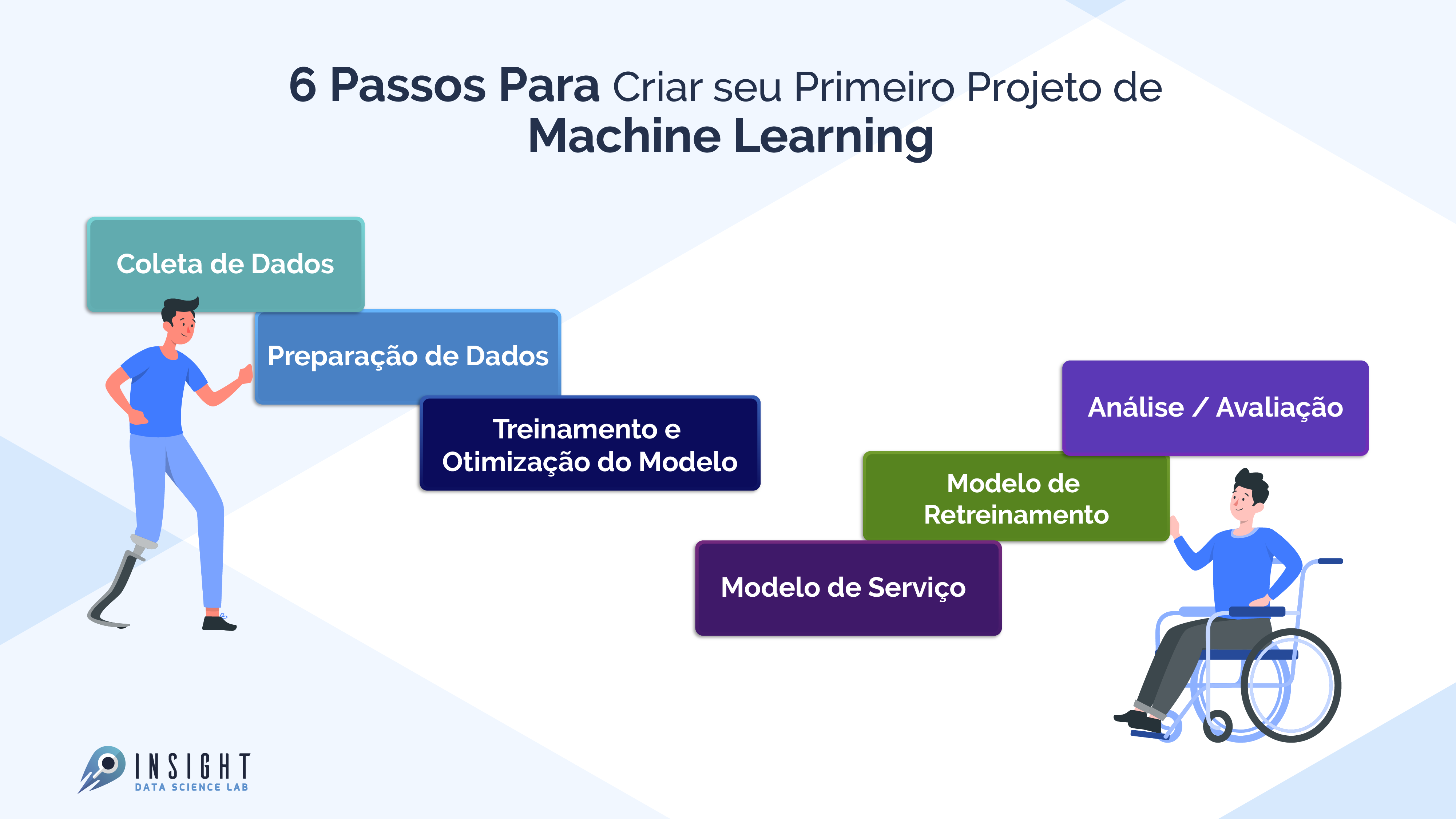
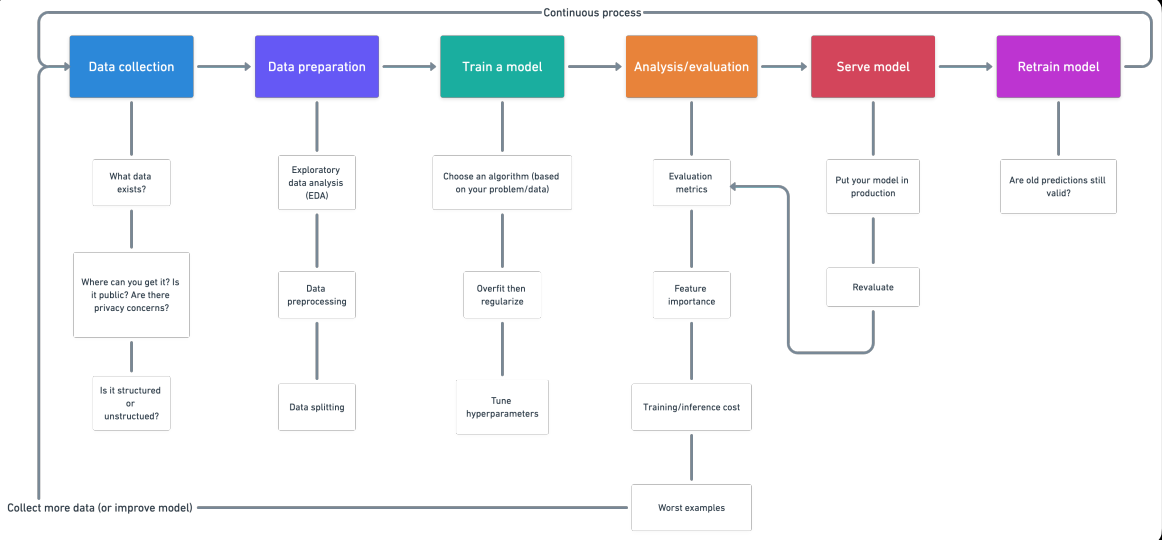
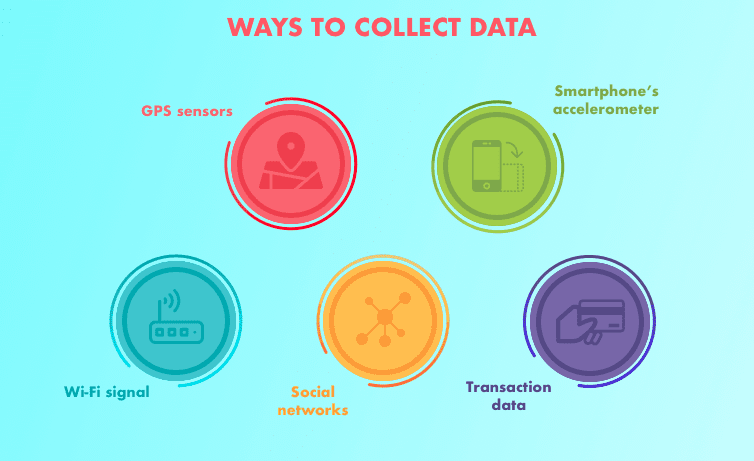
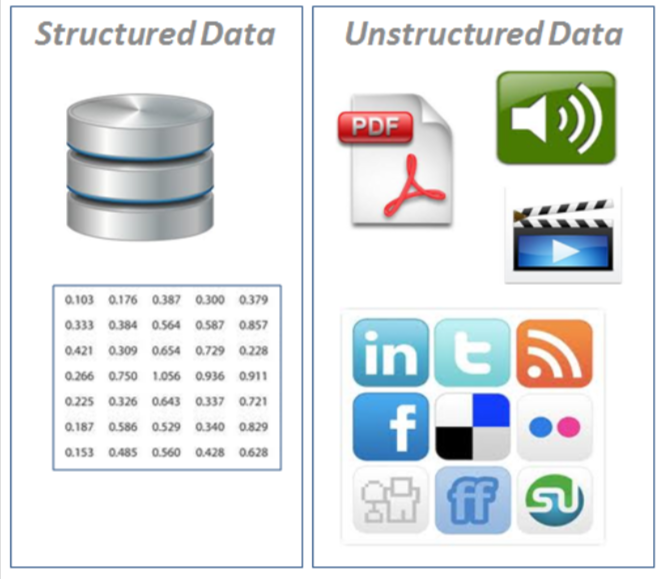
Algoritmos de aprendizado de máquina utilizam parâmetros baseados em dados de treinamento – um subconjunto de dados que representa o conjunto maior. À medida que os dados de treinamento se expandem para representar o mundo de modo mais realista, o algoritmo calcula resultados mais precisos.
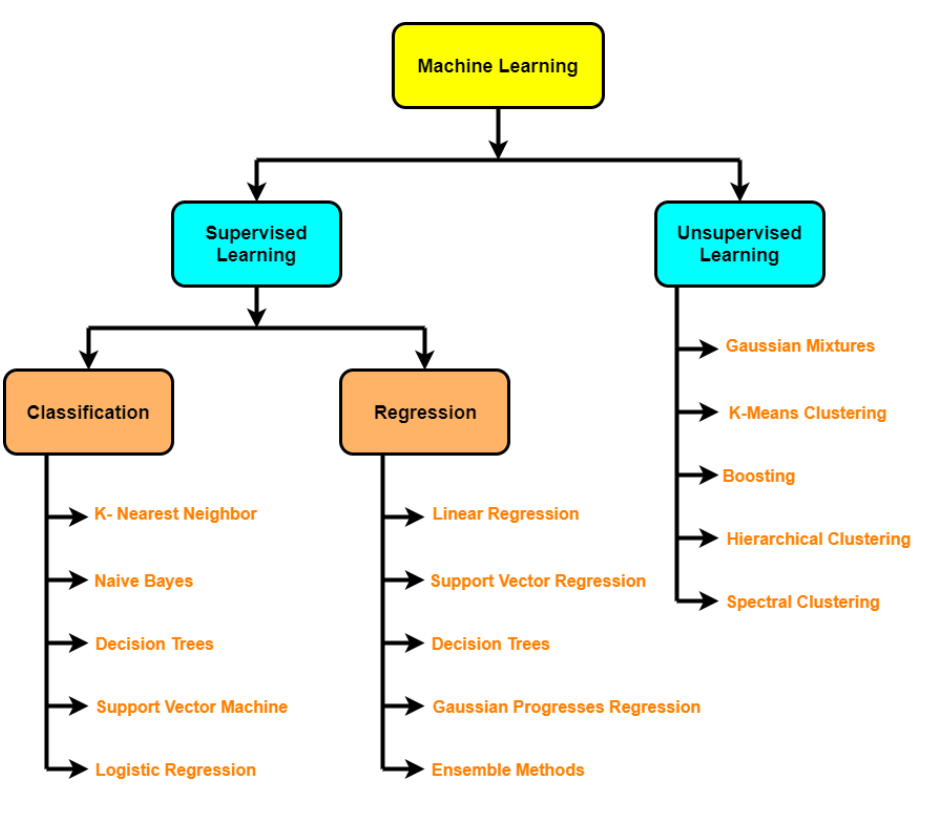
Diferentes algoritmos analisam dados de maneiras diferentes. Geralmente, eles são agrupados pelas técnicas de aprendizado de máquina para as quais são usados: aprendizado supervisionado, aprendizado não supervisionado e aprendizado de reforço. Os algoritmos usados com mais frequência usam a regressão e a classificação para prever categorias de destino, encontrar pontos de dados incomuns, prever valores e descobrir semelhanças.
Tendo isso em mente, vamos conhecer os 5 algoritmos de aprendizado de máquina mais importantes:
- Algoritmos de Ensemble Learning;
- Algoritmos explicativos;
- Algoritmos de agrupamento;
- Algoritmos de Redução de Dimensionalidade;
- Algoritmos de semelhança.
1. Algoritmos de Ensemble Learning (Random Forests, XGBoost, LightGBM, CatBoost)
O que são algoritmos de Ensemble Learning?
Para entender o que eles são, primeiro você precisa saber o que é o Método Ensemble. Esse método consiste no uso simultâneo de vários modelos para obter melhor desempenho do que um único modelo em si.
Conceitualmente, considere a seguinte analogia:

Imagem Terence Shin
Imagine a seguinte situação: em uma sala de aula é dado o mesmo problema de matemática para um único aluno e para um grupo de alunos. Nessa situação, o grupo de alunos pode resolver o problema de forma colaborativa, verificando as respostas uns dos outros e decidindo por unanimidade sobre uma única resposta. Por outro lado, um aluno, sozinho, não tem esse privilégio – ninguém mais está lá para colaborar ou questionar sua resposta.
E assim, a sala de aula com vários alunos é semelhante a um algoritmo de Ensemble com vários algoritmos menores trabalhando juntos para formular uma resposta final.
Saiba mais sobre o Ensemble Learning neste artigo.
Quando são úteis?
Os algoritmos de Ensemble Learning são mais úteis para problemas de regressão e classificação ou problemas de aprendizado supervisionado. Devido à sua natureza inerente, eles superam todos os algoritmos tradicionais de Machine Learning, como Naïve Bayes, máquinas vetoriais de suporte e árvores de decisão.
Algoritmos
2. Algoritmos Explicativos (Regressão Linear, Regressão Logística, SHAP, LIME)
O que são algoritmos explicativos?
Algoritmos explicativos permitem identificar e compreender variáveis que possuem relação estatisticamente significativa com o resultado. Portanto, em vez de criar um modelo para prever valores da variável de resposta, podemos criar modelos explicativos para entender as relações entre as variáveis no modelo.
Do ponto de vista da regressão, há muita ênfase nas variáveis estatisticamente significativas. Por quê? Quase sempre, você estará trabalhando com uma amostra de dados, que é um subconjunto de toda a população. Para tirar conclusões sobre uma população, dada uma amostra, é importante garantir que haja significância suficiente para fazer uma suposição confiável.
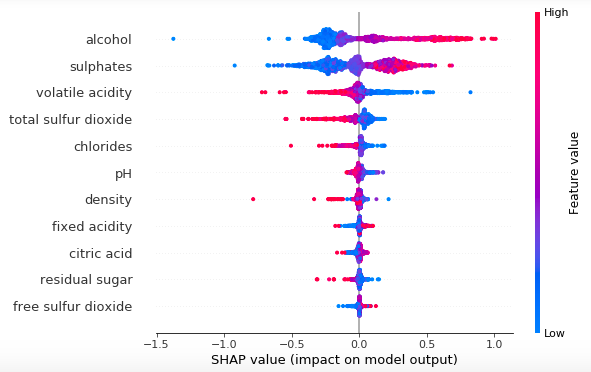

Imagem Terence Shin
Recentemente, também houve o surgimento de duas técnicas populares, SHAP e LIME, que são usadas para interpretar modelos de Machine Learning.
Quando são úteis?
Modelos explicativos são úteis quando você quer entender “por que” uma decisão foi tomada ou quando você quer entender “como” duas ou mais variáveis estão relacionadas entre si.
Na prática, a capacidade de explicar o que seu modelo de Machine Learning faz é tão importante quanto o desempenho do próprio modelo. Se você não puder explicar como um modelo funciona, ninguém confiará nele e ninguém o usará.
Tipos de Algoritmos
Modelos explicativos tradicionais baseados em testes de hipóteses:
- Regressão linear
- Regressão Logística
Algoritmos para explicar modelos de Machine Learning:
3. Algoritmos de Agrupamento (k-Means, Agrupamento Hierárquico)
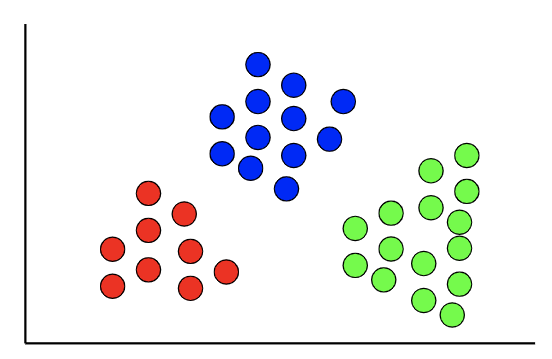

Imagem Terence Shin
O que são algoritmos de agrupamento?
Esses algoritmos são usados para realizar análises de agrupamento, que é uma tarefa de aprendizado não supervisionada que envolve o agrupamento de dados. Ao contrário do aprendizado supervisionado, no qual a variável de destino é conhecida, não há variável de destino nas análises de agrupamento.
Quando são úteis?
O clustering é particularmente útil quando você deseja descobrir padrões e tendências naturais em seus dados. É muito comum que as análises de cluster sejam realizadas na fase de EDA, para descobrir mais informações sobre os dados.
Da mesma forma, o agrupamento permite identificar diferentes segmentos dentro de um dataset com base em diferentes variáveis. Um dos tipos mais comuns de segmentação por cluster é a segmentação de usuários/clientes.
Tipos de Algoritmos
Os dois algoritmos de agrupamento mais comuns são agrupamento k-means e agrupamento hierárquico, embora existam muitos mais:
4. Algoritmos de Redução de Dimensionalidade (PCA, LDA)
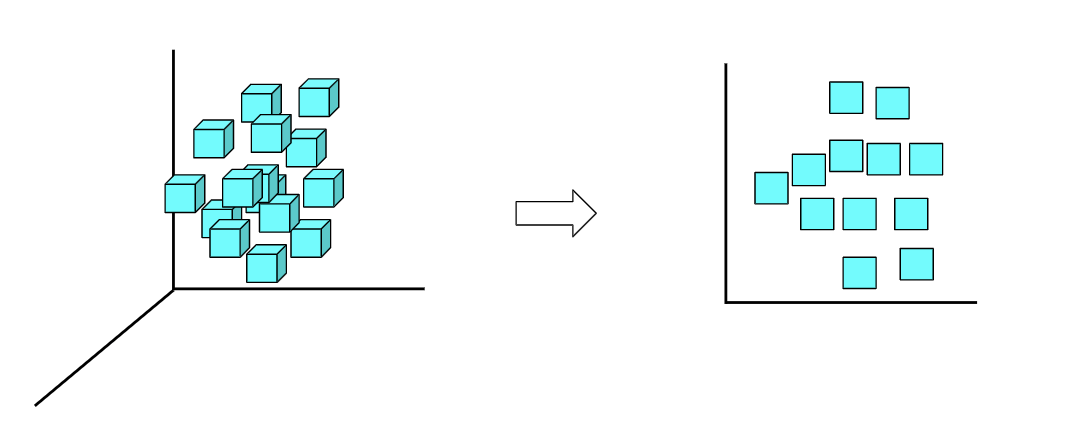

O que são algoritmos de redução de dimensionalidade?
Os algoritmos de redução de dimensionalidade referem-se a técnicas que reduzem o número de variáveis de entrada (ou variáveis de recursos) em um dataset. A redução de dimensionalidade é essencialmente usada para lidar com a maldição da dimensionalidade, um fenômeno que afirma, “à medida que a dimensionalidade (o número de variáveis de entrada) aumenta, o volume do espaço cresce exponencialmente resultando em dados esparsos.
Quando são úteis?
As técnicas de redução de dimensionalidade são úteis em muitos casos:
- Eles são extremamente úteis quando você tem centenas ou até milhares de recursos em um dataset e precisa selecionar alguns.
- Eles são úteis quando seus modelos de ML estão super ajustando os dados, o que implica que você precisa reduzir o número de recursos de entrada.
Tipos de Algoritmos
Abaixo estão os dois algoritmos de redução de dimensionalidade mais comuns:
5. Algoritmos de similaridade (KNN, Distância Euclidiana, Cosseno, Levenshtein, Jaro-Winkler, SVD, etc…)
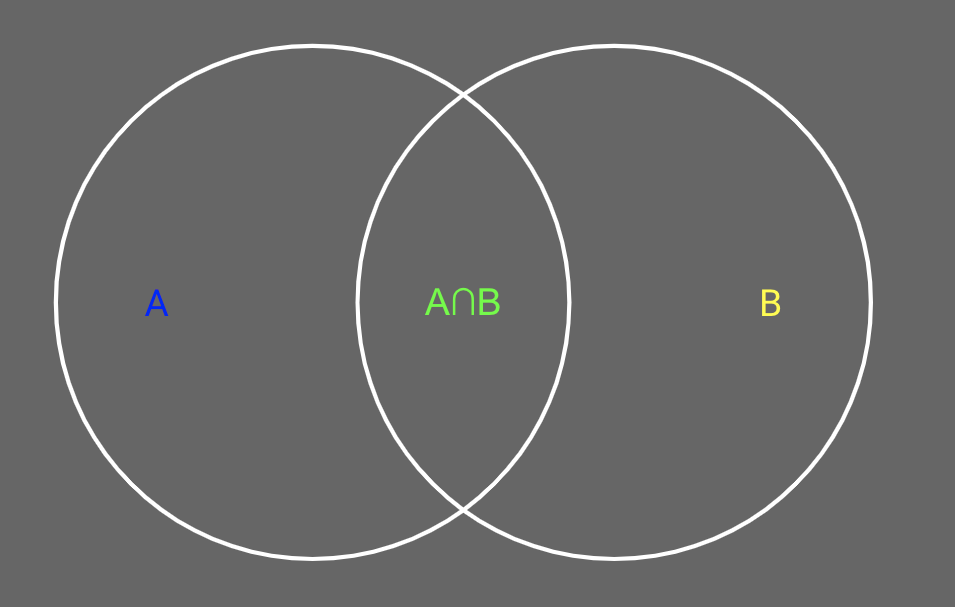

O que são algoritmos de similaridade?
Algoritmos de similaridade são aqueles que computam a similaridade de pares de registros/nós/pontos de dados/texto. Existem algoritmos de similaridade que comparam a distância entre dois pontos de dados, como a distância euclidiana, e também existem algoritmos de similaridade que calculam a similaridade de texto, como o Algoritmo Levenshtein.
Quando são úteis?
Esses algoritmos podem ser usados em uma variedade de aplicações, mas são particularmente úteis para recomendação.
- Quais artigos o Medium deve recomendar a você com base no que você leu anteriormente?
- Qual música o Spotify deve recomendar com base nas músicas que você já gostou?
- Quais produtos a Amazon deve recomendar com base no seu histórico de pedidos?
Estes são apenas alguns dos muitos exemplos em que algoritmos de similaridade e recomendação são usados em nossas vidas cotidianas.
Tipos de Algoritmos
Abaixo está uma lista não exaustiva de alguns algoritmos de similaridade. Se você quiser ler sobre mais algoritmos de distância, confira este artigo. E se você também se interessar por algoritmos de similaridade de strings, leia este artigo.
- K vizinhos mais próximos
- Distância euclidiana
- Semelhança de cosseno
- Algoritmo Levenshtein
- Algoritmo de Jaro-Winkler
- Singular Value Decomposition (SVD) (não é exatamente um algoritmo de similaridade, mas indiretamente se relaciona com similaridade).
Se você gostou desse conteúdo, acompanhe as próximas postagens do Insight Lab aqui e também nas redes sociais!
Fontes: Terence Shin e Azure.