O livro Mathematics for Machine Learning é a dica certa para você que precisa de um apoio nos seus estudos. Escrito para motivar as pessoas a aprenderem conceitos matemáticos a obra não se destina a cobrir técnicas avançadas sobre o assunto, mas pretende fornecer as habilidades matemáticas necessárias para isso.
Conteúdo
Este exemplar pretende simplificar o conhecimento sobre matemática para Machine Learning, introduzindo os conceitos matemáticos com um mínimo de pré-requisitos. As ferramentas matemáticas fundamentais necessárias para entender ML que são apresentadas na primeira parte do livro incluem:
Álgebra linear;
Geometria Analítica;
Decomposição de Matriz;
Cálculo Vetorial;
Otimização;
Probabilidade e estatística.
Esses tópicos são tradicionalmente ensinados em cursos distintos, tornando difícil para os alunos de ciência de dados ou profissionais da área, aprenderem matemática com eficiência. Na segunda parte do livro serão apresentados os seguintes problemas de aprendizado de máquina central:
Quando os modelos encontram os dados;
Regressão linear;
Redução de dimensionalidade com análise de componente principal;
Estimativa de densidade com modelos de mistura gaussiana;
Classificação com máquinas de vetores de suporte.
Público direcionado
Para alunos e outras pessoas com formação matemática, o livro irá oferecer um ponto de partida para a matemática para Machine Learning. Para aqueles que estão aprendendo matemática pela primeira vez, os métodos contidos no livro ajudam a construir intuição e experiência prática com a aplicação de conceitos matemáticos. Cada capítulo inclui exemplos trabalhados e exercícios para testar a compreensão, além de tutoriais de programação oferecidos no site do livro.
Avaliação
De acordo com a opinião dos leitores, Mathematics for Machine Learning é um livro com explicações claras e objetivas sobre matemática aplicada ao aprendizado de Máquina.O livro é muito bem avaliado por seus leitores na Amazon, recebendo uma nota 4.6 de 5 com mais de 100 opiniões.
Autores
Marc Peter Deisenroth é Diretor da DeepMind em Inteligência Artificial no Departamento de Ciência da Computação da University College London. Suas áreas de pesquisa incluem aprendizagem eficiente em dados, modelagem probabilística e tomada de decisão autônoma. Em 2018, ele foi agraciado com o Prêmio do Presidente de Pesquisador de Excelência em Início de Carreira no Imperial College London.
Aldo Faisal lidera o Brain and Behavior Lab do Imperial College London, onde é professor dos Departamentos de Bioengenharia e Computação e membro do Data Science Institute. Faisal estudou Ciência da Computação e Física na Universität Bielefeld (Alemanha). Obteve Ph.D. em Neurociência Computacional na Universidade de Cambridge e tornou-se Pesquisador Júnior no Laboratório de Aprendizagem Computacional e Biológica.
Cheng Soon Ong é Cientista de Pesquisa Principal do Grupo de Pesquisa de Aprendizado de Máquina, Data61 e professor da Australian National University. Sua pesquisa se concentra em permitir a descoberta científica, estendendo os métodos estatísticos de Aprendizado de Máquina. Possui Ph.D. em Ciência da Computação na Australian National University e pós-doctor no Instituto Max Planck de Cibernética Biológica e no Laboratório Friedrich Miescher.
Por tratar-se de uma nova ameaça, sabe-se muito pouco sobre o coronavírus (Sars-CoV-2). Esse fator dá grande abertura para disseminação de fake news (como ficou popularmente conhecido o compartilhamento de informações falsas), que podem ir desde supostos métodos de prevenção, tratamentos caseiros, cura do vírus e até mesmo tratamentos controversos recomendados por médicos, mesmo que não haja comprovação ou evidência científica para tais. Tudo isso pode dificultar o trabalho de órgãos de saúde, prejudicar a adoção de medidas de distanciamento social pela população e acarretar aumentos dos números de infectados e de morte pelo vírus.
Para diminuir os impactos dessa desinformação, diversos sites de checagem de fatos têm ferramentas que identificam e classificam (manualmente) tais notícias. Em geral, essas ferramentas poderiam fazer uso de algoritmos de aprendizagem de máquina para classificação de notícias. Diante dessa problemática, é evidente a necessidade de elaborar mecanismos e ferramentas que possam combater eficientemente o caos das fakes news.
Por isso, durante as disciplinas de Aprendizagem de Máquina e Mineração de Dados (Programa de Pós-graduação em Ciência da Computação da Universidade Federal do Ceará (MDCC-UFC)), nós(Andreza Fernandes, Felipe Marcel, Flávio Carneiro e Marianna Ferreira) propusemos um detector de fake news para analisar notícias sobre o COVID-19 divulgadas em redes sociais. Nosso objetivo é ajudar a população quanto ao esclarecimento da veracidade dessas informações.
Agora, detalharemos o processo de desenvolvimento desse detector de fake news.
Objetivos do projeto
Formar uma base dados de textos com notícias falsas e verdadeiras acerca do COVID-19;
Diminuir enviesamento das notícias;
Experimentar diferentes representações textuais;
Experimentar diferentes abordagens clássicas de aprendizagem de máquina e deep learning;
Construir um BOT no Telegram que ajude na detecção de notícias falsas relacionadas ao COVID-19.
Entendendo as terminologias usadas
Para o entendimento dos experimentos realizadas, vamos conceituar alguns pontos chaves e técnicas de Processamento de Linguagem Natural.
Tokenização: Esse processo transforma todas as palavras de um texto, dado como entrada, em elementos (conhecidos como tokens) de um vetor.
Remoção de Stopwords: Consiste na remoção de palavras de parada, como “a”, “de”, “o”, “da”, “que”, “e”, “do”, dentre outras, pois na maioria das vezes não são informações relevantes para a construção do modelo.
Bag of words: É uma representação simplificada e esparsa dos dados textuais. Consiste em gerar uma bolsa de palavras do vocabulário existente no dado, que constituirá as features do dataset. Para cada sentença é assinalado um “1” nas colunas que apresentam as palavras que ocorrem na sentença e “0” nas demais.
Term Frequency – Inverse Document Frequency (TF-IDF): Indica a importância de uma palavra em um documento. Enquanto TF está relacionada à frequência do termo, IDF busca balancear a frequência de termos mais comuns/frequentes que outros.
Word embeddings: É uma forma utilizada para representar textos, onde palavras que possuem o mesmo sentido têm uma representação muito parecida. Essa técnica aprende automaticamente, a partir de um corpus de dados, a correlação entre as palavras e o contexto, possibilitando que palavras que frequentemente ocorrem em contextos similares possuam uma representação vetorial próxima. Essa representação possui a vantagem de ter um grande poder de generalização e apresentar baixo custo computacional, uma vez que utiliza representações densas e com poucas dimensões, em oposição a técnicas esparsas, como Bag of Words. Para gerar o mapeamento entre dados textuais e os vetores densos mencionados, existem diversos algoritmos disponíveis, como Word2Vec e FastText, os quais são utilizados neste trabalho.
Out-of-vocabulary (OOV): Consiste nas palavras presentes no dataset que não estão presentes no vocabulário da word embedding, logo, elas não possuem representação vetorial.
Edit Distance: Métrica que quantifica a diferença entre duas palavras, contando o número mínimo de operações necessárias para transformar uma palavra na outra.
Metodologia
Agora iremos descrever os passos necessários para a obtenção dos resultados, geração dos modelos e escolha daquele com melhor performance para a efetivação do nosso objetivo.
Obtenção dos Dados
Os dados utilizados para a elaboração dos modelos foram adquiridos das notícias falsas brasileiras sobre o COVID-19, dispostos noChequeado, e de um web crawler dos links das notícias, utilizadas para comprovar que a notícia é falsa no Chequeado, para formar uma base de notícias verdadeiras. Além disso também foi realizado um web crawler para obtenção de notícias doFato Ou Fakedo G1.
Originalmente, os dados obtidos do Chequeado possuíam as classificações “Falso”, “Enganoso”, “Parcialmente falso”, “Dúbio”, “Distorcido”, “Exagerado” e “Verdadeiro mas”, que foram mapeadas todas para “Falso”. Com isso, transformamos nosso problema em classificação binária.
No final, obtivemos um dataset com 1.753 notícias, sendo 808 fakes, simbolizada como classe 0, e 945 verdadeiras, classe 1, com um vocabulário de tamanho 3.698. Com isso, dividimos o nosso dado em conjunto de treino e teste, com tamanhos de 80% e 20%, respectivamente.
Pré-processamento
Diminuição do viés. Ao trabalhar e visualizar os dados, notamos que algumas notícias verdadeiras vinham com palavras e sentenças que enviesavam e deixavam bastante claro para os algoritmos o que é fake e o que é verdadeiro, como: “É falso que”, “#Checamos”, “Verificamos que” e etc. Com isso, removemos essas sentenças e palavras, a fim de diminuir o enviesamento das notícias.
Limpeza textual. Após a etapa anterior, realizamos a limpeza do texto, consistindo em remoção de caracteres estranhos e sinais de pontuação e uso do texto em caixa baixa.
Tokenização. A partir do texto limpo, inicializamos o processo de tokenização das sentenças.
Remoção das Stopwords. A partir das sentenças tokenizadas, removemos as stopwords.
Representação textual
Análise exploratória
A partir do pré-processamento dos dados brutos, inicializamos o processo de análise exploratória dos dados. Verificamos o tamanho do vocabulário do nosso dataset, que totaliza 3.698 palavras.
Análise do Out-of-vocabulary. Com isso, verificamos o tamanho do nosso out-of-vocabulary em relação às word embeddings pré-treinadas utilizadas, totalizando 32 palavras. Um fato curioso é que palavras chaves do nosso contexto encontram-se no out-of-vocabulary e acabam sendo mapeadas para palavras que não tem muita conexão com o seu significado. Abaixo é possível ver algumas dessas palavras mais à esquerda, e a palavra a qual foram mapeadas mais à direita.
Mapeamento de palavras
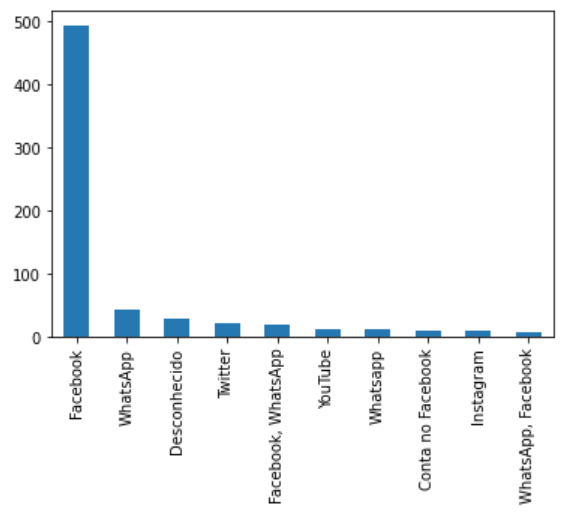
Análise da frequência das fake news por rede social. O dado bruto original advindo do Chequeado possui uma coluna que diz sobre a mídia social em que a fake news foi divulgada. Após uma análise visual superficial, apenas plotando a contagem dos valores dessa coluna (que acarreta até na repetição de redes sociais), notamos que os maiores veículos de propagação de fake news são o Facebook e Whatsapp.
Frequência de fake news por rede social
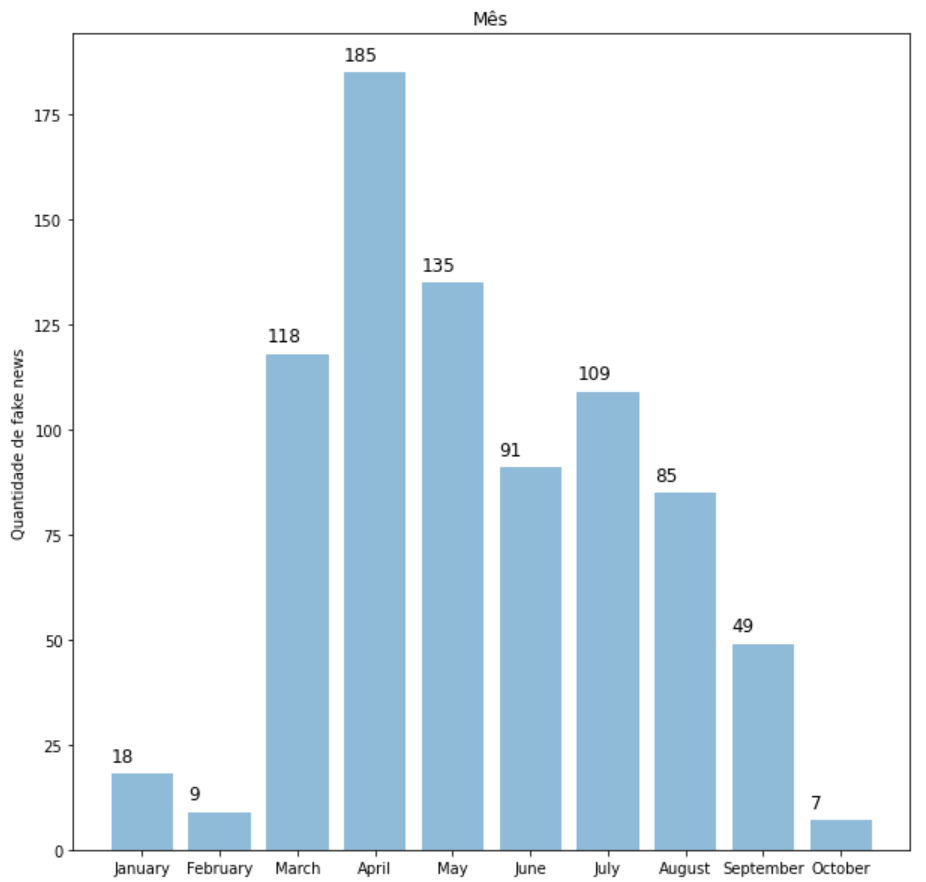
Análise da quantidade de fake news ao longo dos meses. O dado bruto original advindo do Chequeado também possui uma coluna que informava a data de publicação da fake news. Após realizar uma análise visual da distribuição da quantidade de fake news ao longo dos meses, notamos que o maior número de fake news ocorreu em abril, mês em que a doença começou a se espalhar com maior velocidade no território brasileiro. De acordo com o G1, em 28 de abril, o Brasil possuía 73.235 casos do novo coronavírus (Sars-CoV-2), com 5.083 mortes. Além disso, foi nesse mês que começaram a surgir os boatos de combate do Coronavírus via Cloroquina, além de remédios caseiros.
Volume de fake news relacionadas ao COVID-19 ao longo dos meses
Análise da Word Cloud. Com as sentenças tokenizadas, também realizamos uma visualização usando a técnica de Word Cloud, que apresenta as palavras do vocabulário em um tamanho proporcional ao seu número de ocorrência no todo. Com essa técnica, realizamos duas visualizações, uma para as notícias verdadeiras e outra para as fake news.
Nuvem de palavras nas notícias falsas
Nuvem de palavras nas notícias verdadeiras
Divisão treino e teste
A divisão dos conjuntos de dados entre treino e teste foi feita com uma distribuição de 80% e 20% dos dados, respectivamente.Os dados de treino foram ainda divididos em um novo conjunto de treino e um de validação, com uma distribuição de 80% e 20% respectivamente.
Aplicação dos modelos
Para gerar os modelos, escolhemos algoritmos e técnicas clássicas de aprendizagem de máquina, tais como técnicas atuais e bastante utilizadas em competições, sendo eles:
Regressão Logística (*): exemplo de classificador linear;
K-NN (*): exemplo de modelo não-paramétrico;
Análise Discriminante Gaussiano (*): exemplo de modelo que não possui hiperparâmetros;
Árvore de Decisão: exemplo de modelo que utiliza abordagem da heurística gulosa;
Random Forest: exemplo de ensemble de bagging de Árvores de Decisão;
SVM: exemplo de modelo que encontra um ótimo global;
XGBoost: também um ensemble amplamente utilizado em competições do Kaggle;
LSTM-Dense: exemplo de arquitetura que utiliza deep learning.
Os algoritmos foram utilizados por meio de implementações próprias (aqueles demarcados com *) e uso da biblioteca scikit-learn e keras. Para todos os algoritmos, com exceção daqueles que não possuem hiperparâmetros e LSTM-Dense, realizamos Grid Search em busca dos melhores hiperparâmetros e realizamos técnicas de Cross Validation para aqueles utilizados por meio do Scikit-Learn, com k fold igual a 5.
Obtenção das métricas
As métricas utilizadas para medir a performance dos modelos foram acurácia, Precision, Recall, F1-score e ROC.
Tabela 1. Resultados das melhores representações por algoritmo
MODELOS
PRECISION
RECALL
F1-SCORE
ACCURACY
ROC
XGBoost BOW e TF-IDF*
1
1
1
1
1
SVM BOW E TF-IDF*
1
1
1
1
1
Regressão Logística BOW
0.7560
0.7549
0.7539
0.7549
0.7521
LSTM FASTTEXT
0.7496
0.7492
0.7493
0.7492
0.7492
Random Forest TF-IDF
0.7407
0.7407
0.7402
0.7407
0.7388
Árvore de Decisão TF-IDF
0.7120
0.7122
0.7121
0.7122
0.7111
Análise Discriminante Gaussiano Word2Vec
0.7132
0.7122
0.7106
0.7122
0.7089
k-NN FastText
0.6831
0.6809
0.6775
0.6638
0.6550
Tabela 2. Resultados das piores representações por algoritmo
MODELOS
PRECISION
RECALL
F1-SCORE
ACCURACY
ROC
XGBoost Word2Vec
0.7238
0.7236
0.7227
0.7236
0.7211
SVM Word2Vec
0.7211
0.7179
0.7151
0.7179
0.7135
Árvore de Decisão Word2Vec
0.6391
0.6353
0.6351
0.6353
0.6372
Random Forest Word2Vec
0.6231
0.6210
0.6212
0.6210
0.62198
Regressão Logística FastText
0.6158
0.5982
0.5688
0.59829
0.5858
Análise Discriminante Gaussiano TF-IDF
0.5802
0.5811
0.5801
0.5811
0.5786
k-NN BOW
0.5140
0.5099
0.5087
0.5042
0.5127
LSTM WORD2VEC (*)
0.4660
0.4615
0.4367
0.4615
0.4717
Resultados
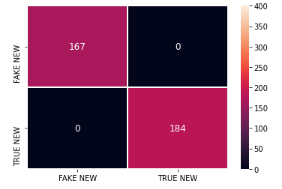
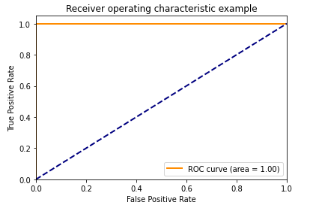
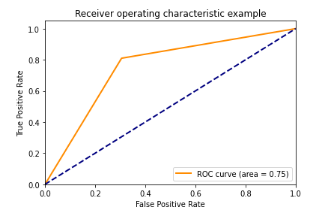
Com os resultados apresentados percebemos que os modelos SVM e XGBoost com as representações TF-IDF e BOW atingiram as métricas igual a 100%. Isso pode ser um grande indicativo de sobreajuste do modelo aos dados. Abaixo podemos visualizar a matriz de confusão e a curva ROC dos mesmos.
Matriz de confusão
Curva ROC
Logo após vem a Regressão Logística com métricas em torno de ~75.49%! Abaixo podemos visualizar sua matriz de confusão e a curva ROC.
Matriz de confusão
Curva ROC
Exemplos de classificações da Regressão Logística
True Positive (corretamente classificada)
Texto que diz que vitamina C e limão combatem o coronavírus
True Negative (corretamente classificada)
Notícia divulgada em 2015 pela TV italiana RAI comprova que o novo coronavírus foi criado em laboratório pelo governo chinês.
False Positive (erroneamente classificada)
Vitamina C com zinco previne e trata a infecção por coronavírus
False Negative (erroneamente classificada)
Que neurocientista britânico publicou estudo mostrando que 80% da população é imune ao novo coronavírus
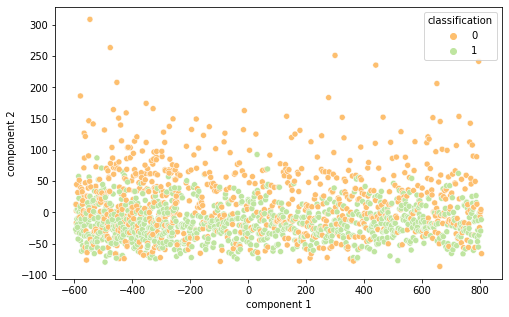
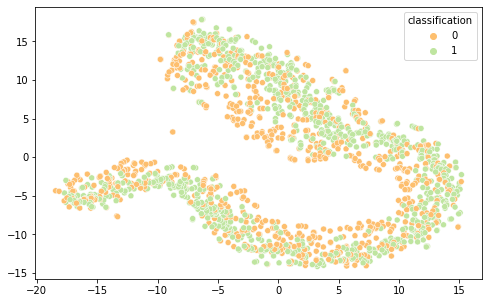
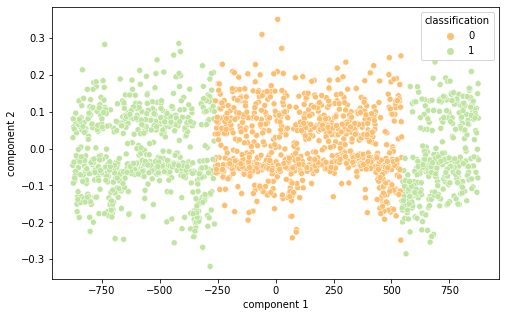
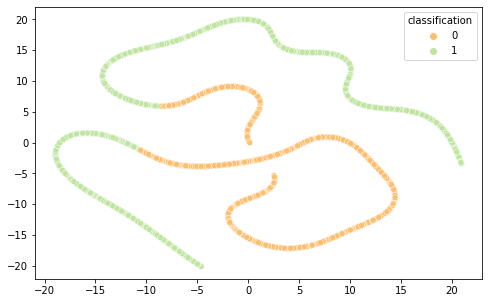
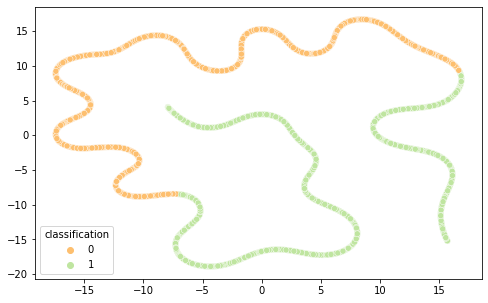
Intrigados com os resultados, resolvemos visualizar as diferentes representações de dados em 2 componentes principais (visto a alta dimensionalidade do dado, o que prejudica a análise do que está acontecendo de fato) por meio das técnicas de PCA e T-SNE, separando por cor de acordo com sua classificação.
É interessante notar que as representações de word embeddings utilizadas possui uma representação bastante confusa e misturada.Já as representações TF-IDF e Bag of Words são facilmente separáveis.
FastText PCA(Semelhante ao Word2Vec)
FastText T-SNE
Word2Vec T-SNE
BOW PCA (Semelhante ao TF-IDF)
BOW T-SNE
TF-IDF T-SNE
Conclusão
A base de dados utilizada para obtenção dos modelos foi obtida por meio do site Chequeado, e, posteriormente, houve o enriquecimento dessa base por meio do web crawler, totalizando 1.383 registros, sendo 701 fake news e 682 notícias verdadeiras.
Para representação textual foram utilizadas as técnicas Bag of Words, TF-IDF e Word embeddings Word2Vec e FastText de 300 dimensões com pesos pré-treinados obtidas por meio da técnica CBOW com dimensões, disponibilizadas pelo Núcleo Interinstitucional de Linguística Computacional (NILC). Para gerar os modelos foram utilizados os algoritmos Regressão Logística, kNN, Análise Discriminante Gaussiano, Árvore de Decisão, Random Forest, Gradient Boosting, SVM e LSTM-Dense. Para avaliação dos modelos foi utilizado as métricas Acurácia, Precision, Recall, F1-score, AUC-ROC e matriz de confusão.
Considerando os experimentos e os resultados, conclui-se que o objetivo principal deste trabalho, gerar modelos capazes de classificar notícias extraídas de redes sociais relacionadas ao COVID-19 como falsas e verdadeiras, foi alcançado com êxito. Como resultados, vimos que os modelos SVM e XGBoost com TF-IDF e BOW atingiram 100% nas métricas, com grandes chances de terem se sobreajustado aos dados. Com isso, consideramos como melhor modelo a Regressão Logística com a representação BOW, atingindo as métricas com valores próximos a 75.49%.
O pior classificador foi o kNN com o BOW e LSTM-Dense com Word2Vec, porém é importante ressaltar que este último não contou com Grid Search e foi treinado com poucas épocas. No geral, as melhores representações foram a TF-IDF e BOW e a pior o Word2Vec.
Para este projeto houveram algumas dificuldades, sendo a principal delas a formação da base de dados, visto que o contexto pandêmico do COVID-19 é algo novo e devido à limitação da API do Twitter em relação ao tempo para extrair os tweets, que era originalmente a ideia da base de dados para esse projeto. Além disso, também houve a dificuldade de remoção do viés dos dados.
Como trabalhos futuros, visamos:
Ampliar a base de dados;
Investigar o que levou ao desempenho do SVM, XGBOOST com as representações TF-IDF e BOW.
Analisar performance dos modelos utilizando outras word embeddings pré-treinadas, como o BERT, Glove e Wang2vec.
Investigar o uso do modelo pré-treinado do BERT e com fine-tuned.
Aplicar PCA Probabilístico
Utilizar arquiteturas de deep learning mais difundidas na comunidade científica.
O Insight apresenta aqui o livro “Machine Learning: A Probabilistic Perspective”, uma obra bem avaliada pelos leitores escrita por Kevin Patrick Murphy. Com um conteúdo extenso, mais de mil páginas, é um livro de companhia para sua carreira profissional que teve sua primeira edição lançado em 2012 e já está na sua quarta versão.
A obraé escrita de maneira informal, acessível e completa com pseudo-código para os algoritmos mais importantes. Possui todos os seus tópicos ilustrados com imagens coloridas e exemplos extraídos de domínios de aplicação como biologia, processamento de texto, visão computacional e robótica. Diferente de um tutorial, ou um livro de receitas de diferentes métodos heurísticos, a obra enfatiza uma abordagem baseada em modelos de princípios, muitas vezes usando a linguagem de modelos gráficos para especificá-los de forma concisa e intuitiva. Quase todos os modelos descritos foram implementados em um pacote de software MATLAB – PMTK (kit de ferramentas de modelagem probabilística) – que está disponível gratuitamente online.
Conteúdo
Com a quantidade cada vez maior de dados em formato eletrônico, a necessidade de métodos automatizados para análise de dados continua a crescer. O objetivo do Machine Learning (ML) é desenvolver métodos que possam detectar automaticamente padrões nos dados e, em seguida, usar esses padrões descobertos para prever dados futuros ou outros resultados de interesse. Este livro está fortemente relacionado aos campos de estatística e dados, fornecendo uma introdução detalhada ao campo e incluindo exemplos.
Com uma introdução abrangente e independente ao campo do Machine Learning, este livro traz uma abordagem probabilística unificada. A obra combina amplitude e profundidade no tema, oferecendo material de base necessário em tópicos como probabilidade, otimização e álgebra linear, bem como discussão de desenvolvimentos recentes no campo, incluindo campos aleatórios condicionais, regularização L1 e Deep Learning.
Público-alvo
A leitura é indicada para estudantes de graduação de nível superior, de nível introdutório e estudantes iniciantes na pós-graduação em ciência da computação, estatística, engenharia elétrica, econométrica ou qualquer outro que tenha a formação matemática apropriada.
É importante que o leitor esteja familiarizado com cálculo multivariado básico, probabilidade, álgebra linear e programação de computador.
Sobre o autor
Kevin P. Murphy é um cientista pesquisador do Google. Anteriormente, ele foi Professor Associado de Ciência da Computação e Estatística na University of British Columbia.
Críticas sobre a obra
Kevin Murphy se destaca em desvendar as complexidades dos métodos de aprendizado de máquina enquanto motiva o leitor com uma série de exemplos ilustrados e estudos de caso do mundo real. O pacote de software que acompanha inclui o código-fonte para muitas das figuras, tornando mais fácil e tentador mergulhar e explorar esses métodos por si mesmo. Uma compra obrigatória para qualquer pessoa interessada em aprendizado de máquina ou curiosa sobre como extrair conhecimento útil de big data.
John Winn, Microsoft Research, Cambridge
Este livro será uma referência essencial para os praticantes do aprendizado de máquina moderno. Ele cobre os conceitos básicos necessários para entender o campo como um todo e os métodos modernos poderosos que se baseiam nesses conceitos. No aprendizado de máquina, a linguagem de probabilidade e estatística revela conexões importantes entre algoritmos e estratégias aparentemente díspares. Assim, seus leitores se articulam em uma visão holística do estado da arte e prontos para construir a próxima geração de algoritmos de Machine Learning.
David Blei, Universidade de Princeton
———— . . . ————
Empolgado para se tornar um profissional mais preparado? Conta aqui, que livro você gostaria que o Insight indicasse?
O livro Python Machine Learning, 3ª edição é um guia abrangente de Machine Learning e Deep Learning com Python. De forma didática, o livro ensina todos os passos necessários servindo como leitura de referência enquanto você cria seus sistemas. Contendo explicações claras e exemplos, o livro inclui todas as técnicas essenciais de Machine Learning (ML).
Neste livro os autores Sebastian Raschka e Vahid Mirjaliliensinam os princípios por trás do ML, permitindo que você construa seus próprios modelos e aplicativos.
Revisado e ampliado para conter TensorFlow 2.0, esta nova edição apresenta aos leitores os novos recursos da API Keras, bem como as últimas adições ao scikit-learn. Ele contém ainda, técnicas de aprendizado por reforço de última geração com base em aprendizado profundo, e uma introdução aos GANs.
Outro conteúdo importante que esta obra traz é o subcampo de Natural Language Processing (NLP), esta obra também te ajudará a aprender como usar algoritmos de Machine Learning para classificar documentos.
Você aprenderá a:
Dominar as estruturas, modelos e técnicas que permitem que as máquinas “aprendam” com os dados;
Usar biblioteca scikit-learn para Machine Learning e TensorFlow para Deep Learning;
Aplicar Machine Learning à classificação de imagens, análise de sentimento, aplicativos inteligentes da Web e treinar redes neurais, GANs e outros modelos;
Descobrir as melhores práticas para avaliar e ajustar modelos;
Prever resultados de destino contínuos usando análise de regressão;
Aprofundar-se em dados textuais e de mídia social usando análise de sentimento
Para quem é este livro
Iniciante em Python e interessado em Machine Learning e Deep Learning, este livro é para você que deseja começar do zero ou ampliar seu conhecimento de ML. Direcionado a desenvolvedores e cientistas de dados que desejam ensinar computadores a aprenderem com dados.
Aproveite a leitura
O livro Python Machine Learning poderá ser seu companheiro nos estudos, seja você um desenvolvedor Python iniciante em ML ou apenas alguém que queira aprofundar seu conhecimento sobre os desenvolvimentos mais recentes.
Se durante a sua vida profissional ou acadêmica, o grande problema foi encontrar tempo para ler, hoje, a realidade é outra. Pensando nisso o Insight Lab resolveu te dar uma ajudinha com dicas de leitura para você se aprimorar. Incluímos na lista obras técnicas e literárias que te trarão um conteúdo valioso e produtivo para sua carreira. Confira a lista.
Do mesmo criador da biblioteca Pandas, este volume é um guia para quem está no início da formação como programador. Ele ajuda a entender o funcionamento e a combinação de ferramentas para o tratamento de dados dentro do ambiente Python.
A obra é desenvolvida em seções curtas, o que torna a informação mais focada, isso ajudará o programador iniciante a identificar claramente os pontos centrais sem entrar em expansões ainda difíceis de entender.
Neste livro você aprenderá, a partir do zero, como os algoritmos e as ferramentas mais essenciais de data science funcionam. Entenderá a desempenhar bibliotecas, estruturas, módulos e stacks do data science ao mesmo tempo que se aprofunda no tema sem precisar, necessariamente, entender de data science.
O livro reflete sobre o que significa a organização dos dados em gráficos, a quem essas informações visuais serão
apresentadas, e dentro de qual contexto. Para a autora a visualização dos dados é o ponto onde as informações devem estar mais sistematizadas, não podendo se tornar um enigma para quem observa.
Ao longo dos capítulos o livro nos mostra processos de concepção dos elementos para a visualização de dados e traz muitos exemplos de antes e depois, ou seja, exemplos de gráficos que não transmitem corretamente a mensagem e, em seguida, uma versão alternativa onde a informação foi apresentada de forma clara e eficiente.
Um dos melhores livros prático sobre Machine Learning. Seja para iniciante na área ou para quem já atua e precisa de um complemento.
De maneira prática, o livro mostra como utilizar ferramentas simples e eficientes para implementar programas capazes de aprender com dados. Utilizando exemplos concretos, uma teoria mínima e duas estruturas Python, prontas para produção, o autor ajuda você a adquirir uma compreensão intuitiva dos conceitos e ferramentas na construção de sistemas inteligentes.
Direcionado principalmente para desenvolvedores, pesquisadores e analistas de Python que desejam executar análises geoespaciais, de modelagem e GIS com o Python.
O livro é uma ótima dica para quem deseja entender o mapeamento e a análise digital e quem usa Python ou outra linguagem de script para automação ou processamento de dados manualmente.
O livro foi feito para programadores que desejam se familiarizar com a Linguagem de Programação Scala para escrever programas concorrentes, escaláveis e reativos. Não é preciso ter experiência em programação para entender os conceitos explicados no livro. Porém, caso tenha, isso o ajudará a aprender melhor os conceitos.
O autor começa analisando os conceitos básicos da linguagem, sintaxe, tipos de dados principais, literais, variáveis e muito mais. A partir daí, o leitor será apresentado às suas estruturas de dados e aprenderá como trabalhar com funções de alta ordem.
7 – The man who solved the market: how Jim Simons Launched the quant revolution de Gregory Zuckerman
Em tradução livre – O homem que resolveu o mercado: como Jim Simons lançou a Revolução Quant. Um livro não técnico, conta a história de Jim Simons, um matemático que começou a usar estatísticas para negociar ações, em uma época em que todo mundo no mercado usava apenas instintos e análises fundamentais tradicionais.
Obviamente, todo mundo ficou cético em relação a seus métodos, mas depois de anos gerenciando seu fundo de investimentos e obtendo resultados surpreendentes, as pessoas acabaram cedendo e começaram a reconhecer o poder dos chamados quant hedge funds, que desempenham um papel enorme no setor financeiro nos dias atuais.
8 – Feature Engineering for Machine Learning de Alice Zheng e Amanda Casari
Embora a Engenharia de Recursos seja uma das etapas mais importantes no fluxo de trabalho da Ciência de Dados, às vezes ela é ignorada. Este livro é uma boa visão geral desse processo, incluindo técnicas detalhadas, advertências e aplicações práticas.
Ele vem com a explicação matemática e o código Python para a maioria dos métodos, portanto, você precisa de um conhecimento técnico razoável para seguir adiante.
9 – The book of why de Judea Pearl e Dana Mackenzie
Muitas vezes nos dizem que “a correlação não implica causalidade”. Quando você pensa sobre isso, no entanto, o conceito de causalidade não é muito claro: o que exatamente isso significa?
Este livro conta a história de como vemos a causalidade de uma perspectiva filosófica e, em seguida, apresenta as ferramentas e modelos matemáticos para entendê-la. Isso mudará a maneira como você pensa sobre causa e efeito.
10 –Moneyball de Michael Lewis
Esta é a história de Billy Beane e Paul DePodesta, que foram capazes de levar o Oakland Athletics, um pequeno time de beisebol, através de uma excelente campanha na Major League Baseball, escolhendo jogadores negligenciados baratos.
Como eles fizeram isso? Usando dados. Isso mudou a maneira como as equipes escolhem seus jogadores, o que anteriormente era feito exclusivamente por olheiros e seus instintos. A história também inspirou um filme com o mesmo nome, e ambos são obras-primas.
Fonte: crb8.org.br
O que achou das dicas? Que mais livros você incluiria? Compartilha com a gente!
A cultura de aprender pela internet ganha novos adeptos todos os dias. A possibilidade de estudar no melhor horário para você, de explorar metodologias, participar de fóruns online com estudantes do mundo todo, de estudar de casa ou de qualquer outro lugar são alguns dos motivos para os cursos online terem crescido tanto.
Este ano, diante da necessidade do isolamento social provocada pela pandemia de COVID-19, temos mais um motivo para buscar as salas de aula virtuais. Confira abaixo cinco cursos online e gratuitos para fazer durante a quarentena. As opções de cursos que serão apresentadas abrangem os três níveis: iniciante, médio e avançado.
*O conteúdo dos cursos indicados é gratuito, mas, se você quiser receber um certificado de conclusão, precisará pagar.
Cursos para iniciantes
1. Aprendizado de Máquina (Machine Learning)
Plataforma: Coursera
Oferecido por: Standford
Carga horária: 54h
Requisitos: não existem exigências iniciais, mas alguma compreensão de cálculo e, especialmente, de Álgebra Linear será importante para aproveitar o curso ao máximo.
Comentários: Andrew Ng, o instrutor deste curso, é uma lenda nos campos de Machine Learning e Inteligência Artificial. Ele é professor em Standford, um dos fundadores da Coursera e desenvolveu um dos primeiros cursos on-line de Machine Learning, que ainda está disponível no YouTube.
Como o curso se descreve:
“Este curso fornece uma ampla introdução ao Aprendizado de Máquina, Datamining e reconhecimento de padrões estatísticos. Os tópicos incluem: (i) Aprendizado supervisionado (algoritmos paramétricos / não paramétricos, máquinas de vetores de suporte, núcleos, redes neurais). (ii) Aprendizagem não supervisionada (agrupamento, redução de dimensionalidade, sistemas de recomendação, aprendizagem profunda). (iii) Boas práticas em aprendizado de máquina (teoria de viés / variância; processo de inovação em aprendizado de máquina e IA).”
Assuntos tratados:
Regressão linear (Linear regression)
Regressão logística (Logistic regression)
Regularização (Regularization)
Redes neurais (Neural Networks)
Máquinas de vetores de suporte (Support Vector Machines)
Aprendizagem não supervisionada (Unsupervised Learning)
Redução de dimensionalidade (Dimensionality Reduction)
Detecção de anomalia (Anomaly Detection)
Sistemas de recomendação (Recommendation Systems)
2. Aprendizado de máquina com Python (Machine Learning with Python)
Plataforma: Coursera
Oferecido por: IBM
Carga horária: 22h
Requisitos: conhecimento em Matemática Básica.
Comentários: apesar do curso ser classificado como de “nível intermediário” pelo Coursera, é um bom ponto de partida para alguém novo no campo. Também é uma boa opção se você estiver procurando por um curso mais curto que o anterior, de Stanford, pois possui uma carga horária bem menor.
Como o curso se descreve:
“Este curso aborda os conceitos básicos de Aprendizado de Máquina usando uma linguagem de programação acessível e conhecida, o Python. Neste curso, analisaremos dois componentes principais: Primeiro, você aprenderá sobre o objetivo do Machine Learning e onde ele é aplicado no mundo real. Segundo, você obterá uma visão geral dos tópicos do Machine Learning, como aprendizado supervisionado versus não supervisionado, avaliação de modelos e algoritmos de aprendizado de máquina.”
Assuntos tratados:
Regressão (Regression)
Classificação (Classification)
Agrupamento (Clustering)
Sistemas de recomendação (Recommendation Systems)
Cursos de nível intermediário
3. Redes Neurais e Aprendizagem Profunda (Neural Networks and Deep Learning)
Plataforma: Coursera
Oferecido por:deeplearning.ai
Carga horária: 30h
Requisitos: Experiência em codificação Python e Matemática do Ensino Médio. Conhecimentos prévios em Machine Learning e/ou em Deep Learning são úteis.
Comentários: depois de dominar os conceitos básicos do Machine Learning e se familiarizar com o Python, o próximo passo é provavelmente familiarizar-se com o TensorFlow, pois muitos algoritmos computacionalmente caros hoje em dia estão sendo executados com ele. Outro check positivo do curso é que Andrew Ng é um dos instrutores.
Como o curso se descreve:
“Neste curso, você aprenderá os fundamentos do Aprendizado Profundo. Quando você terminar esta aula, você irá:
– Entender as principais tendências tecnológicas que impulsionam o Deep Learning
– Ser capaz de construir, treinar e aplicar redes neurais profundas totalmente conectadas
– Saber como implementar redes neurais eficientes (vetorizadas)
– Entender os principais parâmetros na arquitetura de uma rede neural.”
Assuntos tratados:
Introdução à Aprendizagem Profunda (Introduction to Deep Learning)
Noções básicas sobre redes neurais (Neural Networks basics)
Requisitos: conhecimentos de TensorFlow, codificação Python e Matemática do Ensino Médio.
Comentários: curso ideal para ser feito após os cursos indicados acima.
Como o curso se descreve:
“Este curso ensinará como criar redes neurais convolucionais e aplicá-las a dados de imagem. Graças ao aprendizado profundo, a visão por computador está funcionando muito melhor do que apenas dois anos atrás, e isso está permitindo inúmeras aplicações interessantes, desde direção autônoma segura, reconhecimento facial preciso, até leitura automática de imagens radiológicas.”
Assuntos abordados:
Fundamentos de redes neurais convolucionais (Foundations of Convolutional Neural Networks)
Modelos convolucionais profundos: estudos de caso (Deep convolutional models: case studies)
Detecção de objetos (Object detection)
Aplicações especiais: Reconhecimento facial e transferência de estilo neural (Special applications: Face recognition & Neural style transfer)
Oferecido por: National Research University Higher School of Economics
Carga horária: 10 meses, se você conseguir dedicar seis horas por semana
Requisitos: o curso é projetado para aqueles que já estão na indústria, com uma sólida base em Machine Learning e Matemática.
Comentários: essa é uma especialização completa; portanto, tecnicamente, você pode pular qualquer um dos cursos indicados, se achar que não precisa ou se já cobriu esses tópicos no trabalho ou nos cursos anteriores.
Como o curso se descreve:
“Mergulhe nas técnicas modernas de IA. Você ensinará o computador a ver, desenhar, ler, conversar, jogar e resolver problemas do setor. Esta especialização fornece uma introdução ao aprendizado profundo (deep learning), aprendizado por reforço (reinforcement learning), compreensão de linguagem natural (natural language understanding), visão computacional (computer vision) e métodos bayesianos. Os principais profissionais de Aprendizado de Máquina do Kaggle e os cientistas do CERN (European Organization for Nuclear Research) compartilharão sua experiência na solução de problemas do mundo real e ajudarão você a preencher as lacunas entre teoria e prática.”
Assuntos abordados:
Introdução à Aprendizagem Profunda (Introduction to deep learning) – (32hs)
Como Ganhar um Concurso de Ciência de Dados: Aprenda com os Melhores Kagglers (How to Win a Data Science Competition: Learn from Top Kagglers) – (47hs)
Métodos Bayesianos para Aprendizado de Máquina (Bayesian Methods for Machine Learning) – (30hs)
Aprendizagem Prática de Reforço (Practical Reinforcement Learning) – (30hs)
Aprendizagem Profunda em Visão Computacional (Deep Learning in Computer Vision) – (17hs)
Processamento de Linguagem Natural (Natural Language Processing) – (32hs)
Enfrentando Grandes Desafios de Colisor de Hádrons através do Aprendizado de Máquina (Addressing Large Hadron Collider Challenges by Machine Learning) – (24 horas)
A capacidade de classificar e reconhecer certos tipos de dados vem sendo exigida em diversas aplicações modernas e, principalmente, onde o Big Data é usado para tomar todos os tipos de decisões, como no governo, na economia e na medicina. As tarefas de classificação também permitem que pesquisadores consigam lidar com a grande quantidade de dados as quais têm acesso.
Neste post, iremos explorar o que são essas tarefas de classificação, tendo como foco a classificação multi-label (multirrótulo) e como podemos lidar com esse tipo de dado. Todos os processos envolvidos serão bem detalhados ao longo do texto; na parte final da matéria vamos apresentar uma aplicação para que você possa praticar o conteúdo. Prontos? Vamos à leitura! 😉
Diferentes formas de classificar
Livrarias são em sua maioria lugares amplos, às vezes com um espaço para tomar café, e com muitos, muitos livros. Se você nunca entrou em uma, saiba que é um lugar bastante organizado, onde livros são distribuídos em várias seções, como ficção-científica, fotografia, tecnologia da informação, culinária e literatura. Já pensou em como deve ser complicado classificar todos os livros e colocá-los em suas seções correspondentes?
Não parece tão difícil porque esse tipo de problema de classificação é algo que nós fazemos naturalmente todos os dias. Classificação é simplesmente agrupar as coisas de acordo com características e atributos semelhantes. Dentro do Aprendizado de Máquina, ela não é diferente. Na verdade, a classificação faz parte de uma subárea chamada Aprendizado de Máquina Supervisionado, em que dados são agrupados com base em características predeterminadas.
Basicamente, um problema de classificação requer que os dados sejam classificados em duas ou mais classes. Se o problema possui duas classes, ele é chamado de problema de classificação binário, e se possui mais de duas classes, é chamado de problema de classificação multi-class (multiclasse). Um exemplo de um problema de classificação binário seria você escolher comprar ou não um item da livraria (1 para “livro comprado” e 0 para “livro não comprado”). Já foi citado aqui um típico problema de classificação multi-class: dizer a qual seção pertence determinado livro.
O foco deste post está em um variação da classificação multi-class: a classificação multi-label, em que um dado pode pertencer a várias classes diferentes. Por exemplo, o que fazer com um livro que trata de religião, política e ciências ao mesmo tempo?
Como lidar com dados multi-label
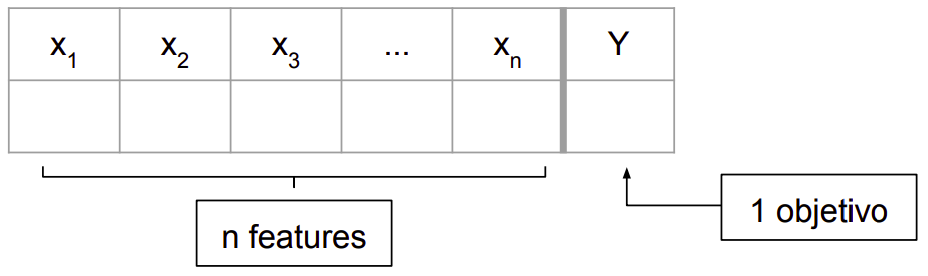
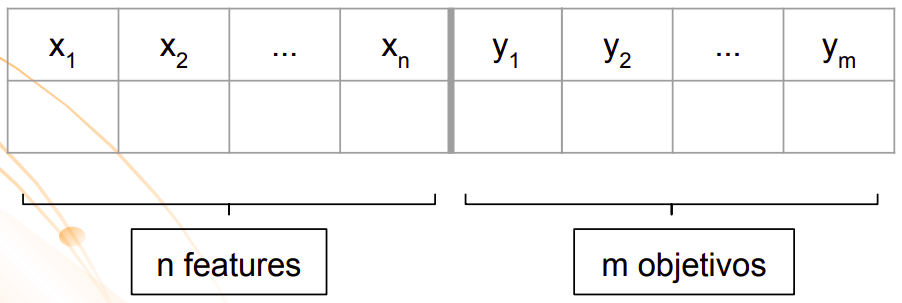
Bem, não sabemos com exatidão como as livrarias resolvem esse problema, mas sabemos que, para qualquer problema de classificação, a entrada é um conjunto de dados rotulado composto por instâncias, cada uma associada a um conjunto de labels (rótulos ou classes).
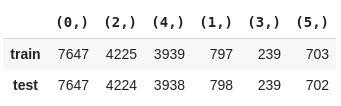
Conjunto de dados para um problema de classificação multi-class
Conjunto de dados para um problema de classificação multi-label
Para que algo seja classificado, um modelo precisa ser construído em cima de um algoritmo de classificação. Tem como garantir que o modelo seja realmente bom antes mesmo de executar ele? Sim! É por isso que os experimentos para esse tipo de problema normalmente envolvem uma primeira etapa: a divisão dos dados em treino (literalmente o que será usado para treinar o modelo) e teste (o que será usado para validar o modelo).
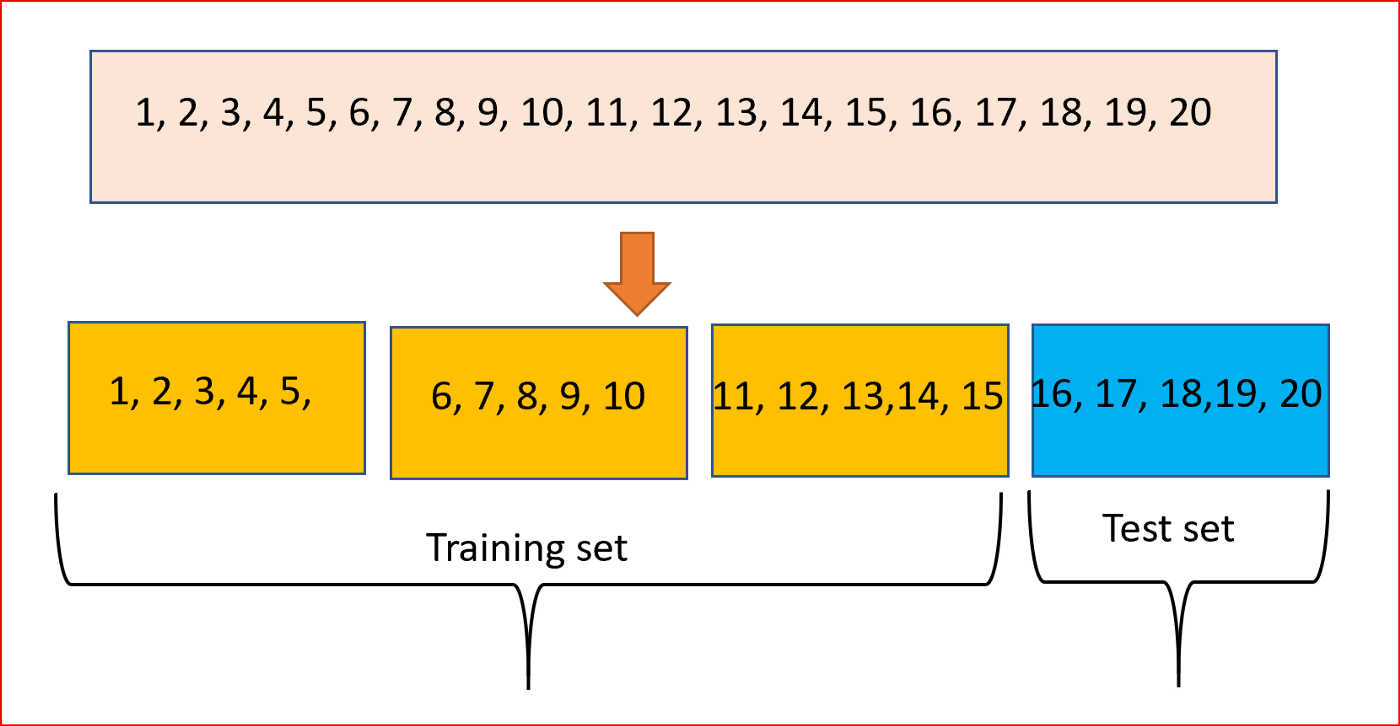
A forma como essa etapa é feita pode variar dependendo da quantidade total do conjunto de dados. Quando os dados são abundantes, utiliza-se um método chamado holdout, em que o dataset (conjunto de dados) é divididoem conjuntos de treino e teste e, às vezes, em um conjunto de validação. Caso os dados sejam limitados, a técnica utilizada para esse tipo de problema é chamada de validação cruzada (cross-validation), que começa dividindo o conjunto de dados em um número de subconjuntos de mesmo tamanho, ou aproximado.
Particionamento dos dados em 4 subconjuntos, 3 para o treino e 1 para o teste
Nas tarefas de classificação, geralmente é usada a versão estratificada desses dois métodos, que divide o conjunto de dados de forma que a proporção de cada classe nos conjuntos de treino e teste sejam aproximadamente iguais a de todo o conjunto de dados. Parece algo simples, mas os algoritmos que realizam esse procedimento o fazem de forma aleatória e não fornecem divisões balanceadas.
Além disso, essa distribuição aleatória pode levar à falta de uma classe rara (que possui poucas ocorrências) no conjunto de teste. A maneira típica como esses problemas são ignorados na literatura é através da remoção completa dessas classes. Isso, no entanto, implica que tudo bem se ignorar esse rótulo, o que raramente é verdadeiro, já que pode interferir tanto no desempenho do modelo quanto nos cálculos das métricas de avaliação.
Agora que a parte teórica foi explicada, vamos à parte prática! 🙂
Apresentação da biblioteca Scikit-multilearn
Sabia que existe uma biblioteca Python voltada apenas para problemas multi-label? Pois é, e ainda possui um nome bem sugestivo: Scikit-multilearn, tudo porque foi construída sob o conhecido ecossistema do Scikit-learn.
O Scikit-multilearn permite realizar diversas operações, mediante as implementações nativas do Python encontradas na biblioteca de métodos populares da classificação multi-label. Caso tenha curiosidade de saber tudo o que ela pode fazer, clique aqui.
A implementação da estratificação iterativa do Scikit-multilearn visa fornecer uma distribuição equilibrada das evidências das classes até uma determinada ordem. Para analisarmos o que isso significa, vamos carregar alguns dados.
Definição do problema
A competição Toxic Comment Classification do Kaggle se trata de um problema de classificação de texto, mais precisamente de classificação de comentários tóxicos. Os participantes devem criar um modelo multi-label capaz de detectar diferentes tipos de toxicidade nos comentários, como ameaças, obscenidade, insultos e ódio baseado em identidade.
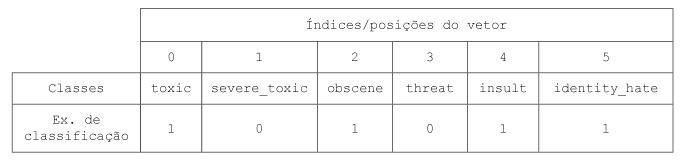
Usaremos como conjunto de dados o conjunto de treino desbalanceado disponível na competição para ilustrar o problema de estratificação de dados multi-label. Esses dados contém um grande número de comentários do Wikipédia, classificados de acordo com os seguintes rótulos:
Avisamos que os comentários desse dataset podem conter texto profano, vulgar ou ofensivo, por isso algumas imagens apresentadas aqui estão borradas. O link para baixar o arquivo train.csv pode ser acessado aqui.
Análise exploratória
Inicialmente, iremos fazer uma breve análise dos dados de modo que possamos resumir as principais características do dataset. Todos os passos até a estratificação estão exemplificados abaixo, com imagens e exemplos em código Python. Se algum código estiver omitido, então alguns trechos são bastante extensos ou se tratam de funções pré-declaradas. Pedimos que acessem o código detalhado, disponível no GitHub, para um maior entendimento.
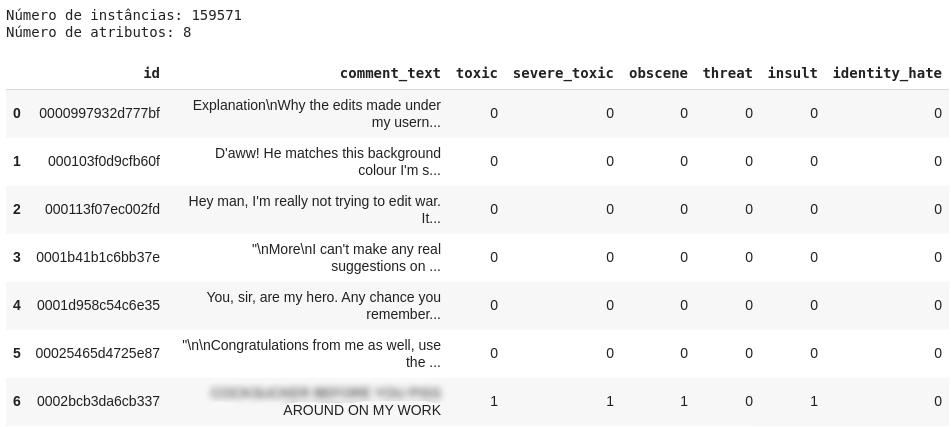
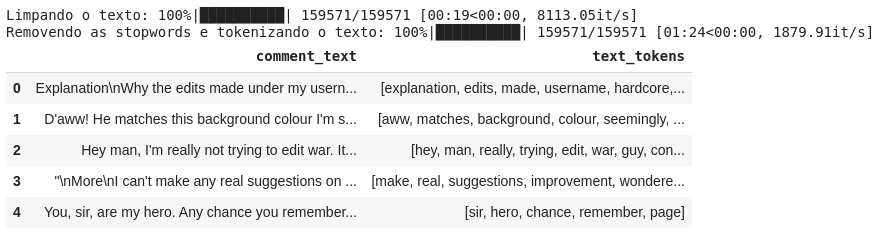
Primeiro, vamos carregar os dados do arquivo train.csv e checar os atributos.
df = pd.read_csv('train.csv')
print('Quantidade de instâncias: {}\nQuantidade de atributos: {}\n'.format(len(df), len(df.columns)))
df[0:7]
Percebe-se que cada label está representada como uma coluna, onde o valor 1 indica que o comentário possui aquela toxicidade e o valor 0 indica que não. Os 6 primeiros textos listados no dataframe não foram classificados em nenhum tipo de toxicidade. Na verdade, quase 90% desse dataset possui textos sem classificação. Não será um problema para nós, pois o método que iremos utilizar considera apenas as classificações feitas.
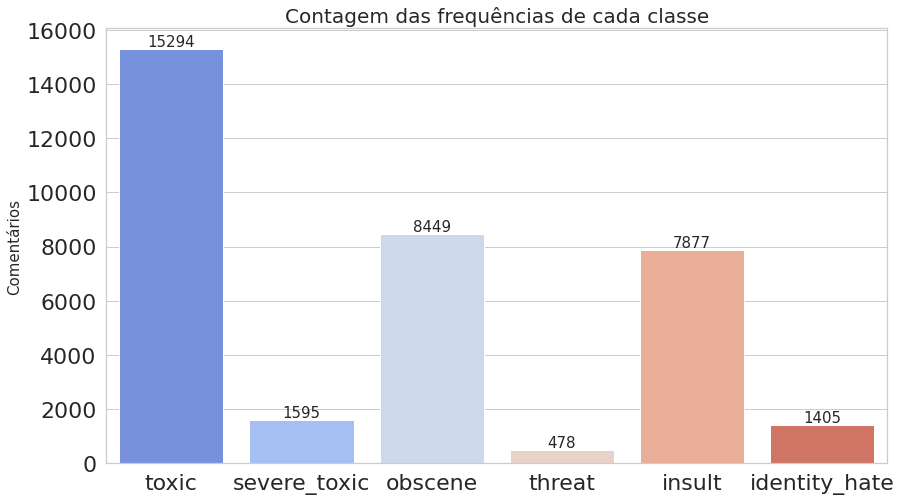
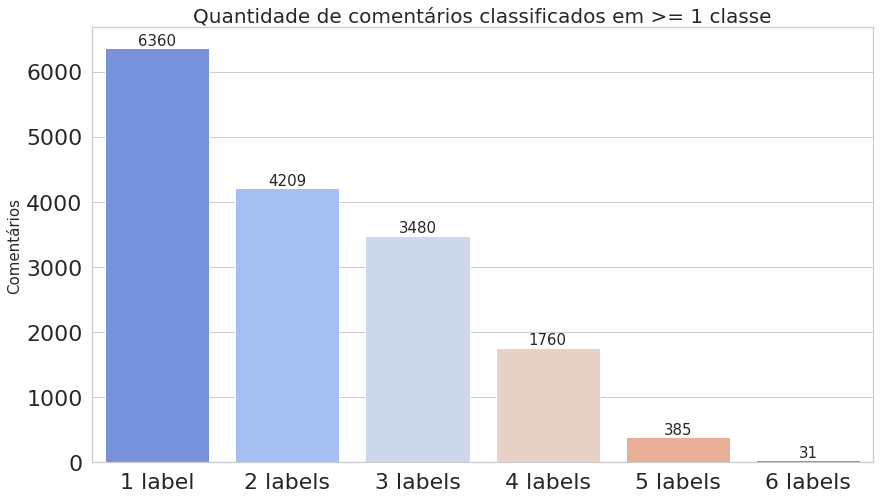
Agora, vamos computar as ocorrências de cada classe, ou seja, quantas vezes cada uma aparece, como também contar o número de comentários que foram classificados com uma ou mais classes. Já podemos notar na imagem acima do dataframe que o texto presente no índice 6 foi classificado como toxic, severe_toxic, obscene e insult.
labels = list(df.iloc[:, 2:].columns.values)
labels_count = df.iloc[:, 2:].sum().values
comments_count = df.iloc[:, 2:].sum(axis=1)
multilabel_counts = (comments_count.value_counts()).iloc[1:]
indexes = [str(i) + ' label' for i in multilabel_counts.index.sort_values()]
plot_histogram_labels(title='Contagem das frequências de cada classe', x_label=labels, y_label=labels_count, labels=labels_count)
plot_histogram_labels(title='Quantidade de comentários classificados em >= 1 classe', x_label=indexes, y_label=multilabel_counts.values, labels=multilabel_counts)
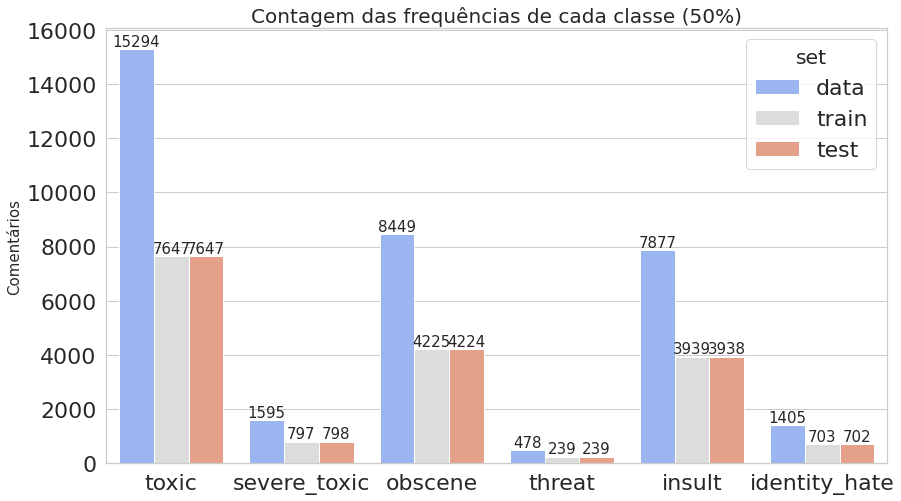
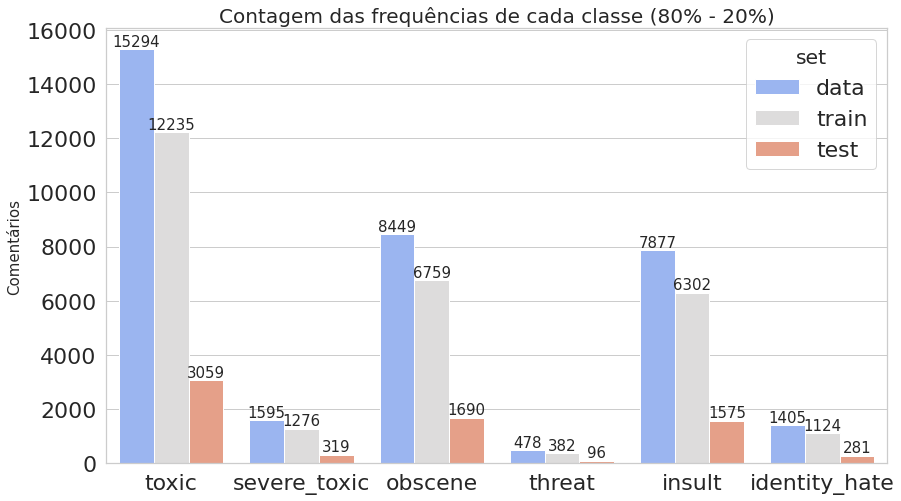
O primeiro gráfico mostra que o dataset é realmente desbalanceado, enquanto o segundo deixa claro que estamos trabalhando com dados multi-label.
Pré-processamento dos dados
O dataset não possui dados faltantes ou duplicados, e nem comentários nulos ou sem classificação (basta olhar como essa análise foi feita aqui no código completo). Apesar de não existirem problemas que podem interferir na qualidade dos dados, um pré-processamento ainda precisa ser feito, pois o intuito é seguir os mesmos passos geralmente realizados até a separação dos dados em treino e teste.
Para esse tipo de problema de classificação de texto, normalmente o pré-processamento envolve o tratamento e limpeza do texto (converter o texto apenas para letras minúsculas, remover as URLs, pontuação, números, etc.), e remoção das stopwords (conjunto de palavras comumente usadas em um determinado idioma). Devemos realizar esse tratamento para que possamos focar apenas nas palavras importantes.
tqdm.pandas(desc='Limpando o texto')
df['text_tokens'] = df['comment_text'].progress_apply(clean_text)
tqdm.pandas(desc='Removendo as stopwords e tokenizando o texto')
df['text_tokens'] = df['text_tokens'].progress_apply(remove_stopwords)
df[['comment_text', 'text_tokens']].head()
Como ilustrado na figura, também foi feito a tokenização do texto, um processo que envolve a separação de cada palavra (tokens) em blocos constituintes do texto, para depois convertê-los em vetores numéricos.
Processo de estratificação
Para divisão do conjunto de dados em conjuntos de treino e teste, usaremos o método iterative_train_test_splitda biblioteca Scikit-multilearn. Antes de prosseguir, esse método assume que possuímos as seguintes matrizes:
Devemos, então, fazer alguns tratamentos para obtermos o X e o y ideais para serem usados como entrada na função. Além disso, também passamos como parâmetro a proporção que desejamos para o teste (o restante será colocado no conjunto de treino). Esse método nos retornará a divisão estratificada do dataset(X_train, y_train, X_test, y_test).
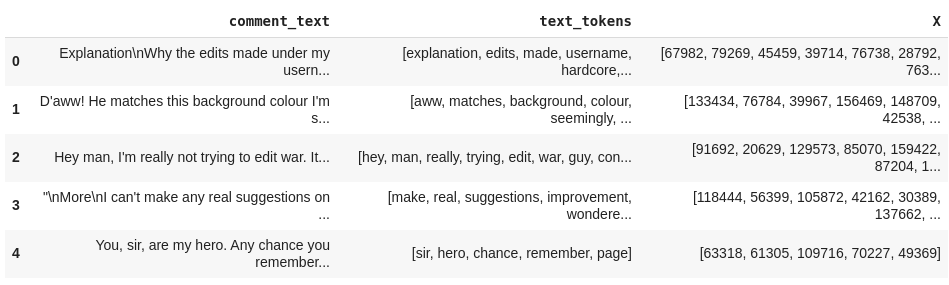
Inicialmente, iremos gerar o X. Até agora o que temos são os tokens do texto, então precisamos mapeá-los para transformá-los em números. Para isso, podemos pegar todas as palavras (tokens) presentes em text_tokens e atribuir a cada uma um id. Assim, criaremos uma espécie de vocabulário.
text_tokens = []
VOCAB = {}
for vet in df['text_tokens'].values:
text_tokens.extend(vet)
text_tokens_set = (list(set(text_tokens)))
for index, word in enumerate(text_tokens_set):
VOCAB[word] = index + 1
print('Quantidade de palavras presentes no texto: {}'.format(len(text_tokens)))
print('Tamanho do vocabulário (palavras sem repetição): {}\n'.format(len(text_tokens_set)))
VOCAB
Com esse vocabulário, conseguimos mapear as palavras para os id’s.
Como o X deve ter a dimensão (número_de_amostras, número_de_instâncias) e como o tamanho de alguns textos deve ser bem maior que de outros, temos que achar o texto com a maior quantidade de palavras e salvar seu tamanho. Depois, fazemos um padding (preenchimento) no restante dos textos, acrescentando 0’s no final de cada vetor até atingir o tamanho máximo estabelecido.
A matriz do y deve conter a dimensão (número_de_amostras, número_de_labels), então pegamos os valores das colunas referentes às classes. Atente para o fato de que cada posição dos vetores presentes em y corresponde a uma classe.
Outra forma de criação do y seria contar as ocorrências das classes para cada texto. Logo, ao invés de utilizar valores binários para indicar que existem palavras pertencentes ou não a um rótulo, colocaríamos os valores das frequências desses rótulos.
from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(maxlen=max_num_words, sequences=df['X'], value=0, padding='post', truncating='post')
y = df[labels].values
print('Dimensão do X: {}'.format(X.shape))
print('Dimensão do y: {}'.format(y.shape))
5. Pronto! Agora podemos fazer a divisão do dataset. Demonstraremos dois exemplos: dividir o dataset em 50% para treino e teste, e dividir em 80% para treino e 20% para teste.
from skmultilearn.model_selection import iterative_train_test_split
# 50% para cada
np.random.seed(42)
X_train, y_train, X_test, y_test = iterative_train_test_split(X, y, test_size=0.5)
# 80% para treino e 20% para teste
np.random.seed(42)
X_train_20, y_train_20, X_test_20, y_test_20 = iterative_train_test_split(X, y, test_size=0.2)
Os conjuntos de treino e teste estão realmente estratificados?
Por fim, iremos analisar se a proporção entre as classes foi realmente mantida.
Plotamos novamente os gráficos que contam quantas vezes cada classe aparece, comparando todo o conjunto de dados com os dados de treino e teste obtidos.
plot_histogram_labels('Contagem das frequências de cada classe (50%)', x_label='labels', y_label='ocorr', labels=classif_train_test, hue_label='set', data=inform_train_test)
plot_histogram_labels('Contagem das frequências de cada classe (80% - 20%)', x_label='labels', y_label='ocorr', labels=classif_train_test_20, hue_label='set', data=inform_train_test_20)
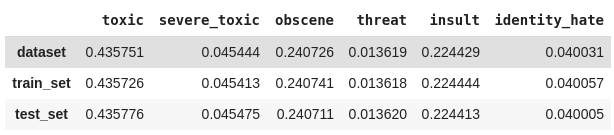
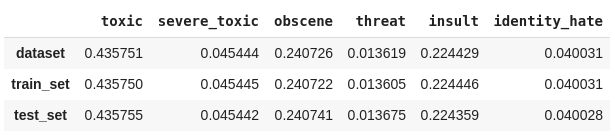
2. Podemos calcular manualmente a proporção das classes dividindo a quantidade de ocorrências de cada classe pelo número total de classificações. Também iremos verificar se a divisão está proporcional utilizando uma métricado Scikit-multilearn que retorna as combinações das classes atribuídas a cada linha.
from collections import Counter
from skmultilearn.model_selection.measures import get_combination_wise_output_matrix
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test, order=1) for combination in row)
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train_20, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test_20, order=1) for combination in row)
}).T.fillna(0.0)
É isso, gente. Esperamos que esse post tenha sido útil, principalmente para quem já enfrentou um problema parecido e não soube o que fazer.
Uma dica de ouro! Um dos melhores livros prático sobre Machine Learning. Seja para você, iniciante na área e que precisa de um guia, ou para quem já atua e precisa de um complemento.
MÃOS À OBRA: APRENDIZADO DE MÁQUINA COM SCIKIT-LEARN & TENSORFLOW. Conceitos, ferramentas e técnicas para a construção de sistemas inteligentes de Aurélien Géron é um livro com ótima avaliação pelos leitores.
De maneira prática, o livro mostra como utilizar ferramentas simples e eficientes para implementar programas capazes de aprender com dados. Utilizando exemplos concretos, uma teoria mínima e duas estruturas Python prontas para produção ― Scikit-Learn e TensorFlow ― o autor Aurélien Géron ajuda você a adquirir uma compreensão intuitiva dos conceitos e ferramentas para a construção de sistemas inteligentes.
Você aprenderá uma variedade de técnicas, desde de uma regressão linear simples até redes neurais profundas. Com exercícios em cada capítulo para ajudá-lo a aplicar o que aprendeu, você só precisa ter experiência em programação para começar.
Segundo Pete Warden, líder mobile do TensorFlow, o livro é uma ótima introdução à teoria e prática na resolução de problemas com redes neurais abrangendo os pontos-chave necessários para entender novas pesquisas.
Na edição atualizada o livro traz exemplos concretos, teoria mínima e três estruturas Python prontas para produção – scikit-learn, Keras e TensorFlow – para ajudá-lo a obter uma compreensão intuitiva dos conceitos e ferramentas para a construção de sistemas inteligentes.
Curiosidades sobre o autor: Aurélien Géron ensinou seus 3 filhos a contar em binário com os dedos (até 1023), ele estudou microbiologia e genética evolutiva antes de entrar na engenharia de software, e seu paraquedas não abriu no segundo salto.
Buscando alguma série para assistir neste fim de semana? Nós temos uma dica: “The Age of A.I.”, série documental produzida pelo YouTube Originals.
Apresentada pelo ator Robert Downey Junior, a série mostra o trabalho de alguns dos pesquisadores mais influentes no desenvolvimento do potencial da inteligência artificial. Em quatro episódios, vamos acompanhar a quais níveis a IA já chegou e o que se espera que sejamos capazes de produzir com ela no futuro, como o aperfeiçoamento da computação afetiva, onde máquinas aprendem a sentir e reagir de uma forma cada vez mais humana.
Existe uma infinidade de opções para classificação. Em geral, não existe uma única opção “melhor” para todas as situações. Dito isto, três métodos populares de classificação – Decision Trees, k-NN e Naive Bayes – podem ser aprimorados para praticamente todas as situações.
visão global
Naive Bayes e K-NN, são dois exemplos de aprendizado supervisionado (onde os dados já vêm rotulados). Árvores de decisão são fáceis de usar para pequenas quantidades de classes. Se você está tentando decidir entre os três, sua melhor opção é levar todos os três para um test drive em seus dados e ver qual produz os melhores resultados.
Se você é novo na classificação, uma árvore de decisão é provavelmente o seu melhor ponto de partida. Isso lhe dará um visual claro e é ideal para entender o que a classificação está realmente fazendo. K-NN vem em um segundo próximo; Embora a matemática por trás disso seja um pouco assustadora, você ainda pode criar um visual do processo do vizinho mais próximo para entender o processo. Finalmente, você vai querer cavar na Naive Bayes. A matemática é complexa, mas o resultado é um processo altamente preciso e rápido – especialmente quando você está lidando com Big Data.
Onde Bayes se destaca
1. Naive Bayes é um classificador linear enquanto K-NN não é; Tende a ser mais rápido quando aplicado a big data. Em comparação, k-nn geralmente é mais lento para grandes quantidades de dados, devido aos cálculos necessários para cada nova etapa do processo. Se a velocidade for importante, escolha Naive Bayes sobre K-NN.
2. Em geral, Naive Bayes é altamente acurado quando aplicado a big data. Não desconsidere o K-NN quando se trata de precisão; como o valor de k no K-NN aumenta, a taxa de erro diminui até atingir a do Bayes ideal (para k → ∞).
3. Naive Bayes oferece a você dois hiperparâmetros para ajustar para suavização: alfa e beta. Um hiperparâmetro é um parâmetro anterior que é ajustado no conjunto de treinamento para otimizá-lo. Em comparação, o K-NN tem apenas uma opção de ajuste: o “k”Ou número de vizinhos.
4. Este método não é afetado pelo maldição da dimensionalidade e euconjuntos de recursos arge, enquanto o K-NN tem problemas com ambos.
1. Se tiver independência condicional Se você tiver uma classificação de afeto altamente negativo, escolha K-NN em vez de Naive Bayes. Naive Bayes pode sofrer com a problema de probabilidade zero; quando a probabilidade condicional de um atributo específico for igual a zero, o Naive Bayes falhará completamente em produzir uma previsão válida. Isso poderia ser corrigido usando um estimador Laplaciano, mas o K-NN poderia acabar sendo a escolha mais fácil.
2. Naive Bayes só funcionará se o limite de decisão é linear, elíptico ou parabólico. Caso contrário, escolha K-NN.
3. Naive Bayes requer que você conheça o subjacente distribuições de probabilidade para categorias. O algoritmo compara todos os outros classificadores contra esse ideal. Portanto, a menos que você conheça probabilidades e pdfs, o uso do Bayes ideal não é realista. Em comparação, o K-NN não exige que você saiba nada sobre as distribuições de probabilidade subjacentes.
4. O K-NN não requer nenhum Treinamento– você apenas carrega o conjunto de dados e ele é executado. Por outro lado, Naive Bayes requer treinamento.
5. O K-NN (e Naive Bayes) superam as árvores de decisão quando se trata de ocorrências raras. Por exemplo, se você está classificando tipos de câncer na população em geral, muitos tipos de câncer são bastante raros. Uma árvore de decisão quase certamente removerá essas classes importantes do seu modelo. Se você tiver ocorrências raras, evite usar árvores de decisão.
1. Dos três métodos, as árvores de decisão são as mais fácil de explicar e entender. A maioria das pessoas entende árvores hierárquicas, e a disponibilidade de um diagrama claro pode ajudá-lo a comunicar seus resultados. Por outro lado, a matemática subjacente ao Teorema de Bayes pode ser muito difícil de entender para o leigo. K-NN se encontra em algum lugar no meio; Teoricamente, você pode reduzir o processo K-NN a um gráfico intuitivo, mesmo que o mecanismo subjacente esteja provavelmente além do nível de entendimento de um leigo.
2. As árvores de decisão têm recursos fáceis de usar para identificar as dimensões mais significativas, lidar com valores ausentes e lidar com valores discrepantes.
3. Embora excessivo Como é um grande problema com as árvores de decisão, a questão poderia (pelo menos em teoria) ser evitada usando árvores reforçadas ou florestas aleatórias. Em muitas situações, o reforço ou florestas aleatórias podem resultar em árvores com desempenho superior a Bayes ou K-NN. A desvantagem desses complementos é que eles adicionam uma camada de complexidade à tarefa e diminuem a grande vantagem do método, que é sua simplicidade.
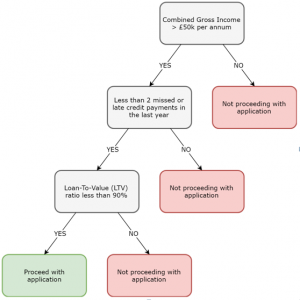
Mais galhos em uma árvore levam a uma chance maior de adaptação excessiva. Portanto, as árvores de decisão funcionam melhor para um pequeno número de aulas. Por exemplo, a imagem acima resulta apenas em duas classes: continue ou não prossiga.
4. Ao contrário de Bayes e K-NN, as árvores de decisão podem trabalhar diretamente de um tabela de dados, sem qualquer trabalho prévio de design.
5. Se você não conhece seus classificadores, uma árvore de decisão será escolha esses classificadores para você de uma tabela de dados. Naive Bayes requer que você conheça seus classificadores com antecedência.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade