Comparando Classificadores: Árvores de Decisão, K-NN e Naive Bayes
Existe uma infinidade de opções para classificação. Em geral, não existe uma única opção “melhor” para todas as situações. Dito isto, três métodos populares de classificação – Decision Trees, k-NN e Naive Bayes – podem ser aprimorados para praticamente todas as situações.
visão global
Naive Bayes e K-NN, são dois exemplos de aprendizado supervisionado (onde os dados já vêm rotulados). Árvores de decisão são fáceis de usar para pequenas quantidades de classes. Se você está tentando decidir entre os três, sua melhor opção é levar todos os três para um test drive em seus dados e ver qual produz os melhores resultados.
Se você é novo na classificação, uma árvore de decisão é provavelmente o seu melhor ponto de partida. Isso lhe dará um visual claro e é ideal para entender o que a classificação está realmente fazendo. K-NN vem em um segundo próximo; Embora a matemática por trás disso seja um pouco assustadora, você ainda pode criar um visual do processo do vizinho mais próximo para entender o processo. Finalmente, você vai querer cavar na Naive Bayes. A matemática é complexa, mas o resultado é um processo altamente preciso e rápido – especialmente quando você está lidando com Big Data.
Onde Bayes se destaca
1. Naive Bayes é um classificador linear enquanto K-NN não é; Tende a ser mais rápido quando aplicado a big data. Em comparação, k-nn geralmente é mais lento para grandes quantidades de dados, devido aos cálculos necessários para cada nova etapa do processo. Se a velocidade for importante, escolha Naive Bayes sobre K-NN.
2. Em geral, Naive Bayes é altamente acurado quando aplicado a big data. Não desconsidere o K-NN quando se trata de precisão; como o valor de k no K-NN aumenta, a taxa de erro diminui até atingir a do Bayes ideal (para k → ∞).
3. Naive Bayes oferece a você dois hiperparâmetros para ajustar para suavização: alfa e beta. Um hiperparâmetro é um parâmetro anterior que é ajustado no conjunto de treinamento para otimizá-lo. Em comparação, o K-NN tem apenas uma opção de ajuste: o “k”Ou número de vizinhos.
4. Este método não é afetado pelo maldição da dimensionalidade e euconjuntos de recursos arge, enquanto o K-NN tem problemas com ambos.
5. Para tarefas como robótica e visão computacional, Bayes supera árvores de decisão.
Onde K-NN se destaca
1. Se tiver independência condicional Se você tiver uma classificação de afeto altamente negativo, escolha K-NN em vez de Naive Bayes. Naive Bayes pode sofrer com a problema de probabilidade zero; quando a probabilidade condicional de um atributo específico for igual a zero, o Naive Bayes falhará completamente em produzir uma previsão válida. Isso poderia ser corrigido usando um estimador Laplaciano, mas o K-NN poderia acabar sendo a escolha mais fácil.
2. Naive Bayes só funcionará se o limite de decisão é linear, elíptico ou parabólico. Caso contrário, escolha K-NN.
3. Naive Bayes requer que você conheça o subjacente distribuições de probabilidade para categorias. O algoritmo compara todos os outros classificadores contra esse ideal. Portanto, a menos que você conheça probabilidades e pdfs, o uso do Bayes ideal não é realista. Em comparação, o K-NN não exige que você saiba nada sobre as distribuições de probabilidade subjacentes.
4. O K-NN não requer nenhum Treinamento– você apenas carrega o conjunto de dados e ele é executado. Por outro lado, Naive Bayes requer treinamento.
5. O K-NN (e Naive Bayes) superam as árvores de decisão quando se trata de ocorrências raras. Por exemplo, se você está classificando tipos de câncer na população em geral, muitos tipos de câncer são bastante raros. Uma árvore de decisão quase certamente removerá essas classes importantes do seu modelo. Se você tiver ocorrências raras, evite usar árvores de decisão.
Onde árvores de decisão se destacam
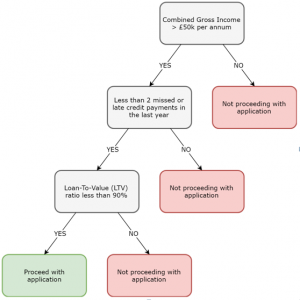
Imagem: Árvore de decisão para um credor hipotecário.
1. Dos três métodos, as árvores de decisão são as mais fácil de explicar e entender. A maioria das pessoas entende árvores hierárquicas, e a disponibilidade de um diagrama claro pode ajudá-lo a comunicar seus resultados. Por outro lado, a matemática subjacente ao Teorema de Bayes pode ser muito difícil de entender para o leigo. K-NN se encontra em algum lugar no meio; Teoricamente, você pode reduzir o processo K-NN a um gráfico intuitivo, mesmo que o mecanismo subjacente esteja provavelmente além do nível de entendimento de um leigo.
2. As árvores de decisão têm recursos fáceis de usar para identificar as dimensões mais significativas, lidar com valores ausentes e lidar com valores discrepantes.
3. Embora excessivo Como é um grande problema com as árvores de decisão, a questão poderia (pelo menos em teoria) ser evitada usando árvores reforçadas ou florestas aleatórias. Em muitas situações, o reforço ou florestas aleatórias podem resultar em árvores com desempenho superior a Bayes ou K-NN. A desvantagem desses complementos é que eles adicionam uma camada de complexidade à tarefa e diminuem a grande vantagem do método, que é sua simplicidade.
Mais galhos em uma árvore levam a uma chance maior de adaptação excessiva. Portanto, as árvores de decisão funcionam melhor para um pequeno número de aulas. Por exemplo, a imagem acima resulta apenas em duas classes: continue ou não prossiga.
4. Ao contrário de Bayes e K-NN, as árvores de decisão podem trabalhar diretamente de um tabela de dados, sem qualquer trabalho prévio de design.
5. Se você não conhece seus classificadores, uma árvore de decisão será escolha esses classificadores para você de uma tabela de dados. Naive Bayes requer que você conheça seus classificadores com antecedência.
Referências
Árvore de decisão vs. classificador Naive Bayes
Comparação entre o Naive Basian e o K-NN Classifier
Fazendo ciência de dados: conversa direta da linha de frente
 Data Science Central
Data Science Central