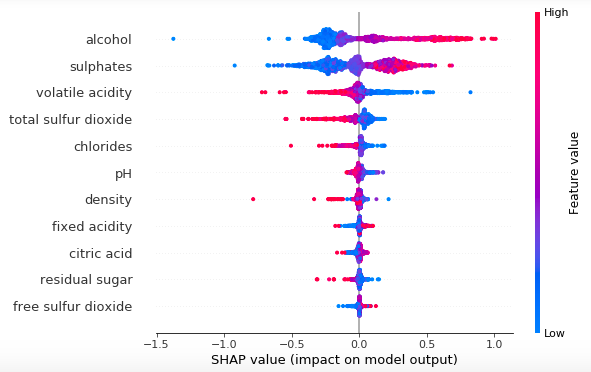
Imagem Terence Shin
Recentemente, também houve o surgimento de duas técnicas populares, SHAP e LIME, que são usadas para interpretar modelos de Machine Learning.
Quando são úteis?
Modelos explicativos são úteis quando você quer entender “por que” uma decisão foi tomada ou quando você quer entender “como” duas ou mais variáveis estão relacionadas entre si.
Na prática, a capacidade de explicar o que seu modelo de Machine Learning faz é tão importante quanto o desempenho do próprio modelo. Se você não puder explicar como um modelo funciona, ninguém confiará nele e ninguém o usará.
Tipos de Algoritmos
Modelos explicativos tradicionais baseados em testes de hipóteses:
Regressão linear
Regressão Logística
Algoritmos para explicar modelos de Machine Learning:
3. Algoritmos de Agrupamento (k-Means, Agrupamento Hierárquico)
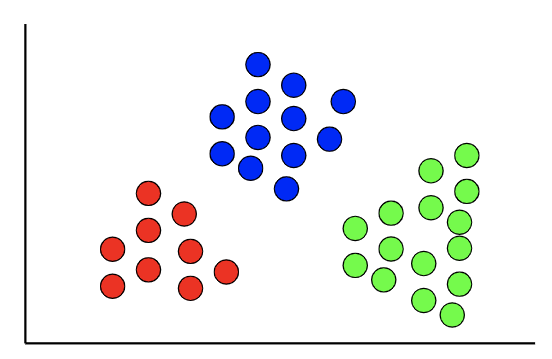
Imagem Terence Shin
O que são algoritmos de agrupamento?
Esses algoritmos são usados para realizar análises de agrupamento, que é uma tarefa de aprendizado não supervisionada que envolve o agrupamento de dados. Ao contrário do aprendizado supervisionado, no qual a variável de destino é conhecida, não há variável de destino nas análises de agrupamento.
Quando são úteis?
O clustering é particularmente útil quando você deseja descobrir padrões e tendências naturais em seus dados. É muito comum que as análises de cluster sejam realizadas na fase de EDA, para descobrir mais informações sobre os dados.
Da mesma forma, o agrupamento permite identificar diferentes segmentos dentro de um dataset com base em diferentes variáveis. Um dos tipos mais comuns de segmentação por cluster é a segmentação de usuários/clientes.
Tipos de Algoritmos
Os dois algoritmos de agrupamento mais comuns são agrupamento k-means e agrupamento hierárquico, embora existam muitos mais:
4. Algoritmos de Redução de Dimensionalidade (PCA, LDA)
O que são algoritmos de redução de dimensionalidade?
Os algoritmos de redução de dimensionalidade referem-se a técnicas que reduzem o número de variáveis de entrada (ou variáveis de recursos) em um dataset. A redução de dimensionalidade é essencialmente usada para lidar com a maldição da dimensionalidade, um fenômeno que afirma, “à medida que a dimensionalidade (o número de variáveis de entrada) aumenta, o volume do espaço cresce exponencialmente resultando em dados esparsos.
Quando são úteis?
As técnicas de redução de dimensionalidade são úteis em muitos casos:
Eles são extremamente úteis quando você tem centenas ou até milhares de recursos em um dataset e precisa selecionar alguns.
Eles são úteis quando seus modelos de ML estão super ajustando os dados, o que implica que você precisa reduzir o número de recursos de entrada.
Tipos de Algoritmos
Abaixo estão os dois algoritmos de redução de dimensionalidade mais comuns:
Algoritmos de similaridade são aqueles que computam a similaridade de pares de registros/nós/pontos de dados/texto. Existem algoritmos de similaridade que comparam a distância entre dois pontos de dados, como a distância euclidiana, e também existem algoritmos de similaridade que calculam a similaridade de texto, como o Algoritmo Levenshtein.
Quando são úteis?
Esses algoritmos podem ser usados em uma variedade de aplicações, mas são particularmente úteis para recomendação.
Quais artigos o Medium deve recomendar a você com base no que você leu anteriormente?
Qual música o Spotify deve recomendar com base nas músicas que você já gostou?
Quais produtos a Amazon deve recomendar com base no seu histórico de pedidos?
Estes são apenas alguns dos muitos exemplos em que algoritmos de similaridade e recomendação são usados em nossas vidas cotidianas.
Tipos de Algoritmos
Abaixo está uma lista não exaustiva de alguns algoritmos de similaridade. Se você quiser ler sobre mais algoritmos de distância, confira este artigo. E se você também se interessar por algoritmos de similaridade de strings, leia este artigo.
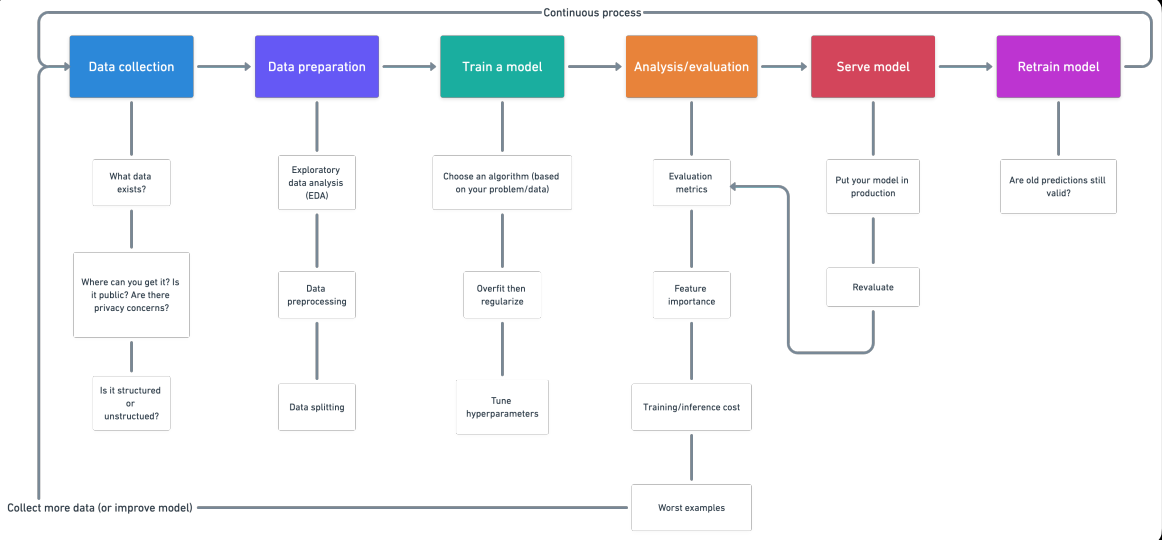
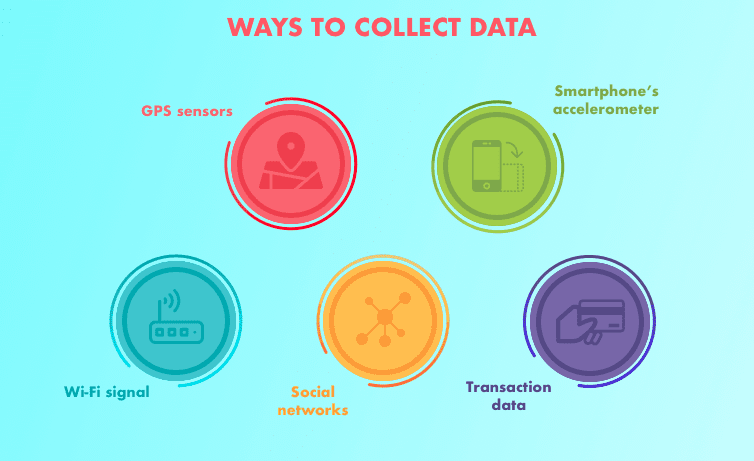
Aqui você verá as várias etapas envolvidas em um projeto de Machine Learning (ML). Existem etapas padrões que você deve seguir para um projeto de Ciência de Dados. Para qualquer projeto, primeiro, temos que coletar os dados de acordo com nossas necessidades de negócios. A próxima etapa é limpar os dados como remover valores, remover outliers, lidar com conjuntos de dados desequilibrados, alterar variáveis categóricas para valores numéricos, etc.
Depois do treinamento de um modelo, use vários algoritmos de aprendizado de máquina e aprendizado profundo. Em seguida, é feita a avaliação do modelo usando diferentes métricas, como recall, pontuação f1, precisão, etc. Finalmente, a implantação do modelo na nuvem e retreiná-lo. Então vamos começar:
Fluxo de trabalho do projeto de Aprendizado de Máquina
1. Coleta de dados
Perguntas a serem feitas:
Que problema deve ser resolvido?
Que dados existem?
Onde você pode obter esses dados? São públicos?
Existem preocupações com a privacidade?
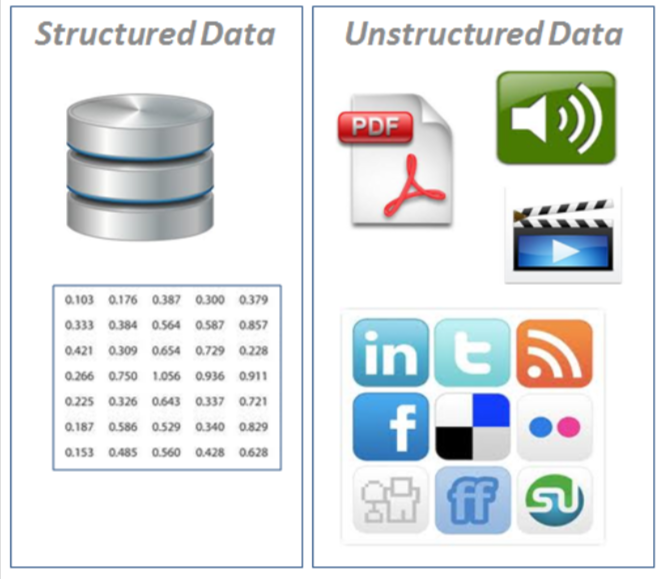
É estruturado ou não estruturado?
Tipos de dados
Dados estruturados: aparecem em formato tabular (estilo linhas e colunas, como o que você encontraria em uma planilha do Excel). Ele contém diferentes tipos de dados, por exemplo: numéricos, categóricos, séries temporais.
Nominal / categórico – Uma coisa ou outra (mutuamente exclusivo). Por exemplo, para balanças de automóveis, a cor é uma categoria. Um carro pode ser azul, mas não branco. Um pedido não importa.
Numérico: qualquer valor contínuo em que a diferença entre eles importa. Por exemplo, ao vender casas o valor de R$ 107.850,00 é maior do que R$ 56.400,00.
Ordinal: Dados que têm ordem, mas a distância entre os valores é desconhecida. Por exemplo, uma pergunta como: como você classificaria sua saúde de 1 a 5? 1 sendo pobre, 5 sendo saudável. Você pode responder 1,2,3,4,5, mas a distância entre cada valor não significa necessariamente que uma resposta de 5 é cinco vezes melhor do que uma resposta de 1.
Séries temporais: dados ao longo do tempo. Por exemplo, os valores históricos de venda de Bulldozers de 2012-2018.
Dados não estruturados: dados sem estrutura rígida (imagens, vídeo, fala, texto em linguagem natural)
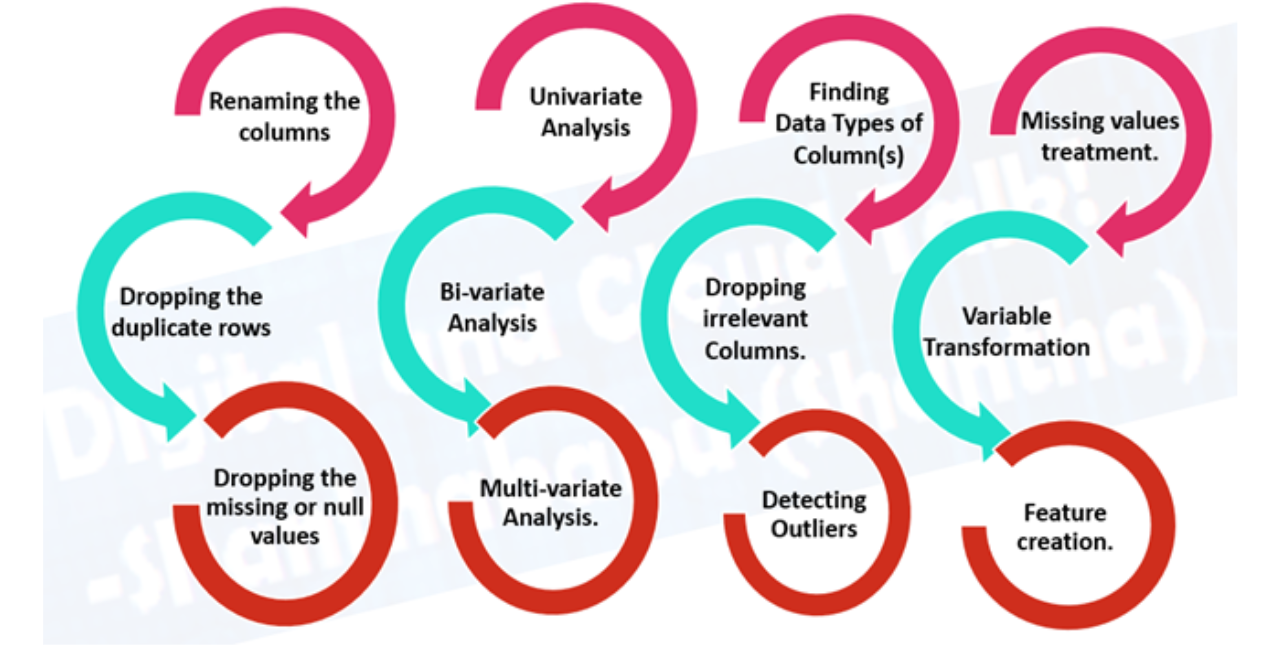
2. Preparação de dados
2.1 Análise Exploratória de Dados (EDA), aprendendo sobre os dados com os quais você está trabalhando
Quais são as variáveis de recursos (entrada) e as variáveis de destino (saída)? Por exemplo, para prever doenças cardíacas, as variáveis de recursos podem ser a idade, peso, frequência cardíaca média e nível de atividade física de uma pessoa. E a variável de destino será a informação se eles têm ou não uma doença.
Que tipo de dado você tem? Estruturado, não estruturado, numérico, séries temporais. Existem valores ausentes? Você deve removê-los ou preenchê-los com imputação de recursos.
Onde estão os outliers? Quantos deles existem? Por que eles estão lá? Há alguma pergunta que você possa fazer a um especialista de domínio sobre os dados? Por exemplo, um médico cardiopata poderia lançar alguma luz sobre seu dataset de doenças cardíacas?
2.2 Pré-processamento de dados, preparando seus dados para serem modelados.
Imputação de recursos: preenchimento de valores ausentes, um modelo de aprendizado de máquina não pode aprender com dados que não estão lá.
Imputação única: Preencha com a média, uma mediana da coluna;
Múltiplas imputações: modele outros valores ausentes e com o que seu modelo encontrar;
KNN (k-vizinhos mais próximos): Preencha os dados com um valor de outro exemplo semelhante;
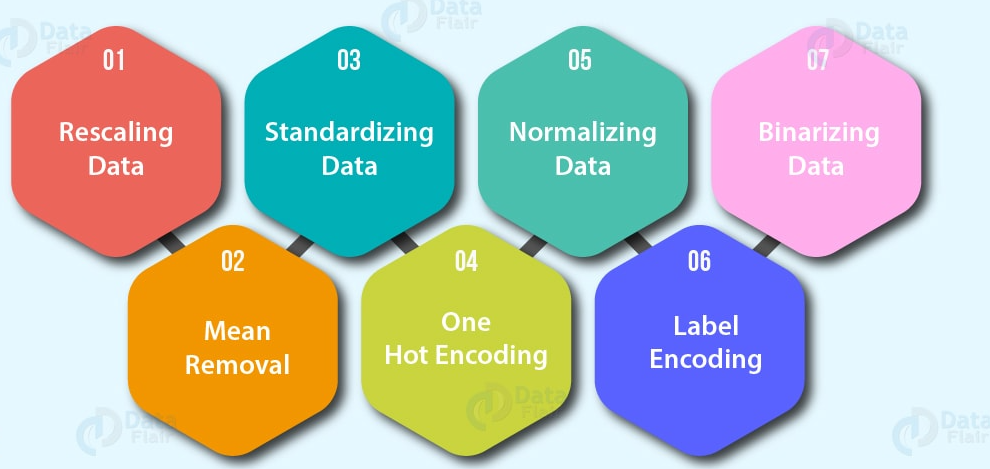
Codificação de recursos (transformando valores em números). Um modelo de aprendizado de máquina exige que todos os valores sejam numéricos.
Uma codificação rápida: Transforme todos os valores exclusivos em listas de 0 e 1, onde o valor de destino é 1 e o resto são 0s. Por exemplo, quando as cores de um carro são verdes, vermelhas, azuis, verdes, o futuro das cores de um carro seria representado como [1, 0 e 0] e um vermelho seria [0, 1 e 0].
Codificador de rótulo:Transforme rótulos em valores numéricos distintos. Por exemplo, se suas variáveis de destino forem animais diferentes, como cachorro, gato, pássaro, eles podem se tornar 0, 1 e 2, respectivamente.
Codificação de incorporação: aprenda uma representação entre todos os diferentes pontos de dados. Por exemplo, um modelo de linguagem é uma representação de como palavras diferentes se relacionam entre si. A incorporação também está se tornando mais amplamente disponível para dados estruturados (tabulares).
Normalização de recursos (dimensionamento) ou padronização: quando suas variáveis numéricas estão em escalas diferentes (por exemplo, number_of_bathroom está entre 1 e 5 e size_of_land entre 500 e 20000 pés quadrados), alguns algoritmos de aprendizado de máquina não funcionam muito bem. O dimensionamento e a padronização ajudam a corrigir isso.
Engenharia de recursos: transforma os dados em uma representação (potencialmente) mais significativa, adicionando conhecimento do domínio.
Decompor;
Discretização: transformando grandes grupos em grupos menores;
Recursos de cruzamento e interação: combinação de dois ou mais recursos;
Características do indicador: usar outras partes dos dados para indicar algo potencialmente significativo.
Seleção de recursos: selecionar os recursos mais valiosos de seu dataset para modelar. Potencialmente reduzindo o overfitting e o tempo de treinamento (menos dados gerais e menos dados redundantes para treinar) e melhorando a precisão.
Redução de dimensionalidade: Um método comum de redução de dimensionalidade, PCA ou análise de componente principal, toma um grande número de dimensões (recursos) e usa álgebra linear para reduzi-los a menos dimensões. Por exemplo, digamos que você tenha 10 recursos numéricos, você poderia executar o PCA para reduzi-los a 3;
Importância do recurso (pós-modelagem): ajuste um modelo a um dataset, inspecione quais recursos foram mais importantes para os resultados e remova os menos importantes;
Os métodos Wrapper geram um subconjunto “candidato”, contendo atributos selecionados no conjunto de treinamento, e utilizam a precisão resultante do classificador para avaliar o subconjunto de atributos “candidatos”.
Lidando com desequilíbrios: seus dados têm 10.000 exemplos de uma classe, mas apenas 100 exemplos de outra?
Colete mais dados (se puder);
Use o pacote scikit-learn-contribimbalanced- learn;
Use SMOTE: técnica desobreamostragem de minoria sintética. Ele cria amostras sintéticas de sua classe secundária para tentar nivelar o campo de jogo.
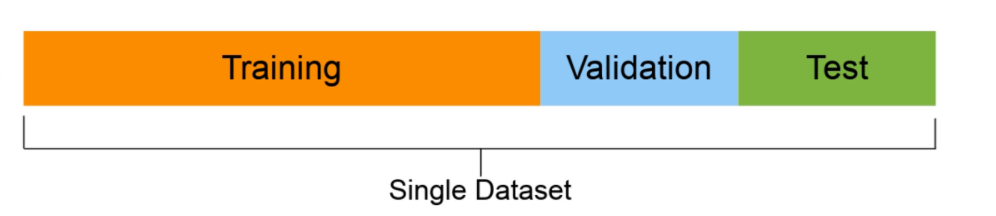
2.3 Divisão de dados
Conjunto de treinamento: geralmente o modelo aprende com 70-80% dos dados;
Conjunto de validação: normalmente os hiperparâmetros do modelo são ajustados com 10-15% dos dados;
Conjunto de teste: geralmente o desempenho final dos modelos é avaliado com 10-15% dos dados. Se você fizer certo os resultados no conjunto de teste fornecerão uma boa indicação de como o modelo deve funcionar no mundo real. Não use este dataset para ajustar o modelo.
Algoritmos não supervisionados – Clustering, redução de dimensionalidade (PCA, Autoencoders, t-SNE), Uma detecção de anomalia.
Tipos de aprendizagem
Aprendizagem em lote;
Aprendizagem online;
Aprendizagem de transferência;
Aprendizado ativo;
Ensembling.
Plataforma para detecção e segmentação de objetos.
Engenharia de atributos
Seleção de atributos
Tipos de Algoritmos e Métodos: Filter Methods, Wrapper Methods, Embedded Methods;
Seleção de Features com Python;
Testes estatísticos: podem ser usados para selecionar os atributos que possuem forte relacionamento com a variável que estamos tentando prever. Os métodos disponíveis são:
f_classif: é adequado quando os dados são numéricos e a variável alvo é categórica.
mutual_info_classif é mais adequado quando não há uma dependência linear entre as features e a variável alvo.
f_regression aplicado para problemas de regressão.
Chi2: Mede a dependência entre variáveis estocásticas, o uso dessa função “elimina” os recursos com maior probabilidade de serem independentes da classe e, portanto, irrelevantes para a classificação;
Recursive Feature Elimination – RFE: Remove recursivamente os atributos e constrói o modelo com os atributos remanescentes, ou seja, os modelos são construídos a partir da remoção de features;
Feature Importance: Métodos ensembles como o algoritmo Random Forest, podem ser usados para estimar a importância de cada atributo. Ele retorna um score para cada atributo, quanto maior o score, maior é a importância desse atributo.
Ajuste e regularização
Underfitting – acontece quando seu modelo não funciona tão bem quanto você gostaria. Tente treinar para um modelo mais longo ou mais avançado.
Overfitting – acontece quando sua perda de validação começa a aumentar ou quando o modelo tem um desempenho melhor no conjunto de treinamento do que no conjunto de testes.
Regularização: uma coleção de tecnologias para prevenir / reduzir overfitting (por exemplo, L1, L2, Dropout, Parada antecipada, Aumento de dados, normalização em lote).
Ajuste de hiperparâmetros – execute uma série de experimentos com configurações diferentes e veja qual funciona melhor.
4. Análise / Avaliação
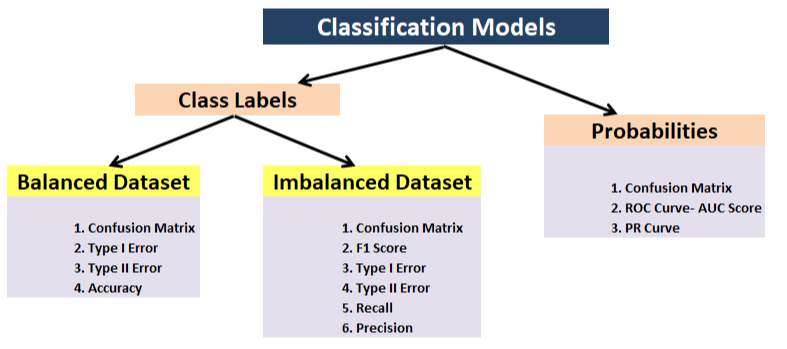
Avaliação de métricas
Classificação – Acurácia, precisão, recall, F1, matriz de confusão, precisão média (detecção de objeto);
Regressão – MSE, MAE, R ^ 2;
Métrica baseada em tarefas – por exemplo, para um carro que dirige sozinho, você pode querer saber o número de desengates.
Engenharia de atributos
Custo de treinamento / inferência.
5. Modelo de Serviço (implantação de um modelo)
Coloque o modelo em produção;
Ferramentas que você pode usar: TensorFlow Servinf, PyTorch Serving, Google AI Platform, Sagemaker;
MLOps: onde a engenharia de software encontra o aprendizado de máquina, basicamente toda a tecnologia necessária em torno de um modelo de aprendizado de máquina para que funcione na produção.
Usar o modelo para fazer previsões;
Reavaliar.
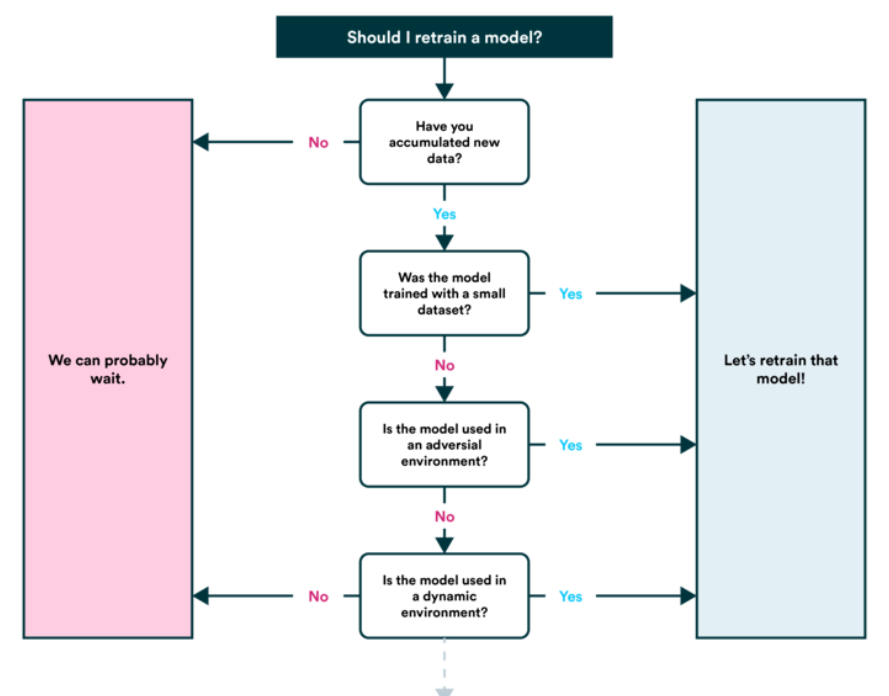
6. Modelo de retreinamento
O modelo ainda é válido para novas cargas de trabalho?
Veja o desempenho do modelo após a veiculação (ou antes da veiculação) com base em várias métricas de avaliação e reveja as etapas acima conforme necessário. Lembre-se de que o aprendizado de máquina é muito experimental, então é aqui que você deverá rastrear seus dados e experimentos;
Você também verá que as previsões do seu modelo começam a “envelhecer” ou “flutuar”, como quando as fontes de dados mudam ou atualizam (novo hardware, etc.). É quando você deverá retreiná-lo.
O Python está bem estabelecido como a linguagem ideal para ciência de dados e aprendizado de máquina, e isso se deve em parte à biblioteca de ML de código aberto PyTorch.
A combinação do PyTorch com ferramentas poderosas de construção de rede neural profunda e fáceis de uso, torna-o uma escolha popular entre cientistas de dados. À medida que sua popularidade cresce, mais e mais empresas estão mudando do TensorFlow para o PyTorch, tornando-se agora o melhor momento para começar a usar o PyTorch.
Hoje, vamos te ajudar a entender o que torna o PyTorch tão popular, alguns fundamentos do uso dessa biblioteca e ajudá-lo a fazer seus primeiros modelos computacionais.
O que é o PyTorch?
O PyTorch é uma biblioteca Python de aprendizado de máquina de código aberto usada para implementações de aprendizado profundo, como visão computacional (usando TorchVision) e processamento de linguagem natural. Essa biblioteca foi desenvolvida pelo laboratório de pesquisa de IA do Facebook (FAIR) em 2016 e, desde então, é adotada nos campos da ciência de dados e ML.
O PyTorch torna o aprendizado de máquina intuitivo para aqueles que já estão familiarizados com Python e tem ótimos recursos como suporte OOP e gráficos de computação dinâmica.
Junto com a construção de redes neurais profundas, o PyTorch também é ótimo para cálculos matemáticos complexos por causa de sua aceleração de GPU. Esse recurso permite que o PyTorch use a GPU do seu computador para acelerar enormemente os cálculos.
Essa combinação de recursos exclusivos e a simplicidade incomparável do PyTorch o torna uma das bibliotecas de aprendizado profundo mais populares, competindo apenas com o TensorFlow pelo primeiro lugar.
Por que usar o PyTorch?
Antes do PyTorch, os desenvolvedores usavam cálculos avançados para encontrar as relações entre erros retro-propagados e peso do nó. Redes neurais mais profundas exigiam operações cada vez mais complicadas, o que restringia o aprendizado de máquina em escala e acessibilidade.
Agora, podemos usar bibliotecas de ML para completar automaticamente todo esse cálculo! As bibliotecas de ML podem computar redes de qualquer tamanho ou formato em questão de segundos, permitindo que mais desenvolvedores criem redes maiores e melhores.
O PyTorch leva essa acessibilidade um passo adiante, comportando-se como o Python padrão. Em vez de aprender uma nova sintaxe, você pode usar o conhecimento existente de Python para começar rapidamente. Além disso, você pode usar bibliotecas Python adicionais com PyTorch, como depuradores populares como o PyCharm.
PyTorch vs. TensorFlow
A principal diferença entre PyTorch e TensorFlow é a escolha entre simplicidade e desempenho: o PyTorch é mais fácil de aprender (especialmente para programadores Python), enquanto o TensorFlow tem uma curva de aprendizado, mas tem um desempenho melhor e é mais usado.
Popularidade: Atualmente, o TensorFlow é a ferramenta ideal para profissionais e pesquisadores do setor porque foi lançado 1 ano antes do PyTorch. No entanto, a taxa de usuários do PyTorch está crescendo mais rápido do que a do TensorFlow, sugerindo que o PyTorch pode em breve ser o mais popular.
Paralelismo de dados: O PyTorch inclui paralelismo de dados declarativo, em outras palavras, ele distribui automaticamente a carga de trabalho do processamento de dados em diferentes GPUs para acelerar o desempenho. O TensorFlow tem paralelismo, mas exige que você atribua o trabalho manualmente, o que costuma ser demorado e menos eficiente.
Gráficos dinâmicos vs. estáticos: PyTorch tem gráficos dinâmicos por padrão que respondem a novos dados imediatamente. O TensorFlow tem suporte limitado para gráficos dinâmicos usando o TensorFlow Fold, mas usa principalmente gráficos estáticos.
Integrações: PyTorch é bom para usar em projetos na AWS por causa de sua estreita conexão por meio do TorchServe. O TensorFlow está bem integrado com o Google Cloud e é adequado para aplicativos móveis devido ao uso da API Swift.
Visualização: O TensorFlow tem ferramentas de visualização mais robustas e oferece um controle mais preciso sobre as configurações do gráfico. A ferramenta de visualização Visdom da PyTorch ou outras bibliotecas de plotagem padrão, como matplotlib, não são tão completas quanto o TensorFlow, mas são mais fáceis de aprender.
Fundamentos do PyTorch
Tensores
Os tensores PyTorch são variáveis indexadas (arrays) multidimensionais usadas como base para todas as operações avançadas. Ao contrário dos tipos numéricos padrão, os tensores podem ser atribuídos para usar sua CPU ou GPU para acelerar as operações.
Eles são semelhantes a uma matriz NumPy n-dimensional e podem até ser convertidos em uma matriz NumPy em apenas uma única linha.
Tensores vêm em 5 tipos:
FloatTensor: 32-bit float
DoubleTensor: 64-bit float
HalfTensor: 16-bit float
IntTensor: 32-bit int
LongTensor: 64-bit int
Como acontece com todos os tipos numéricos, você deseja usar o menor tipo que atenda às suas necessidades para economizar memória. O PyTorch usa FloatTensorcomo o tipo padrão para todos os tensores, mas você pode mudar isso usando:
torch.set_default_tensor_type(t)
Para inicializar doisFloatTensors:
import torch
# initializing tensors
a = torch.tensor(2)
b = torch.tensor(1)
Os tensores podem ser usados como outros tipos numéricos em operações matemáticas simples.
Você também pode mover tensores para serem manipulados pela GPU usando cuda.
if torch.cuda.is_available():
x = x.cuda()
y = y.cuda()
x + y
Como tensores são matrizes em PyTorch, você pode definir tensores para representar uma tabela de números:
ones_tensor = torch.ones((2, 2)) # tensor containing all ones
rand_tensor = torch.rand((2, 2)) # tensor containing random values
Aqui, estamos especificando que nosso tensor deve ser um quadrado 2×2. O quadrado é preenchido com todos os 1 ao usar a função ones() ou números aleatórios ao usar a função rand().
Redes neurais
PyTorch é comumente usado para construir redes neurais devido aos seus modelos de classificação excepcionais, como classificação de imagem ou redes neurais convolucionais (CNN).
As redes neurais são camadas de nós de dados conectados e ponderados. Cada camada permite que o modelo identifique a qual classificação os dados de entrada correspondem.
As redes neurais são tão boas quanto seu treinamento e, portanto, precisam de grandes conjuntos de dados e estruturas GAN, que geram dados de treinamento mais desafiadores com base naqueles já dominados pelo modelo.
O PyTorch define redes neurais usando o pacotetorch.nn, que contém um conjunto de módulos para representar cada camada de uma rede.
Cada módulo recebe tensores de entrada e calcula os tensores de saída, que trabalham juntos para criar a rede. O pacote torch.nntambém define funções de perda que usamos para treinar redes neurais.
As etapas para construir uma rede neural são:
Construção: Crie camadas de rede neural, configure parâmetros, estabeleça pesos e tendências.
Propagação direta: Calcule a saída prevista usando seus parâmetros. Meça o erro comparando a saída prevista e a real.
Retropropagação: Depois de encontrar o erro, tire a derivada da função de erro em termos dos parâmetros de nossa rede neural. A propagação para trás nos permite atualizar nossos parâmetros de peso.
Otimização iterativa: Minimize erros usando otimizadores que atualizam parâmetros por meio de iteração usando gradiente descendente.
Aqui está um exemplo de uma rede neural em PyTorch:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
O nn.moduledesigna que esta será uma rede neural e então a definimos com duas camadas conv2d, que realizam uma convolução 2D, e 3 camadas lineares, que realizam transformações lineares.
A seguir, definimos um método direto para descrever como fazer a propagação direta. Não precisamos definir um método de propagação para trás porque PyTorch inclui uma funçãobackwards()por padrão.
Não se preocupe se isso parece confuso agora, depois vamos cobrir implementações mais simples do PyTorch neste tutorial.
Autograd
Autograd é um pacote PyTorch usado para calcular derivadas essenciais para operações de rede neural. Essas derivadas são chamadas de gradientes. Durante uma passagem para frente, o autograd registra todas as operações em um tensor habilitado para gradiente e cria um gráfico acíclico para encontrar a relação entre o tensor e todas as operações. Essa coleção de operações é chamada de diferenciação automática.
As folhas deste gráfico são tensores de entrada e as raízes são tensores de saída. O Autograd calcula o gradiente traçando o gráfico da raiz à folha e multiplicando cada gradiente usando a regra da cadeia.
Depois de calcular o gradiente, o valor da derivada é preenchido automaticamente como um atributograddo tensor.
import torch
# pytorch tensor
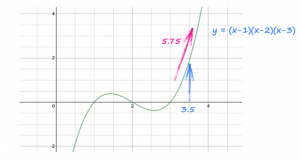
x = torch.tensor(3.5, requires_grad=True)
# y is defined as a function of x
y = (x-1) * (x-2) * (x-3)
# work out gradients
y.backward()
Por padrão,requires_gradé definido comofalsee o PyTorch não rastreia gradientes. Especificarrequires_gradcomoTruedurante a inicialização fará o PyTorch rastrear gradientes para este tensor em particular sempre que realizarmos alguma operação nele.
Este código olha paraye vê que ele veio de(x-1) * (x-2) * (x-3)e calcula automaticamente o gradiente dy / dx,3x^2 – 12x + 11.
A instrução também calcula o valor numérico desse gradiente e o coloca dentro do tensorxao lado do valor real dex, 3.5.
Juntos, o gradiente é 3 * (3.5 * 3.5) – 12 * (3.5) + 11 = 5.75.
Figura 01
Os gradientes se acumulam por padrão, o que pode influenciar o resultado se não for redefinido. Use model.zero_grad() para zerar novamente seu gráfico após cada gradiente.
Otimizadores
Os otimizadores permitem que você atualize os pesos e tendências dentro de um modelo para reduzir o erro. Isso permite que você edite como seu modelo funciona sem ter que refazer tudo.
Todos os otimizadores PyTorch estão contidos no pacotetorch.optim, com cada esquema de otimização projetado para ser útil em situações específicas. O módulo torch.optimpermite que você construa um esquema de otimização abstrato apenas passando uma lista de parâmetros. O PyTorch tem muitos otimizadores para escolher, o que significa que quase sempre há um que melhor se adapta às suas necessidades.
Por exemplo, podemos implementar o algoritmo de otimização comum, SGD (Stochastic Gradient Descent), para suavizar nossos dados.
Depois de atualizar o modelo, useoptimizer.step()para dizer ao PyTorch para recalcular o modelo.
Sem usar otimizadores, precisaríamos atualizar manualmente os parâmetros do modelo, um por um, usando um loop:
for params in model.parameters():
params -= params.grad * learning_rate
No geral, os otimizadores economizam muito tempo, permitindo que você otimize a ponderação dos dados e altere o modelo sem refazê-lo.
Gráficos de computação com PyTorch
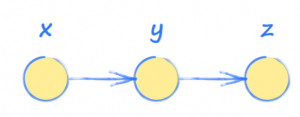
Para entender melhor o PyTorch e as redes neurais, é importante praticar com gráficos de computação. Esses gráficos são essencialmente uma versão simplificada de redes neurais com uma sequência de operações usadas para ver como a saída de um sistema é afetada pela entrada.
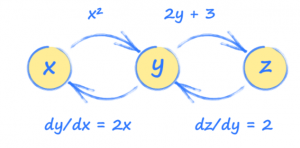
Em outras palavras, a entradaxé usada para encontrary, que então é usada para encontrar a saída z.
Figura 02
Imagine que yezsão calculados assim:
y = x^2
z = 2y + 3
No entanto, estamos interessados em como a saídazmuda com a entradax, então precisaremos fazer alguns cálculos:
dz/dx = (dz/dy) * (dy/dx)
dz/dx = 2.2x
dz/dx = 4x
Usando isso, podemos ver que a entrada x = 3,5 fará com que z = 14.
Saber definir cada tensor em termos dos outros (y e zem termos dex,zem termos dey, etc.) permite que o PyTorch construa uma imagem de como esses tensores estão conectados.
Figura 03
Esta imagem é chamada de gráfico computacional e pode nos ajudar a entender como o PyTorch funciona nos bastidores. Usando esse gráfico, podemos ver como cada tensor será afetado por uma mudança em qualquer outro tensor. Esses relacionamentos são gradientes e são usados para atualizar uma rede neural durante o treinamento.
Esses gráficos são muito mais fáceis de fazer usando o PyTorch do que manualmente. Então, agora que entendemos o que está acontecendo nos bastidores, vamos tentar fazer esse gráfico.
import torch
# set up simple graph relating x, y and z
x = torch.tensor(3.5, requires_grad=True)
y = x*x
z = 2*y + 3
print("x: ", x)
print("y = x*x: ", y)
print("z= 2*y + 3: ", z)
# work out gradients
z.backward()
print("Working out gradients dz/dx")
# what is gradient at x = 3.5
print("Gradient at x = 3.5: ", x.grad)
Isso mostra quez = 14, exatamente como encontramos manualmente acima!
Mãos à obra com PyTorch: gráfico computacional de vários caminhos
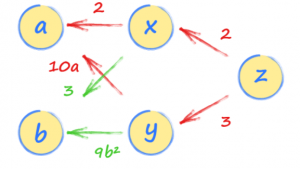
Agora que você viu um gráfico computacional com um único conjunto relacional, vamos tentar um exemplo mais complexo.
Primeiro, defina dois tensores, aeb, para funcionar como nossas entradas. Certifique-se de definirrequires_grad=Truepara que possamos fazer gradientes na linha.
import torch
# set up simple graph relating x, y and z
a = torch.tensor(3.0, requires_grad=True)
b = torch.tensor(2.0, requires_grad=True)
Em seguida, configure as relações entre nossa entrada e cada camada de nossa rede neural, x, y e z. Observe que z é definido em termos de x e y, enquanto x e y são definidos usando nossos valores de entrada a e b.
import torch
# set up simple graph relating x, y and z
a = torch.tensor(3.0, requires_grad=True)
b = torch.tensor(2.0, requires_grad=True)
x = 2*a + 3*b
y = 5*a*a + 3*b*b*b
z = 2*x + 3*y
Isso cria uma cadeia de relacionamentos que o PyTorch pode seguir para entender todos os relacionamentos entre os dados.
Agora podemos calcular o gradientedz/da seguindo o caminho de volta dez para a.
Existem dois caminhos, um passando porxe outro pory. Você deve seguir os dois e adicionar as expressões de ambos os caminhos. Isso faz sentido porque ambos os caminhos deaazcontribuem para o valor dez.
Teríamos encontrado o mesmo resultado se tivéssemos calculadodz/dausando a regra da cadeia do cálculo.
Figura 04
O primeiro caminho porxnos dá2 * 2e o segundo caminho por y nos dá3 * 10a. Assim, a taxa na qualzvaria coma é4 + 30a.
Seaé 22, entãodz/da é4+30∗2=64.
Podemos confirmar isso no PyTorch adicionando uma propagação para trás dez e pedindo o gradiente (ou derivado) dea.
import torch
# set up simple graph relating x, y and z
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(1.0, requires_grad=True)
x = 2*a + 3*b
y = 5*a*a + 3*b*b*b
z = 2*x + 3*y
print("a: ", a)
print("b: ", b)
print("x: ", x)
print("y: ", y)
print("z: ", z)
# work out gradients
z.backward()
print("Working out gradient dz/da")
# what is gradient at a = 2.0
print("Gradient at a=2.0:", a.grad)
Próximos passos para o seu aprendizado
Parabéns, você concluiu seu início rápido de PyTorch e Redes Neurais! A conclusão de um gráfico computacional é uma parte essencial da compreensão de redes de aprendizado profundo.
À medida que você aprender habilidades e aplicativos avançados de aprendizado profundo, você desejará explorar:
PLN ou Processamento de Linguagem Natural é a forma como as máquinas entendem e lidam com as linguagens humanas. Esta técnica lida com dados não estruturados de texto e embora seja difícil de dominá-la é fácil de entender seus conceitos.
Cientes disso, devemos entender que a disponibilidade e geração de dados são complexidades envolvidas, em geral, com qualquer tipo de caso de uso de Machine Learning (ML). Mas o PLN é o campo onde esse problema é relativamente menos pronunciado, pois há muitos dados de texto ao nosso redor. Os e-mails que escrevemos, os comentários que postamos, os blogs que escrevemos são alguns exemplos.
Tipos:
1) Reconhecimento de entidade nomeada
O processo de extração de entidades de nomeadas no texto, nome de pessoas, países, organizações, extrai informações úteis que podem ser usadas para vários fins como: classificação, recomendação, análise de sentimento, entre outros.
Um chatbot é o exemplo de uso mais comum. A consulta do usuário é entendida por meio das entidades no texto e respondida de acordo com elas.
2) Resumo do texto
É onde os conceitos-chave do texto são extraídos e o resumo parafraseado é construído em torno dele. Isso pode ser útil em resultados de pesquisas extensos.
3) Tradução
Conversão de texto de uma linguagem para outra. O tradutor do Google é o exemplo mais comum que temos.
4) Fala em texto
Converte voz em dados de texto, sendo o exemplo mais comum os assistentes em nossos smartphones.
5) NLU
Natural Language Understanding é uma forma de entender as palavras e frases no que diz respeito ao contexto. Eles são úteis na análise de sentimento dos comentários de usuários e consumidores. Modelos NLU são comumente usados na criação de chatbot.
6) NLG
Natural Language Generation vai além do processamento da máquina ou da compreensão do texto. Essa é a capacidade das máquinas de escrever conteúdo por si mesmas. Uma rede profunda, usando Transformers GTP-3, escreveu este artigo.
Iniciando
Os insights sobre como o Machine Learning lida com dados não estruturados de texto são apresentados por meio de um exemplo básico de classificação de texto.
Entrada:
Uma coluna de ‘texto’ com comentários de revisão por usuário. Uma coluna de ‘rótulo’ com um sinalizador para indicar se é um comentário positivo ou negativo.
Saída:
A tarefa é classificar os comentários com base no sentimento como positivos ou negativos.
Etapas de pré-processamento
Um pré-processamento será feito para transformar os dados em algoritmos de ML. Como o texto não pode ser tratado diretamente por máquinas, ele é convertido em números. Dessa forma, os dados não estruturados são convertidos em dados estruturados.
NLTK é uma biblioteca Python que pode ajudar você nos casos de uso de PLN e atende muito bem às necessidades de pré-processamento.
1) Remoção de palavras irrelevantes
Palavras irrelevantes ocorrem com frequência e não acrescentam muito significado ao texto. Os mecanismos de pesquisa também são programados para ignorar essas palavras. Podemos citar como exemplo as palavras: de, o, isso, tem, seu, o quê, etc.
A remoção dessas palavras ajuda o código a se concentrar nas principais palavras-chave do texto que adicionam mais contexto.
Aplicando a remoção de palavras irrelevantes a um data frame do Pandas com uma coluna de ‘texto’.
input_df[‘text’] = input_df[‘text’].apply(lambda x: “ “.join(x for x in x.split() if x not in stop))
2) Remoção de emojis e caracteres especiais
Os comentários do usuário são carregados de emojis e caracteres especiais. Eles são representados como caracteres Unicode no texto, denotados como U +, variando de U + 0000 a U + 10FFFF.
Flexão é a modificação de uma palavra para expressar diferentes categorias gramaticais como tempo verbal, voz, aspecto, pessoa, número, gênero e humor. Por exemplo, as derivações de ‘venha’ são ‘veio’, ‘vem’. Para obter o melhor resultado, as flexões de uma palavra devem ser tratadas da mesma maneira. Para lidar com isso usamos a lematização.
A lematização resolve as palavras em sua forma de dicionário (conhecida como lema), para a qual requer dicionários detalhados nos quais o algoritmo pode pesquisar e vincular palavras aos lemas correspondentes.
Por exemplo, as palavras “correr”, “corre” e “correu” são todas formas da palavra “correr”, portanto “correr” é o lema de todas as palavras anteriores.
a) Stemming
Stemming é uma abordagem baseada em regras que converte as palavras em sua palavra raiz (radical) para remover a flexão sem se preocupar com o contexto da palavra na frase. Isso é usado quando o significado da palavra não é importante. A palavra raiz pode ser uma palavra sem sentido em si mesma.
def stemming_text(text):
stem_words = [porter.stem(w) for w in w_tokenizer.tokenize(text)]
return ‘ ‘.join(stem_words)
input_df[‘text’] = input_df[‘text’].apply(lambda x: stemming_text(x))
b) Lematização
A lematização, ao contrário de Stemming, reduz as palavras flexionadas adequadamente, garantindo que a palavra raiz (lema) pertence ao idioma. Embora a lematização seja mais lenta em comparação com a Stemming, ela considera o contexto da palavra levando em consideração a palavra anterior, o que resulta em melhor precisão.
Código de explicação:
w_tokenizer = nltk.tokenize.WhitespaceTokenizer()
lemmatizer = nltk.stem.WordNetLemmatizer()
def lemmatize_text(text):
lemma_words = [lemmatizer.lemmatize(w) for w in w_tokenizer.tokenize(text)]
return ‘ ‘.join(lemma_words)
print(lemmatize_text('study'),
lemmatize_text('studying') ,
lemmatize_text('studies'))
Esta é a etapa em que as palavras são convertidas em números, que podem ser processados pelos algoritmos. Esses números resultantes estão na forma de vetores, daí o nome.
1) Modelo Bag of words
Este é o mais básico dos vetorizadores. O vetor formado contém palavras no texto e sua frequência. É como se as palavras fossem colocadas em um saco. A ordem das palavras não é mantida.
Código de explicação:
from sklearn.feature_extraction.text import CountVectorizer
bagOwords = CountVectorizer()
print(bagOwords.fit_transform(text).toarray())
print('Features:', bagOwords.get_feature_names())
Entrada:
text = [“I like the product very much. The quality is very good.”,
Os vetores dos textos 2 e 5 (ao contrário do que se espera), por serem de sentidos opostos, não diferem tanto. A matriz retornada é esparsa.
2) n-gramas
Ao contrário da abordagem do saco de palavras, a abordagem de n-gram depende da ordem das palavras para derivar seu contexto. O n-gram é uma sequência contígua de “n” itens em um texto, portanto, o conjunto de recursos criado com o recurso n-grams terá um número n de palavras consecutivas como recursos. O valor para “n” pode ser fornecido como um intervalo.
Só porque uma palavra aparece com alta frequência não significa que a palavra acrescenta um efeito significativo sobre o sentimento que procuramos. A palavra pode ser comum a todos os textos de amostra. Por exemplo, a palavra ‘product’ em nossa amostra é redundante e não fornece muitas informações relacionadas ao sentimento. Isso apenas aumenta a duração do recurso.
Frequência do termo (TF) – é a frequência das palavras em um texto de amostra.
Frequência inversa do documento (IDF) – destaca a frequência das palavras em outros textos de amostra. Os recursos são raros ou comuns nos textos de exemplo é a principal preocupação aqui.
Quando usamos ambos os TF-IDF juntos (TF * IDF), as palavras de alta frequência em um texto de exemplo que tem baixa ocorrência em outros textos de exemplo recebem maior importância.
No terceiro texto de exemplo, as palavras de valores ‘broken‘ e ‘delivered‘ são raras em todos os textos e recebem pontuação mais alta do que ‘product‘, que é uma palavra recorrente.
Geralmente, esse tipo de cenário terá um desequilíbrio de classe. Os dados de texto incluíam mais casos de sentimento positivo do que negativo. A maneira mais simples de lidar com o desequilíbrio de classe é aumentando os dados com cópias exatas da classe minoritária (neste caso, os cenários de sentimento negativo). Essa técnica é chamada de sobreamostragem.
Algoritmo de Machine Learning
Após a conclusão das etapas de processamento, os dados estão prontos para serem passados para um algoritmo de ML para ajuste e previsão. Este é um processo iterativo no qual um algoritmo adequado é escolhido e o ajuste do hiperparâmetro é feito.
Um ponto a ser observado aqui é que, aparentemente, como qualquer outro problema de ML, as etapas de pré-processamento devem ser tratadas após a divisão de treinamento e teste.
Código de implementação
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
rnd_mdl = RandomForestClassifier()
rnd_mdl.fit(tfidf_result, input_df[‘label’])
#Using the fitted model to predict from the test data
#test_df is the test data and tfidf_result_test is the preprocessed test text data
output_test_pred = rnd_mdl.predict(tfidf_result_test)
#finding f1 score for the generated model
test_f1_score = f1_score(test_df[‘label’], output_test_pred)
Biblioteca pré-construída
Há uma biblioteca pré-construída em NLTK que pontua os dados de texto com base no sentimento. Ele não precisa dessas etapas de pré-processamento. É denominado nltk.sentiment.SentimentAnalyzer.
Finalizando
Existem muitos modelos avançados de Deep Learning pré-treinados disponíveis para PLN. O pré-processamento envolvido, ao usar essas redes profundas, varia consideravelmente da abordagem de ML fornecida aqui.
Esta é uma introdução simples ao interessante mundo da PLN! É um vasto espaço em constante evolução!
Com o aumento significativo de dispositivos computacionais nos últimos anos, a quantidade de dados transmitidos e armazenados cresceu de forma alarmante. Diante disso, os logs de sistema são um artefato essencial para a aplicação das técnicas de detecção de anomalias, pois eles registram os estados e eventos significativos do sistema, ajudando a depurar os comportamentos que não são esperados.
Na indústria é comum registrar informações detalhadas do tempo de execução do software em logs, permitindo que os desenvolvedores e engenheiros de suporte analisem o comportamento do sistema. As ricas informações registradas pelos logs permitem que os desenvolvedores conduzam uma variedade de tarefas de gerenciamento de sistema, como diagnóstico de erros e travamentos, garantia de segurança da aplicação e detecção de anomalias.
A detecção de anomalias desempenha um papel muito importante em várias comunidades, como a de Ciência de Dados, Aprendizado de Máquina, Visão Computacional e Estatística, e é provavelmente o campo mais comum para conduzir uma análise formal e confiável em logs de sistema. Isso, porque é possível detectar coisas que deram errado na execução do processo.
Esse campo, que busca comportamentos anormais do sistema observando os dados de log, permite que os desenvolvedores localizem e resolvam problemas em tempo hábil.
Conceitos básicos
Quando uma instância de dados apresenta um comportamento diferente do que é esperado pelo sistema, ela passa a ser denominada anomalia. O objetivo da detecção de anomalias é determinar todas essas instâncias orientando-se por dados. As anomalias também são chamadas de anormalidades, novidades, desvios ou discrepâncias na literatura de mineração de dados e estatística.
Os desvios podem ser causados por erros nos dados, mas às vezes são indicativos de um novo processo subjacente, anteriormente desconhecido. Agora, vamos conhecer os três tipos de classificação nas quais as anomalias são divididas: anomalias pontuais, anomalias contextuais e anomalias coletivas.
A maioria dos trabalhos na literatura concentra-se em anomalias pontuais, que geralmente representam uma irregularidade ou desvio aleatório que pode não ter uma interpretação particular.
Uma anomalia contextual, também conhecida como anomalia condicional, é uma instância de dados que pode ser considerada anômala em algum contexto específico, por exemplo, o timestamp, um padrão de gasto de dinheiro, a ocorrência de eventos em logs do sistema ou qualquer recurso usado para descrever o comportamento normal.
Anomalias coletivas são um tipo de anomalia que, individualmente, aparece como instâncias normais, e quando observada em grupo, exibe características incomuns.
Aplicações: anomalias robustas
A detecção de anomalias pode ser aplicada em muitos contextos, inclusive para identificar discrepâncias robustas. Nesse caso, temos o LogRobust, uma abordagem de detecção de anomalias baseada em log.
O LogRobust busca uma detecção precisa e robusta, considerando que os dados de log do mundo real estão em constante mudança. Devido à instabilidade dos dados de log, a eficácia das abordagens de detecção de anomalias existentes é significativamente afetada.
A arquitetura do LogRobust adota a rede neural baseada em atenção Bi-LSTM para lidar com as sequências de log instáveis. Já que os eventos de log diferentes têm impactos distintos no resultado da classificação, o mecanismo de atenção foi apresentado ao modelo Bi-LSTM para atribuir pesos diferentes aos eventos de log. Além disso, o impacto do ruído dos dados também pode ser reduzido, pois eventos com ruído tendem a ter menos importância e são mais propensos a receber pouca atenção.
Aplicações: análise de sentimentos
A detecção de anomalias também pode ser utilizada no contexto de análise de sentimentos.
Em seu trabalho, Hudan Studiawan (2020) propõe uma nova técnica de análise de sentimentos baseada em aprendizado profundo para verificar se há atividades anômalas em logs de sistema operacional (SO). Esse problema é considerado análise de sentimento de duas classes: sentimentos positivos e negativos.
Studiawan usou uma técnica de Deep Learning que fornece alta precisão e flexibilidade em relação a dados não vistos anteriormente. Especificamente, é usado um modelo Gated Recurrent Unit para detectar o sentimento nas mensagens de log do sistema operacional.
Em logs do sistema operacional da vida real, o número de mensagens negativas é muito menor do que as positivas, gerando o desbalanceamento de classe. E para alcançar um equilíbrio entre as duas classes de sentimento é usado o método de Tomek link. O equilíbrio produzirá um modelo de aprendizado profundo melhor; portanto, capaz de detectar com mais precisão atividades anômalas.
Para concluir
Por fim, os métodos não-supervisionados são amplamente utilizados quando não se tem dados rotulados.Vários frameworks de Deep Learning que abordam desafios na detecção de anomalias não-supervisionadas são propostos e mostrados para produzir um desempenho de estado da arte.
Kengo Tajiri (2020) propõe um método de monitoramento de sistemas TIC (Tecnologia da Informação e Comunicação) para detecção contínua de anomalias, considerando que as dimensões dos vetores mudam frequentemente. Os métodos de detecção de anomalias baseados em Autoencoders, que treinam um modelo para descrever a “normalidade”, são promissores para monitorar o estado dos sistemas.
Há uma grande necessidade de desenvolver técnicas de detecção de anomalias de uso geral e personalizadas para problemas. Essas metodologias devem ser adaptadas para acompanhar as últimas mudanças na tecnologia que podem resultar em novas vulnerabilidades em vários sistemas. As técnicas de detecção de anomalias precisam ser eficientes o suficiente para capturar a pequena quantidade de outliers em grandes fluxos de dados e também inteligentes o suficiente para detectar anomalias em períodos de tempo curtos ou longos.
Se você quiser continuar aprendendo sobre o tema, confira aqui embaixo as indicações bibliográficas que selecionamos.
Até o próximo tema!
Referências Bibliográficas
AGGARWAL, Charu C. Neural networks and deep learning. Springer, v. 10, p. 978-3, 2018.
CHALAPATHY, Raghavendra; CHAWLA, Sanjay. Deep learning for anomaly detection: A survey. arXiv preprint arXiv:1901.03407, 2019.
CHANDOLA, Varun; BANERJEE, Arindam; KUMAR, Vipin. Anomaly detection: A survey. ACM computing surveys (CSUR), v. 41, n. 3, p. 1-58, 2009.
MA, Rongjun. Anomaly detection for Linux system log. 2020. Dissertação de Mestrado. University of Twente.
PANG, Guansong. Deep Learning for Anomaly Detection: A Review. ACM Computing Surveys (CSUR), v. 54, n. 2, p. 1-38, 2021.
SONG, Xiuyao. Conditional anomaly detection. IEEE Transactions on knowledge and Data Engineering, v. 19, n. 5, p. 631-645, 2007.
STUDIAWAN, Hudan; SOHEL, Ferdous; PAYNE, Christian. Anomaly detection in operating system logs with deep Learning-based sentiment analysis. IEEE Transactions on Dependable and Secure Computing, 2020.
TAJIRI, Kengo et al. Dividing Deep Learning Model for Continuous Anomaly Detection of Inconsistent ICT Systems. In: NOMS 2020-2020 IEEE/IFIP Network Operations and Management Symposium. IEEE, 2020. p. 1-5.
ZHANG, Xu et al. Robust log-based anomaly detection on unstable log data. In: Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2019. p. 807-817.
ZHU, Jieming et al. Tools and benchmarks for automated log parsing. In: 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2019. p. 121-130.
Todo mundo está falando sobre aprendizado de máquina, de uma disciplina acadêmica, ele tornou-se uma das tecnologias mais interessantes em qualquer parte. Incluindo desde a compreensão dos feeds de vídeo em carros autônomos até a personalização de medicamentos, essa tecnologia está se tornando importante em todos os setores. Por isso, te convidamos a conhecer profundamente o livro “Building Machine Learning Pipelines: Automating Model Life Cycles with TensorFlow”.
Escrito pela dupla de autoresHannes Hapke e Catherine Nelson, esse livro busca mostrar como construir um sistema de machine learning padrão que é automatizado e resulta em modelos reproduzíveis.
O que são Machine Learning Pipelines?
Os pipelines de aprendizado de máquina implementam e formalizam processos para acelerar, reutilizar, gerenciar e implantar modelos de aprendizado de máquina. O objetivo deste livro é contribuir para a padronização de projetos de aprendizado de máquina, conduzindo os leitores por todo um pipeline de aprendizado de máquina, de ponta a ponta.
Um pipeline automatizado e reproduzível reduz o esforço necessário para implantar um modelo, assim, o pipeline deve incluir etapas que:
Criem versões de seus dados de maneira eficaz e dê início a uma nova execução de treinamento de modelo
Validem os dados recebidos e verifique a variação de dados
Pré-processem os dados de maneira eficiente para o treinamento e validação do seu modelo
Treinem seus modelos de aprendizado de máquina de maneira eficaz
Acompanhem o treinamento do seu modelo
Analisem e valide seus modelos treinados e ajustados
Implantem o modelo validado
Dimensionem o modelo implantado
Capturem novos dados de treinamento e modelem as métricas de desempenho com ciclos de feedback
O livro
Neste guia prático, Hannes Hapke e Catherine Nelson orientam você nas etapas de automação de um pipeline de aprendizado de máquina usando o ecossistema TensorFlow. Você aprenderá as técnicas e ferramentas que reduzirão o tempo de implantação, assim, você poderá se concentrar no desenvolvimento de novos modelos em vez de manter sistemas legados.
“Building Machine Learning Pipelines” é voltado para cientistas de dados e engenheiros de machine learning, mas também conversa com gerentes de projetos de data science e engenheiros DevOps. Para a leitura da obra, você deve estar confortável com os conceitos básicos de aprendizado de máquina e familiarizado com pelo menos uma estrutura de aprendizado de máquina (por exemplo, PyTorch, TensorFlow, Keras). Os exemplos de aprendizado de máquina neste livro são baseados no TensorFlow e Keras, mas os conceitos principais podem ser aplicados a qualquer estrutura.
Este livro te ajudará a:
Entender as etapas para criar um pipeline de aprendizado de máquina
Criar seu pipeline usando componentes do TensorFlow Extended
Orquestrar seu pipeline de aprendizado de máquina com Apache Beam, Apache Airflow e Kubeflow Pipelines
Trabalhar com dados usando o TensorFlow Data Validation e TensorFlow Transform
Analisar um modelo em detalhes usando o TensorFlow Model Analysis
Examinar a equidade e o viés no desempenho do seu modelo
Implantar modelos com TensorFlow Serving ou TensorFlow Lite para dispositivos móveis
Aprender técnicas de aprendizado de máquina que preservam a privacidade
Os autores
Hannes Hapke
Hannes Hapke é um cientista de dados sênior do Concur Labs no SAP Concur e mestre em Engenharia Elétrica pela Oregon State University. Antes de ingressar no SAP Concur, Hannes resolveu problemas de infraestrutura de aprendizado de máquina em vários setores, incluindo saúde, varejo, recrutamento e energias renováveis. Além disso, Hannes é co-autor de uma publicação sobre processamento de linguagem natural e aprendizado profundo e apresentou-se em várias conferências sobre aprendizado profundo e Python.
Catherine Nelson
Catherine Nelson também é cientista de dados sênior do Concur Labs no SAP Concur e tem PhD em geofísica pela Durham University e mestrado em Ciências da Terra pela Oxford University. Suas principais áreas de foco vão desde ML explainability e análise de modelos até o ML com preservação da privacidade. Enquanto trabalhou como geofísica, ela estudou vulcões antigos e explorou petróleo na Groenlândia.
Gostou da nossa dica? Então, agora é hora de alinhar o livro, sua vontade de aprender, seu tempo e praticar bastante para expandir suas habilidades em machine learning.
Muito se fala sobre a grande procura das empresas por cientistas de dados e os excelentes salários reservados a esses profissionais. Mas quem pode receber esse título, quais habilidades tornam os cientistas de dados tão requisitados e ainda raros no mercado de trabalho?
Para conhecer quais competências você deve desenvolver para se tornar um cientista de dados, e entender que este não é um processo de apenas 6 meses, trazemos aqui a lista produzida por Daniel D. Gutierrez sobre as 10 habilidades essenciais de ciência de dados em 2021.
Gutierrez é cientista de dados, autor de quatro livros de data science, jornalista de tecnologia e professor, tendo ministrado aulas de ciência de dados, aprendizado de máquina (machine learning) e R em nível universitário.
1. Experiência com GPUs
Agora é a hora de entender a grande popularidade das GPUs. A maneira mais fácil de começar a usar GPUs para aprendizado de máquina é começar com um serviço de GPU em nuvem. Aqui está uma pequena lista de opções que podem ser adequadas às suas necessidades:
Colab – Google Colaboratory, ou “Colab” para abreviar, é um produto do Google Research. O Colab permite que qualquer pessoa escreva e execute código Python arbitrário por meio do navegador, e é especialmente adequado para aprendizado de máquina. Especificamente, o Colab é um serviço de nuvem gratuito hospedado pelo Google que usa o Jupyter Notebook, ou seja, que não requer instalação para uso, ao mesmo tempo que fornece acesso a recursos de computação, incluindo GPUs.
Kaggle – Kaggle (propriedade do Google) fornece acesso gratuito às GPUs NVIDIA TESLA P100. Essas GPUs são úteis para treinar modelos de aprendizado profundo (deep learning), no entanto, não aceleram a maioria dos outros fluxos de trabalho, como bibliotecas Python, Pandas e Scikit-learn. Você pode usar um limite de cota por semana de GPU. A cota é restabelecida semanalmente e é de 30 horas ou às vezes mais, dependendo da demanda e dos recursos.
NVIDIA NGC – O catálogo NGC ™ é um hub para software otimizado por GPU para deep learning, machine learning e computação de alto desempenho que acelera a implantação para fluxos de trabalho de desenvolvimento para que cientistas, desenvolvedores e pesquisadores possam se concentrar na construção de soluções, coleta de insights e entrega de valor comercial.
Cloud GPUs no Google Cloud Platform – GPUs de alto desempenho no Google Cloud para aprendizado de máquina, computação científica e visualização 3D.
2. Visualização de dados criativa e storytelling de dados
A visualização de dados, juntamente com o storytelling de dados, continua sendo uma habilidade importante a ser cultivada por todos os cientistas de dados. Essa etapa integra o processo de ciência de dados e é uma habilidade que diferencia os cientistas de dados de seus colegas engenheiros de dados. Os cientistas de dados assumem a importante função de interagir com os responsáveis pelo projeto ao entregar os resultados de um trabalho de data science.
Além dos tradicionais relatórios e resultados numéricos, uma visualização de dados atraente e bem pensada é a melhor maneira de mostrar os resultados provenientes de um algoritmo de aprendizado de máquina. Além disso, é também um ingrediente básico do estágio final do storytelling de dados do projeto, onde o cientista de dados se esforça para chegar a uma descrição concisa e não técnica dos resultados, onde as principais descobertas são facilmente compreendidas.
Para quem sente dificuldade nesta parte, como no trabalho com elementos mais criativos e visuais, sempre procure por novas técnicas de visualização de dados usando pacotes R recém-descobertos e bibliotecas Python para tornar o resultado mais atraente.
3. Python
Para Gutierrez, é difícil ignorar o Python, pois a maioria dos bons artigos de blog e materiais de aprendizagem usam esta linguagem. Por exemplo, a maioria dos documentos de aprendizagem profunda que aparecem no arXiv referem-se a repositórios GitHub com código Python usando estruturas como Keras, TensorFlow e Pytorch, e quase tudo que acontece no Kaggle envolve Python.
Ainda de acordo com o autor, o R costumava ter a vantagem com os 16.891 pacotes disponíveis para complementar a linguagem base, mas o Python afirma ter uma ordem de magnitude maior do que essa. Um conhecimento robusto de Python é uma habilidade de ciência de dados importante para se aprender.
4. SQL
SQL é uma ótima linguagem de consulta de dados, mas não é uma linguagem de programação de propósito geral. É fundamental que todo cientista de dados seja proficiente em SQL. Muitas vezes, seus conjuntos de dados para um projeto de ciência de dados vêm diretamente de um banco de dados relacional corporativo. Portanto, o SQL é seu canal para adquirir dados. Além disso, você pode usar SQL diretamente em R e Python como uma ótima maneira de consultar dados em um quadro de dados.
5. GBM além de Deep Learning
A IA e o aprendizado profundo continuam no topo do “hype cycle” do setor, e certamente 2021 não será diferente. O aprendizado profundo é a ferramenta perfeita para muitos domínios de problemas, como classificação de imagens, veículos autônomos, PNL e muitos outros. Mas quando se trata de dados tabulares, ou seja, dados típicos de negócios, deep learning pode não ser a escolha ideal. Em vez disso, o GBM (Gradient Boosted Machines) é o algoritmo de aprendizado de máquina que geralmente atinge a melhor precisão em dados estruturados / tabulares, superando outros algoritmos, como as tão faladas redes neurais profundas (deep learning). Alguns dos principais GBMs incluem XGBoost, LightGBM, H2O e catboost.
6. Transformação de dados
Muitas vezes, é mencionado em voz baixa quando os cientistas de dados se encontram: o processo de data munging (também conhecido como data wrangling, transformação de dados) leva a maior parte do tempo e do orçamento de custos de um determinado projeto de ciência de dados.
Transformar dados não é o trabalho mais atraente, mas acertar pode significar sucesso ou fracasso com o aprendizado de máquina. Para uma tarefa tão importante, um cientista de dados deve certificar-se de agregar à sua caixa de ferramentas de ciência de dados código que atenda a muitas necessidades comuns. Se você usa R, isso significa usar dplyr e, se você usa Python, então Pandas é sua ferramenta de escolha.
7. Matemática e estatística
Manter um conhecimento sólido dos fundamentos dos algoritmos de aprendizado de máquina requer uma base em matemática e estatística. Essas áreas são normalmente deixadas por último no esforço de aprendizado de muitos cientistas de dados, isso porque matemática / estatística podem não estar em sua lista pessoal de atualização. Mas um entendimento elementar dos fundamentos matemáticos do aprendizado de máquina é imprescindível para evitar apenas adivinhar os valores dos hiperparâmetros ao ajustar algoritmos.
As seguintes áreas da matemática são importantes: cálculo diferencial, equações diferenciais parciais, cálculo integral (curvas AUC-ROC), álgebra linear, estatística e teoria da probabilidade. Todas essas áreas são importantes para entender como funcionam os algoritmos de aprendizado de máquina.
Um objetivo de todos os cientistas de dados é ser capaz de consumir “a bíblia do aprendizado de máquina”, “Elements of Statistical Learning”, de Hastie, Tibshirani e Friedman. Esse é um daqueles livros que você nunca termina de ler.
Para atualizar sua matemática, verifique o conteúdo do OpenCourseWare do professor Gilbert Strang do MIT.
8. Realização de experimentos com os dados
Busque novos conjuntos de dados e experimente, experimente e experimente! Os cientistas de dados nunca conseguem praticar o suficiente trabalhando com fontes de dados desconhecidas. Felizmente, o mundo está cheio de dados. É apenas uma questão de combinar suas paixões (ambientais, econômicas, esportivas, estatísticas de crime, o que for) com os dados disponíveis para que você possa realizar as etapas do “processo de ciência de dados” para aprimorar suas habilidades. A experiência que você ganha com seus próprios experimentos com dados o ajudará profissionalmente no futuro.
9. Conhecimento especializado
Um consultor independente de ciência de dados pode trabalhar em todos os tipos de projetos interessantes em um amplo espectro de domínios de problemas: manufatura, sem fins lucrativos, educação, esportes, moda, imóveis, para apenas mencionar alguns.
Então, quando se tem um novo cliente de um novo setor, é fundamental aumentar rapidamente seu conhecimento na área desde o início. Falar com pessoas da organização do cliente que são especialistas no assunto, analisar as fontes de dados disponíveis, ler tudo que possa encontrar sobre o assunto, incluindo white papers, postagens em blogs, periódicos, livros, artigos de pesquisa; tudo isso em uma tentativa de começar a todo vapor.
10. Aprendizado de máquina ético
O professor Gutierrez apresenta aos seus alunos uma lista de casos em que cientistas de dados foram solicitados a usar suas habilidades para fins nefastos.
“Falo a eles sobre os cientistas de dados que desenvolvem tecnologia para criar imagens e vídeos ‘deep fake’ indetectáveis. Conto a eles a vez em que testemunhei um gerente de ciência de dados de uma grande empresa pública de jogos que disse a uma multidão em um encontro que ele e sua equipe trabalharam com psicólogos para descobrir maneiras de viciar crianças em seus jogos. E eu falo sobre Rebekah Jones, a cientista de dados do estado da Flórida que se recusou a adulterar os dados do COVID-19 para fazer a situação da saúde pública do estado parecer melhor.”
Se você deseja se tornar um profissional de ciência de dados ético, pense no futuro. Saiba desde já que em sua carreira, provavelmente, surgirão situações nas quais você precisará se posicionar contra o uso de suas habilidades para prejudicar outras pessoas. Olhando para 2021, o clima político pode estar propício para tais dilemas.
Atualmente, grandes organizações estão investindo em análise preditiva e testando opções que sejam capazes de gerar eficiência de negócios e novas maneiras de lidar com seu público.
Partindo da ideia de que os dados são a nova riqueza mundial, saber refiná-los e transformá-los em informação será a chave para alavancar seu potencial.
Se você quer entender o que Machine Learning faz, o melhor é aprender na prática através de uma série de projetos já disponíveis. Veja aqui, 9 projetos de ML que o Insight selecionou no Kaggle para você aprender e se inspirar.
Diariamente, pessoas no mundo todo compram e vendem imóveis. Mas como saber qual o melhor preço para esta categoria de produto? Como saber se o valor oferecido é justo? Neste projeto, é proposto um modelo de Machine Learning para prever o preço de uma casa baseado em dados como tamanho, ano de construção, entre outros. Durante o desenvolvimento e avaliação desse modelo, você verá o código usado para cada etapa seguido de sua saída. Este estudo utilizou a linguagem de programação Python.
O reconhecimento de gênero permite a uma empresa fazer sugestões de produtos ou serviços de maneira mais personalizada aos seus usuários. Neste projeto o banco de dados foi criado para identificar uma voz como masculina ou feminina, com base nas propriedades acústicas da voz e da fala.
O conjunto de dados consiste em 3.168 amostras de voz gravadas, coletadas de homens e mulheres. As amostras de voz são pré-processadas por análise acústica em R usando os pacotes seewave e tuneR, com uma faixa de frequência analisada de 0hz-280hz (faixa vocal humana).
Com o crescimento da internet, o meio digital incentivou diversas práticas ruins como o email spam. Aparentemente, ele é uma parte inseparável da experiência na web, algo que aceitamos como normal, mas que é preciso combater e para isso surgiu a detecção de emails spam.
Neste projeto você irá encontrar um arquivo CSV contendo informações relacionadas de 5172 arquivos de email escolhidos aleatoriamente e seus respectivos rótulos para classificação de spam ou não spam. As informações sobre todos os 5172 emails estão armazenadas em um dataframe compacto, em vez de arquivos de texto separados.
Neste projeto de análise de dados do aplicativo Uber, o conjunto de dados são de viagens de passageiros que partem de um ponto A para um ponto B. O valor da viagem é calculado no momento da solicitação de forma automática pelo aplicativo, considerando distância, tempo estimado de viagem e disponibilidade atual do carro.
Terminada a viagem, é cobrado no cartão de crédito do passageiro e transferido uma porcentagem desse valor para a conta do motorista. Finalmente, antes de iniciar uma corrida, a viagem pode ser cancelada pelo motorista ou pelo passageiro.
A análise descritiva dos dados irá responder perguntas relacionadas a quantidade de passageiros e motoristas, quanto será o custo de uma viagem, quem são os melhores passageiros e os piores motoristas, entre outros questionamentos.
Em contrapartida ao surgimento do e-commerce e a facilidade de meios de pagamento e transações bancárias totalmente online, houve um aumento significativo nas fraudes com cartão de crédito. As operadoras de cartão passaram a dar mais importância a sistemas que possam detectar transações fraudulentas, para preservar seus clientes.
Este projeto contém transações realizadas com cartões de crédito em setembro de 2013 por portadores de cartões europeus, com intuito de analisar as transações fraudulentas.
Os sistemas de recomendação fazem com que o processo de recomendação natural do ser humano ganhe uma maior versatilidade, de modo que venha a atender digitalmente as demandas e necessidades das pessoas que procuram por algo.
O projeto analisa dados de filmes e sistemas de recomendação. Nele você verá algumas implementações de algoritmos de recomendação (baseado em conteúdo, popularidade e filtragem colaborativa) e também a construção de um conjunto desses modelos para chegar ao sistema de recomendação final.
A análise de sentimentos é uma mineração contextual de um texto que identifica e extrai informações subjetivas no material de origem. Ela ajuda as empresas a entenderem o sentimento social de sua marca, produto ou serviço.
Segundo os criadores deste conjunto de dados, sua abordagem foi única porque os dados de treinamento foram criados automaticamente, ao invés de anotações humanos. Nesta abordagem, foi presumido que qualquer tuíte com emotions positivos, era positivo, e tuítes com emotions negativos, foram negativos.
Em um processo de extração de informações dos dados, existe a técnica de Mineração de Dados, que visa explorar grandes quantidades de dados com o intuito de encontrar padrões relevantes e consistentes no relacionamento entre os atributos (basicamente, colunas de tabelas) dessas bases de dados. Uma das primeiras técnicas desenvolvidas nesse sentido foi o KDD (Knowledge Discovery in Database), desenvolvido durante o final da década de 1980. A extração de conhecimento a partir de uma base de dados é dividida em: coleta de dados, tratamento dos dados e resultado final (transformação dos dados em informações e posteriormente em conhecimento).
Neste projeto, pode-se entender as fases do KDD (Knowledge Discovery in Database) para uma base de dados na qual existe uma série de atributos de análise de imagens de células na região do câncer feitos com ultrassonografia para prever se um câncer de mama é benigno ou maligno.
Após a extração dos dados da plataforma Kaggle, foi realizado um pré-processamento para garantir que os dados lidos e interpretados sejam relevantes para o processo de extração de conhecimento.
Em seguida, foi implementada a transformação dos dados, através do algoritmo KNN (K-Nearest Neighbors). Por fim, foram feitas as previsões a partir de novos dados, isto é, após o aprendizado realizado pelo algoritmo KNN sobre a base de dados, novas entradas de dados buscaram classificar se uma nova entrada de fotos de células seria um câncer benigno ou maligno, baseado no aprendizado anterior.
Este projeto é para todos os aspirantes a cientistas de dados aprenderem e revisarem seus conhecimentos através de uma análise estatística detalhada do conjunto de dados do Titanic com a implementação do modelo ML.
Os objetivos principais deste trabalho são:
fazer uma análise estatística de como alguns grupos de pessoas sobreviveram mais do que outros;
fazer uma análise exploratória de dados (EDA) do titanic com visualizações e contação de histórias;
prever com o uso de ML as chances de sobrevivência dos passageiros.
Se você gosta de trabalhar com dados financeiros, este projeto pode ser interessante para você. O objetivo deste projeto é prever os preços futuros das ações aprendendo com o desempenho de uma empresa.
Neste projeto serão explorados dados do mercado de ações, em particular ações de tecnologia. Ele apresenta como usar o Pandas para obter informações sobre ações, visualizar seus diferentes aspectos e, por fim, algumas maneiras de analisar o risco de uma ação com base em seu histórico de desempenho anterior. Além disso tudo, será abordado a previsão dos preços futuros de ações por meio do método Long Short Term Memory (LSTM).
No kaggle, você também encontra outros excelentes projetos como estes, disponíveis para aprendizagem e competições com outros cientistas de dados, engenheiros de Machine Learning e curiosos da área. Aprender com profissionais e ter acesso à base de dados para treinar suas habilidades, além de participar de competições, trará a você cada vez mais segurança em sua formação.
Gostou da nossa seleção? Se você tem o seu próprio projeto ou quer indicar outro, compartilha aqui conosco!
O livro Mathematics for Machine Learning é a dica certa para você que precisa de um apoio nos seus estudos. Escrito para motivar as pessoas a aprenderem conceitos matemáticos a obra não se destina a cobrir técnicas avançadas sobre o assunto, mas pretende fornecer as habilidades matemáticas necessárias para isso.
Conteúdo
Este exemplar pretende simplificar o conhecimento sobre matemática para Machine Learning, introduzindo os conceitos matemáticos com um mínimo de pré-requisitos. As ferramentas matemáticas fundamentais necessárias para entender ML que são apresentadas na primeira parte do livro incluem:
Álgebra linear;
Geometria Analítica;
Decomposição de Matriz;
Cálculo Vetorial;
Otimização;
Probabilidade e estatística.
Esses tópicos são tradicionalmente ensinados em cursos distintos, tornando difícil para os alunos de ciência de dados ou profissionais da área, aprenderem matemática com eficiência. Na segunda parte do livro serão apresentados os seguintes problemas de aprendizado de máquina central:
Quando os modelos encontram os dados;
Regressão linear;
Redução de dimensionalidade com análise de componente principal;
Estimativa de densidade com modelos de mistura gaussiana;
Classificação com máquinas de vetores de suporte.
Público direcionado
Para alunos e outras pessoas com formação matemática, o livro irá oferecer um ponto de partida para a matemática para Machine Learning. Para aqueles que estão aprendendo matemática pela primeira vez, os métodos contidos no livro ajudam a construir intuição e experiência prática com a aplicação de conceitos matemáticos. Cada capítulo inclui exemplos trabalhados e exercícios para testar a compreensão, além de tutoriais de programação oferecidos no site do livro.
Avaliação
De acordo com a opinião dos leitores, Mathematics for Machine Learning é um livro com explicações claras e objetivas sobre matemática aplicada ao aprendizado de Máquina.O livro é muito bem avaliado por seus leitores na Amazon, recebendo uma nota 4.6 de 5 com mais de 100 opiniões.
Autores
Marc Peter Deisenroth é Diretor da DeepMind em Inteligência Artificial no Departamento de Ciência da Computação da University College London. Suas áreas de pesquisa incluem aprendizagem eficiente em dados, modelagem probabilística e tomada de decisão autônoma. Em 2018, ele foi agraciado com o Prêmio do Presidente de Pesquisador de Excelência em Início de Carreira no Imperial College London.
Aldo Faisal lidera o Brain and Behavior Lab do Imperial College London, onde é professor dos Departamentos de Bioengenharia e Computação e membro do Data Science Institute. Faisal estudou Ciência da Computação e Física na Universität Bielefeld (Alemanha). Obteve Ph.D. em Neurociência Computacional na Universidade de Cambridge e tornou-se Pesquisador Júnior no Laboratório de Aprendizagem Computacional e Biológica.
Cheng Soon Ong é Cientista de Pesquisa Principal do Grupo de Pesquisa de Aprendizado de Máquina, Data61 e professor da Australian National University. Sua pesquisa se concentra em permitir a descoberta científica, estendendo os métodos estatísticos de Aprendizado de Máquina. Possui Ph.D. em Ciência da Computação na Australian National University e pós-doctor no Instituto Max Planck de Cibernética Biológica e no Laboratório Friedrich Miescher.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade