Introdução
O Big Data e Inteligência Artificial é um projeto em desenvolvimento pelo Insight Lab e o Ministério da Justiça e Segurança Pública. O objetivo desse projeto é realizar estudos científicos para criar uma plataforma que permitirá integrar e analisar fontes de dados de segurança pública dos estados brasileiros, direcionando, então, a implantação de estratégias para a melhoria da segurança pública.
Entre as ferramentas já disponíveis desse projeto está o Geointeligência, que é um sistema de georreferenciamento aplicado na segurança pública. E desde 2020, essa ferramenta também está sendo usada na área da saúde, pois, devido à pandemia de Covid-19, o Governo do Ceará implementou o Geointeligência para entender a disseminação dessa doença no estado.
Importação de eventos é uma das principais funcionalidades do Geointeligência. Implementado utilizando a linguagem de programação Scala com Play Framework, ele é um dos sistemas desenvolvidos por nossa equipe e tem como objetivo analisar eventos espaço-temporais através de algoritmos que procuram encontrar padrões capazes de ajudar na melhor aplicação de forças tarefas de segurança.
Como o Geointeligência é um sistema analítico, ele precisa que os eventos utilizados em suas análises sejam adicionados à sua base. E uma das maneiras mais importantes para fazer isso é a importação através de arquivos do tipo csv ou xlsx.
A importação de arquivos traz a facilidade de qualquer usuário poder importar seus eventos e utilizar o sistema para fazer análises a fim de identificar padrões úteis em seus eventos. Sem a importação de arquivos, nenhuma organização ou usuário poderiam criar análises com seus eventos, e com isso as análises seriam menos eficazes para diversos casos. Tendo isso em vista, a importação de eventos tem a necessidade de ser uma funcionalidade robusta e eficaz para importar eventos em larga escala.
Motivação – Processando muitos eventos
A importação de eventos passou a ser uma funcionalidade muito importante para nossos usuários. Com isso, notamos que a maioria deles tinham que dividir os arquivos de importação em diversos arquivos menores devido à limitação de tamanho e ao tempo que eles esperavam que sua tarefa fosse concluída para, só então, ter uma resposta do sistema.
Por conta disso, nossa equipe resolveu que precisávamos melhorar a eficiência da importação para que fosse possível processar muitos eventos através de um único arquivo e com vários usuários ao mesmo tempo. Quantos eventos nós queríamos ser capazes de processar em um só arquivo?
> Que tal 300.000 eventos?
Arquivos grandes
Em virtude dos requisitos que nós tínhamos à época, nossa implementação inicial da funcionalidade de importação de arquivos era bem simples. Uma vez que o servidor recebesse a requisição HTTP do usuário, ele carregaria todo o arquivo em memória e faria todo o processamento necessário dos eventos contidos nele dentro do escopo dessa mesma requisição, retornando então para o usuário uma resposta com a quantidade de eventos importados.
Dada a necessidade de se importar grandes quantidades de eventos, surgiram dois problemas principais com essa implementação. O arquivo que deveria conter essa maior quantidade de eventos a serem importados precisaria ser significativamente maior, ocasionando um consumo de memória que tornaria progressivamente mais limitada a utilização dessa funcionalidade por múltiplos usuários ao mesmo tempo.
Além disso, mais eventos significavam que a aplicação precisaria gastar proporcionalmente mais tempo para processar um arquivo completo. Por conta disso e pelo fato de a importação ser realizada dentro do escopo de uma requisição HTTP, o usuário poderia precisar esperar por muito tempo até que o upload desse arquivo fosse feito e seus eventos fossem validados e inseridos na base de dados, para só então ter uma resposta e poder seguir utilizando a aplicação, que ficaria “bloqueada” esperando a finalização da requisição.
Devido ao impacto causado pelo consumo de memória e o tempo de espera do usuário durante uma importação, nós precisávamos resolver esses problemas para obtermos uma implementação que suportasse a importação de grandes quantidades de eventos.
Para resolver o problema do consumo de memória, tivemos de elaborar uma estratégia para o processamento do arquivo na qual fosse garantido que o arquivo em si nunca fosse integralmente carregado em memória, o que ampliaria a escalabilidade da aplicação e permitiria, mais facilmente, a possibilidade de importações sendo executadas simultaneamente.
Em paralelo, para resolver o problema de espera do usuário, chegamos à conclusão de que o processamento dos eventos não poderia estar limitado ao escopo de uma requisição do usuário. Isto é, uma vez que o usuário iniciasse uma importação, o Geointeligência deveria ser capaz de respondê-lo que sua requisição de importação fora aceita, mas o processo de importação em si deveria ser executado em segundo plano. Por consequência, uma vez que a importação fosse executada fora do escopo da requisição de importação, o usuário precisaria receber algum tipo de feedback do sistema informando-o quando sua tarefa fosse concluída. Desta forma, nós também tivemos de desenvolver um mecanismo, independente do escopo de uma requisição, capaz de informar ao usuário que sua importação foi concluída.
Disco é mais barato que memória RAM
Com o crescimento no tamanho dos arquivos de importação, a estratégia que nós havíamos implementado já não funcionava. Para resolver isso, uma opção seria guardar todo o arquivo em disco e depois ir carregando apenas partes dele na memória à medida que os eventos contidos nele fossem sendo processados.
Felizmente, para uma linguagem como o Scala, carregar apenas uma parte de um arquivo em memória não é uma tarefa difícil, uma vez que esse arquivo esteja salvo em disco ou em uma base de dados. Para implementar isso, nós utilizamos apenas as abstrações de InputStream e OutputStream nativas da linguagem de programação, sem que houvesse a necessidade da utilização de nenhuma biblioteca externa. Como os arquivos que nós usávamos armazenavam os eventos de modo sequencial, nós tínhamos tudo o que precisávamos para implementar essa arquitetura.
Desta forma, nós implementamos a seguinte estratégia:
- Assim que o servidor recebesse a requisição com o arquivo de eventos, ele seria diretamente armazenado em nossa base de dados através de um stream;
- Quando necessário, o sistema retiraria, também através de um stream, partes do arquivo contendo blocos de eventos que precisavam ser validados e inseridos;
- Cada bloco de eventos seria, então, processado de modo independente, isto é, cada um dos eventos de um bloco deveria passar por uma série de validações antes de serem inseridos em nossa base;
- Quando todo o arquivo fosse consumido, isto é, quando todo o seu conteúdo tivesse sido “lido”, e todos os seus eventos fossem processados, o sistema removeria esse arquivo da base.
Utilizando essa estratégia, nós conseguimos controlar de maneira muito mais detalhada o quanto do arquivo seria carregado na memória dos nossos servidores, além de permitir que partes de um mesmo arquivo pudessem ser processadas paralelamente.
O usuário não pode esperar
Importar algumas centenas de eventos no escopo de uma requisição HTTP era algo simples. Processar um arquivo pequeno com essa quantidade de eventos não é uma tarefa tão custosa assim. O usuário ficaria esperando alguns poucos segundos e a tarefa dele estaria concluída.
Acontece que esse padrão de uso não durou muito tempo e logo os usuários precisaram fazer importações na casa dos milhares de eventos. Essas importações demoravam mais, deixando o usuário esperando por vários segundos; isso quando o processo todo conseguia ser executado dentro do tempo limite de uma requisição HTTP.
Isso não estava bom o suficiente. Nós precisávamos permitir que nosso sistema fosse robusto o bastante para permitir importações maiores e gostaríamos também que o usuário não fosse obrigado a ficar esperando sua importação terminar para realizar outras atividades dentro do sistema.
Nós precisávamos que as importações feitas no Geointeligência acontecessem em segundo plano, isto é, uma vez que o usuário iniciasse uma importação, esta deveria acontecer fora do escopo de sua requisição, e o usuário deveria ter alguma forma de verificar se sua tarefa já havia sido concluída.
Para isso, nós utilizamos a ferramenta mais indicada para a nossa necessidade e que estava à nossa disposição: o Akka.
Por que Akka e Akka Cluster?
O Akka é um conjunto de ferramentas que simplifica a construção de aplicativos concorrentes e distribuídos na JVM. Como nossos sistemas são implementados utilizando a linguagem de programação Scala, que roda na JVM, o Akka costuma ser uma ótima ferramenta para nos auxiliar a tornar nossos sistemas mais poderosos. Além disso, o Akka nos traz a possibilidade de trabalhar com o modelo de atores, que facilita o nosso trabalho como desenvolvedores no processo de criação de sistemas concorrentes e distribuídos.
Outro ponto importante é que nossa infraestrutura prevê a possibilidade da criação de múltiplas instâncias da mesma aplicação com o objetivo de suportar uma maior quantidade de usuários durante um momento de estresse do sistema. Desse modo, o Akka, juntamente com o Akka Cluster, nos permitem desenvolver funcionalidades utilizando modelo de atores com o objetivo de tornar transparente para o desenvolvedor questões de gerenciamento e comunicação entre mais de uma instância de um mesmo sistema.
Conversa entre atores
No fim, para conseguirmos que a importação fosse toda processada fora do escopo da requisição do usuário, nós tivemos que fazer grandes mudanças na forma como ela era implementada, substituindo a estratégia anterior por uma baseada no modelo de atores. Resumidamente, essa estratégia utiliza um conjunto de atores, pequenas unidades de processamento capazes de se comunicar entre si através de mensagens, que são responsáveis por executar cada passo da importação.
Para implementar essa arquitetura de atores nós utilizamos a API de atores do Akka, uma vez que ela já abstrai uma porção de detalhes de gerenciamento de threads e bloqueios, tornando o trabalho do desenvolvedor mais focado na construção do sistema em si e nas interações entre os atores.
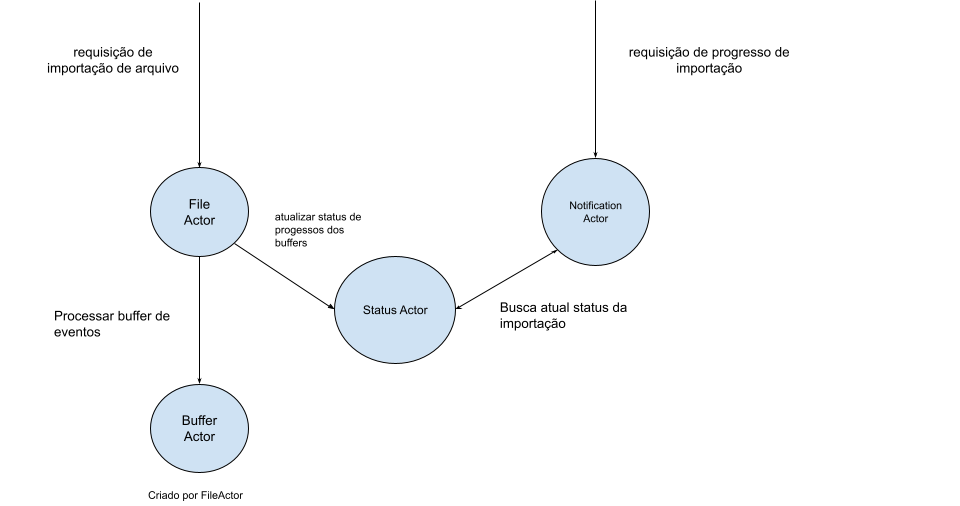

Resumidamente, quando um usuário envia uma requisição de importação para o sistema, o arquivo enviado é imediatamente salvo em nossa base de dados e uma mensagem com informações desse arquivo é enviada para um ator de arquivo (File Actor). As principais responsabilidades desse ator de arquivo são controlar o andamento da importação e carregar o arquivo de importação armazenado na base em partes na memória. Toda essa etapa inicial é executada ainda dentro do escopo da requisição HTTP do usuário, mas a partir desse ponto a execução ocorre em segundo plano.
O ator de arquivo, então, envia uma parte do arquivo para um segundo ator: o ator de blocos de eventos (Buffer Actor). Ele funciona como um buffer, responsável por processar um bloco de eventos, realizando as devidas validações e inserindo os eventos válidos na base. Uma vez que o ator de blocos de eventos tenha inserido todo um bloco de eventos, ele notifica novamente o ator de arquivo com informações desses eventos. O ator de arquivo então envia para um terceiro ator (Status Actor) as informações atualizadas da importação. Esse ator é responsável por manter o estado da importação com informações como quantidade de eventos inseridos e quantidade de erros encontrados.
O ator de arquivos, então, reinicia seu ciclo de execução, retirando partes do arquivo, uma a uma, e enviando-as para o ator de blocos. Por fim, quando o último bloco do arquivo é retirado da base e seus eventos são processados, o ator de arquivo remove esse arquivo da base, completando assim o processo de importação.
Acompanhando o progresso
A evolução da importação para ser processada fora do escopo de uma requisição HTTP não bloqueando o usuário no sistema gerou a necessidade de uma funcionalidade de feedback para o usuário sobre o processamento da importação do seu arquivo de eventos. A nossa arquitetura de atores possui um ator de notificação (Notification Actor) cuja função é justamente disponibilizar informações sobre as importações que estão ocorrendo naquele momento.
Por isso, surgiu a ideia de criar um canal de comunicação direto entre o front-end e esse ator de notificação através de um Websocket. Sempre que o ator de estado da importação é atualizado com novas informações de importações atuais, ele utiliza esse Websocket para enviar mensagens com o progresso dessas importações para o front-end que, por sua vez, fica responsável por apresentar ao usuário essas informações como indicado na imagem abaixo:
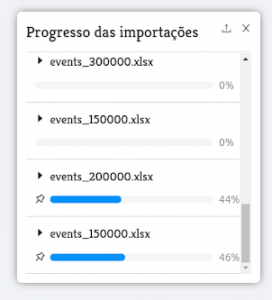

O Geointeligência apresenta cada importação com uma barra de progresso sendo atualizada em tempo real. Ao clicar sobre a importação, o usuário verá mais informações sobre a quantidade de eventos que estão sendo inseridos, repetidos ou se houve erros:
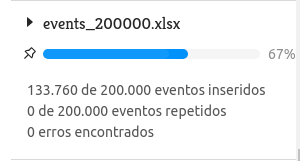
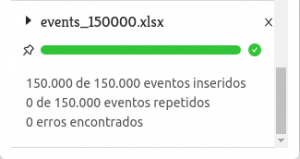


Com essa funcionalidade o usuário tem a todo instante o entendimento do momento atual de sua importação e pode continuar usando o sistema sem precisar esperar que todo o processo seja finalizado.
Capacidade de importação
O Geointeligência passou a importar de forma eficaz uma quantidade significativamente maior de eventos por arquivo. Essa evolução deveu-se à saída do escopo de uma requisição HTTP, leitura otimizada do arquivo durante processamento, adição do modelo de atores do Akka para processamento de eventos e introdução do Akka Cluster para suportar diversas instâncias
Hoje, nosso sistema consegue importar arquivos com 300 mil eventos em pouco mais de dois minutos, sem que o usuário precise esperar o processamento de todos esses eventos para continuar a utilizar o sistema. O usuário pode fazer uma análise de eventos enquanto outros são importados. Isso melhorou a usabilidade do nosso sistema, permitindo ao usuário utilizar seu tempo para fazer as análises em vez de preparar os dados.
Conclusão
Com tudo isso, nossa equipe encontrou uma ótima forma de lidar com uma importação maciça de eventos sem precisar que o usuário esperasse a finalização de todo o processamento.
A utilização do Akka e de atores trouxe mais responsividade para a funcionalidade e, com isso, a utilização de mensagens assíncronas para informar progresso ao usuário permitiu que nosso sistema se comportasse de maneira mais reativa.
Nossos usuários ganharam tempo de processamento com o uso de modelo de atores para processar partes dos eventos por vez, e além disso, agora eles podem acompanhar todo o processo em tempo real com o progresso visual. A saída do escopo da requisição HTTP trouxe muitas vantagens para a importação no Geointeligência e a utilização do Akka fez com que o desenvolvimento disso fosse bem menos complexo do que poderia ser.
Melhorar a experiência do usuário é sempre um objetivo que devemos procurar dentro de nossos sistemas.