Entenda como funciona streaming de dados em tempo real
Desde o final do milênio passado, uma palavra relativamente desconhecida começou a ser propagada: “streaming”. Timidamente no início e geralmente em áreas mais técnicas, foi gradualmente emergindo até se tornar onipresente.
De plataformas de áudio (Spotify, Deezer, Apple Music, YouTube Music, Amazon Music,Tidal, entre outras) e de vídeo (Youtube, Netflix, Vimeo, DailyMotion, Twitch, entre outras) a aplicações mais específicas, o streaming passou a ser uma palavra do cotidiano dos devs.
Geralmente, o termo vem acompanhado de outro já bem conhecido: Big Data, o qual podemos entender como conjuntos de dados (dataset) tão grandes que não podem ser processados e gerenciados utilizando soluções clássicas como sistemas de banco de dados relacionais (SGBD). Podemos ter streaming de dados fora do contexto de Big Data, porém é bem comum essas palavras virem em um mesmo contexto.
Neste instante, o desenvolvedor já quer fazer um “hello world” e já pergunta: “qual o melhor framework de streaming?” (falar no melhor é quase sempre generalista e enviesado, o termo “mais adequado” é mais realista, opinião do autor). Vamos entender o que é streaming de dados e o que podemos entender como “tempo real”.
Streaming de dados
Para uma melhor concepção do que é streaming de dados, primeiro vamos entender o que é processamento de dados em batch (lote em português ou, um termo mais antigo, “batelada”).
As tarefas computacionais geralmente são chamadas de jobs e podem executar em processos ou threads. Os que podem ser executados sem a interação do usuário final ou ser agendados para execução são chamados de batch jobs. Um exemplo é um programa que lê um arquivo grande e gera um relatório.
Frameworks
Na era do Big Data, surgiram vários modelos de programação e frameworks capazes de executar jobs em batch de forma otimizada e distribuída. Um deles é o modelo de programação MapReduce que foi introduzido e utilizado inicialmente pela Google como um framework que possui três componentes principais: uma engine de execução MapReduce, um sistema de arquivo distribuído chamado Google File System (GFS) e um banco de dados NoSQL chamado BigTable.
Podemos citar vários outros frameworks que possuem capacidade de processamento de dados em larga escala, em paralelo e com tolerância a falhas como: Apache Hadoop, Apache Spark, Apache Beam e Apache Flink (falaremos mais dele adiante). Frameworks que executam processamento em batch geralmente são utilizados para ETL (Extract Transform Load).
Processamento de datasets em forma de streaming
Uma outra forma de processar datasets é em forma de streaming. Aqui, já deixamos uma dica importante: streaming não é melhor que batch, são duas formas diferentes de processar dados e cada uma delas possui suas particularidades e aplicações.
Então, sem mais delongas, o que é um processamento de dados em streaming? De acordo com o excelente (e super indicado) livro “Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing”, podemos definir streaming como “um tipo de engine de processamento de dados projetado para tratar datasets infinitos”.
A primeira coisa a se ter em mente é que os dados virão infinitamente (unbounded), diferente do processamento em batch que é finito, e não há como garantir a ordem em que os mesmos chegam. Para isso existe uma série de estratégias (ou heurísticas) que tenta mitigar tais questões e cada uma delas com seus pontos fortes e fracos. Como diz o ditado: “There is no free lunch”!
Quando tratamos de datasets, podemos falar de duas estruturas importantes: tabelas, como uma visão específica do dado em um ponto específico do tempo, como acontece nos SGBDs tradicionais, e streams, como uma visão elemento a elemento durante a evolução de um dataset ao longo do tempo.
Dois eixos de funcionamento: sources e sinks
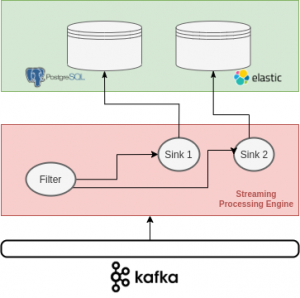
O dataset no processamento de streams funciona com duas pontas: sources e sinks. O source representa uma conexão de entrada e o sink uma de saída no seu streaming. Para clarear, podemos fazer uma analogia bem simples: pensem em uma caixa d’água que é enchida por meio de uma ligação de canos da companhia de água da sua cidade. Essa caixa d’água dá vazão para as torneiras e chuveiros da casa por meio da ligação hidráulica de sua residência. Nessa abstração, nosso dataset é a água contida na caixa d’água, nosso source é a ligação com a companhia de água e, finalmente, os sinks são as torneiras e chuveiros.
Levando agora para um exemplo real, podemos ter um sistema de streaming codificado em um framework/engine de processamento distribuído que poderia ser Apache Flink, Apache Storm, Apache Flume, Apache Samza, dentre outros, que recebe mensagens por meio da leitura de um sistema de mensageria (source) como Apache Kafka, por exemplo, processa-as em tempo real filtrando apenas aquelas que contiverem determinadas palavras-chave e envia uma saída para o Elasticsearch (sink 1) e outras para um banco de dados relacional PostgreSQL (sink 2).
O eixo temporal
Agora que já sabemos o que é um streaming de dados, vamos ao outro eixo: o temporal.
Entendemos o tempo como algo contínuo e que nunca para. Não se assustem! Aqui não iremos tratar questões físicas, como a teoria da relatividade. Nós, enquanto devs, tratamos o tempo como contínuo.
Para uma aplicação que processa streaming, cada dado que entra na nossa engine possui três abstrações de tempo: event time, ingestion time e processing time. O event time representa a hora em que cada evento individual é gerado na fonte de produção, ingestion time o tempo em que os eventos atingem o aplicativo de processamento streaming e processing time o tempo gasto pela máquina para executar uma operação específica no aplicativo de processamento de streaming.
Event time, ingestion time e processing time
Afinal de contas, a minha aplicação de streaming processa dados em tempo real? Aí vem a resposta que ninguém gosta de ouvir: “depende do contexto”, ou se preferir, “isso é relativo”. Vamos ao exemplo anterior da leitura de mensagens do Kafka e escrita no Elasticsearch e PostgreSQL, detalhando os tempos do processamento:

| Event time | 2020-01-01 01:45:55.127 |
| Ingestion time | 2020-01-01 01:45:57.122 |
| Processing time | 2020-01-01 01:45:57.912 |
O Ingestion time é responsável por qualquer atraso no processamento do dado e sua possível flutuação assim que o processamento “consome” a mensagem.
Quanto maior a diferença entre o tempo de geração da mensagem (event time) e o tempo que a mensagem chega a engine de streaming (ingestion time), menos “tempo real” será seu processamento. Por isso costumamos, falar em artigos científicos, em tempo “quase-real”. A diferença entre a hora da geração e a que a mensagem é processada é de 2 segundos e 784 milissegundos. Isso representa o “atraso” de apenas uma mensagem. Agora imaginem um throughput de 100 mil mensagens por segundo! Essa diferença de tempo tende a aumentar se o sistema não conseguir consumir e processar essa quantidade de mensagens à medida que chegam.
Mais uma dica de Big Data e streaming: não menospreze os milissegundos. Em grandes volumes, eles fazem muita diferença.
A ordenação dos dados
Outra questão que precisamos estar preparados é o problema que ocorre quando recebemos os dados de mais de uma fonte (source) ou a fonte de dados está com os event times fora de ordem. Se tivermos uma aplicação onde a ordem desses eventos importe, é necessário que haja uma heurística que trate dessa ordenação ou mesmo deste descarte dos dados fora de ordem. A maioria dos frameworks de streaming implementam alguma dessas heurísticas.
Um dos frameworks mais utilizados pelos devs, o Apache Flink possui o conceito de watermarks (marcas d’água). A ideia central é: quando um dado é “carimbado” com uma watermarks, a engine supõe que nenhum dado com tempo inferior (passado) irá chegar.
Como não podemos ter essa certeza, o framework espera que o desenvolvedor escolha como quer tratar esses casos: não toleramos dados com watermarks inferior à última reconhecida (atrasado) ou o framework espera um determinado tempo (10 segundos, por exemplo), ordena as mensagens e envia para processamento. O que chegar fora dessa janela de tempo será descartado. Há a possibilidade ainda de tratar esses dados que seriam descartados, mas fica fora do escopo deste post.
O case Alibaba
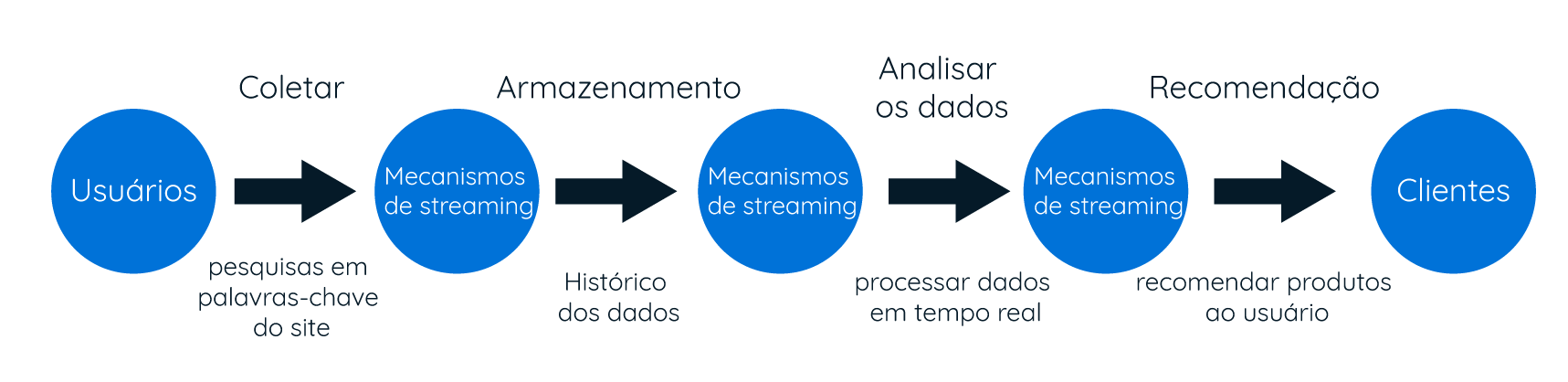
Um exemplo real da utilização de streaming de dados em tempo real em um ambiente de Big Data é o case do gigante chinês Alibaba, um grupo de empresas que possui negócios e aplicações focadas em e-commerce, incluindo pagamentos on-line, business-to-business, motor de busca e serviços de computação em nuvem.
Seus dois produtos mais conhecidos são o site de e-commerce (Alibaba.com) e os serviços em nuvem (Alibaba Cloud). O grupo lançou oficialmente em 2016 uma plataforma utilizada para busca e recomendação utilizando Apache Flink. Os mecanismos de recomendação filtram os dados dentro da plataforma de streaming utilizando algoritmos e dados históricos para recomendar os itens mais relevantes ao usuário.
Passos fundamentais para o trabalho com streaming de dados
Neste ponto, já entendemos o que é um streaming de dados e o quão tempo-real ele pode ser. Para finalizarmos, deixaremos algumas dicas para quem quer enveredar por essa área tão onipresente no mercado dev:
- Entenda os conceitos de streaming de dados antes de escolher um framework e começar a codar (de novo a dica do livro: Streaming Systems). Isso envolve o conceito de sources, sinks, pipeline, agregações de tempo;
- Esteja preparado para grande volumes de dados e altos throughput: isso pode parar sua aplicação por falta de recursos como espaço, memória e processamento;
- Pense distribuído! A maioria dos frameworks de streaming possuem o conceito de cluster. Dessa forma, sua aplicação conseguirá escalar horizontalmente e estar preparada para grandes volumes;
- Escove os bits. Essa é uma expressão bem dev. Entenda bem a linguagem e o framework que você está utilizando. Tire o máximo deles. Uma estrutura de dados inadequada ou ineficiente para o caso, um laço desnecessário, uma serialização/deserialização onde não é preciso podem minar o desempenho da sua aplicação.
- Por último e não menos importante: teste de carga! Faça testes levando sua aplicação ao extremo para identificar possíveis gargalos. Isso não substitui os testes unitários e afins. A finalidade é outra: ver o quanto sua aplicação consegue processar de dados.
É isso aí, pessoal. Espero que tenha suscitado uma vontade de aprender mais sobre streaming de dados em tempo real e suas aplicações.
Saudações e até a próxima!
Referências:
- Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing. 2019.
- What is batch processing? IBM® Knowledge Center
- Beyond Batch Processing: Towards Real-Time and Streaming Big Data. 2014. Saeed Shahrivari. Computers Journal.
- Stream processing: An Introduction to Event Time in Apache Flink. 2018. Apache Flink. Markos Sfikas.
- Why Did Alibaba Choose Apache Flink Anyway? 2019. Apache Flink Community China.